") 智能駕駛芯片TOP20排名
智能駕駛芯片TOP20排名
智能駕駛芯片排名并不簡(jiǎn)單只看AI算力,CPU、存儲(chǔ)帶寬、功耗和AI算力數(shù)值一樣重要,這個(gè)下文會(huì)詳細(xì)分析。CPU算力也很重要,智能駕駛系統(tǒng)軟件異常復(fù)雜,會(huì)消耗大量的CPU運(yùn)算資源,軟件系統(tǒng)包含眾多中間件諸如SOME/IP、自適應(yīng)AUTOSAR、DDS、ROS等,基礎(chǔ)軟件包括訂制的Linux BSP、OS抽象層、虛擬機(jī),還有與底層硬件關(guān)聯(lián)的內(nèi)存管理、各種驅(qū)動(dòng)、各種通訊協(xié)議等等。除此之外,應(yīng)用層中的路徑規(guī)劃、高精度地圖、行為決策等也大量消耗CPU資源,同時(shí)CPU也管理AI運(yùn)算時(shí)的任務(wù)調(diào)度、存儲(chǔ)搬運(yùn)指令等,整體的任務(wù)調(diào)度、決策自然也是CPU的任務(wù)。CPU是絕對(duì)的核心,AI是CPU的附屬功能,只是在做圖像特征提取、分類、BEV變換、矢量地圖映射或空間分布占有時(shí)才用到AI。
排名的權(quán)重依次是AI算力、存儲(chǔ)帶寬、CPU算力、GPU算力、制造工藝。存儲(chǔ)帶寬和AI算力同等權(quán)重,GPU也是錦上添花,大部分車載AI處理部分只能對(duì)應(yīng)INT8位數(shù)據(jù),而GPU可以對(duì)應(yīng)FP32數(shù)據(jù),有些時(shí)候可能有很大作用。實(shí)際AI算力數(shù)字完全是個(gè)黑箱,操作空間極大,參考意義不大。最能準(zhǔn)確衡量算力的是MAC陣列數(shù)量,谷歌的TPU V1是65000個(gè)FP16 MAC,運(yùn)行頻率0.7GHz,那么算力就是65000*0.7G*2=91TOPS。特斯拉第一代FSD兩個(gè)NPU,每個(gè)NPU是9216個(gè)INT8 MAC,運(yùn)行頻率是2GHz,算力就是2*2*2G*9216=73.7TOPS。制造工藝方面,自然還是越先進(jìn),功耗越低。
