") 利用人工智能和機器人技術(shù)實現(xiàn)復(fù)雜的自動化任務(wù)!
利用人工智能和機器人技術(shù)實現(xiàn)復(fù)雜的自動化任務(wù)!
這篇mylangrobot項目由neka-nat創(chuàng)建,本文已獲得作者Shirokuma授權(quán)進行編輯和轉(zhuǎn)載。
https://twitter.com/neka_nat
GitHub-mylangrobot :GitHub - neka-nat/mylangrobot: Language instructions to mycobot using GPT-4V
引言
本項目創(chuàng)建了一個使用GPT-4V和myCobot的一個演示,演示機械臂簡單得到拾取操作,這個演示使用了一個名叫SoM(物體檢測對象)的方法,通過自然語言生成機器人動作。通俗點換一句話來說就是,機器接受自然語言,去尋找目標(biāo)然后讓機械臂進行抓取的一個案例。
本項目的亮點主要是GPT-4V的圖像處理和SoM物體檢測算法相結(jié)合,通過自然語言和機器交互實現(xiàn)機械臂運動。
軟件
SoM
Set of Mark(SoM)是一種用于增強大型語言模型的視覺理解能力。圖像經(jīng)過SoM處理之后能夠在圖像上添加一系列的標(biāo)記,這些標(biāo)記能夠被語言類模型識別和處理。這些標(biāo)記有助于模型更準(zhǔn)確的識別和理解圖像中的物體和內(nèi)容。
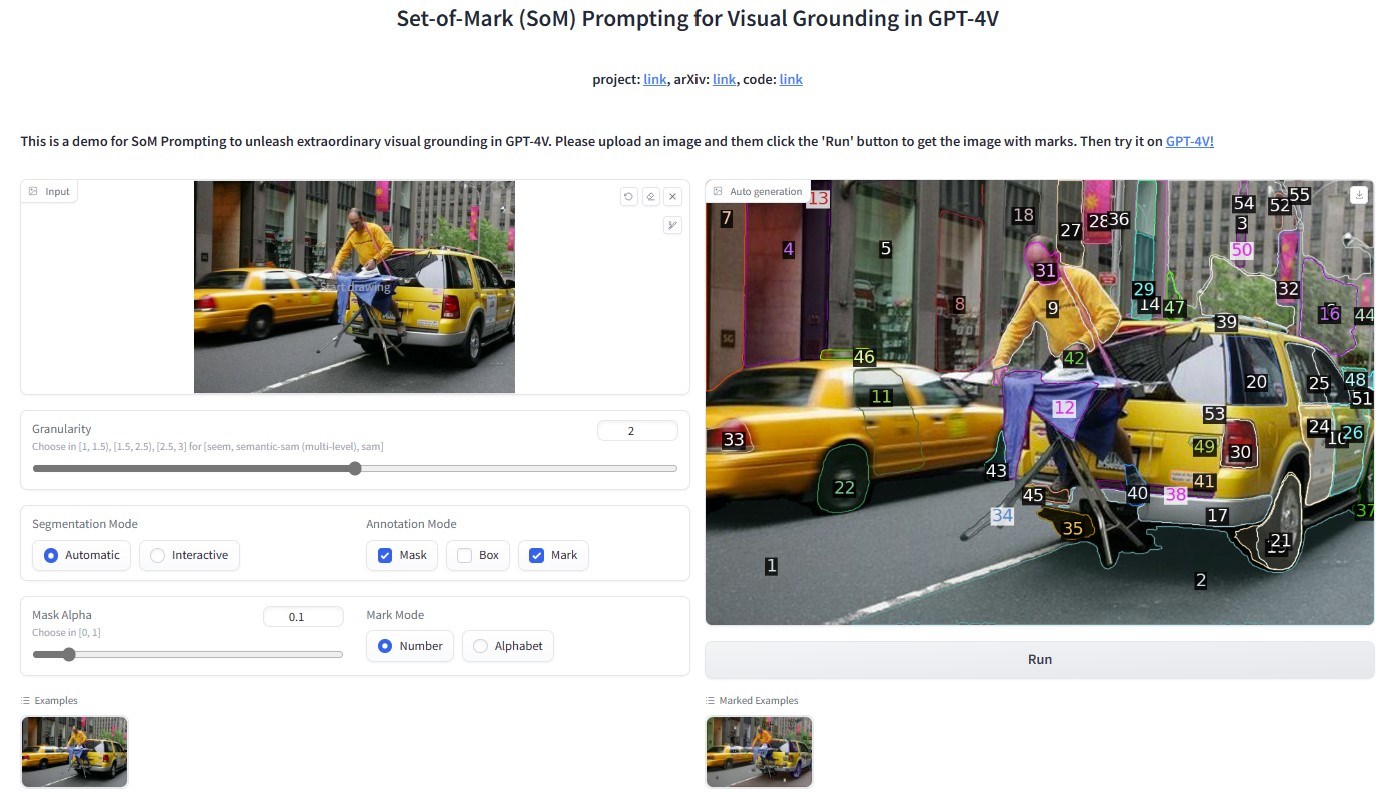
這使得語言模型能夠針對圖像中的元素進行更精準(zhǔn)的分析和描述,從而提高其在視覺任務(wù)上的表現(xiàn)。
GPT-4V
我們常聊的GPT是一個大預(yù)言模型,我們可以跟它進行對話聊天。在迭代新的版本的GPT-4V是一個大模型多模態(tài)語言模型,它不單單能處理文本信息,現(xiàn)在還能夠處理圖像信息。能夠?qū)D像理解,圖像生成,圖像描述的功能,這樣大模型結(jié)合GPT-4的強大自然語言處理能力和現(xiàn)金的圖像分析技術(shù),可以提供更高效和更準(zhǔn)確的視覺和語言綜合能力。
下面是OpenAI 提供的例子
簡要介紹:將一個視頻提供給GPT4,通過GPT-4V對圖像的處理,生成對視頻講解的內(nèi)容的過程。原文鏈接:Processing and narrating a video with GPT's visual capabilities and the TTS API | OpenAI Cookbook
User:
"These are frames from a video that I want to upload. Generate a compelling description that I can upload along with the video."

視頻中某一幀的圖像
#GPT-4V對圖像的描述處理
GPT4:
"
審核編輯 黃宇
-
機器人
+關(guān)注
關(guān)注
211文章
28737瀏覽量
208815 -
人工智能
+關(guān)注
關(guān)注
1796文章
47864瀏覽量
240716 -
GPT
+關(guān)注
關(guān)注
0文章
363瀏覽量
15543 -
機械臂
+關(guān)注
關(guān)注
12文章
527瀏覽量
24754
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論