 1-2B參數規模大模型的使用心得
1-2B參數規模大模型的使用心得
來自:劉聰NLP
寫在前面
大模型時代,根據大模型縮放定律,大家通常都在追求模型的參數規模更大、訓練的數據更多,從而使得大模型涌現出更多的智能。但是,模型參數越大部署壓力就越大。即使有gptq、fastllm、vllm等推理加速方法,但如果GPU資源不夠也很難保證高并發。
那么如何在模型變小的同時,模型效果不明顯下降,在指定任務上也可以媲美大模型的效果呢?
Google前幾天發布的Gemini,在移動端采用1.8B參數模型面向低端手機,3.25B參數模型面向高端手機。
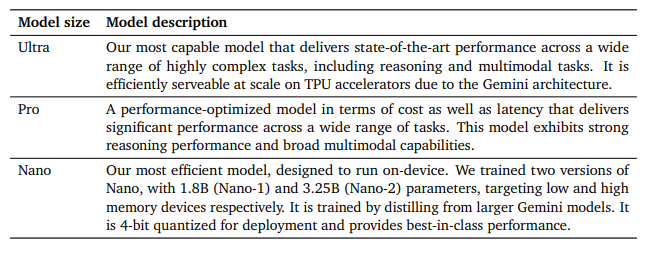
An overview of the Gemini 1.0 model family
而微軟最近也是推出了2.7B的Phi-2模型,評測效果絕群。
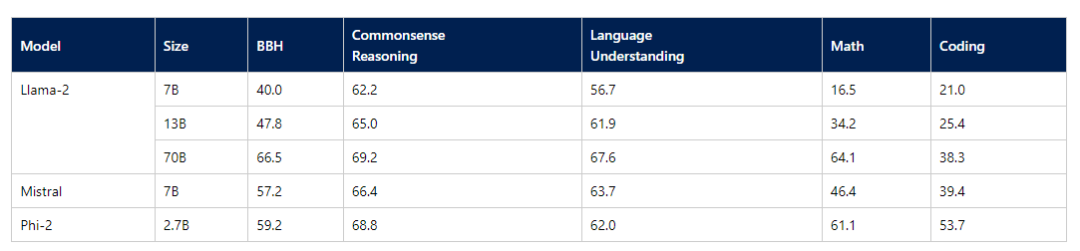
Averaged performance on grouped benchmarks compared to popular open-source SLMs

Comparison between Phi-2 and Gemini Nano 2 Model on Gemini’s reported benchmarks
恰好筆者前段時間也在研究1-2B參數量左右的模型,因此寫寫心得體會;并匯總了一下現在市面上開源的1-2B參數量的大模型。
這波反向操作,佛曰:不可說。
如何使大模型變小
模型壓縮的方法包括:用更多的數據硬訓練小模型、通過大模型對小模型進行蒸餾、通過大模型對小模型進行剪枝、對大模型進行量化、對大模型進行低秩分解。
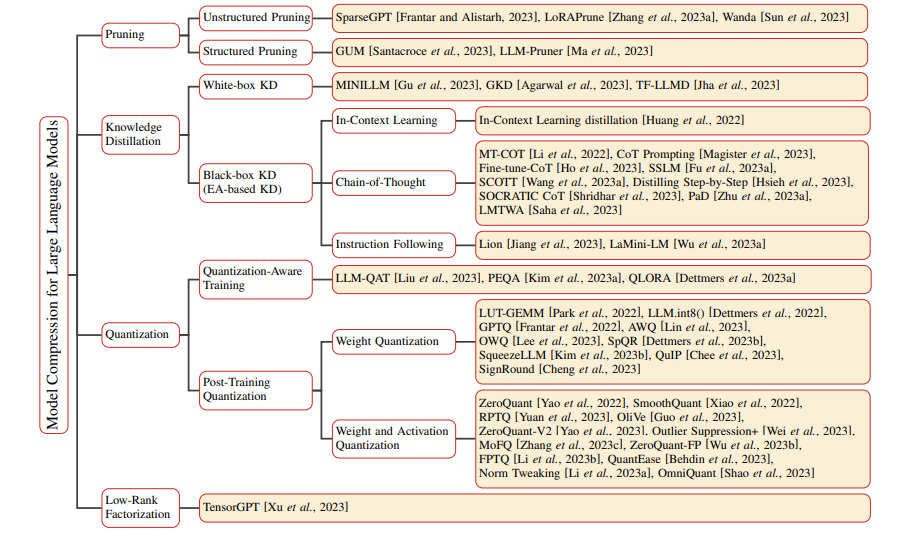
Taxonomy of Model Compression methods for Large Language Models
但是模型參數量變小還是硬訓練或蒸餾一個參數量小的模型,剪枝和量化只是對模型進行推理加速,本質上參數量沒有變少。
對于預訓練階段來說,往往需要更多的數據硬訓練。參數規模不夠,只能數據質量和數據數量來湊。

