 Blaze: 用Rust重寫Spark執行層,平均提升30%算力
Blaze: 用Rust重寫Spark執行層,平均提升30%算力
大家好,我是Tim。
前一段時間,快手數據架構團隊開源了Blaze項目,它是一個利用本機矢量化執行來加速SparkSQL查詢處理的插件。
用通俗的話講就是通過使用Rust重寫Spark物理執行層來達到性能提升的目的。
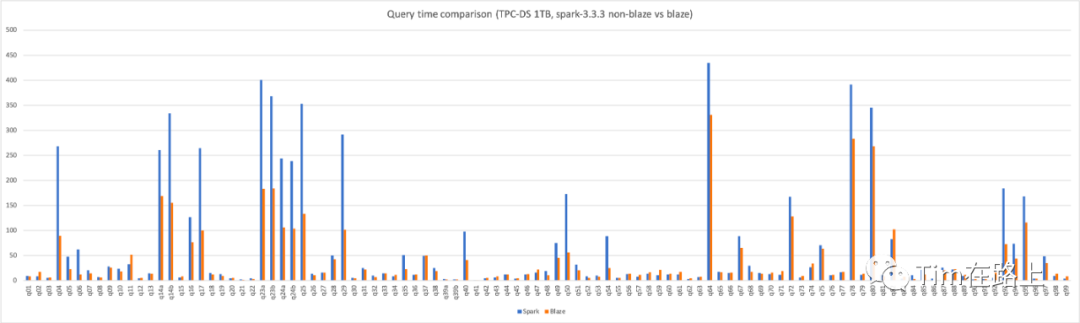
并且在TPC-DS 1TB的所有測試中,Blaze相比Spark3.3減少了40%的計算時間,降低了近一半的集群資源開銷。
此外,在快手內部上線的數倉生產作業也觀測到了平均30%的算力提升,實現了較大的降本增效。
今天我們就來聊一聊這個Blaze,以及近來重寫Spark執行層進行提效的諸多項目。
Spark填補了一個空白
在大數據建設的初期,單臺機器的 RAM 是有限且昂貴的,所以在進行集群規模計算時唯一可行選擇是基于 MapReduce 的 Hadoop,它可以在諸多廉價的普通主機上進行集群計算。
眾所周知,MapReduce 對磁盤 IO 的負擔非常重,而且并沒有真正發揮所有 RAM 的價值。
隨著機器硬件的發展,RAM的價格也大幅降低,這時Spark提出了彈性分布式數據集(RDD),這是一種分布式內存抽象,可以讓程序員以容錯的方式在大型集群上執行內存計算。
Spark 完美地填補了這個空白。突然間,許多大數據處理都可以非常高效地完成。
為什么要重寫Spark執行層?
而隨著硬件技術的繼續發展,Spark也需要進行相應的優化,來充分的發揮出底層硬件提供的能力。
以查詢計劃執行為例。原有的Spark引擎執行一個查詢計劃,往往采用火山模型的方式。
這種上層算子遞歸調用下層算子獲取并處理元組的方式,存在虛函數調用次數較多、指令或數據cache miss率高的缺陷,并且這種一次處理一個元組的方式無法使用CPU的SIMD指令進行優化,從而造成查詢執行效率低下的問題。
向量化執行就是解決上述問題的一種有效手段。
然而,我們都知道Spark是使用Scala寫的,和JAVA類似是運行在JVM上的。
在Java中,與C++或Rust相比,沒有直接的手動向量化特性,實現向量化都是由JVM自動控制的。
例如,JVM會對循環進行分析,判斷是否有類似于向量化的優化機會。
如果JVM發現某個循環中其計算次數大于一定量級,且指令可以被SIMD指令集所支持,那么它會將循環展開為并行操作,從而實現向量化執行。
publicstaticvoidvectorAdd(float[]a,float[]b,float[]result){
for(inti=0;i200;i++){
result[i]=a[i]+b[i];
}
}
如上面的代碼所示,其有可能會被JVM轉換為向量化執行。
即使循環符合向量化的條件,JVM也不能保證一定會自動實現向量化執行。在某些情況下,JVM可能會選擇跳過向量化執行。
所以,到目前為止,Spark中的性能殺手Shuffle等操作依然采用了行式數據處理。
不過對于讀寫列式文件的算子,如Parquet、Orc等,已經實現了向量化的批量操作。
除此以外,Scala、Java實現的Spark還會帶來垃圾收集(GC)開銷,這也是JAVA系語言的通病。
如果垃圾回收的時間太長,會嚴重影響任務執行的穩定性,甚至會被誤識別為節點失聯。
最后,Java還存在較高的內存消耗和無法進行低級別的系統優化等問題,這都迫使人們一直在嘗試重寫Spark執行層算子。
一直沒有開源的Photon
其實對于重寫Spark執行層算子,Spark的母公司Databricks早已進行了嘗試,并已經為其付費用戶提供了向量化的執行引擎Photon。
Photon已經被應用多年,其被定位為適用于 Lakehouse 環境的矢量化查詢引擎。在Databricks的內部數據上,Photon 已將一些客戶工作負載加速了 10 倍以上。
業界也一直有向量化執行引擎出現,例如velox、gluten(gluten可以支持velox或ck作為后端)。
velox就是一個單機/單節點的c++的向量化query runtime實現。
當然velox目標不只是Spark, 它希望統一替換大數據計算引擎的單節點runtime,包括Spark、Presto、Pytorch,以取得加速效果。
