 淺談存內計算生態環境搭建以及軟件開發
淺談存內計算生態環境搭建以及軟件開發
在當今數據驅動的商業世界中,能夠快速處理和分析大量數據的能力變得越來越重要。而存內計算開發環境在此領域發揮其關鍵作用。存內計算環境利用內存(RAM)而非傳統的磁盤存儲來加速數據處理,提供了一個高效和靈活的平臺。這種環境的核心優勢在于其能夠提供極高的數據處理速度和效率,使得數據可以直接在內存中被快速訪問和處理,這對于需要實時數據處理和分析的應用來說至關重要。
在了解存內計算開發環境的核心優勢和作用后,我們現在將轉向實現存內計算技術潛力的關鍵:存內計算生態環境的搭建以及軟件開發的具體細節。它們不僅為存內計算應用的開發和運行提供必要的基礎,也是實現高效數據處理和分析的關鍵組成部分。
一.存內計算環境搭建
(一)背景介紹
存內計算環境搭建是一種高效的數據處理方法,它涉及在計算機內存中配置和管理數據及應用程序,以提高數據處理和計算的速度。存內計算環境的搭建對于高效軟件的開發至關重要。首先,它提供了快速的數據訪問和處理能力,從而顯著減少了數據處理時間,這對于實時數據分析和在線事務處理尤為重要。此外,存內計算支持大數據和復雜應用的處理,滿足了現代軟件開發對于處理大量數據的需求。同時,它還能簡化應用架構,提高開發效率。
此外,在搭建存內計算環境時,關鍵的硬件和軟件是不可或缺的。硬件方面,需要足夠的RAM來存儲數據集和支持計算過程。軟件方面,則涉及選擇支持存內計算的數據庫和應用平臺,如SAP HANA、Apache Spark等。不僅如此,還需制定有效的數據管理策略,實施性能優化措施,并考慮安全性與數據備份方案,以及潛在的集群及分布式計算的布局。
(二)研究現狀
存內計算環境搭建的主流方法和策略包括集成處理器技術、數據管理和流程優化等。存內計算環境的搭建重點關注存儲設備內部的集成計算能力,這通常通過在存儲設備中嵌入微處理器或定制硬件來實現。這些處理器可以直接在數據存儲的位置進行數據處理任務,大大減少了數據在存儲單元和中央處理單元之間的移動,提高了數據處理的速度和效率。其次,在軟件層面,存內計算環境需要配備能夠支持這種硬件架構的操作系統和文件系統,例如GenStore(圖1),其是專門為基因組序列分析設計的存內處理系統[1]。這些系統需要智能地管理數據,將計算密集型的任務分配到最合適的存儲設備上。此外,還需開發專門的算法和工具,以優化數據的存儲和檢索過程,確保計算任務的高效執行。
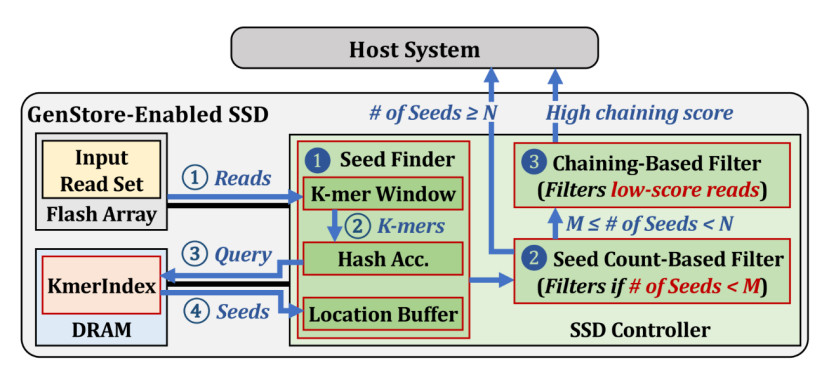
圖1 GenStore的概述
在實用工具和平臺方面,市場上已經有多種支持存內計算的產品和解決方案。例如,某些高性能固態硬盤(SSD)已經集成了額外的處理能力,能夠在設備級別進行數據處理。同時,一些軟件提供商也開發了專門的工具和平臺,以支持存內計算,使得用戶可以更容易地實現和管理這種計算模型。例如,在大數據分析領域,某些企業利用存內計算來處理大規模的數據集,通過在存儲設備內部進行初步的數據處理,降低了對傳統CPU的依賴,加快了整個數據分析過程。
(三)環境搭建對軟件開發的影響
搭建存內計算環境對軟件開發的影響是深遠的,尤其在提升軟件的性能和效率方面。
首先,存內計算環境的出現改變了數據處理的傳統模式,將更多的計算任務從中央處理器轉移到存儲設備中。這要求軟件開發者重新思考數據處理和計算任務的分布方式。在存內計算環境中,開發者需要設計能夠在存儲設備上有效運行的算法和程序,同時也要考慮如何高效地利用存儲設備內部的處理器和資源。
此外,在存內計算環境中,軟件開發者還需考慮數據在存儲設備中的布局。合理的數據布局可以減少數據訪問的延遲,并充分利用存儲設備的內部帶寬。這些考慮不僅涉及到軟件本身的編碼,還包括對操作系統、文件系統等底層支持的優化。
綜上,存內計算環境的搭建不僅促使硬件技術的創新,也推動了軟件開發方法的變革。在這種環境中,軟件性能和效率的提升依賴于開發者對存儲設備計算能力的深入理解和有效利用。因此,軟件和硬件之間的緊密協作成為了實現最佳性能的關鍵。
二.存內計算軟件開發
(一)研究背景
存內計算提供了在數據處理和分析中更高的速度和效率,這對于需要處理大量數據的應用尤其重要。然而,這也為軟件開發人員帶來了新的挑戰,例如需要深入了解存內計算的工作原理,以及如何優化代碼以充分利用其性能優勢。同時,開發人員還需考慮如何在保持軟件靈活性的同時,提高與存內計算硬件的兼容性。
為了更好地適應存內計算,開發者們正在探索新的編程模型和語言。這些新工具和語言旨在簡化存內計算的編程過程,同時提供強大的功能來支持復雜的數據處理任務。例如,一些研究正在探討如何將常見的編程概念和結構(如循環和并行處理)適配到存內計算架構中。
(二)研究現狀