智能駕駛芯片TOP20
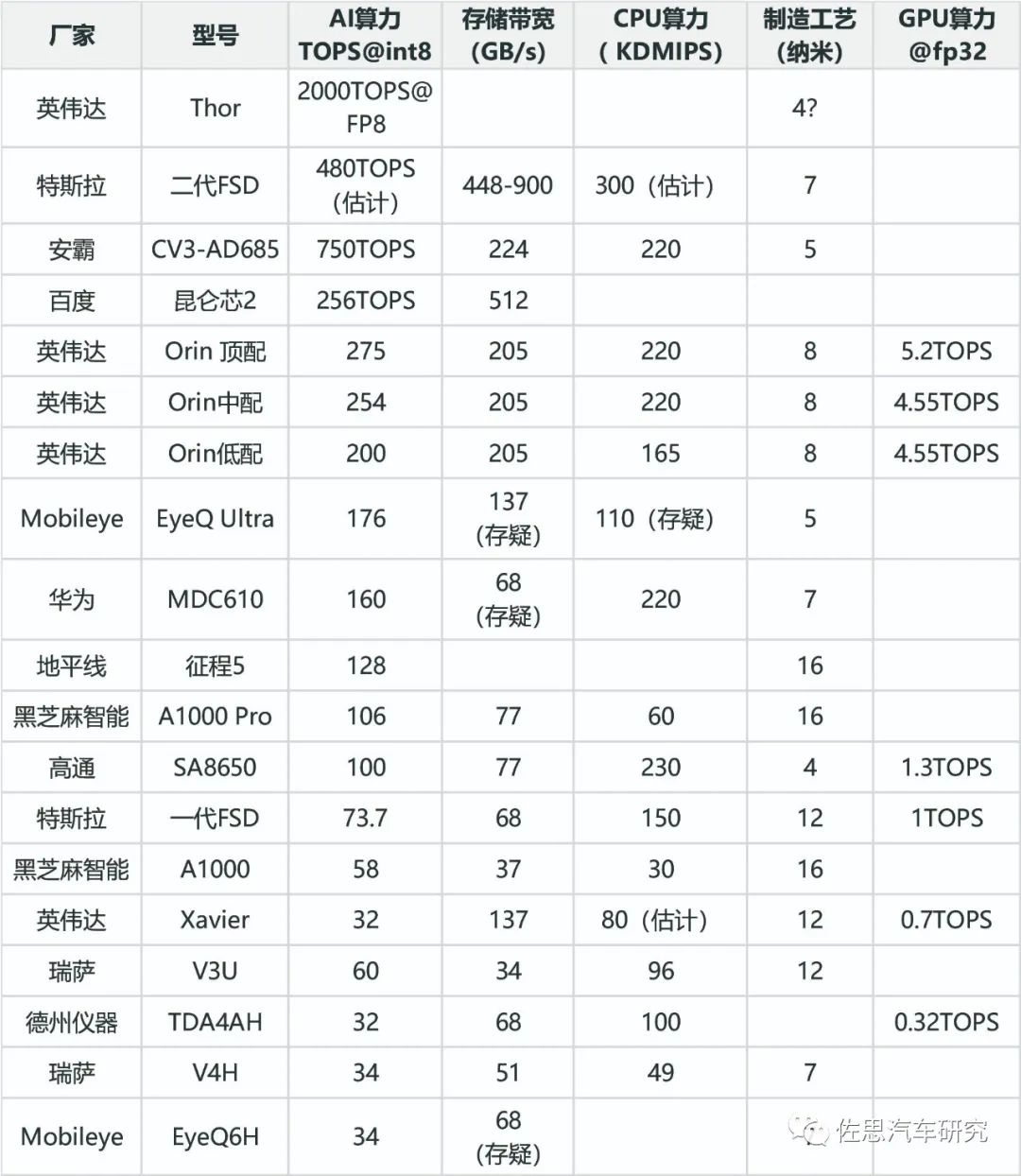
圖片來源:公開資料整理
如何計(jì)算存儲(chǔ)帶寬,芯片本身都有存儲(chǔ)管理器,這通常是CPU的一部分,決定存儲(chǔ)帶寬的有兩點(diǎn),首先是CPU支持的存儲(chǔ)類型,即存儲(chǔ)的物理層和控制器,其次是CPU的存儲(chǔ)帶寬,LPDDR的存儲(chǔ)帶寬最高一般是256比特,GDDR可以到384比特,HBM可以到4096甚至8192比特,這些都關(guān)聯(lián)成本,廠家在設(shè)計(jì)芯片時(shí),會(huì)在成本和性能之間找一個(gè)平衡點(diǎn),有些廠家偏重成本,那就64比特甚至32比特,有些偏重性能,如真正的AI芯片,無一例外都是HBM的,成本都在1500美元以上。
常見汽車內(nèi)存性能與價(jià)格對(duì)比
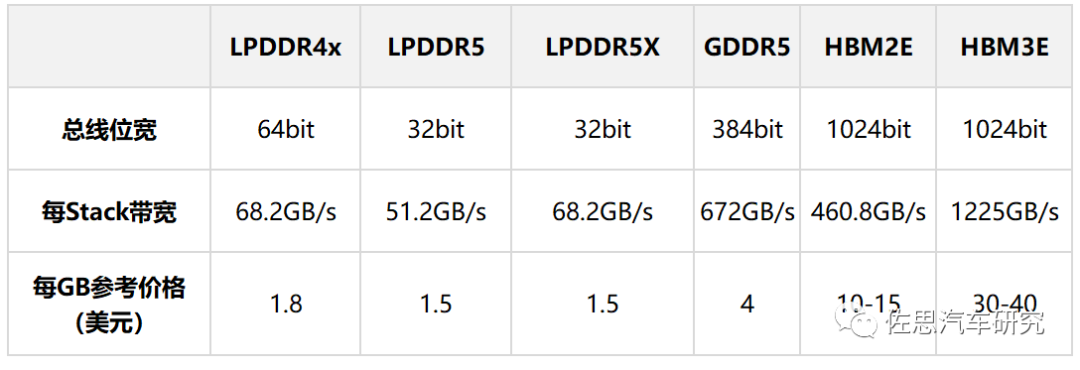
圖片來源:公開資料整理
上表為常見汽車內(nèi)存性能與價(jià)格對(duì)比,顯然,一分價(jià)錢一分貨。英偉達(dá)H100是HBM3的最大采購者,每GB的采購價(jià)格大約14美元。還有一點(diǎn)需要指出,目前沒有車規(guī)級(jí)GDDR6存儲(chǔ)芯片。
目前智能駕駛芯片除了百度和特斯拉,都采用了LPDDR。
歷代LPDDR的參數(shù)
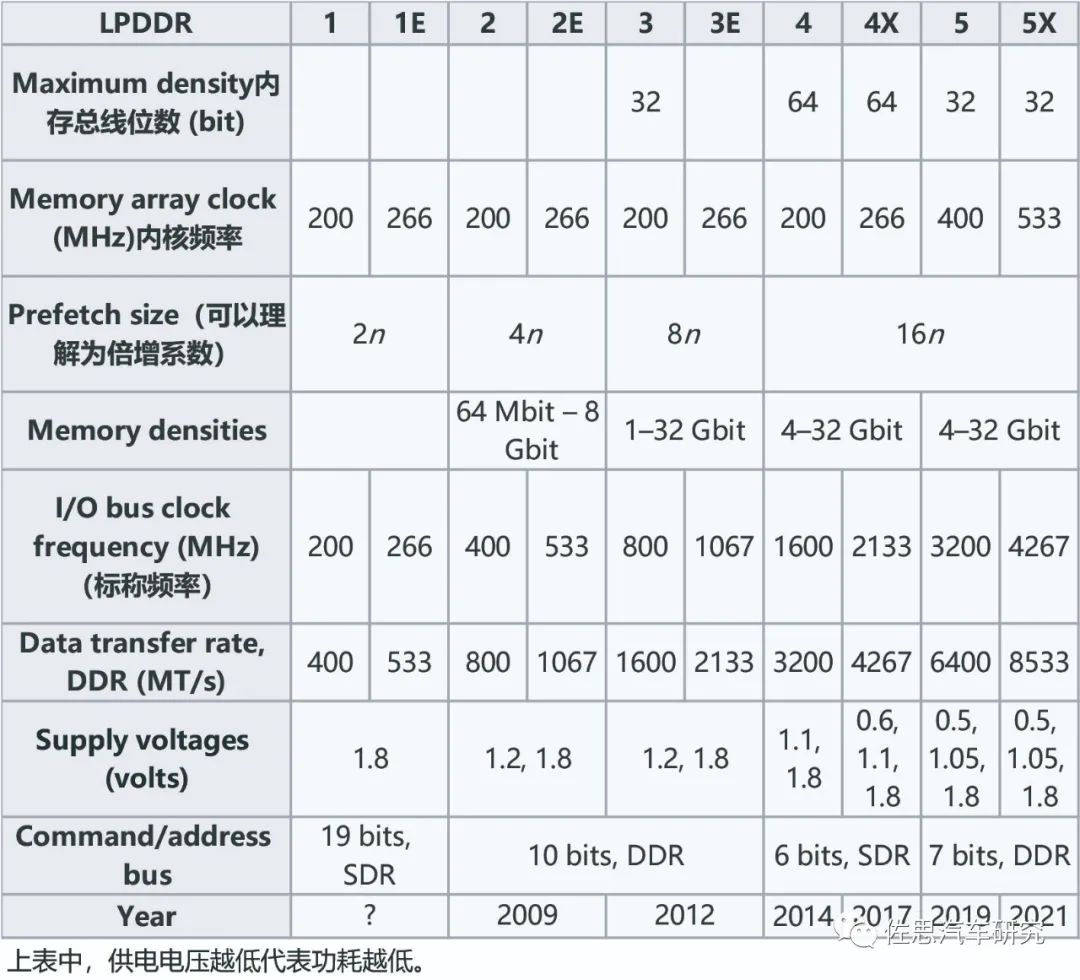
圖片來源:公開資料整理
存儲(chǔ)帶寬等于CPU的存儲(chǔ)位寬乘以存儲(chǔ)器的Datatransfer rate, DDR (MT/s)再除以8換算為大寫的GB,例如英偉達(dá)Orin其存儲(chǔ)位寬是256比特,支持LPDDR5,傳輸速率為6400MT/s,那么存儲(chǔ)帶寬為256*6400M/8=204.8GB/s,再比如特斯拉一代FSD,存儲(chǔ)位寬是128比特,支持LPDDR4,傳輸速率為3200MT/s,存儲(chǔ)帶寬就是128*3200M/8=51.2GB/s。
