") 借助NVIDIA Aerial CUDA增強(qiáng)5G/6G的DU性能和工作負(fù)載整合
借助NVIDIA Aerial CUDA增強(qiáng)5G/6G的DU性能和工作負(fù)載整合

Aerial CUDA 加速無線接入網(wǎng) (RAN)可加速電信工作負(fù)載,使用 CPU、GPU 和 DPU 在云原生加速計算平臺上提供更高水平的頻譜效率 (SE)。
適用于 Aerial 的 NVIDIA MGX 系統(tǒng)基于先進(jìn)的 NVIDIA Grace Hopper 超級芯片和 NVIDIA Bluefield-3 DPU 構(gòu)建,旨在加速 5G 端到端無線網(wǎng)絡(luò):
虛擬化 RAN (vRAN)分布式單元(DU)
集中式單元(CU)
用戶平面函數(shù)(UPF)
vRouter
網(wǎng)絡(luò)安全
這種全棧加速方法可提供領(lǐng)先的性能和頻譜效率,同時降低總擁有成本(TCO),并為更好的資產(chǎn)回報(ROA)開辟新的盈利機(jī)會。NVIDIA 6G 研究云平臺中提供了 Aerial CUDA 加速的 RAN 軟件堆棧。
電信公司已投入數(shù)十億資金購買 4G/5G 頻譜,預(yù)計他們將再次投入購買 6G 頻譜,以滿足日益增長的移動用戶需求。
該生態(tài)系統(tǒng)包括芯片制造商、OEM 和獨(dú)立軟件供應(yīng)商(ISV),可提供具有不同性能特征的解決方案。這些解決方案主要基于專用硬件,例如專用集成電路(ASIC)或系統(tǒng)級芯片(SoC),用于處理計算密集型第 1 層(L1)和第 2 層(L2)功能。
挑戰(zhàn)在于如何在 RAN 解決方案中實(shí)施算法的復(fù)雜程度與實(shí)施成本和功耗之間取得平衡。
電信公司希望能夠分解 RAN 工作負(fù)載的硬件和軟件,使其能夠在云基礎(chǔ)設(shè)施上構(gòu)建網(wǎng)絡(luò),從而為軟件創(chuàng)新、新的差異化服務(wù)、控制硬件生命周期管理以及提高總體擁有成本(TCO)開辟可能性。
vRAN 展示了商用現(xiàn)成(COTS)平臺運(yùn)行 RAN 分布式單元(DU)工作負(fù)載的能力。但是,由于計算性能差距,需要加速,從而實(shí)現(xiàn)某些工作負(fù)載的固定功能加速,例如前向糾錯(FEC)。
在本文中,我們將討論用于 DU 工作負(fù)載加速的 Aerial CUDA 加速 RAN 的進(jìn)展,詳細(xì)介紹所使用的算法和預(yù)期收益、所使用的底層硬件,以及它整合 DU、集中式單元(CU)和核心等電信工作負(fù)載以及使用多租戶功能托管創(chuàng)收工作負(fù)載的能力。最后,我們將探討電信公司有望實(shí)現(xiàn)的總體 TCO 和 ROA 優(yōu)勢。
Aerial CUDA 加速 RAN
NVIDIA Aerial RAN 將適用于 5G 和 AI 框架的 Aerial 軟件與 NVIDIA 加速計算平臺相結(jié)合,幫助電信公司降低 TCO 并實(shí)現(xiàn)基礎(chǔ)設(shè)施盈利。
Aerial RAN 具有以下主要特性:
