") 使用愛(ài)芯派Pro開(kāi)發(fā)板部署人體姿態(tài)估計(jì)模型
使用愛(ài)芯派Pro開(kāi)發(fā)板部署人體姿態(tài)估計(jì)模型
在經(jīng)過(guò)之前對(duì)于開(kāi)發(fā)板的使用,以及通過(guò)幾個(gè)愛(ài)芯派官方給出的示例demo(mobilenet/yolov5)在開(kāi)發(fā)板上的部署之后,筆者也逐漸了解了愛(ài)芯派這塊開(kāi)發(fā)板利用其官方的推理引擎和pipeline部署模型的整體架構(gòu)。接下來(lái)就回到最開(kāi)始定的主線上了——人體姿態(tài)估計(jì)。這篇文章就是記錄對(duì)一些輕量化人體姿態(tài)估計(jì)模型的調(diào)研,和前期準(zhǔn)備。
01人體姿態(tài)估計(jì)任務(wù)介紹
其實(shí)姿態(tài)任務(wù)識(shí)別在很多生活場(chǎng)景都被使用到,這里給大家舉幾個(gè)例子:
虛擬主播:大家看到B站直播時(shí)的“皮套人”,通常通過(guò)一個(gè)2D live的形象展示一個(gè)動(dòng)漫形象,然后和主播同步動(dòng)作。這就是通過(guò)攝像頭識(shí)別當(dāng)前主播姿態(tài),再同步到虛擬形象上實(shí)現(xiàn)的。
VR游戲:大家可能用過(guò)像kinect這樣的設(shè)備,用于VR體感游戲。kinect同樣會(huì)識(shí)別當(dāng)前用戶(hù)的姿態(tài),然后用于VR交互中。
活動(dòng)識(shí)別:通過(guò)得到人體姿態(tài)后,再通過(guò)一個(gè)簡(jiǎn)單的分類(lèi)器,可以得到當(dāng)前的運(yùn)動(dòng)狀態(tài),如用戶(hù)是否跌倒(可以幫助監(jiān)控老年人),以及用戶(hù)當(dāng)前身體狀態(tài)等。
02人體姿態(tài)估計(jì)任務(wù)技術(shù)路線
其實(shí)人體姿態(tài)估計(jì)任務(wù)已經(jīng)有很久的年頭了,在當(dāng)前也算是很成熟的任務(wù)了。有興趣的朋友可以閱讀下這篇綜述:Deep Learning-Based Human Pose Estimation: A Survey (arxiv.org)。下面簡(jiǎn)單的對(duì)單人、多人人體姿態(tài)估計(jì)的技術(shù)路線做個(gè)小介紹:
03Openpose/lightweight openpose模型
首先要用到的是Openpose模型,這應(yīng)該是最有名的人體姿態(tài)估計(jì)的模型了,因?yàn)槭鞘讉€(gè)開(kāi)源的人體姿態(tài)估計(jì)框架。論文如下:1812.08008.pdf (arxiv.org)。如下圖所示,openpose能在多人情況下達(dá)到理想的識(shí)別效果。這里簡(jiǎn)單說(shuō)明一下openpose的原理:openpose就是原來(lái)的Bottom-up模型,會(huì)先生成針對(duì)關(guān)鍵點(diǎn)的heatmap圖像,來(lái)預(yù)測(cè)關(guān)鍵點(diǎn)的位置;同時(shí)也會(huì)PAF圖像,也叫做關(guān)節(jié)的親和力場(chǎng),哪些關(guān)節(jié)的親和力大,那么把它們劃分為同一個(gè)人。比如一個(gè)胳膊對(duì)應(yīng)兩個(gè)關(guān)節(jié)點(diǎn)。
Openpose存在的一個(gè)問(wèn)題便它其實(shí)是于比較大的模型,在GPU上運(yùn)行速度也只是勉強(qiáng)實(shí)時(shí)。為了部署在端側(cè),使用較低算力的設(shè)備,我們需要進(jìn)一步將其輕量化,也就是lightweight openpose項(xiàng)目。這個(gè)主要針對(duì)Openpose模型做一些改進(jìn),參數(shù)量下降為15% ,但是性能缺相差無(wú)幾(精度降低1%)。這里不細(xì)講了,有興趣的朋友可以看這篇文章:輕量級(jí)OpenPose, Lightweight OpenPose
