") 淺談Q-Learning在Agent的應用
淺談Q-Learning在Agent的應用
OpenAI 宮斗告一段落,現(xiàn)在到處都在猜 Q* 是什么。本文沒有 Q* 的新料,但是會探討一下 Q-Learning 在 Agent 方面的可能應用。
有趣的分享!LLMs時代下,幻覺、對話、對齊、CoT、Agent和事實性評估等領(lǐng)域的前沿研究
實現(xiàn) tool 自動選擇和參數(shù)配置
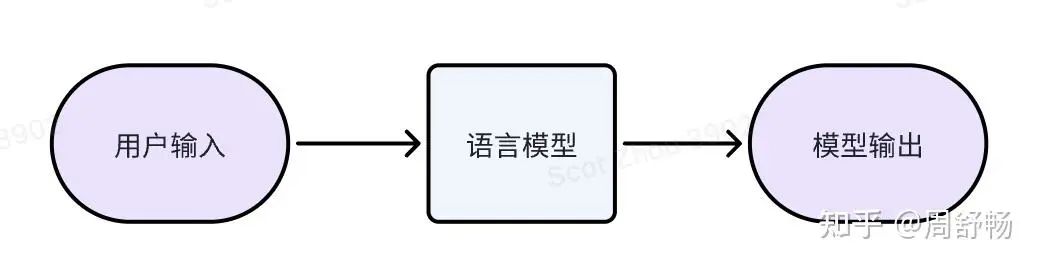
經(jīng)典文字模型
經(jīng)典的文字模型我們已經(jīng)很熟悉了:訓練時,模型不停的預測下一個 token 并與真實語料比較,直到模型的輸出分布非常接近于真實分布。
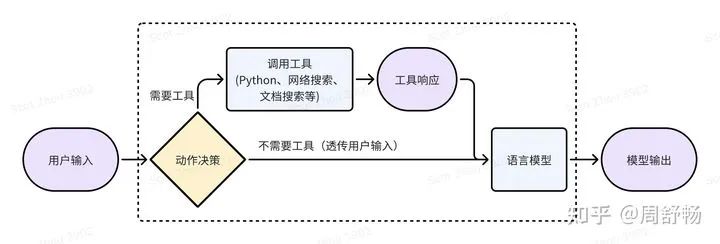
因為語言模型的局限性(比如搞不定大數(shù)計算),所以多家大模型公司走上了語言模型 + 工具的道路。比如 GPT4-turbo 就可以靈活調(diào)用網(wǎng)絡(luò)搜索、Analysis(某種 Python) 這些 tools,來生成 tool response(即網(wǎng)絡(luò)搜索結(jié)果、Python 執(zhí)行結(jié)果),來幫助回答文字問題。
這就引入了一個決策問題,對于一個用戶表達(utterance),到底要不要做網(wǎng)絡(luò)搜索或者調(diào)用 Python 來幫助回答呢?如果決策錯誤,則結(jié)果不最優(yōu):
?工具的響應結(jié)果(tool response)可能無濟于事甚至產(chǎn)生誤導。比如有一些網(wǎng)絡(luò)上的玩梗會影響模型對一些基本概念的知識。?工具的調(diào)用引入了額外的時間消耗。
因此,好好搞一些標注,訓一個“動作決策”模型,能拿到第一波好處。這是有監(jiān)督學習的思路。這里動作決策模型的輸出,是具體的含參數(shù)的動作,比如調(diào)用網(wǎng)絡(luò)搜索時,需要給出“是否搜索”和“搜索關(guān)鍵字”兩部分信息。因此動作決策模型最好也是個大模型。這么搞的問題,是上限不高,受制于“動作決策模型”的標注質(zhì)量,并且并沒有直接優(yōu)化“模型輸出”,需要人絞盡腦汁來針對模型調(diào)整“動作決策模型”的標注來達到最優(yōu)。比如對于網(wǎng)絡(luò)搜索,當搜索引擎不同時,需要為“動作決策模型”使用不同的搜索關(guān)鍵字作為標注。
但從另一個角度,虛線框內(nèi)的部分,仍然是一個文字進文字出的"模型",所以理論上可以用降低輸出結(jié)果的困惑度的方法,按強化學習(RL)去訓練這個復合了工具的“語言模型”。這里因為“動作的決策”不可微,所以來自“模型輸出”的梯度只能用 RL 往回傳。使用 RL 的具體步驟為:
?利用標注訓練“動作決策模型”,使得整體有一定效果,即完成行為克隆(behavior cloning)這一啟動步。?用強化學習繼續(xù)訓練整體,即復合了工具的“語言模型”。
Reward 由幾項組成:
?利用<用戶輸入、模型輸出>這樣的成對數(shù)據(jù)(格式上接近 SFT 數(shù)據(jù)),計算困惑度?如果有用戶偏好數(shù)據(jù),也可以仿照 DPO 構(gòu)造不同動作間的對比數(shù)據(jù)項。?把調(diào)用工具的時間和成本代價,折算進 Reward
實際,以上相當于使用了 Q-learning 的一個簡單變體 DDPG,即假設(shè)存在函數(shù)映射μ使得μ(當前狀態(tài)) = 最優(yōu)工具調(diào)用動作與參數(shù) 如果不做這個假設(shè),還是使用 Q(s, a) 的形式,則更接近 Reward Model 的搞法。
這里一個附送的好處,是可以做層級強化學習(hierarchical RL),就是說可以在工具調(diào)用中嵌套工具調(diào)用,比如一個網(wǎng)絡(luò)搜索中嵌套網(wǎng)絡(luò)搜索。因為上面在 Reward 里計入了“調(diào)用工具的時間和成本代價”,所以優(yōu)化后的模型不太會出現(xiàn)盲目使用工具的情況。同時 RL 天然能處理多步?jīng)Q策,所以不特別需要研究“多輪交互時的動作決策模型標注“。