一個軟件定義、可擴(kuò)展、模塊化、高度可編程和云原生的框架,無需任何固定函數(shù)加速器。它使生態(tài)系統(tǒng)能夠靈活地采用其商業(yè)產(chǎn)品所需的模塊。
DU L1、DU L2+、CU、UPF 和其他網(wǎng)絡(luò)功能的全棧加速,可實(shí)現(xiàn)工作負(fù)載整合,從而更大限度地提高性能和頻譜效率,實(shí)現(xiàn)出色的系統(tǒng) TCO。
通用型基礎(chǔ)架構(gòu),具有多租戶,可支持傳統(tǒng)工作負(fù)載和先進(jìn)的 AI 應(yīng)用程序,從而實(shí)現(xiàn)出色的 RoA。
全棧加速
全棧加速依托如下兩個支柱:
NVIDIA Aerial 軟件,可加速 DU 功能 L1 和 L2;
支持生態(tài)系統(tǒng)在平臺上運(yùn)行和優(yōu)化 CU 或 UPF 等工作負(fù)載,并實(shí)現(xiàn)工作負(fù)載整合。
圖 1 顯示加速 DU L1 和 L2 是 NVIDIA 實(shí)現(xiàn)全棧加速的關(guān)鍵方面。
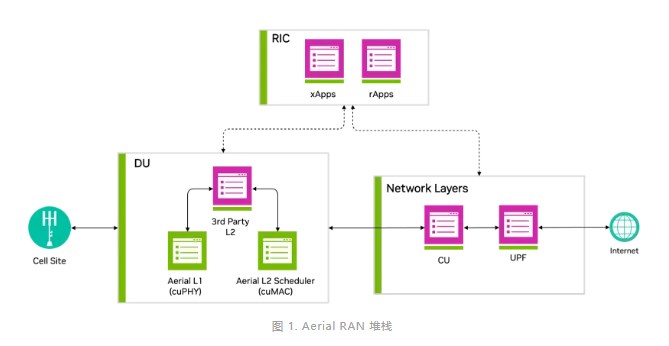
DU 加速
Aerial 已實(shí)施先進(jìn)算法,以提高 RAN 協(xié)議棧的頻譜效率,涵蓋 DU L1 和 L2。
本文中介紹的加速 L1 和 L2 功能是通過一種利用加速計算平臺內(nèi)的 GPU 并行計算能力的通用方法實(shí)現(xiàn)的。
圖 2 顯示 MGX 服務(wù)器平臺在同一 GPU 實(shí)例上托管經(jīng)加速的 L1 cuPHY 和 L2 MAC 調(diào)度程序 cuMAC,并由 CPU 托管 L2+ 堆棧。這展示了基于 GPU 的平臺在同時加速多個計算密集型工作負(fù)載方面的強(qiáng)大功能。
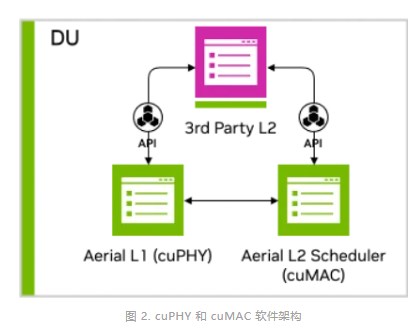
L1 (cuPHY)
Aerial cuPHY 是 RAN 物理層 L1 的數(shù)據(jù)和控制通道的 3GPP 兼容、GPU 加速的全內(nèi)聯(lián)實(shí)現(xiàn)。它提供 L1 高 PHY 庫,通過利用 GPU 的強(qiáng)大計算能力和高度并行性來處理 L1 的計算密集型部分,提供無與倫比的可擴(kuò)展性。它支持標(biāo)準(zhǔn)多輸入多輸出(sMIMO)和大規(guī)模 MIMO(mMIMO)配置。
作為一種軟件實(shí)現(xiàn),它支持持續(xù)增強(qiáng)和優(yōu)化工作負(fù)載,正如 cuPHY 隨著時間推移在 AX800 加速平臺和全新 MGX 平臺上持續(xù)實(shí)現(xiàn)容量提升。
L1 中的信道估計是任何無線接收機(jī)中的基礎(chǔ)塊,優(yōu)化的信道估計器可以顯著提高性能。傳統(tǒng)的信道估計方法包括最小平方(LS)或最小均方誤差(MMSE)。這些方法的比較總結(jié)在表 1 中。

NVIDIA 使用新的通道估計器增強(qiáng)了 cuPHY L1,該估計器的性能優(yōu)于表 1 中列出的方法。此實(shí)現(xiàn)使用復(fù)制核 Hilbert 空間(RKHS)通道估計器算法。
