 探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

隨著信息技術的迅猛發展,存算一體技術逐漸成為計算領域的研究熱點。在這一領域,基于SRAM(靜態隨機存取存儲器)和MRAM(磁性隨機存取存儲器)的存內計算和存算一體架構日益受到重視,為計算性能和能效帶來了新的可能性。本文將深入探討這兩種技術的原理、優勢及其在不同領域的應用,旨在為讀者提供對存算一體技術發展趨勢的全面了解。
一.基于 SRAM 的存內計算
在信息技術的不斷發展中,SRAM存內邏輯計算技術日益成為研究的焦點。自2016年Jeloka等人提出了基于SRAM的存內邏輯計算以來,這一領域取得了長足的進步。該技術不僅僅局限于邏輯運算,還應用于神經網絡的硬件加速,為計算領域帶來了全新的可能性。
SRAM的邏輯運算是通過激活同一列的多個存儲單元來實現的。這些存儲單元的字線被同時激活,通過靈敏放大器感測位線電壓,得到存儲單元存儲比特的邏輯運算結果。在增加額外的邏輯門后,SRAM可以實現邏輯或非和邏輯與非運算。與傳統的SRAM陣列相比,新的陣列具有更高的密度和更低的功耗,為存內計算提供了更廣闊的發展空間。
在這一領域的持續探索中,研究者們提出了更多創新的SRAM存內計算架構。例如,Aga等人提出了一種新的存內計算架構,通過添加解碼器和使用單端靈敏放大器實現了邏輯異或運算。而Dong等人則提出了一種4+2T的SRAM單元,相比傳統的6T SRAM單元具有更好的噪聲容限。
針對傳統6T SRAM單元存在的讀寫干擾和存儲內容翻轉等問題,研究者們提出了8T和10T SRAM單元。Agrawal等人則提出了使用8T SRAM單元和8+T SRAM單元的解耦讀寫路徑,成功實現了存內布爾運算,包括邏輯與非、邏輯或非、邏輯異或等邏輯運算。相比于6T SRAM單元,8T SRAM單元提高了數據的吞吐量和處理速度,為計算性能帶來了明顯的提升。

一些研究者還探索了SRAM單元與算術電路協同的架構,例如Rajput等人提出了一種8T SRAM單元與算術電路協同的架構,具有更高的能量利用率和讀取裕量。
基于SRAM的存內邏輯計算技術不斷創新,為計算領域帶來了更高的性能和更低的功耗。隨著這一技術的不斷發展,我們有理由期待它在未來的計算應用中發揮更加重要的作用。
二.基于 SRAM 的存內計算在神經網絡的應用
近年來,深度學習技術在神經網絡領域蓬勃發展,但由于常規訓練通常依賴于高功耗的CPU或GPU,因此功耗問題成為制約其應用的重要因素。然而,隨著超大規模集成電路制造業的飛速進步,嵌入式系統逐漸成為研究的熱點。嵌入式系統以其低功耗和小占用面積的特點,成為解決目標檢測等問題的理想選擇。
在嵌入式神經形態處理系統的發展中,基于憶阻器的神經形態計算體系架構引起了廣泛關注。多種基于憶阻器的神經形態計算體系架構相繼被提出。例如,Sun等人提出了一種基于憶阻器的神經形態計算架構,實現了三層全并行卷積神經網絡(FP-CNN)。而在此基礎上,Sun等人將其作為基本計算單元提出了一種級聯神經網絡體系架構。Yakopcic等人則提出了一種基于憶阻器的卷積神經網絡,利用多個憶阻器交叉陣列實現。
