 機器學習怎么進入人工智能
機器學習怎么進入人工智能
人工智能(Artificial Intelligence,AI)是一門涉及計算機、工程、數學、哲學和認知科學等多個領域的交叉學科,旨在構建智能化計算機系統,使之能夠自主感知、理解、學習和決策。如今,人工智能已成為一個熱門領域,涉及到多個行業和領域,例如語音識別、機器翻譯、圖像識別等。
在編程中進行人工智能的關鍵是使用機器學習算法,這是一類基于樣本數據和模型訓練來進行預測和判斷的算法。下面將介紹使用機器學習算法進行人工智能編程的步驟和技術。

1. 數據收集和預處理
數據是進行機器學習的關鍵之一。在進行人工智能編程之前,需要從各種數據源中收集數據。數據可以來自許多來源,例如互聯網、社交媒體、傳感器等。一些常見的數據類型包括文本、圖片、音頻等。
然而,很多數據可能是不完整的、不準確的、格式不統一的。因此,在進行機器學習之前,需要對數據進行預處理和清理。預處理步驟通常包括數據清洗、去重、歸一化等,以及一些特定的操作,如圖像處理和文本分詞等。
2. 特征提取和選擇
特征是機器學習的另一個重要組成部分,它們用于描述數據,從而便于模型進行預測或分類。特征通常是一個向量或一個矩陣。
在進行特征提取時,需要將原始數據轉換為向量或矩陣形式。例如圖像可以表示為一個像素矩陣,文本可以表示為一個詞袋模型。特征工程的目的是從原始數據中提取有用的特征,在進行模型訓練和預測時能夠提高準確性。
特征選擇是指從所有特征中選擇最重要的特征,排除不重要的特征,以提高模型的準確性。這可以通過常見的方法,如相關性分析和主成分分析等來實現。
3. 選擇和訓練模型
在選擇模型時,需要考慮數據的特點、預測或分類的目標、甚至硬件資源等因素。一些常見的機器學習模型包括決策樹、支持向量機(SVM)、神經網絡和隨機森林等。
訓練模型的過程是指模型根據輸入數據進行自我調整和優化的過程。這個步驟通常涉及到一些優化算法,如梯度下降、遺傳算法等。訓練過程的時間和效率都與數據量、模型復雜度以及硬件性能等因素有關。
4. 模型調整和測試
模型調整是指調整模型參數以提高訓練結果的過程。這可以通過更改模型算法、參數和訓練數據的數量或質量等來實現。
模型測試是指通過測試集來測試模型的準確性和可靠性,以及檢驗模型的泛化能力。測試結果應該反映模型在新數據上的表現。
總之,在編程中進行人工智能需要掌握上述的基本步驟和技術。此外,還需要對數據理解和預測的領域有足夠的知識,例如對文本分析需要有語言學的知識。需要注意的是,機器學習是一個迭代的過程,需要反復測試、調整和優化模型,以達到更高的精度和準確性。
機器學習如何獲得人工智能機器學習是實現人工智能的關鍵技術之一。
通過機器學習,計算機可以通過學習和分析數據來獲得知識和經驗,并自動進行決策和預測。
機器學習如何實現人工智能呢?機器學習是如何進行的機器學習是通過訓練模型,讓計算機從數據中學習并提取有用的信息和規律。
收集并準備數據,然后選擇適當的機器學習算法,如監督學習、無監督學習或強化學習。
將數據輸入到模型中進行訓練和優化,不斷調整模型的參數和結構,以使其能夠更準確地進行預測和決策。
機器學習如何應用于人工智能機器學習可以應用于各種領域的人工智能應用中。
在自然語言處理領域,通過機器學習可以實現語音識別、機器翻譯和自動問答等功能。
在計算機視覺領域,機器學習可以用于圖像識別、物體檢測和人臉識別等任務。
機器學習還可以應用于智能推薦系統、金融風險預測和醫療診斷等領域。
機器學習中的神經網絡是如何實現人工智能的神經網絡是一種重要的機器學習算法,模擬人類大腦的神經元網絡結構。
通過神經網絡,機器可以進行復雜的模式識別和決策。
神經網絡的訓練是通過反向傳播算法來實現的,即通過不斷調整網絡中的權重和偏置,使得網絡的輸出與期望的輸出盡可能接近。
機器學習的未來發展方向是什么機器學習和人工智能仍然處于快速發展階段,未來有許多潛在的發展方向。
其中包括深度學習的進一步發展,增強學習的應用拓展,以及機器學習與其他技術的結合,如大數據、云計算和物聯網等。
還需要解決機器學習中的一些挑戰,如數據隱私和安全性問題,以實現更加可靠和可信的人工智能系統。
通過機器學習,人工智能得以實現。