針對(duì)其部署,筆者使用了一些開(kāi)源的項(xiàng)目后,發(fā)現(xiàn)如下的項(xiàng)目比較好用,就先用其觀察模型的效果:
git clone https://github.com/Hzzone/pytorch-openpose.git
(左右移動(dòng)查看全部?jī)?nèi)容)
在其body.py里面可以簡(jiǎn)單的寫(xiě)一段代碼輸出onnx文件觀察網(wǎng)絡(luò)結(jié)構(gòu):
class Body(object):
def __init__(self, model_path):
self.model = bodypose_model()
if torch.cuda.is_available():
self.model = self.model.cuda()
model_dict = util.transfer(self.model, torch.load(model_path))
self.model.load_state_dict(model_dict)
self.model.eval()
dummy_input = torch.randn(1, 3, 368, 368).cuda()
torch.onnx.export(self.model, dummy_input, "model/openpose_lightweight_body.onnx")
(左右移動(dòng)查看全部?jī)?nèi)容)
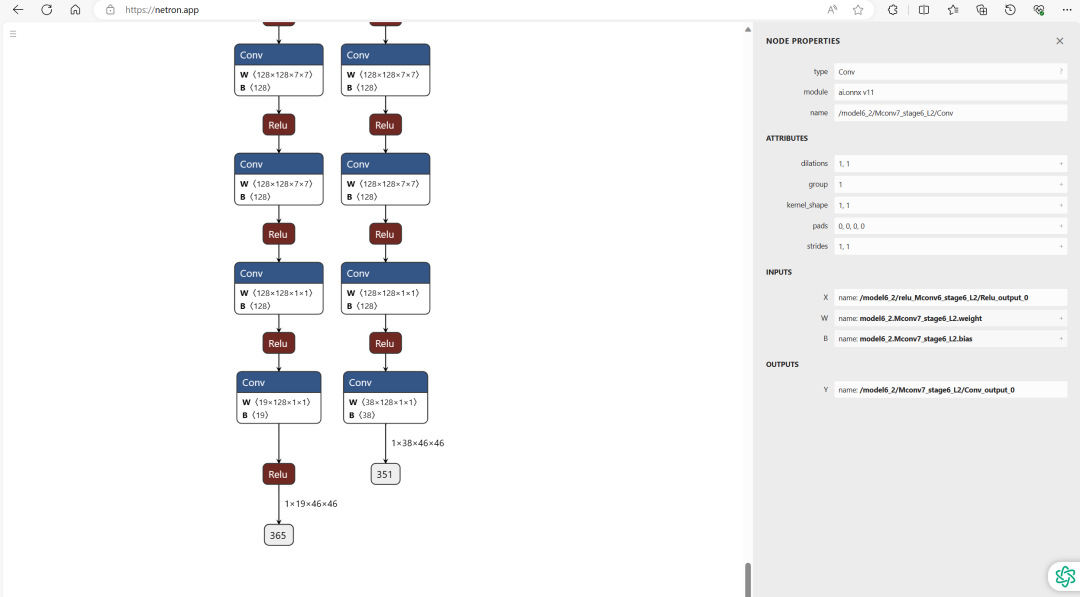
Openpose模型最終會(huì)輸出了兩個(gè)特征圖heat_map和paf_map,shape分別為(height,width,19)和(height,width,38),其中width、height分別為輸入圖片的寬高/8,其實(shí)是由于最開(kāi)始會(huì)通過(guò)一個(gè)VGG網(wǎng)絡(luò)提取特征,得到輸入圖片的寬高/8的特征圖。19表示coco數(shù)據(jù)集的關(guān)節(jié)種類(lèi)個(gè)數(shù)18(即一個(gè)人體的所有關(guān)節(jié)點(diǎn))+1個(gè)背景類(lèi)別,38表示由這18個(gè)關(guān)節(jié)點(diǎn)構(gòu)成的肢體的部分親和力場(chǎng)(每個(gè)肢體由兩個(gè)關(guān)節(jié)連接組成)。如下圖所示,把導(dǎo)出來(lái)的onnx文件放到netron網(wǎng)站可以看到其具體結(jié)構(gòu)。這里可以看到輸出的shape,也方便我們部署的要求。
04Movenet
除了Openpose外,筆者還有一個(gè)選型,就是谷歌的輕量級(jí)人體姿態(tài)估計(jì)模型MoveNet。它是更近的一個(gè)輕量級(jí)人體姿態(tài)估計(jì)模型,但是一個(gè)缺點(diǎn)是它沒(méi)有論文,也沒(méi)有官方代碼,雖然有開(kāi)源的tfjs模型還有tflite模型,但是也只能通過(guò)觀察模型結(jié)構(gòu)去反推。
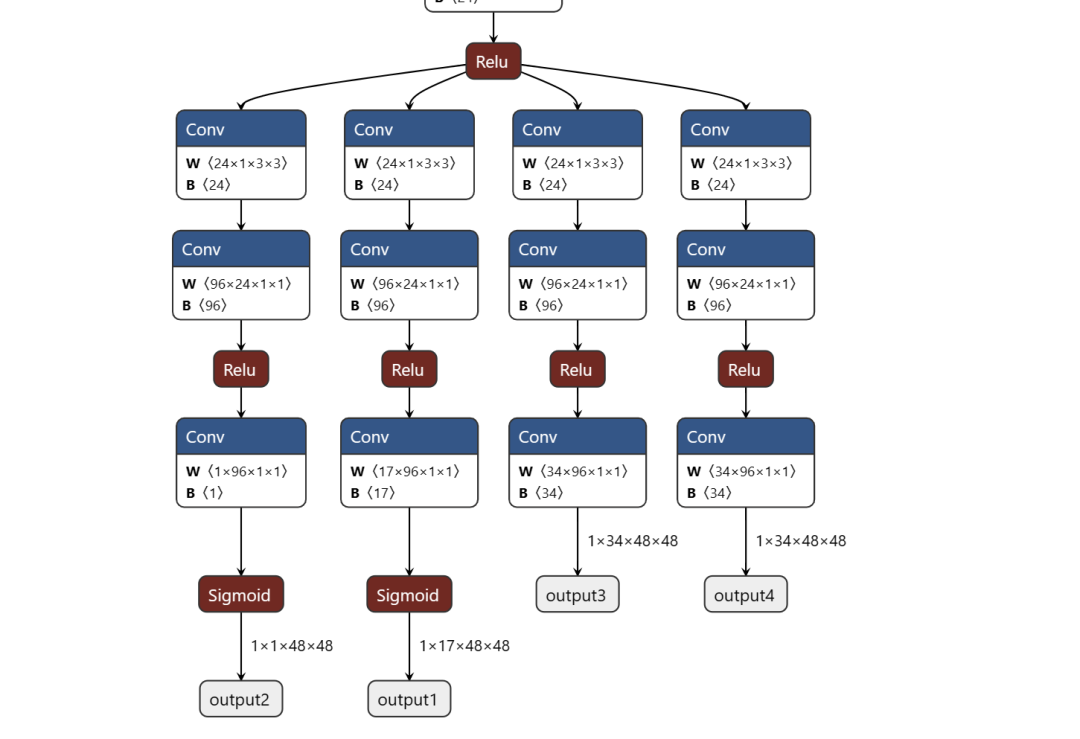
movenent的介紹在這個(gè)網(wǎng)站:Next-Generation Pose Detection with MoveNet and TensorFlow.js — The TensorFlow Blog ,通過(guò)對(duì)其學(xué)習(xí),以及利用官方模型轉(zhuǎn)換到onnx模型,打開(kāi)到netron網(wǎng)站觀察其結(jié)構(gòu),可以發(fā)現(xiàn)其有四個(gè)輸出,分別對(duì)應(yīng)預(yù)測(cè)人體實(shí)例的幾何中、預(yù)測(cè)人體的全部關(guān)鍵點(diǎn)集、 預(yù)測(cè)所有關(guān)鍵點(diǎn)的位置的熱力場(chǎng)、以及預(yù)測(cè)關(guān)鍵點(diǎn)2D偏移場(chǎng),也就是每個(gè)關(guān)鍵點(diǎn)精確子像素位置的局部偏移。這與Openpose不同,但是有了更精細(xì)話的結(jié)果。