盡管這些方法在網絡架構方面取得了顯著成效,但當憶阻器陣列存在低良率問題時,其性能卻會受到明顯影響。為此,本文提出了一種基于憶阻器的神經形態計算方法,結合了提高憶阻器陣列乘累加計算準確率的校準方法和可減少訓練誤差的原位訓練方法,從而能夠提高網絡在低良率陣列中的識別率。
這一方法的提出將為嵌入式神經計算帶來全新的可能性,不僅能夠提高計算準確率,還能在較低的功耗下實現更為穩健的性能表現。隨著該方法的進一步研究和應用,我們有信心在嵌入式神經計算領域邁出更加堅實的步伐,為智能計算的未來鋪平道路。
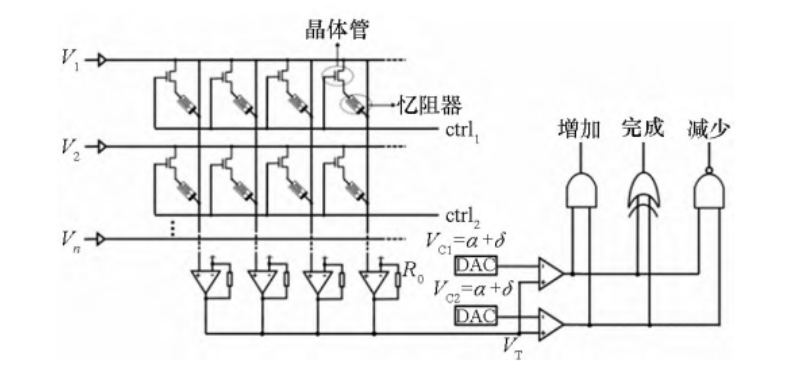
一種編程憶阻器交叉陣列的電路如下圖:
2.1 神經網絡算法(BNN)
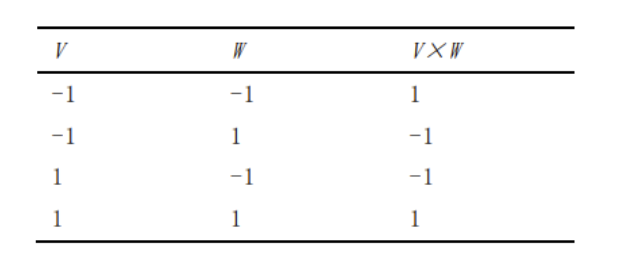
神經網絡算法中,乘加計算是最為頻繁的操作之一。為了應對計算需求與功耗之間的平衡,研究者們提出了二值化神經網絡(BNN),將輸入和權重進行二值化,限定為1或-1。這種二值化使得基于SRAM的乘法運算可以被視為邏輯同或運算。然而,使用一位二值權重可能會導致較大的精度損失,因此研究者們將注意力轉向了并行計算,以實現多位權重運算。
一種被提出的并行計算結構包括WL開關矩陣用于激活多行字線,閃存ADC的多電平檢測器(MLSA)以及生成基準電壓的參考生成器。另一種基于6T SRAM的雙拆分結構實現了完全并行的乘積和累加計算,取得了顯著的效果。該架構不僅可以實現全連接層的計算時間達到2.3 ns,而且能效最高可達55.8 TOPS/W。然而,這種架構使用了大量的晶體管,導致了較大的面積。
乘法真值表如下。
Nguyen等人提出了用于DNN存內計算的10T SRAM,并設計了整體架構,成功映射了LeNet-5手寫數字識別網絡。該架構支持完全并行的乘加計算,并且實現了4位權重、4位輸入、8位輸出的乘加操作。另外,Su等人提出了可用于2到8位運算的雙向轉置6T SRAM,支持神經網絡推理和訓練的過程。
此外,為了進一步降低功耗,研究者們還研究了稀疏性處理。Han等人提出了一種基于8T SRAM的DNN加速器,不僅具有前向傳播和后向傳播功能,還具有稀疏性處理功能。通過只存儲非零值及其地址的方式來過濾零值,使得不必要的計算被跳過,最終實現了功耗上的降低。
在國內外,許多優秀團隊也為SRAM的存內計算做出了貢獻。他們提出了各種創新的方法和結構,如無乘法函數逼近器、更高線性度和吞吐量的SRAM單元、無ADC的動態SRAM架構等,以加速神經網絡的計算過程并降低功耗。這些研究成果為神經網絡計算的進一步優化提供了重要的參考和啟示。
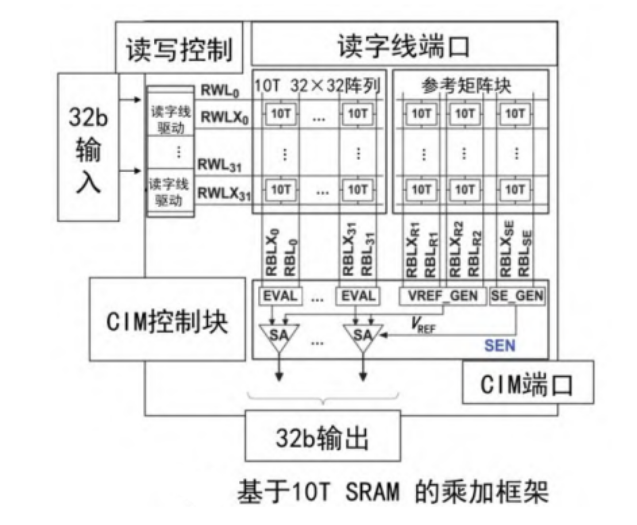
如下圖所示,這種架構通過在一個32×32的10T SRAM陣列中輸入32個輸入向量,將輸入向量與權重矩陣做乘法運算。在同一列上的所有SRAM單元的位線上的電流被求和并轉換成模擬電壓,在敏感放大器模塊中將此模擬電壓與參考電壓進行對比,生成數字信號的輸出。參考電壓由3列10T SRAM組成的參考陣列塊生成,同時此參考陣列塊還產生檢測放大器SA的檢測使能信號。通過這樣的方式,完成了矩陣和向量之間的乘加運算。
這種架構是通過28納米CMOS工藝實現的,具有高能效和高吞吐量的優勢。這意味著它在進行神經網絡計算時能夠以更低的功耗和更高的效率完成任務,從而提高了整個系統的性能表現。