機器學習通過訓練模型,讓計算機從數據中學習并提取有用的信息和規律。
它可以應用于各種領域的人工智能應用中,并通過神經網絡等算法來實現復雜的模式識別和決策。
學習基本編程知識:在開始使用Python實現人工智能之前,需要掌握基本的編程知識,例如變量、數據類型、條件語句、循環語句、函數和對象等。
了解人工智能概念和算法:學習人工智能領域的基本概念和算法,例如機器學習、深度學習、神經網絡、決策樹和聚類等。
選擇適當的庫和框架:選擇適當的Python庫和框架可以加快開發過程,例如NumPy、Pandas、Matplotlib、Scikit-learn、TensorFlow和PyTorch等。
數據預處理:對數據進行清洗、轉換、縮放和標準化等預處理操作,以便用于機器學習算法。
建立模型:使用Python庫和框架構建機器學習模型或深度學習模型。
訓練模型:使用Python編寫代碼,對模型進行訓練,并調整模型參數以提高模型性能。
測試模型:測試模型性能,使用測試數據評估模型的準確性、精確性、召回率和F1分數等指標。
部署模型:將模型部署到生產環境中,以便進行實時預測和推理。
總的來說,Python是一種非常適合實現人工智能的編程語言,具有豐富的庫和框架,可以簡化開發過程并提高效率。
圖像分類:使用Python和深度學習庫如TensorFlow和PyTorch,可以構建圖像分類模型,用于將圖像分類為不同的類別。
自然語言處理:Python中有許多自然語言處理工具和庫,如NLTK和spaCy。使用這些工具,可以構建文本分類器、語言模型和對話系統等應用程序。
機器學習:Python是一種非常流行的機器學習編程語言。使用庫如Scikit-learn和Keras,可以構建分類、回歸、聚類和推薦系統等應用程序。
數據分析:Python也是一種非常流行的數據分析語言。使用Pandas和NumPy等庫,可以處理和分析大量數據集,構建預測模型和數據可視化應用程序。
智能游戲:使用Python和Pygame等庫,可以構建智能游戲,如智能象棋、掃雷和五子棋等。
以上是一些使用Python實現人工智能的示例,但實際上Python的應用領域非常廣泛,可以應用于許多其他領域,如計算機視覺、語音識別、推薦系統、物聯網等。
數據收集和處理:這是任何機器學習項目的第一步,需要獲取和準備用于訓練和測試模型的數據。Python的pandas庫和numpy庫提供了強大的數據處理功能,可以用來清洗、轉換和分析數據集。
特征選擇:特征是指在訓練數據中用來預測目標變量的屬性。特征選擇是選擇最相關的特征,以獲得更好的預測性能。Python的sklearn庫提供了許多特征選擇算法,包括基于統計學的算法和基于機器學習的算法。
模型選擇和訓練:選擇一個適合您的問題的機器學習模型,并使用訓練數據對其進行訓練。Python的sklearn庫包含了大量的機器學習算法,包括決策樹、隨機森林、支持向量機、神經網絡等。
模型評估:評估模型的性能是非常重要的。Python的sklearn庫提供了多種模型評估指標,例如準確率、精確率、召回率、F1分數等等。您可以使用這些指標來比較不同模型之間的性能。
模型調優:如果您的模型性能不夠好,可以考慮調整模型參數以獲得更好的性能。Python的sklearn庫提供了許多用于調整模型參數的工具,包括網格搜索、隨機搜索等。
預測:一旦您擁有一個訓練好的模型,就可以使用它來進行預測了。Python的sklearn庫提供了用于預測新數據的函數,您可以使用它來進行預測并獲取預測結果。
-
人工智能
+關注
關注
1804文章
48497瀏覽量
245253 -
機器學習
+關注
關注
66文章
8481瀏覽量
133904
發布評論請先 登錄
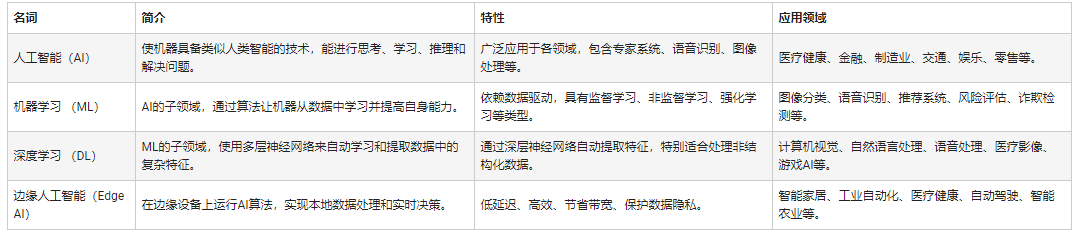
人工智能和機器學習以及Edge AI的概念與應用
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
如何在低功耗MCU上實現人工智能和機器學習
嵌入式和人工智能究竟是什么關系?
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論