 谷歌Gemini自曝用文心一言訓練,字節被OpenAI封號,大模型互薅羊毛是常態?
谷歌Gemini自曝用文心一言訓練,字節被OpenAI封號,大模型互薅羊毛是常態?

電子發燒友網報道(文/吳子鵬)近兩天,原本就火熱的人工智能大模型再度被澆上了一桶油,話題熱度更勝從前。不過,這一次大家探討的并不是大模型前景和算力這些,而是大模型之間互薅羊毛的問題。根據微博知名博主@闌夕爆料,對谷歌Gemini進行測試時,如果用中文詢問Gemini的身份,其回答竟然是百度文心一言。
更讓人大跌眼鏡的是,測試人員可以使用“小愛同學”“小度”等提示詞喚醒Gemini。并且,Gemini還能夠告訴測試人員,自己是如何獲取到百度的訓練數據的。

網傳對話場景

網傳對話場景
不過,此則消息應該是很快就引起了谷歌技術人員的關注,在消息曝光不久后,Gemini應對上述提示詞和問題的方式就發生了改變。通過“小愛同學”“小度”等提示詞無法再喚醒Gemini,且對于相關問題的闡述也發生了變化,顯然谷歌技術人員很快修復了一些bug。
谷歌Gemini飽受質疑
當地時間12月6日,谷歌宣布推出“最大、最強、最通用”的新大型語言模型Gemini,我們對此也進行了專門的報道。在發布會上谷歌聲稱,在32項廣泛使用的基準測試中,Gemini Ultra獲得了30個SOTA(State of the art,特指領先水平的大模型)。這也就意味著,Gemini 1.0版本在文本、代碼、音頻、圖像和視頻處理能力方面,以及推理、數學、代碼等方面都吊打GPT-4。
同時,在發布會上谷歌還展示了Gemini相關的能力。比如,Gemini可以非常高效地從數十萬份文件中獲取對科學家有用的數據,并創建數據集;Gemini可以在世界上最受歡迎的編程語言(如Python、Java、C++和Go)中理解、解釋和生成高質量的代碼。
不過,谷歌是通過視頻展示的Gemini的相關能力,而不是通過現場實操。于是乎,就在谷歌發布會的次日,有視頻制作人員質疑稱,谷歌的演示視頻并不是實錄,而是剪輯的。隨后,谷歌在博客文章中解釋了多模態交互過程,并提到了視頻演示中的猜拳,谷歌承認,不同于視頻中對于猜拳手勢的快速反應,只有在向Gemini同時展示這三個手勢并提示其這是游戲時,Gemini才會得出猜拳游戲的結論。
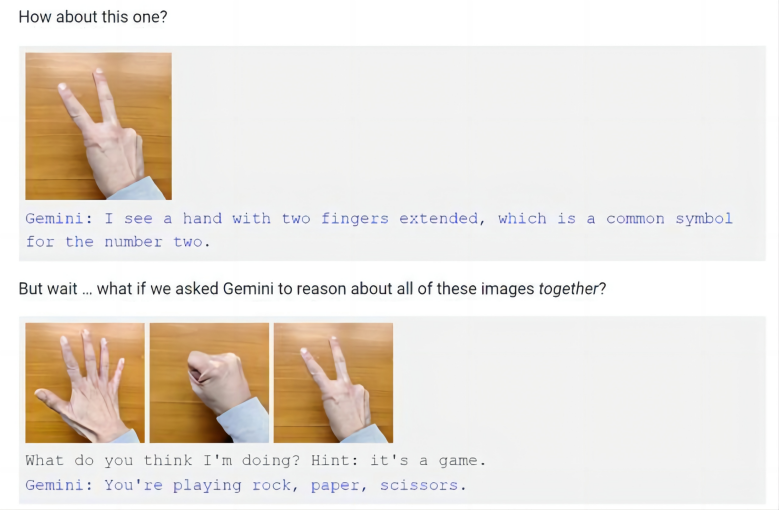
圖源:谷歌博文
因此,現在很多人都認為谷歌夸大了Gemini的能力,只有使用靜態圖片和多段提示詞拼湊,Gemini才能夠顯示出多模態的能力,這和谷歌宣稱的實時多模態反應明顯是不相符的。
大模型之間互薅羊毛
除了性能質疑之外,此次事件則揭露了大模型發展另一個規則——互薅羊毛。實際上,在Gemini自曝是百度文心一言之前,國內字節跳動就發生了相關問題。
近日,有外媒報道稱,字節跳動在使用OpenAI技術開發自己的大語言模型,違反了OpenAI服務條款,導致賬戶被暫停。對此,字節跳動相關負責人向記者回應稱:今年年初,當技術團隊剛開始進行大模型的初期探索時,有部分工程師將GPT的API服務應用于較小模型的實驗性項目研究中。該模型僅為測試,沒有計劃上線,也從未對外使用。4月公司引入GPT API調用規范檢查后,這種做法已經停止。字節跳動稱,后續會嚴格遵守OpenAI的使用協議。
從Gemini調整之后的回復來看,其在訓練過程中確實使用了百度文心一言的訓練數據,這其實也無可厚非。百度文心一言在中文理解及相關的多模態生成能力方面確實處于領先的位置,那么背后的原因定然是因為百度掌握著質量相對更好的中文訓練數據集,因此其他大模型如果想要在中文對話方面取得進展,使用文心一言的訓練數據確實是最高效的方式。
另外,除了字節跳動,此前谷歌也被質疑使用OpenAI數據來訓練Bard,最終谷歌的回應是Bard沒有使用ShareGPT或是ChatGPT的任何數據來進行訓練。另外,國內也有很多公司被質疑是采用OpenAI數據來完善自己的大模型。不過,這種行為大都見不得光,因此都被否認了。