存儲(chǔ)帶寬如此重要的原因是Roof-line模型,Roof-lineModel 解決的,是“計(jì)算量為A且訪存量為B的模型在算力為C且?guī)挒镈的計(jì)算平臺(tái)所能達(dá)到的理論性能上限E是多少”這個(gè)問題。
模型計(jì)算量指的是輸入單個(gè)樣本(對(duì)于CNN而言就是一張圖像),模型進(jìn)行一次完整的前向傳播所發(fā)生的浮點(diǎn)運(yùn)算個(gè)數(shù),也即模型的時(shí)間復(fù)雜度,單位是FLOPS。訪存量:指的是輸入單個(gè)樣本,模型完成一次前向傳播過程中所發(fā)生的內(nèi)存交換總量,也即模型的空間復(fù)雜度。在理想情況下(即不考慮片上緩存),模型的訪存量就是模型各層權(quán)重參數(shù)的內(nèi)存占用(Kernel Mem)與每層所輸出的特征圖的內(nèi)存占用(Output Mem)之和。計(jì)算量除以訪存量就可以得到模型的計(jì)算強(qiáng)度I (Intensity),它表示此模型在計(jì)算過程中,每Byte內(nèi)存交換到底用于進(jìn)行多少次浮點(diǎn)運(yùn)算。單位是FLOP/Byte。模型在計(jì)算平臺(tái)上所能達(dá)到的每秒浮點(diǎn)運(yùn)算次數(shù)(理論值)。單位是 FLOP/s,即P。
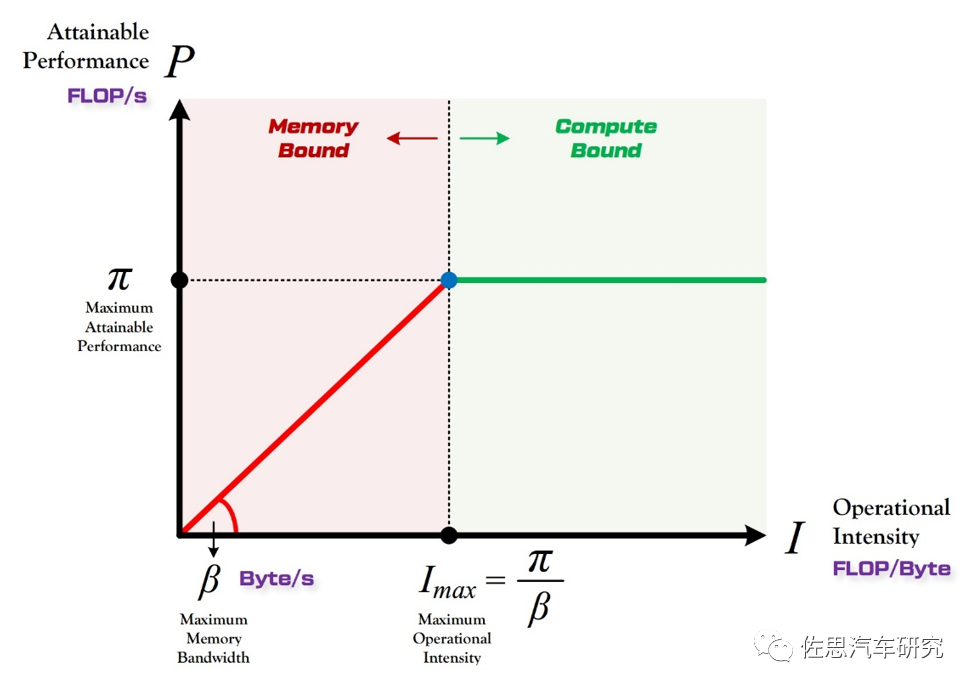
算力決定“屋頂”的高度(綠色線段),帶寬決定“房檐”的斜率(紅色線段)
模型計(jì)算的理論性能自然不可能超過其硬件的最大理論性能,如果有一個(gè)異常消耗算力的模型,其需要的算力超過了計(jì)算平臺(tái)的理論性能,那么計(jì)算平臺(tái)的利用率是100%,也就是紅色線段部分,這時(shí)的風(fēng)險(xiǎn)就是處理圖像的幀率或者說FPS會(huì)達(dá)不到目標(biāo)幀率,對(duì)智能駕駛來說,主流幀率是30FPS,低速智能駕駛可以再降低一點(diǎn),高速需要再升高一點(diǎn)。