三.基于 MRAM 的存算一體
基于MRAM(磁性隨機存取存儲器)的存算一體(MRAM-in-Memory Computing)是一種新型的計算模式,它結合了內存和計算的功能,利用MRAM的非易失性和快速讀寫特性,在存儲器內部進行計算操作,從而提高計算效率和能源利用率。
MRAM作為一種新型的存儲技術,具有快速的讀/寫速度、低功耗和非易失性等優點。這些特性使得MRAM非常適合用于存算一體的應用。在存算一體中,計算任務可以直接在MRAM中進行,而無需將數據從存儲器傳輸到CPU進行處理,從而減少了數據傳輸的延遲和能耗。
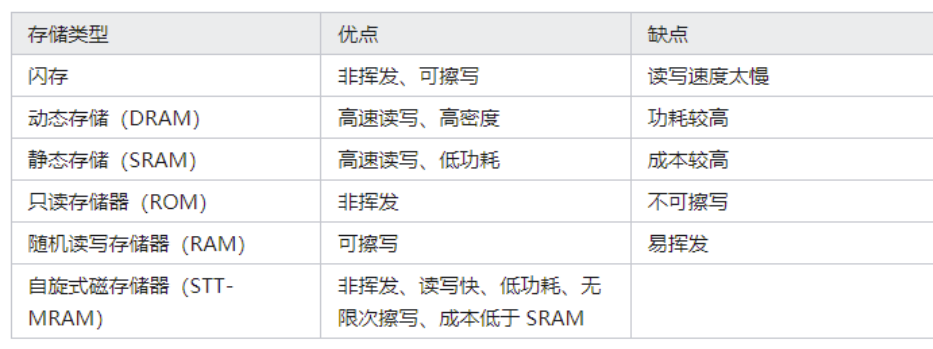
MRAM 與其他類型存儲器相比具有明顯優勢。下表列出幾種不同類型的存儲器優缺點比較:
通過將計算操作與存儲操作結合在一起,存算一體架構可以實現更高效的數據處理。例如,對于機器學習應用,可以在MRAM中進行矩陣乘法等計算密集型操作,而無需將數據移動到CPU或GPU。這樣可以大大減少數據傳輸的時間和能耗,提高系統的整體性能。
此外,存算一體還可以降低硬件系統的復雜性,減少了CPU和存儲器之間的通信帶寬需求,簡化了系統架構,降低了成本。
自旋芯片被認為具有SRAM的高速度、DRAM的高密度以及Flash的非易失性等優點,這一觀點得到了中國科學院院士、南京大學物理系教授和博士生導師的認同。此外,自旋芯片的抗輻射性也備受軍方青睞,使其原則上可以取代當前各類存儲器,成為未來的通用存儲器。
魯汶儀器的一位員工介紹稱,目前,MRAM主要在軍工、大數據高性能存儲等領域有一些應用。然而,隨著工藝的成熟和成本的降低,MRAM有望取代DRAM。
然而歷史上在DRAM和Flash的發展過程中,一直有人認為還有其他存儲芯片技術可以取代它們,但都沒有成功。趙巍勝認為,DRAM和Flash將隨著新技術的引入不斷發展。例如,DRAM技術因為EUV光刻機的使用而得以進步。目前,MRAM在特定應用場景下已經有了一定的市場份額,如ToT、車載、航空航天等領域。然而,未來MRAM很有可能向新的消費級市場發起沖擊。
四.SRAM 的存內計算和于 MRAM 的存算一體探討
SRAM的存內計算和基于MRAM的存算一體是兩種不同的計算模式,它們各自有著獨特的特點和優勢。
SRAM的存內計算:
工作原理:SRAM的存內計算利用存儲單元的邏輯運算功能,通過激活同一列的多個存儲單元來實現邏輯運算。
優勢:
高密度和低功耗:相比傳統的SRAM陣列,新的SRAM存內計算架構具有更高的密度和更低的功耗,提供了更廣闊的發展空間。
邏輯運算功能:SRAM存儲單元具有邏輯運算功能,可以實現邏輯與非、邏輯或非、邏輯異或等邏輯運算。
創新:研究者們提出了各種創新的SRAM存內計算架構,如8T和10T SRAM單元,以及解耦讀寫路徑等,進一步提高了計算性能和能效。
基于MRAM的存算一體:
工作原理:基于MRAM的存算一體將計算和存儲功能結合在一起,利用MRAM的快速讀/寫速度和非易失性,在存儲器內部進行計算操作。
優勢:
減少數據傳輸:由于計算任務可以直接在MRAM中進行,無需將數據傳輸到CPU或GPU,因此可以減少數據傳輸的延遲和能耗。
降低系統復雜性:存算一體可以降低硬件系統的復雜性,簡化系統架構,降低成本。
