") OCR終結(jié)了?曠視提出可以文檔級(jí)OCR的多模態(tài)大模型框架Vary,支持中英文,已開(kāi)源!
OCR終結(jié)了?曠視提出可以文檔級(jí)OCR的多模態(tài)大模型框架Vary,支持中英文,已開(kāi)源!

想將一份文檔圖片轉(zhuǎn)換成 Markdown 格式?以往這一任務(wù)需要文本識(shí)別、布局檢測(cè)和排序、公式表格處理、文本清洗等多個(gè)步驟——
這一次,只需一句話命令,多模態(tài)大模型 Vary 直接端到端輸出結(jié)果:
無(wú)論是中英文的大段文字:


還是包含了公式的文檔圖片:

又或是手機(jī)頁(yè)面截圖:
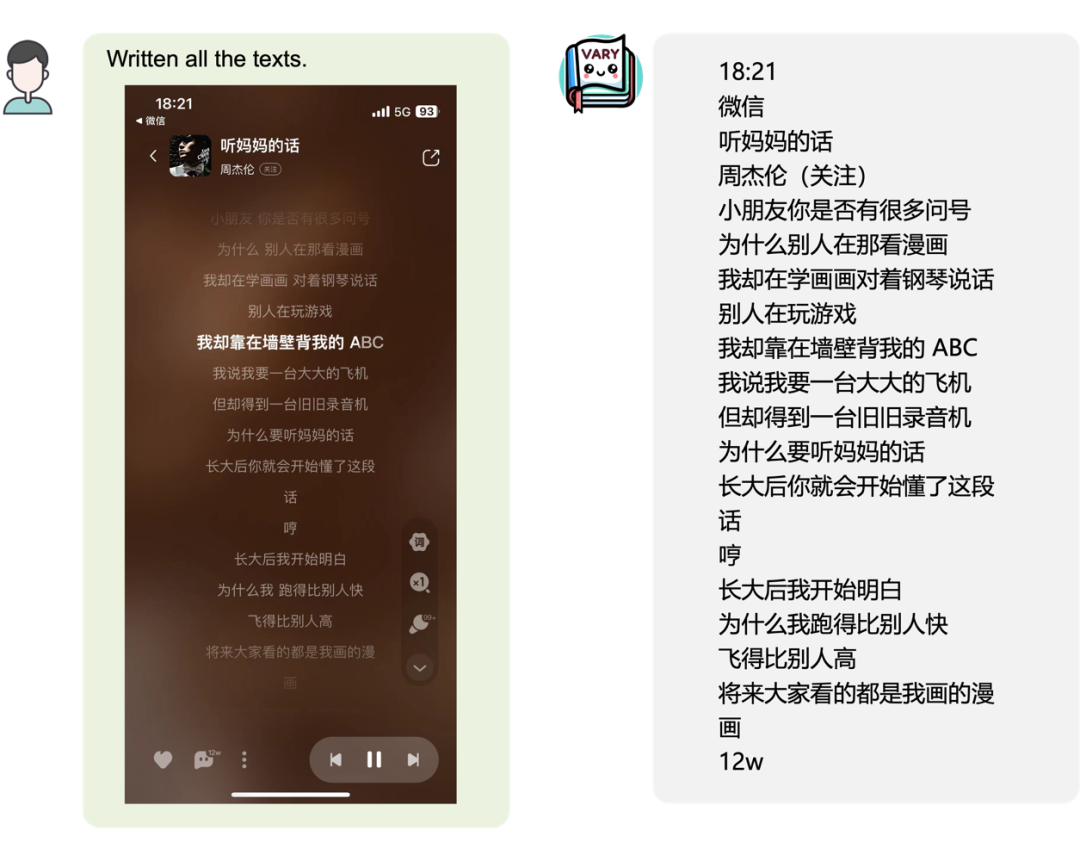
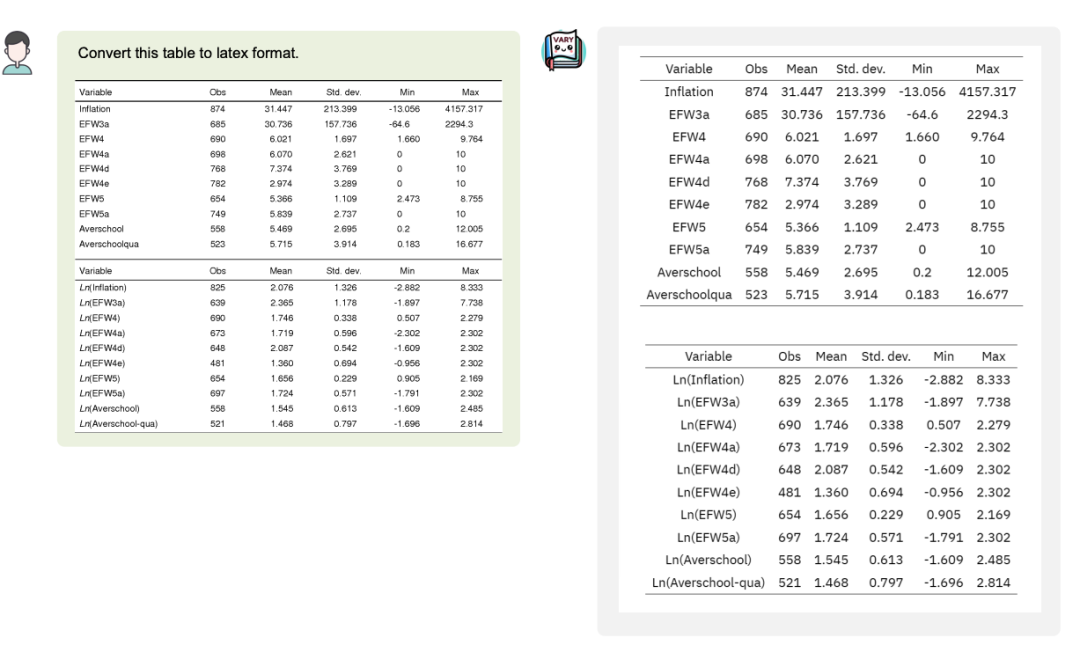
甚至可以將圖片中的表格轉(zhuǎn)換成 Latex 格式:
當(dāng)然,作為多模大模型,通用能力的保持也是必須的:
Vary 表現(xiàn)出了很大的潛力和極高的上限,OCR 可以不再需要冗長(zhǎng)的 pipline,直接端到端輸出,且可以按用戶的 prompt 輸出不同的格式如 Latex、Word、Markdown。通過(guò) LLM 極強(qiáng)的語(yǔ)言先驗(yàn),這種架構(gòu)還可以避免 OCR 中的易錯(cuò)字,比如“杠桿”和“杜桿”等, 對(duì)于模糊文檔,也有望在語(yǔ)言先驗(yàn)的幫助下實(shí)現(xiàn)更強(qiáng)的 OCR 效果。
項(xiàng)目一出,引發(fā)了不少網(wǎng)友的關(guān)注,有網(wǎng)友看后直呼 “kill the game!”