由于需要的算力太高,計(jì)算平臺(tái)滿負(fù)荷運(yùn)轉(zhuǎn)也無法適應(yīng),幀率會(huì)下降,此時(shí)高速行駛的話就會(huì)有風(fēng)險(xiǎn),一般來說,廠家不會(huì)推薦算力需求遠(yuǎn)超理論性能上限的模型。
在低于100%利用率的綠色線段部分,模型理論性能 P 的大小完全由計(jì)算平臺(tái)的帶寬上限(房檐的斜率)以及模型自身的計(jì)算強(qiáng)度 I (Intensity)所決定,因此這時(shí)候就稱模型處于 Memory-Bound 狀態(tài)。可見,在模型處于帶寬瓶頸區(qū)間的前提下,計(jì)算平臺(tái)的帶寬即房檐越陡,或者說模型的計(jì)算強(qiáng)度 I 越大,模型的理論性能 P 可呈線性增長(zhǎng)。斜率越低,意味著即使計(jì)算強(qiáng)度快速增加,計(jì)算平臺(tái)算力的增加還是很緩慢,計(jì)算平臺(tái)的利用率很低,比如計(jì)算平臺(tái)的理論算力是100TOPS,斜率很低,很高計(jì)算強(qiáng)度的模型利用率也可能不到50%,換句話說,存儲(chǔ)帶寬決定了計(jì)算平臺(tái)的性能利用率,因此存儲(chǔ)帶寬重要性絲毫不亞于算力,甚至高于算力。這也是為何特斯拉二代FSD排名第二的主要原因,GDDR6的帶寬相對(duì)LPDDR有壓倒性優(yōu)勢(shì)。
特斯拉第二代FSD

圖片來源:網(wǎng)絡(luò)
特斯拉第二代FSD采用了三星的7納米工藝,之所以用三星代工,主要可能還是價(jià)格和地理因素,三星代工的價(jià)格遠(yuǎn)低于臺(tái)積電,只有臺(tái)積電價(jià)格的一半左右,臺(tái)積電的亞利桑那廠效率低下,從2020年開工建設(shè),預(yù)計(jì)到2025年才能投產(chǎn),而三星的德克薩斯奧斯汀二代工廠僅用兩年就完工投產(chǎn),而特斯拉總部離奧斯汀也很近。