RKHS L1 信道估計
RKHS 信道估計專注于時域信道脈沖響應(yīng)(CIR)的有意義部分,可限制不必要的噪聲并放大脈沖響應(yīng)的相關(guān)部分(圖 3)。
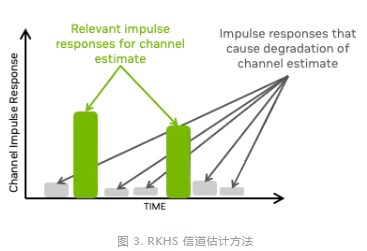
RKHS 需要復(fù)雜的計算,接近無限凸優(yōu)化問題。RKHS 將這個無限凸問題轉(zhuǎn)換為有限凸問題,而不會損失任何性能。
RKHS 計算密集型,非常適合在 GPU 上進(jìn)行并行處理。表 2 總結(jié)了 sMIMO 和 mMIMO 配置的 RKHS 增益和計算需求。

RKHS 計算得出的 CIR(圖 4)與實(shí)際通道(在模擬環(huán)境中測量得出)非常接近,用于具有四個天線和兩個 UL 層的分接延遲線(TDL)- C 通道模型。
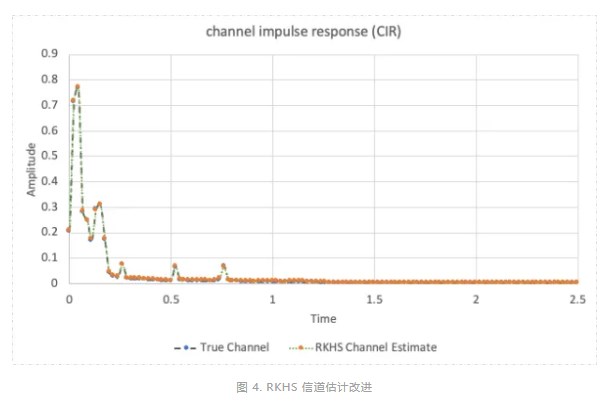
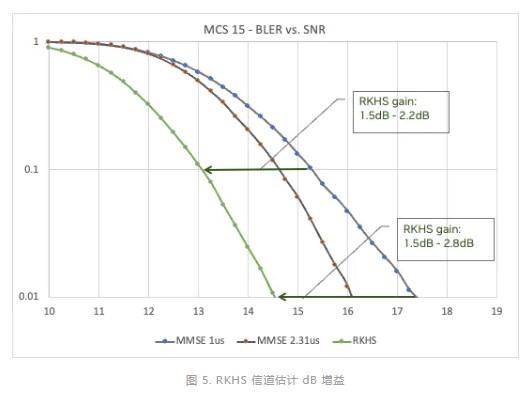
在一系列調(diào)制和編碼方案(MCS)中,與信噪比(SNR)曲線相比,改進(jìn)后的 CIR 顯著提高了誤碼率(BER)。圖 5 顯示了 RKHS 相對于 MMSE(具有兩個不同的窗口,1 s 和 2.3 s)的優(yōu)勢,對于 MCS 15,可提供高達(dá) 2.5 dB 的增益。
L2 (cuMAC)
RAN 協(xié)議棧中的 L2 MAC 調(diào)度程序在決定 UE 如何訪問無線電資源方面發(fā)揮著重要作用。而這反過來又決定了整個網(wǎng)絡(luò)的頻譜效率。
對于 5G 系統(tǒng),有許多自由度,包括:
傳輸時間間隔(TTI)插槽
已分配的物理資源塊(PRB)
MCS
MIMO 層選擇
典型的調(diào)度程序?qū)W⒂趩蝹€單元,這會限制實(shí)現(xiàn)的性能。表 3 顯示了典型調(diào)度程序方法的比較。

在 NVIDIA ,我們使用比例公平(PF)算法實(shí)施了多單元調(diào)度程序,其性能優(yōu)于表 3 中列出的兩種方法。
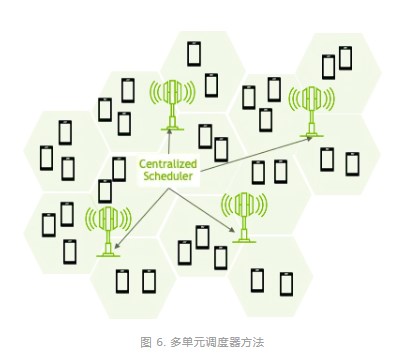
多單元調(diào)度程序
NVIDIA 多單元調(diào)度程序通過優(yōu)化大量相鄰單元的調(diào)度參數(shù)(TTI、PRB、MCS 和 MIMO 層),顯著提高了無線性能(圖 6)。
使用 PF 算法的多單元調(diào)度需要復(fù)雜的計算邏輯來解決所有單元中的各種變量。這非常適合具有大規(guī)模并行處理能力的 GPU。表 4 總結(jié)了 sMIMO 和 mMIMO(聯(lián)合調(diào)度 20 個單元)的優(yōu)勢和計算需求。如您所見,CPU 計算需求很高。
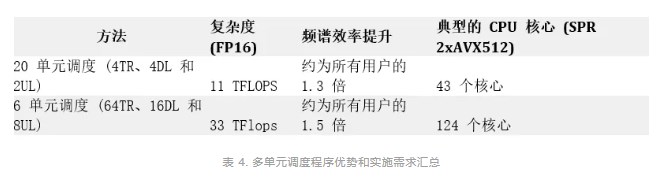
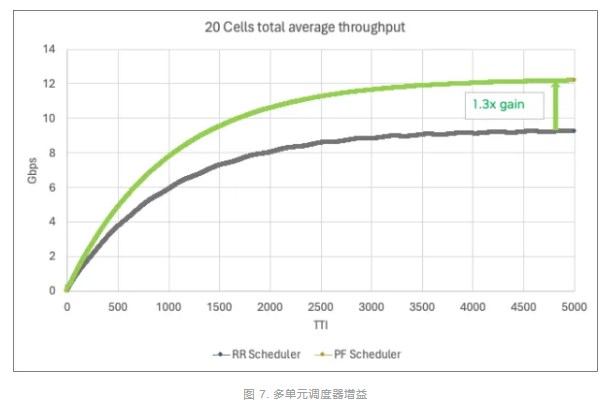
圖 7 顯示了 20 個 100MHz 4T4R 4DL/2UL 單元(每個單元具有 500 個活躍 UE 和 16 個 UE/TTI)的頻譜效率。