Textbooks Are All You Need
而在指令微調階段,往往是蒸餾更優秀的大模型,來讓小模型效果更好。利用GPT3.5、GPT4的數據直接指令微調是對閉源大模型蒸餾的方法之一,也是目前大家主流的做法。但也可以在蒸餾過程中,利用閉源大模型充當一個裁判來判別教師模型回答和學生模型回答的差異,讓學生模型向老師模型(閉源)進行反饋,重點是找到困難數據讓學生模型進行更好的學習。
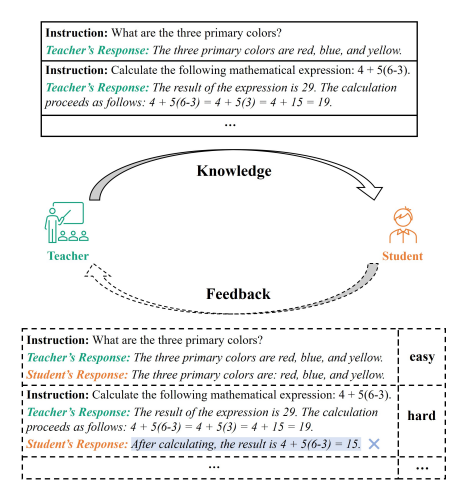
Lion: Adversarial Distillation of Proprietary Large Language Models
當然如果你本身擁有更大更好的大模型,那么就可以用標準的知識蒸餾來進行模型蒸餾,利用KL散度,對教師模型和學生模型輸出概率分布之間的差異進行訓練學習。
將更大模型的效果蒸餾到小模型上,會比硬訓練的效果要理想,但首先要有一個可獲取網絡各層logits的大&好&強的模型。
訓練1-2B參數規模使我痛并快樂
訓練1-2B模型讓我又找到了全量調參的快樂,之前受顯卡限制,都是Lora、QLora等方法訓練。
模型部署階段,再也不用為顯存發愁,老卡也輕輕松松進行模型部署。對于2B模型,Float32進行參數部署也就8G、Float16就需要4G,如果再做量化的話更小,甚至CPU部署速度也可以接受。
同等數據情況下,效果確實不如更大的模型。以Qwen1.8B和7B為例,在自己任務上指標差了7-10個點。
在個人任務上,通過增加數據,將訓練數據擴大2-4倍并提高數據質量之后,效果基本上可以媲美。
小模型在沒有定制優化的任務上,就一言難盡了,泛化能力等都遠不如更大的模型。
用了小模型之后,再也沒被吐槽過速度了。
主流1-2B參數規模的大模型匯總
共整理了14個1-2B參數規模的大模型,按照參數量從大到小排序,如下所示。
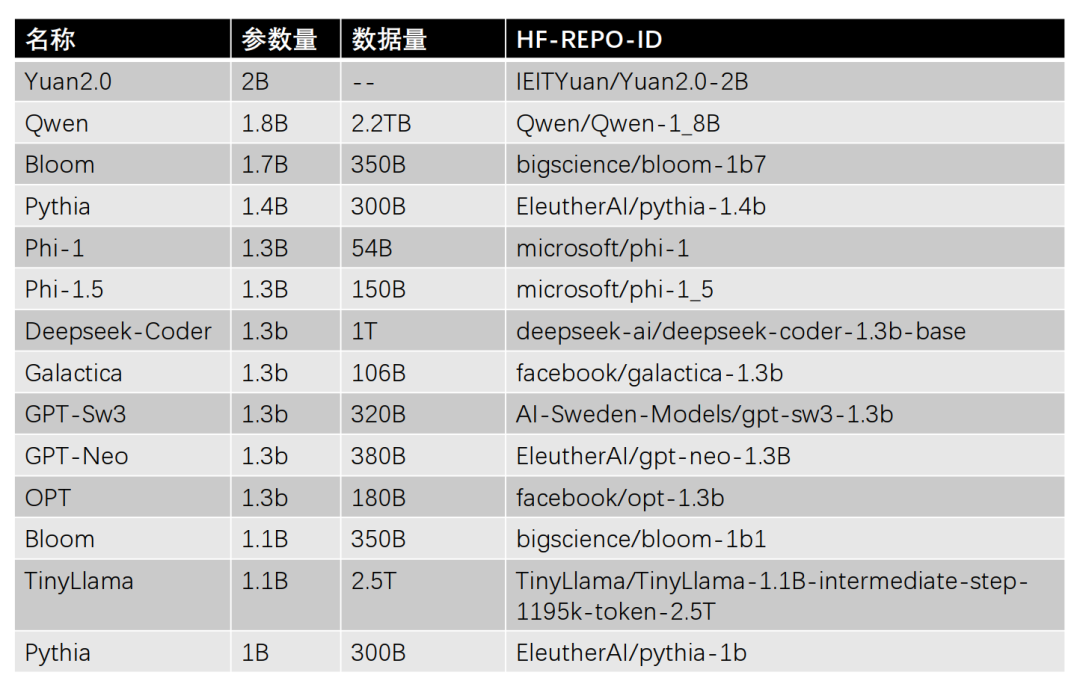
PS: HF訪問不了的小伙伴,可以看一下《大模型下載使我痛苦》。
Yuan2.0-2B
Yuan2.0-2B是浪潮發布的Yuan2.0大模型的2B版本,采用中英文的高質量資料,包括書籍、百科、論文等。Yuan2.0-2B模型層數24層,隱藏層維度2048,支持最大長度8192。
Qwen-1.8B
Qwen-1.8B是阿里發布的Qwen大模型的1.8B版本,采用2.2TB Token的數據進行預訓練,包含高質量中、英、多語言、代碼、數學等數據,涵蓋通用及專業領域的訓練語料。Yuan2.0-2B模型層數24層,隱藏層維度2048,支持最大長度8192,并且開源了對應的Chat模型。
Bloom-1.7B&1.1B
Bloom-1.7B&1.1B是Hugging Face牽頭組織的BigScience項目開源的Bloom大模型的1.7B和1.1B版本。訓練數據涉及46種自然語言和13種編程語言,共計1.6TB的文本數據。Bloom-1.7B模型層數24層,隱藏層維度2048,支持最大長度2048。Bloom-1.1B模型層數24層,隱藏層維度1536,支持最大長度2048。
Pythia-1.4B&1B