第一代FSD使用三星的14納米工藝,WikiChip的數(shù)據(jù)顯示,三星7nm LPP HD高密度cell方案的晶體管密度在95.08 MTr/mm2,而HP高性能方案的晶體管密度則在77.01 MTr/mm2;三星14納米UHP方案的晶體管密度則在26.22MTr/mm2,HP方案晶體管密度則在32.94 MTr/mm2,基本上三星7納米是14納米密度的3倍以上,意味著特斯拉至少可以塞進(jìn)3倍多的MAC陣列,AI性能可以提升三倍,一代FSD的AI性能是73.7TOPS@INT8,3倍就是221.1,再像英偉達(dá)那樣搞個(gè)稀疏模型加速,算力數(shù)字可以再增長(zhǎng)一倍,加上二代FSD芯片面積明顯比一代要大,且NPU增加到3個(gè),因此估計(jì)算力在500TOPS上下。特斯拉二代FSD也大幅度加強(qiáng)了CPU,使用三星Exynos 20核心配置,這也說明CPU在智能駕駛中很重要。
安霸的CV3熟悉的人可能不多,其存儲(chǔ)帶寬支持最高的LPDDR5X,且是最高的256比特,采用三星的5納米工藝制造,目前得到了德國大陸汽車公司的支持。
安霸CV3-AD內(nèi)部框架圖
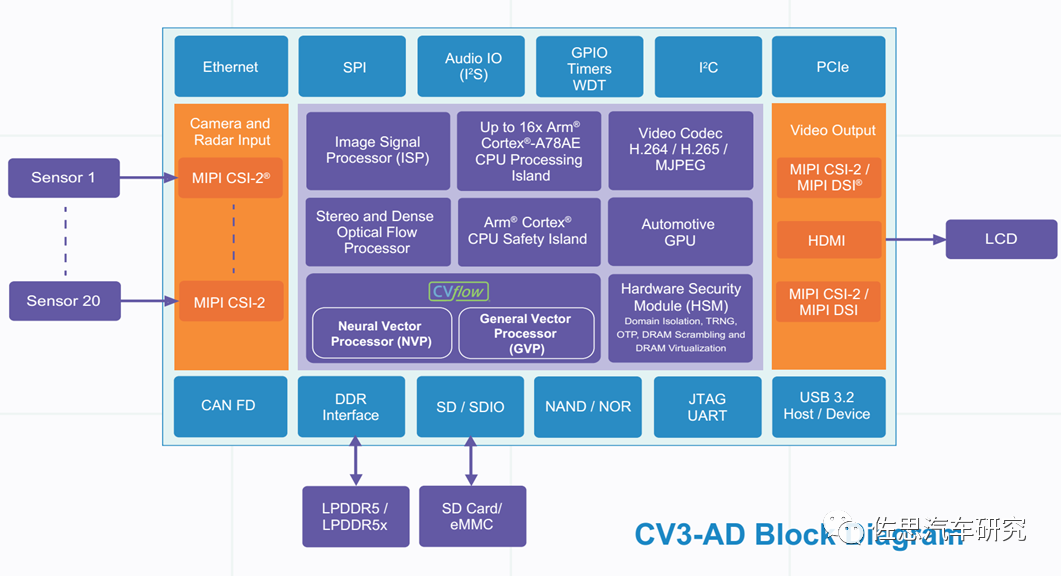
圖片來源:Ambarella
安霸CV3-AD最高包括了16核心的Coretex-A78AE,CPU算力也是極高。也通過了ASIL-B級(jí)認(rèn)證。AI算力方面是等效于500TOPS。英偉達(dá)的位寬是256比特,特斯拉和Mobileye大多是128比特,征程6未公布存儲(chǔ)信息。
百度的昆侖芯2很少人知曉,實(shí)際這不能算百度的,它是百度芯片部分獨(dú)立后的產(chǎn)物,公司全稱是昆侖芯(北京)科技有限公司,前身為百度智能芯片及架構(gòu)部,于2021年4月完成獨(dú)立融資,首輪估值約130億元。2022年11月29日,在百度Apollo Day技術(shù)開放日上,第二代昆侖芯在百度無人駕駛車輛RoboTaxi的駕駛系統(tǒng)上已經(jīng)做了完整的適配,在高階自動(dòng)駕駛系統(tǒng)中運(yùn)行正常。