DU 綜合加速提升
總而言之,RKHS 信道估計支持每個 UE 更高的 MCS 分配,而多單元調(diào)度器代表了無線電資源調(diào)度的重大飛躍。這兩種方法都能顯著提高頻譜效率,并在 GPU 上得到優(yōu)化實(shí)施。
例如,對于 6 單元的 100MHz 64T64R 系統(tǒng),實(shí)現(xiàn) 2 倍以上的 SE 增益將需要大約 240 個核心(大約 8 個 32 核心 CPU),需要額外的 CPU 服務(wù)器。相較于 GPU 實(shí)現(xiàn),其中 L1 PHY 處理和 L2 調(diào)度程序托管在單個服務(wù)器中的單個 GPU 上。
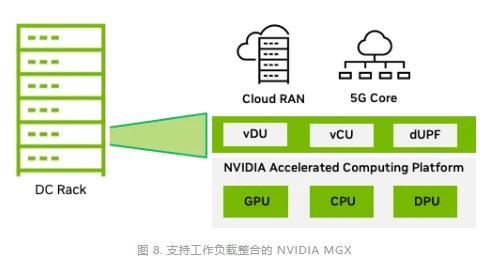
工作負(fù)載整合
如前文所述,全棧加速的第二個支柱是整合多個工作負(fù)載并在 Aerial RAN 上加速這些工作負(fù)載。這是通過利用 NVIDIA 加速計算平臺中的 GPU、CPU 和 DPU 的可用計算資源來實(shí)現(xiàn)的。
針對電信工作負(fù)載,MGX 系統(tǒng)提供針對數(shù)據(jù)中心的模塊化和可擴(kuò)展架構(gòu)。該系統(tǒng)可提供所需的計算能力,以整合 RAN CU、RAN 智能控制器(RIC)應(yīng)用等功能以及 UPF 等核心功能。
NVIDIA Grace Hopper 超級芯片結(jié)合了 NVIDIA Grace 和 NVIDIA Hopper 架構(gòu),使用 NVIDIA NVLink-C2C 為 5G 和 AI 應(yīng)用提供 CPU+GPU 一致性內(nèi)存模型。
CU 可以利用許多 Grace CPU 核心。RIC 應(yīng)用程序(例如通常包含 AI/ML 技術(shù)以提高頻譜效率的 xApp)可以在 GPU 上進(jìn)行加速。
隨著我們進(jìn)一步進(jìn)入網(wǎng)絡(luò),UPF 等功能通過使用關(guān)鍵的 DPU 功能可以從 DPU 加速中受益:
GTP 加密和解密
流哈希處理和接收端縮放(RSS)
深度數(shù)據(jù)包檢測(DPI)
工作負(fù)載整合使電信公司能夠更大限度地減少部署在數(shù)據(jù)中心的服務(wù)器數(shù)量,從而全面提高 TCO。
多租戶 Aerial RAN
電信公司需要一個可以滿足電信工作負(fù)載嚴(yán)苛的性能和可靠性要求的平臺,能夠在一個通用平臺上托管不同類型的電信工作負(fù)載(從 RAN 到核心)。
電信 RAN 基礎(chǔ)設(shè)施的利用率明顯不足。借助多租戶云基礎(chǔ)設(shè)施,電信公司可以在有閑置容量時通過可盈利的應(yīng)用程序提高利用率。
可以為電信公司提供盈利機(jī)會的工作負(fù)載類型包括生成式 AI 和基于大語言模型(LLM)的多接入邊緣計算(MEC)應(yīng)用程序。這些類型的工作負(fù)載在分布式電信邊緣數(shù)據(jù)中心引發(fā)了前所未有的計算需求。
由于需要在邊緣支持大量基于 LLM 的應(yīng)用程序,因此專用于執(zhí)行 LLM 推理的邊緣 GPU 服務(wù)器和各種 MEC 應(yīng)用程序正在大幅增加。
