 GRU模型實戰訓練 智能決策更精準
GRU模型實戰訓練 智能決策更精準

上一期文章帶大家認識了一個名為GRU的新朋友, GRU本身自帶處理時序數據的屬性,特別擅長對于時間序列的識別和檢測(例如音頻、傳感器信號等)。GRU其實是RNN模型的一個衍生形式,巧妙地設計了兩個門控單元:reset門和更新門。reset門負責針對歷史遺留的狀態進行重置,丟棄掉無用信息;更新門負責對歷史狀態進行更新,將新的輸入與歷史數據集進行整合。通過模型訓練,讓模型能夠自動調整這兩個門控單元的狀態,以期達到歷史數據與最新數據和諧共存的目的。
理論知識掌握了,下面就來看看如何訓練一個GRU模型吧。
訓練平臺選用Keras,請提前自行安裝Keras開發工具。直接上代碼,首先是數據導入部分,我們直接使用mnist手寫字體數據集:
import numpy as np import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import GRU, Dense from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import load_model # 準備數據集 (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.astype('float32') / 255.0 x_test = x_test.astype('float32') / 255.0 y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10)
模型構建與訓練:
# 構建GRU模型 model = Sequential() model.add(GRU(128, input_shape=(28, 28), stateful=False, unroll=False)) model.add(Dense(10, activation='softmax')) # 編譯模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型訓練 model.fit(x_train, y_train, batch_size=128, epochs=10, validation_data=(x_test, y_test))
這里,眼尖的伙伴應該是注意到了,GRU模型構建的時候,有兩個參數,分別是stateful以及unroll,這兩個參數是什么意思呢?
GRU層的stateful和unroll是兩個重要的參數,它們對GRU模型的行為和性能有著重要影響:
stateful參數:默認情況下,stateful參數為False。當stateful設置為True時,表示在處理連續的數據時,GRU層的狀態會被保留并傳遞到下一個時間步,而不是每個batch都重置狀態。這對于處理時間序列數據時非常有用,例如在處理長序列時,可以保持模型的狀態信息,而不是在每個batch之間重置。需要注意的是,在使用stateful時,您需要手動管理狀態的重置。
unroll參數:默認情況下,unroll參數為False。當unroll設置為True時,表示在計算時會展開RNN的循環,這樣可以提高計算性能,但會增加內存消耗。通常情況下,對于較短的序列,unroll設置為True可以提高計算速度,但對于較長的序列,可能會導致內存消耗過大。
通過合理設置stateful和unroll參數,可以根據具體的數據和模型需求來平衡模型的狀態管理和計算性能。而我們這里用到的mnist數據集實際上并不是時間序列數據,而只是將其當作一個時序數據集來用。因此,每個batch之間實際上是沒有顯示的前后關系的,不建議使用stateful。而是每一個batch之后都要將其狀態清零。即stateful=False。而unroll參數,大家就可以自行測試了。
模型評估與轉換:
# 模型評估
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 保存模型
model.save("mnist_gru_model.h5")
# 加載模型并轉換
converter = tf.lite.TFLiteConverter.from_keras_model(load_model("mnist_gru_model.h5"))
tflite_model = converter.convert()
# 保存tflite格式模型
with open('mnist_gru_model.tflite', 'wb') as f:
f.write(tflite_model)
便寫好程序后,運行等待訓練完畢,可以看到經過10個epoch之后,模型即達到了98.57%的測試精度:

來看看最終的模型樣子,參數stateful=False,unroll=True:
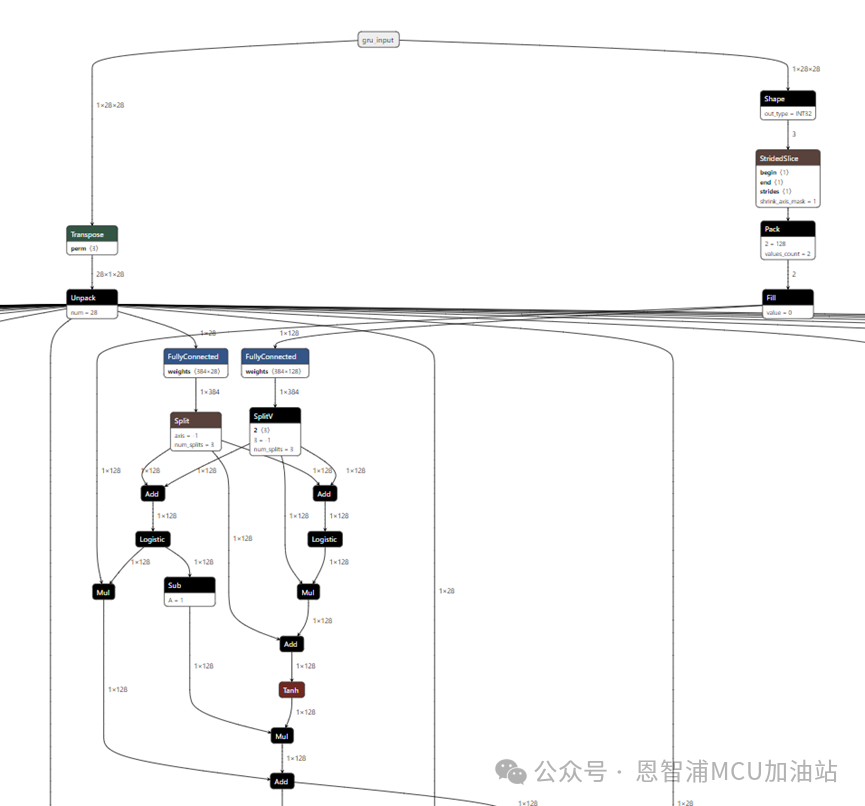
這里,我們就會發現,模型的輸入好像被拆分成了很多份,這是因為我們指定了輸入是28*28。第一個28表示有28個時間步,后面的28則表示每一個時間步的維度。這里的時間步,指代的就是歷史的數據。
現在,GRU模型訓練就全部介紹完畢了,對于機器學習和深度學習感興趣的伙伴們,不妨親自動手嘗試一下,搭建并訓練一個屬于自己的GRU模型吧!
希望每一位探索者都能在機器學習的道路上不斷前行,收獲滿滿的知識和成果!
-
Gru
+關注
關注
0文章
12瀏覽量
7649 -
機器學習
+關注
關注
66文章
8502瀏覽量
134584 -
rnn
+關注
關注
0文章
89瀏覽量
7108
原文標題:GRU模型實戰訓練,智能決策更精準!
文章出處:【微信號:NXP_SMART_HARDWARE,微信公眾號:恩智浦MCU加油站】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
動態感知+智能決策,一文解讀 AI 場景組網下的動態智能選路技術
宇視科技梧桐大模型賦能交通治理
AI賦能邊緣網關:開啟智能時代的新藍海
【「大模型啟示錄」閱讀體驗】+開啟智能時代的新鑰匙
GPU是如何訓練AI大模型的
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型

如何訓練自己的LLM模型
Llama 3 模型訓練技巧
AI大模型的訓練數據來源分析
如何訓練自己的AI大模型
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論