那么這樣的效果,是如何做到的呢?
背后原理
目前的多模態(tài)大模型幾乎都是用 CLIP 作為 Vision Encoder 或者說(shuō)視覺(jué)詞表。確實(shí),在 400M 圖像文本對(duì)訓(xùn)練的 CLIP 有很強(qiáng)的視覺(jué)文本對(duì)齊能力,可以覆蓋多數(shù)日常任務(wù)下的圖像編碼。但是對(duì)于密集和細(xì)粒度感知任務(wù),比如文檔級(jí)別的 OCR、Chart 理解,特別是在非英文場(chǎng)景,CLIP 表現(xiàn)出了明顯的編碼低效和 out-of-vocabulary問(wèn)題。
受語(yǔ)言的 LLMs 啟發(fā),純 NLP 大模型(如 LLaMA)從英文到中文(外語(yǔ))時(shí)因?yàn)樵荚~表編碼中文效率低,必須要擴(kuò)大 text 詞表。那么對(duì)于現(xiàn)在基于 CLIP 視覺(jué)詞表的多模大模型也是一樣的,遇到 “foreign language image”,如一頁(yè)論文密密麻麻的文字,很難高效地將圖片 token 化,Vary 提出就是解決這一問(wèn)題,在不 overwrite 原有詞表前提下,高效擴(kuò)充視覺(jué)詞表。