圖 9 顯示了 MGX 平臺,該平臺可以托管所有工作負(fù)載,并幫助電信公司克服計算資源利用不足的問題,減少總體能源足跡,并提高基礎(chǔ)設(shè)施的貨幣化程度。
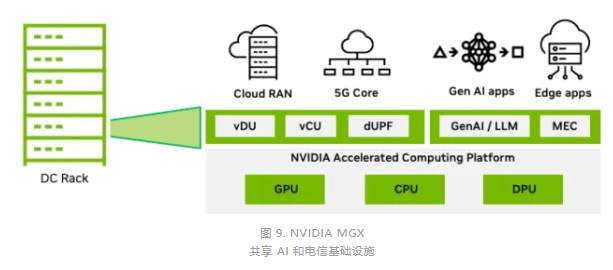
共享 AI 和電信基礎(chǔ)設(shè)施
Aerial CUDA 加速 RAN 的優(yōu)勢
到目前為止,我們已經(jīng)討論了 NVIDIA Aerial 軟件如何幫助提高整體頻譜效率,以及加速計算平臺如何提供處理能力,以在同一平臺上整合多個工作負(fù)載。
多租戶平臺支持 AI 工作負(fù)載的貨幣化。5 年期 TCO 分析顯示,該平臺的可用時間約為 AI 的 30%,并考慮到典型的每小時 GPU 定價,可提供顯著抵消平臺成本的收入。與僅使用 CPU 的系統(tǒng)相比,此 ROA 對每美元指標(biāo)的性能有重大影響。
根據(jù)條形圖顯示,與 x86 CPU 相比,采用 AI 創(chuàng)收的 GPU 的每成本性能提升了 4.1 倍。
結(jié)束語
總而言之,Aerial RAN 可提供出色的 TCO 并釋放新的收入機(jī)會,從而更大限度地提高投資回報率(ROA)。
NVIDIA 正在改變電信基礎(chǔ)設(shè)施,該基礎(chǔ)設(shè)施基于 NVIDIA 加速計算平臺構(gòu)建,并由 Aerial 軟件提供支持。Aerial CUDA 加速的 RAN 可滿足電信公司的愿望,以 TCO 高效的方式提供市場領(lǐng)先的無線功能,并能夠開始以當(dāng)今部署的基礎(chǔ)設(shè)施無法實(shí)現(xiàn)的方式從部署的基礎(chǔ)設(shè)施中獲利。
在本文中,我們詳細(xì)介紹了使用新算法在 L1 和 L2 上實(shí)現(xiàn)的頻譜效率提升,并討論了基于 RAN 和 LLM 的工作負(fù)載加速 AI 工作負(fù)載的能力。新一代 NVIDIA 平臺將通過提供更高的單元密度和更高的工作負(fù)載加速來進(jìn)一步改進(jìn)這些關(guān)鍵指標(biāo)。
Aerial CUDA 加速 RAN 作為 NVIDIA 6G 研究云平臺的一部分提供。
審核編輯:劉清
-
集成電路
+關(guān)注
關(guān)注
5420文章
12008瀏覽量
367751 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5282瀏覽量
106030 -
ASIC芯片
+關(guān)注
關(guān)注
2文章
92瀏覽量
24228 -
超級芯片
+關(guān)注
關(guān)注
0文章
38瀏覽量
9063 -
MIMO技術(shù)
+關(guān)注
關(guān)注
0文章
43瀏覽量
7725
原文標(biāo)題:借助 NVIDIA Aerial CUDA 加速 RAN,增強(qiáng) 5G/6G 的 DU 性能和工作負(fù)載整合
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論