其對接Spark就是通過gluten項目進行對接的,velox目前也已基本在Meta公司內部落地。
但其開源社區一直不溫不火,甚至涼涼。
Blaze 借助Arrow DataFusion實現向量化執行引擎
Blaze的實現原理和Velox、Photon都是大同小異。
即在運行時嘗試使用向量化算子計算,如果不支持則回退回Spark原來的計算算子。
不過需要注意的是,Blaze是將Spark運行時物理運算符轉換為 Rust DataFusion的向量化實現。
關于DataFusion是什么,可以參考這篇文章:Apache Arrow DataFusion到底是什么?
目前Blaze可能還不支持聚合運算符,UDF 或 RDD API,這顯然會影響 TPC-DS 查詢的整體運行時間。不過,在快手內部據傳Blaze中已經添加了對聚合運算符的支持。
在開源的Blaze已支持Spark3.0和Spark3.3版本,其使用方式和gluten類似,通過在Spark環境中添加相應的Jar包實現功能擴展。
目前從其跑的TPC-DS 查詢性能測試上可以看出,Blaze平均提升30%的性能,節約了40%的集群資源。
然而其問題也和Velox一樣。
一方面需要在Spark集群環境中安裝特定版本的Rust/C++,而且Rust/C++在龐大的集群機器中可能會存在各種環境問題。
另一方面,其不支持UDF(當然Photon也不支持),在真實的計算任務中可能會存在各種兼容性問題,而導致需要回退到原始的Spark執行引擎上,可能會造成原始任務的性能倒退。
說白了,即不可能全局開啟Blaze性能優化,目前也只能針對特定任務特點用戶進行開啟優化。
Blaze引擎優化定位只是針對Spark引擎,而且在向量化的實現上又是基于DataFusion開源項目,相比Velox引擎其未來開源的路可能會比較好走一點,畢竟目標沒那么大嘛。
當然Blaze的出現還有一個作用,也許會迫使Databricks開源他們藏掖已久的Photon,這當然是一件好事。
就像當年Iceberg迫使Databricks開源其收費的數據湖存儲引擎Delta Lake一樣。
總結
Spark執行算子的向量化是未來必須要走的路,Blaze項目通過將Spark物理執行層算子轉換為Rust Arrow DataFusion向量化算子來提升性能,目前已在快手內部部分業務上線,并實現30%的性能提升。
在快手內部的成功,并不一定可以在開源社區獲得成功。
一方面,Spark社區并不會允許其并入Spark項目來獲得更大關注,另一方面這種優化實現方式在真實重要的業務場景,必然存在很多自定義的函數或算子,這給其在其他公司數據團隊上的落地造成了困難。
這可能需要數據團隊具有不破不立的精神,否則其并不能帶來全平臺的性能收益,而這顯然會使得使用Blaze項目所需的成本項異常顯眼。
最后,希望Blaze項目可以成功,至少可以迫使Databricks開源其Photon,也希望更多native引擎開源來提升Spark任務執行性能。
-
磁盤
+關注
關注
1文章
388瀏覽量
25657 -
SPARK
+關注
關注
1文章
106瀏覽量
20413 -
Rust
+關注
關注
1文章
233瀏覽量
6962
原文標題:Blaze: 用Rust重寫Spark執行層,平均提升30%算力
文章出處:【微信號:Rust語言中文社區,微信公眾號:Rust語言中文社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
“算力”的分層定義-初級算力


rx580算力,rx580顯卡算力,rx588算力,rx588顯卡算力 精選資料分享
Cloudflare用Rust重寫Nginx C模塊,構建沒有Nginx的未來
Rust重寫的LSP:KCL IDE 插件的功能介紹與設計解析
Windows 11初嘗Rust,36000行內核代碼已重寫!
存算一體+Chiplet能否應對AI大算力和高能耗的挑戰?
算力網絡的概念及整體架構

阿里云倚天實例已為數千家企業提供算力,性價比提升超30%

一次Rust重寫基礎軟件的實踐
算力的分類與現代生活





 工商網監
工商網監
評論