引入動態(tài)拆分任務(wù)
以上的 tool 調(diào)用,特別是網(wǎng)絡(luò)搜索和 Python 執(zhí)行,主要是為模型輸出產(chǎn)生一些參考,因此本質(zhì)上沒有互斥性,就是說各個動作間沒有強依賴。我們下面考慮一個動作間有強烈互相影響的場景:“任務(wù)拆分”。
當用戶輸入復雜到一定程度,我們需要引入拆分。靜態(tài)拆分不需要特殊處理,但是如果希望子任務(wù)是跟據(jù)動態(tài)執(zhí)行時獲得的信息動態(tài)調(diào)整的,則要引入一個任務(wù)棧來進行管理。之前 AutoGPT 即引入了動態(tài)拆分子任務(wù),基于語言模型實現(xiàn)了一定的 Agent 能力。但是一直以來 AutoGPT 并沒有通過“訓練”來加強能力的方法。下面,我們先把 AutoGPT 搬到 RL 里,一個搞法是借助 MCTS(蒙特卡洛搜索樹)。
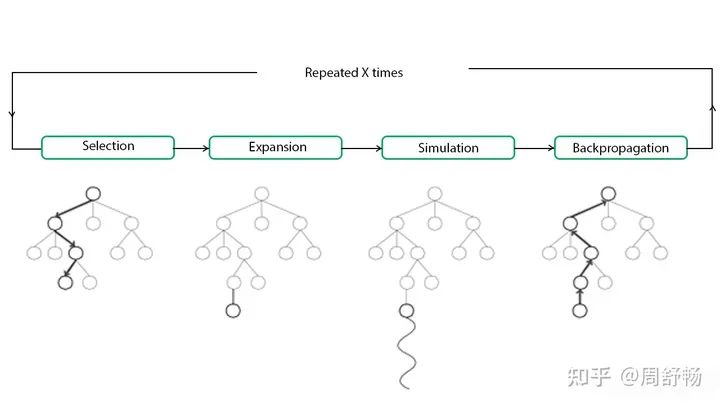
根結(jié)點是當前任務(wù)。各個葉子結(jié)點有 expandable 和 terminal 兩個屬性,其中 expandable 結(jié)點可以進一步被展開成子任務(wù)。注意
?MCTS 里 sibling 結(jié)點之間是或關(guān)系,選一即可。?MCTS 的 Policy Network 對應上文中的“動作決策”模型。?MCTS 里的 Value Network 可以用一大模型實現(xiàn),描述當前結(jié)點的價值。比如發(fā)現(xiàn)當前子任務(wù)是死胡同時(如發(fā)現(xiàn)模型在用窮舉法證明“偶數(shù)加偶數(shù)還是偶數(shù)”時)可以喊停。?上文的工具調(diào)用“模型”可以自然地嵌入到這里使用
子任務(wù)拆分沒什么可用的數(shù)據(jù),可以先靠語言模型天賦能力開始。訓練數(shù)據(jù)可以選有明確答案的題,以答對為 Reward。MCTS 的形式特別適用需要回溯的任務(wù)(把某種任務(wù)分解推倒重來),比如數(shù)學計算。
(到這,我們得到了一個用 Q-learning 整體驅(qū)動的,自動學習如何拆任務(wù)調(diào)工具的框架,似乎和 Q* 公開的一些線索對上了一些。)
審核編輯:黃飛
-
Agent
+關(guān)注
關(guān)注
0文章
128瀏覽量
27648 -
Q-Learning
+關(guān)注
關(guān)注
0文章
5瀏覽量
8226 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86355
原文標題:Q-Learning 在 Agent 的應用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
《AI Agent應用與項目實戰(zhàn)》閱讀體驗--跟著迪哥學Agent
【「零基礎(chǔ)開發(fā)AI Agent」閱讀體驗】+初品Agent
【「零基礎(chǔ)開發(fā)AI Agent」閱讀體驗】+Agent的工作原理及特點
【「零基礎(chǔ)開發(fā)AI Agent」閱讀體驗】+Agent開發(fā)平臺
基于Q-Learning的認知無線電系統(tǒng)感知管理算法
基于LCS多機器人的算法介紹
基于Q-learning的碼率控制算法
Q Learning算法學習
淺談Q-Learning和SARSA時序差分算法
基于雙估計器的Speedy Q-learning算法
《自動化學報》—多Agent深度強化學習綜述

怎樣使用Bevy和dfdx解決經(jīng)典的Cart Pole問題呢
7個流行的強化學習算法及代碼實現(xiàn)
7個流行的強化學習算法及代碼實現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論