不同于現(xiàn)有方法直接用現(xiàn)成的 CLIP 詞表,Vary 分兩個(gè)階段:第一階段先用一個(gè)很小的 Decoder-only 網(wǎng)絡(luò)用自回歸方式幫助產(chǎn)生一個(gè)強(qiáng)大的新視覺(jué)詞表;然后在第二階段融合新詞表和 CLIP 詞表,從而高效的訓(xùn)練多模大模型擁有新 feature。Vary 的訓(xùn)練方法和模型結(jié)構(gòu)如下圖:
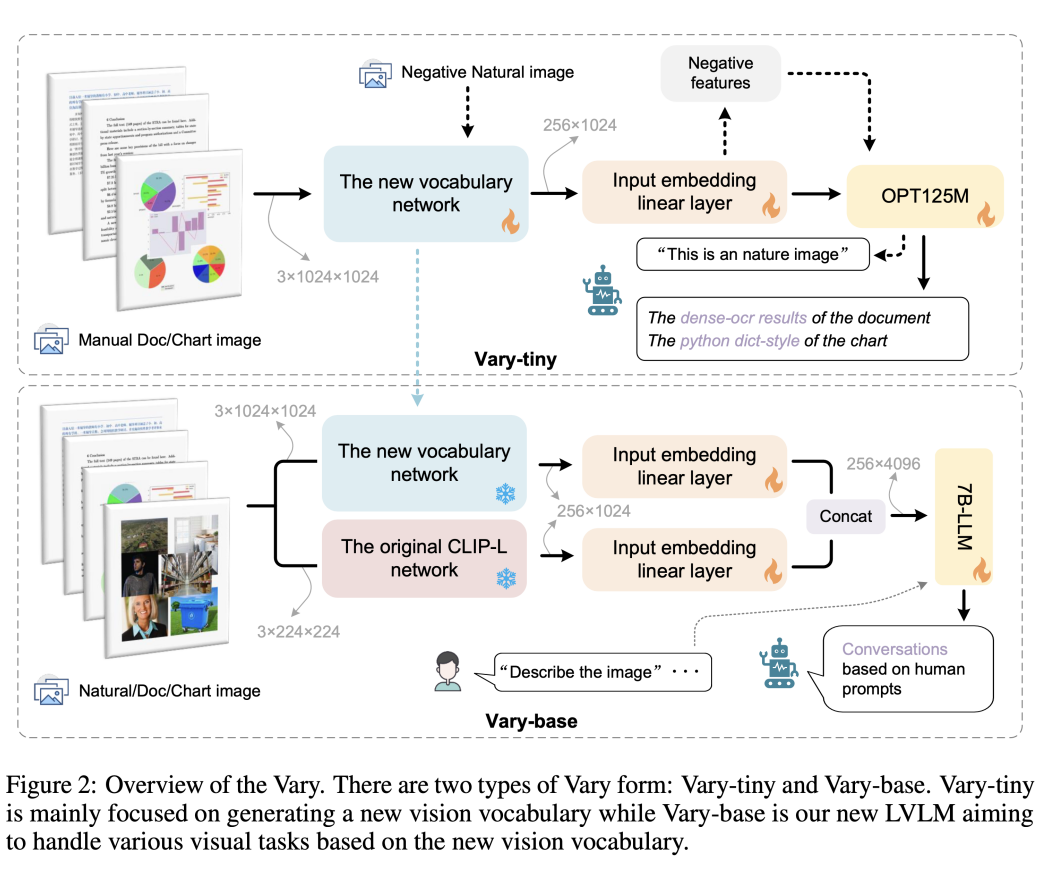
通過(guò)在公開(kāi)數(shù)據(jù)集以及渲染生成的文檔圖表等數(shù)據(jù)上訓(xùn)練,Vary 極大增強(qiáng)了細(xì)粒度的視覺(jué)感知能力。在保持 Vanilla 多模態(tài)能力的同時(shí),激發(fā)出了端到端的中英文圖片、公式截圖和圖表理解能力。
另外,原本可能需要幾千 tokens 的頁(yè)面內(nèi)容,通過(guò)文檔圖片輸入,信息被Vary壓縮在了 256 個(gè)圖像 tokens 中。這也為進(jìn)一步的頁(yè)面分析和總結(jié)提供了更多的想象空間。
目前,Vary 的代碼和模型均已開(kāi)源,還給出了供大家試玩的網(wǎng)頁(yè) demo。感興趣的小伙伴可以去試試了~
項(xiàng)目主頁(yè):
https://varybase.github.io/

參考鏈接
?https://zhuanlan.zhihu.com/p/671420712
· ·
原文標(biāo)題:OCR終結(jié)了?曠視提出可以文檔級(jí)OCR的多模態(tài)大模型框架Vary,支持中英文,已開(kāi)源!
文章出處:【微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2930文章
46094瀏覽量
390304
原文標(biāo)題:OCR終結(jié)了?曠視提出可以文檔級(jí)OCR的多模態(tài)大模型框架Vary,支持中英文,已開(kāi)源!
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
OCR識(shí)別訓(xùn)練完成后給的是空壓縮包,為什么?

孚為智能采用多角度高清攝像與智能OCR技術(shù),實(shí)現(xiàn)集裝箱號(hào)碼全自動(dòng)識(shí)別。#集裝箱號(hào)ocr識(shí)別
愛(ài)芯通元NPU適配Qwen2.5-VL-3B視覺(jué)多模態(tài)大模型

海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
大模型預(yù)標(biāo)注和自動(dòng)化標(biāo)注在OCR標(biāo)注場(chǎng)景的應(yīng)用
階躍星辰開(kāi)源多模態(tài)模型,天數(shù)智芯迅速適配
海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品
字節(jié)跳動(dòng)發(fā)布OmniHuman 多模態(tài)框架
商湯日日新多模態(tài)大模型權(quán)威評(píng)測(cè)第一
曠視亮相2024數(shù)字科技生態(tài)大會(huì)
ElfBoard開(kāi)源項(xiàng)目|車(chē)牌識(shí)別項(xiàng)目技術(shù)文檔

利用OpenVINO部署Qwen2多模態(tài)模型
明治案例 | PE編織袋【大視野】【OCR識(shí)別】

基于AX650N芯片部署MiniCPM-V 2.0高效端側(cè)多模態(tài)大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論