2011年,昆侖芯科技正式獨(dú)立,開始從事AI計(jì)算相關(guān)的工作,早期使用FPGA芯片來對(duì)AI進(jìn)行計(jì)算加速。2011-2015年之間,昆侖芯科技部署了超過5000片F(xiàn)PGA芯片用在百度數(shù)據(jù)中心,到了2017年累計(jì)部署超過12000片的FPGA芯片。并在2018年決定自研AI芯片,正式啟動(dòng)昆侖芯系列產(chǎn)品的研發(fā)和設(shè)計(jì)。2020年,第一代昆侖芯開始大規(guī)模地部署,2022年,第二代昆侖芯在數(shù)據(jù)中心、工業(yè)領(lǐng)域、自動(dòng)駕駛等領(lǐng)域大規(guī)模地部署和落地。第一代昆侖芯是14納米的人工智能芯片, 這款芯片采用了先進(jìn)的HBM內(nèi)存、2.5D的封裝,芯片剛量產(chǎn)就在百度數(shù)據(jù)中心里面部署了超過2萬片。一年后第二代昆侖芯量產(chǎn),采用了更先進(jìn)的7納米工藝、XPU第二代的架構(gòu),也是業(yè)界第一顆采用GDDR6高速顯存技術(shù)的AI芯片。昆侖芯科技正在研發(fā)更先進(jìn)的第三代AI芯片,針對(duì)高階自動(dòng)駕駛系統(tǒng),未來會(huì)考慮推出定制的車規(guī)高性能的SoC(系統(tǒng)級(jí)芯片)。
英偉達(dá)對(duì)存儲(chǔ)系統(tǒng)一向比較重視,全線都是最高的256比特。高通SA8650與座艙領(lǐng)域的SA8255非常近似,CPU和GPU基本完全相同,AI算力做了特別加強(qiáng),存儲(chǔ)位寬是比較少見的96比特,SA8650是取代上一代SA8540P的,主要是增加了針對(duì)功能安全的部分,增加了4個(gè)Cortex-R52內(nèi)核。Mobileye對(duì)成本異常重視,也從不公布其存儲(chǔ)帶寬和支持存儲(chǔ)類型,只能猜測(cè)。Xavier雖是早期產(chǎn)品,但存儲(chǔ)位寬是最高的256比特,所以排名很靠前。
審核編輯:劉清
-
控制器
+關(guān)注
關(guān)注