隨著存內計算硬件的發展,軟件開發社區正在尋找方法將這種新技術集成到傳統的軟件開發工作流程中。例如,流行的開源框架Apache Spark已經開始探索如何利用存內計算技術來提高數據處理的效率。此外,TensorFlow等機器學習框架也在調整其算法,以更好地利用存內計算的高速數據處理能力。
Apache Spark是一種廣泛使用的大數據處理框架,它的主要特點是基于內存計算,能夠快速處理大量數據。近年來,Spark團隊開始探索如何將存內計算技術整合到其框架中,以進一步提高數據處理效率。Apache Spark通過優化其內存管理和數據處理算法來適應存內計算架構。這意味著Spark能夠更有效地利用基于CIM技術的硬件,減少數據在內存和CPU之間的移動,從而提高整體的數據處理速度。為了充分利用存內計算的高速處理能力,Spark正在調整其核心算法,例如對RDD(彈性分布式數據集)的操作和Spark SQL的查詢優化。
圖2 Apache Spark 框架
TensorFlow是一個廣泛應用于機器學習和深度學習的框架。隨著存內計算技術的發展,TensorFlow也在調整其算法以適應這一新的計算模式,例如通過優化其底層數據處理和神經網絡訓練算法來利用存內計算的優勢。另一方面,可以減少在訓練深度學習模型時數據在GPU和內存之間的傳輸,從而加快訓練過程TensorFlow開發人員正在增強其框架的靈活性,以支持不同類型的存內計算硬件。這包括改進對異構計算資源的支持,使得TensorFlow能夠更有效地在搭載CIM技術的系統上運行。
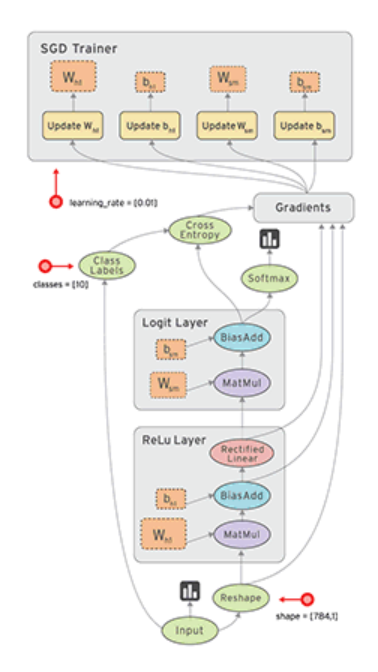
圖3 TensorFlow的計算圖
通過開發人員的努力,Apache Spark和TensorFlow不僅能夠提高數據處理和機器學習模型訓練的速度,還能在能耗和性能方面取得顯著改進。這些進展在軟件開發領域展示了存內計算技術的巨大潛力,尤其是在處理大數據和復雜計算任務時。隨著存內計算技術的不斷發展和成熟,預計這些框架將在未來的軟件開發中發揮更重要的作用。
(三)軟件開發對CIM架構的要求
在軟件開發領域,特別是對于數據密集型應用,對CIM架構的需求日益增長。首先,CIM架構必須能夠高效處理大數據量,這意味著它需要具備高吞吐量和低延遲的能力。為了提升軟件開發的效率,CIM架構還需提供靈活的編程接口和強大的軟件支持,讓開發者可以輕松地利用其特性。隨著數據需求的增長,CIM架構的設計應具備良好的可擴展性,以應對不斷增加的計算資源需求。此外,在移動和邊緣計算設備中,CIM架構還需在維持高性能的同時,優化能源效率,以滿足現代計算環境的需求。
總結與展望
存內計算環境的搭建和軟件開發正處于一個快速發展的時期,隨著技術的進步,這兩個領域都展現出了顯著的潛力和多樣化的發展趨勢。存內計算環境通過利用內存(RAM)加速數據處理,提供了一個高效和靈活的平臺,特別適合實時數據分析和在線事務處理。這一環境的優勢在于其極高的數據處理速度和效率,顯著減少了數據處理時間,并支持大數據和復雜應用的處理。在軟件開發領域,Apache Spark和TensorFlow等框架正在適應存內計算架構,優化內存管理和數據處理算法,以更高效地利用基于CIM技術的硬件。這些框架的調整不僅加快了數據處理和機器學習模型訓練的速度,還在能耗和性能方面取得了顯著改進。
未來展望中,存內計算技術預計將繼續發展,尤其在與軟件開發的協同方面。預計這一領域將見證更高效、靈活且可擴展的存內計算環境,并且軟件開發將更深入地利用其優勢,以支持更復雜和數據密集的應用。同時,安全性將成為未來發展的一個重要考慮因素。總之,存內計算和軟件開發領域預計將繼續緊密合作,推動數據處理和分析技術的進步。
資料來源
Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa,etc. 2022. GenStore: a high-performance in-storage processing system for genome sequence analysis. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS '22). Association for Computing Machinery, New York, NY, USA, 635–654.
審核編輯 黃宇
-
RAM
+關注
關注
8文章
1391瀏覽量
116976 -
內存
+關注
關注
8文章
3115瀏覽量
75061 -
存內計算
+關注
關注
0文章
32瀏覽量
1486
發布評論請先 登錄







 工商網監
工商網監
評論