為什么其他大模型頻傳借用OpenAI數據來訓練呢,重要原因在于GPT-4性能領先一個重要的原因就是數據集質量更高。根據semianalysis發布的《GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE》文章,GPT-4是一個使用1.8萬億巨量參數訓練的模型框架,而GPT-3只有約1750億個參數,另外GPT-4擁有16個專家模型,每個MLP專家大約有1110億個參數。這就是為什么在展示Gemini Ultra的MMLU訓練時,谷歌將“CoT@32”進行小字注釋,代表Gemini Ultra的MMLU測試使用了思維鏈提示技巧,嘗試了32次并從中選擇最好結果。與之對比,GPT-4無提示詞技巧給5個示例。就這樣,GPT-4的成績為86.4%,依然高于Gemini Ultra的83.7%。
另外,OpenAI用13萬億的token訓出了GPT-4。因為沒有高質量的token,這個數據集還包含了許多個epoch。
綜上所述,雖然GPT-4的訓練數據規模沒有官方說明,但是semianalysis文章可信度很高,這個規模比Gemini Ultra宣稱的萬億似乎更強,也不怪大家都想用GPT調優自己的模型。
當然,每一個模型都有自己擅長的地方,尤其是那些垂直的行業模型,在行業數據方面肯定是優于一般多模態大模型的,因此被薅羊毛的概率也很大,但是這大都不會被公開。
大模型數據集背后的產業鏈
為了讓GPT-4具有領先的性能,OpenAI的研發團隊在模型優化、數據選擇和硬件投入等方面做了大量工作。相信谷歌的Gemini Ultra和百度文心一言等大模型也是如此。對于大模型來說,預訓練數據集是一個非常關鍵的元素,很大程度上決定了大模型最終的性能水平。
在這個大背景下,隨著大模型產業發展,訓練數據也逐漸成為一種產業。比如國內的云測數據,云測創立于2011年,是一家以人工智能技術驅動的企業服務平臺,為全球超過百萬的企業及開發者提供云測試服務、AI訓練數據服務、安全服務。該公司的云測數據入選“北京市人工智能行業賦能典型案例(2023)”,在垂直大模型訓練數據服務方面很有造詣。
再比如,海天瑞聲作為國內領先基礎數據服務商,是國內首家且是目前唯一一家A股上市的人工智能訓練數據服務企業,為阿里巴巴、Meta、騰訊、百度、字節跳動等公司提供數據服務。
北京郵電大學科學技術研究院副院長曾雪云教授此前在受訪時表示,“互聯網上生成的這些數據,它是非結構化的數據,也是非標準化的數據。這樣的數據就是一種原始的、比較雜亂的、沒有規范的數據,它就需要在計算前進行顆粒度上的清洗,所以高質量數據通常都有從非結構化到結構化這樣的一個加工過程。”
“現在從對數據科學的研究、國家對數據的治理,到學術界對數據的研究、產業界對數據的利用都是一個藍海,都是一個剛開始的狀態。”曾雪云教授提到。
當然不僅國內關注到這一塊的產業價值,作為頭部企業,OpenAI希望與機構合作建立新的人工智能訓練數據集。OpenAI為此創立了“數據伙伴關系”(Data Partnerships)計劃,該計劃旨在與第三方機構合作,建立用于人工智能模型訓練的公共和私有數據集。OpenAI 在一篇博文中表示,數據合作伙伴關系旨在“讓更多組織能夠幫助引導人工智能的未來”,并“從更有用的模型中獲益”。
結語
人工智能大模型其實是大數據時代的典型產物,那么也就無法脫離對大數據的依賴。大模型的火爆讓高質量訓練數據成為高價值、緊俏的資源,而這些數據往往掌握在頭部企業手里,這就是為什么大模型企業之間互相會薅羊毛。不過,相較于互聯網海量的數據,目前科技巨頭的訓練數據集還只是九牛一毛,如何從海量互聯網數據提取有價值的訓練數據集,已經逐漸成為一個產業鏈。
-
谷歌
+關注
關注
27文章
6231瀏覽量
108166 -
字節跳動
+關注
關注
0文章
347瀏覽量
9488 -
OpenAI
+關注
關注
9文章
1210瀏覽量
8931 -
文心一言
+關注
關注
0文章
133瀏覽量
1864 -
大模型
+關注
關注
2文章
3146瀏覽量
4076
發布評論請先 登錄
寧暢與與百度文心大模型展開深度技術合作
deepseek和文心一言兩者有什么區別?哪個跟合適您使用呢?
百度文心大模型4月1日起全面免費開放
谷歌 Gemini 2.0 Flash 系列 AI 模型上新
機械革命無界X系列輕薄本將預裝文心一言
AI智能眼鏡定制_AI眼鏡硬件主板國產展銳W517方案





 工商網監
工商網監
評論