114文章
16972瀏覽量
182926 -
智能駕駛
+關(guān)注
關(guān)注
4文章
2776瀏覽量
49694 -
HBM
+關(guān)注
關(guān)注
1文章
408瀏覽量
15113 -
GPU芯片
+關(guān)注
關(guān)注
1文章
305瀏覽量
6122 -
LPDDR
+關(guān)注
關(guān)注
0文章
44瀏覽量
6536
原文標(biāo)題:智能駕駛芯片TOP20排名
文章出處:【微信號(hào):zuosiqiche,微信公眾號(hào):佐思汽車研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
魔視智能斬獲TOP合資品牌新定點(diǎn)項(xiàng)目
比克電池多款圓柱電池躋身全國出貨量TOP10

愛芯元智榮登2025中國IC設(shè)計(jì)Fabless100排行榜之TOP10 AI芯片公司
墨芯榮登2025中國IC設(shè)計(jì)Fabless100排行榜之TOP10 AI芯片公司
京東方榮登2025年度全球百強(qiáng)創(chuàng)新機(jī)構(gòu)榜單
云知聲榮登2024數(shù)字技術(shù)創(chuàng)新企業(yè)TOP20榜單
京東方位列2024 IFI專利授權(quán)排行榜全球第12位

北斗智聯(lián)榮獲2024年度自動(dòng)駕駛領(lǐng)域創(chuàng)新企業(yè)
普強(qiáng)榮獲2024智能客服企業(yè)TOP20
半導(dǎo)體IP無線連接解決方案提供商旋極星源入選2024未來之星·川商最具價(jià)值投資企業(yè)TOP20榜單

智能駕駛與自動(dòng)駕駛的關(guān)系
輝羲智能推出首款高階智能駕駛芯片光至R1
云知聲入選億歐智庫“2024中國生成式AI企業(yè)商業(yè)落地Top20榜單”
1454億元!最新全球MEMS廠商TOP 30排名公布,這5家中國公司殺入!(附全名單)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論