同樣為了復(fù)刻movenet網(wǎng)絡(luò)結(jié)構(gòu),筆者選擇參照如下的項(xiàng)目進(jìn)行實(shí)現(xiàn)。
git clone https://github.com/fire717/movenet.pytorch.git
(左右移動(dòng)查看全部?jī)?nèi)容)
后續(xù)筆者先嘗試將openpose/lightweight openpose部署在板子上,再?lài)L試對(duì)movenent進(jìn)行進(jìn)一步的優(yōu)化。
審核編輯:湯梓紅
-
gpu
+關(guān)注
關(guān)注
28文章
4919瀏覽量
130766 -
開(kāi)發(fā)板
+關(guān)注
關(guān)注
25文章
5572瀏覽量
102931 -
模型
+關(guān)注
關(guān)注
1文章
3499瀏覽量
50092 -
vr
+關(guān)注
關(guān)注
34文章
9668瀏覽量
152220 -
愛(ài)芯派
+關(guān)注
關(guān)注
0文章
3瀏覽量
145
原文標(biāo)題:如何用愛(ài)芯派 Pro 開(kāi)發(fā)板來(lái)部署人體姿態(tài)估計(jì)模型
文章出處:【微信號(hào):gh_9b9470648b3c,微信公眾號(hào):電子發(fā)燒友論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】+ 圖像分割和填充的Demo測(cè)試
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】人體姿態(tài)估計(jì)模型部署前期準(zhǔn)備
【愛(ài)芯派?Pro?開(kāi)發(fā)板試用體驗(yàn)】CPU性能測(cè)試,與樹(shù)莓派4B對(duì)比
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】人體姿態(tài)估計(jì)模型部署后期嘗試
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】人體姿態(tài)估計(jì)模型部署后期嘗試
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】開(kāi)箱報(bào)告
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】+開(kāi)箱初次體驗(yàn)
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】開(kāi)箱報(bào)告
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】開(kāi)箱報(bào)告 + 資料準(zhǔn)備
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】篇一:開(kāi)箱篇
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】yolov8模型轉(zhuǎn)換
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】開(kāi)箱測(cè)試
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】模型部署(以mobilenetV2為例)
【愛(ài)芯派 Pro 開(kāi)發(fā)板試用體驗(yàn)】部署愛(ài)芯派官方Y(jié)OLOV5模型
在AI愛(ài)克斯開(kāi)發(fā)板上用OpenVINO?加速YOLOv8分類(lèi)模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論