應用前景:MRAM作為一種新型存儲技術,在軍工、大數據高性能存儲等領域已經有了一些應用,并有望取代DRAM。
對比:
工作原理差異:SRAM的存內計算主要利用存儲單元的邏輯運算功能,而基于MRAM的存算一體則是將計算和存儲功能集成在MRAM中。
優勢重點不同:SRAM存內計算注重于提高計算性能和能效,而基于MRAM的存算一體則注重于減少數據傳輸延遲和降低系統復雜性。
應用領域不同:SRAM存內計算主要應用于邏輯計算和神經網絡硬件加速,而基于MRAM的存算一體則更多應用于軍工、大數據高性能存儲等領域。
兩者各有特點,適用于不同的場景和應用需求。SRAM的存內計算更適用于需要高性能邏輯計算和神經網絡加速的場景,而基于MRAM的存算一體則更適用于減少數據傳輸延遲和簡化系統架構的場景。
五.總結
本文深入探討了基于SRAM和MRAM的存算一體技術在計算領域的應用和發展。首先,介紹了基于SRAM的存內邏輯計算技術,包括其原理、優勢以及在神經網絡領域的應用。其次,詳細討論了基于MRAM的存算一體技術,包括其工作原理、優勢以及在軍工和大數據存儲領域的應用。最后,對比了SRAM的存內計算和基于MRAM的存算一體技術的差異,包括工作原理、優勢重點和應用領域等方面。
在全文中,強調了這兩種技術在提高計算性能、降低能耗、簡化系統架構等方面的重要作用,展望了它們在未來的計算應用中的潛力和前景。同時,對于不同場景下的適用性和優勢進行了詳細的分析和比較,為讀者提供了深入了解存內計算技術的參考。
參考文獻
DRAM時代即將到來,泛林集團這樣構想3D DRAM的未來架構
3D DRAM Is Coming. Here’s a Possible Way to Build It.Benjamin Vincent
3D堆疊DRAM Cache的建模以及功耗優化關鍵技術研究
存內計算概述
中國科學技術大學
應用于憶阻器陣列存內計算的低延時低能耗新型感知放大器
基于存算一體集成芯片的大模型專用硬件架構
高能效高安全新興計算芯片:現狀、挑戰與展望 54.01(2024):34-47.
校準方法和存內訓練相結合的憶阻器神經形態計算方法
Survey of In-Memory Computing Technology Based on SRAM and Non-Volatile Memory
審核編輯 黃宇
-
存儲器
+關注
關注
38文章
7651瀏覽量
167389 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103606 -
sram
+關注
關注
6文章
786瀏覽量
115957 -
MRAM
+關注
關注
1文章
236瀏覽量
32293 -
存內計算
+關注
關注
0文章
33瀏覽量
1519
發布評論請先 登錄
知存科技再推存算一體芯片,用AI技術推動助聽器智能化

知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
?什么是存內計算
2023年存算一體是芯片設計的技術趨勢

直播預約 |開源芯片系列講座第24期:SRAM存算一體:賦能高能效RISC-V計算

開源芯片系列講座第24期:基于SRAM存算的高效計算架構





 工商網監
工商網監
評論