Pythia-1.4B&1B是EleutherAI開源的Pythia的1.4B和1B版本。主要使用300B Token的The Pile數據集進行訓練。Pythia-1.4B模型層數24層,隱藏層維度2048。Pythia-1B模型層數16層,隱藏層維度2048。
Phi-1&Phi-1.5
Phi-1&Phi-1.5是微軟開源的Phi大模型的兩個不同版本,均有1.3B參數,模型層數24層,隱藏層維度2048。Phi-1模型訓練54B Token的數據,而Phi-1.5模型訓練150B Token的數據。
Deepseek-Coder-1.3B
Deepseek-Coder-1.3B是深度求索發布開源的Deepseek-Coder的1.3B版本,采用1TB Token的數據進行預訓練,數據由87%的代碼和13%的中英文自然語言組成,模型層數24層,隱藏層維度2048。
Galactica-1.3b是MetaAI開源的Galactica大模型的1.3B版本,采用106B Token數據進行訓練,數據主要來自論文、參考資料、百科全書和其他科學來源等。模型層數24層,隱藏層維度2048。
GPT-Sw3-1.3B
GPT-Sw3-1.3B是AI Sweden開源的GPT-SW3大模型的1.3B版本,采用320B Token數據進行訓練,數據主要由瑞典語、挪威語、丹麥語、冰島語、英語和編程代碼數據集組成。模型層數24層,隱藏層維度2048。
GPT-Neo-1.3B
GPT-Neo-1.3B是EleutherAI開源的GPT-Neo大模型的1.3B版本,GPT-Neo模型主要為了復現的GPT-3模型,采用380B Token數據進行訓練,模型層數24層,隱藏層維度2048。
OPT-1.3B
OPT-1.3B模型是由MetaAI開源的OPT大模型的1.3B版本,采用180B Token數據進行訓練,模型層數24層,隱藏層維度2048。
TinyLlama-1.1B
TinyLlama模型是一個1.1B參數的Llama模型,旨在3TB Token的數據上進行訓練,目前訓練到2.5TB Token數據,模型層數22層,隱藏層維度2048。
寫到最后
如果領導非要部署大模型,但對效果要求沒有那么高,又沒有資源支持,那么選擇一個1-2B的模型也是不錯的呦。
審核編輯:湯梓紅
-
手機
+關注
關注
35文章
6934瀏覽量
159290 -
gpu
+關注
關注
28文章
4921瀏覽量
130812 -
參數
+關注
關注
11文章
1867瀏覽量
32913 -
開源
+關注
關注
3文章
3634瀏覽量
43584 -
大模型
+關注
關注
2文章
3062瀏覽量
3907
原文標題:1-2B參數規模大模型使用心得及模型匯總
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【MATLAB使用心得匯總——Tips6 】
NE555關于計數器的使用心得
TFT LCD使用心得
詳細談談TFT LCD 的使用心得
無線藍牙模塊CC2540使用心得
內核調試利器printk的使用心得

Aultium Designer 的使用心得和基本電路圖的搭建

智慧服裝工廠電子看板試用心得
開源大模型Falcon(獵鷹) 180B發布 1800億參數
HT for Web (Hightopo) 使用心得(5)- 動畫的實現






 工商網監
工商網監
評論