 利用大模型服務一線小哥的探索與實踐
利用大模型服務一線小哥的探索與實踐
一、小哥作業+大模型
2022年OpenAI基于GPT推出了聊天機器人ChatGPT,帶來了非常驚艷的語言理解、內容生成、知識推理等能力,能夠準確理解人的語言、意圖,并能夠回答出清晰、完整的內容,讓人很難分辨出溝通交流的是人類還是機器人。
大模型會嘗試基于已有的內容,生成內容的延續。基于預訓練階段加入的海量文章、電子圖書、網頁內容等等,大模型給出最接近我們期望的內容。比如我們提供的內容是“北京是...”,大模型掃描海量內容進行排名,為了讓內容更有創造力,大模型使用了巫術,一般采用基于可配置參數(top K, top P, Temperature) 的概率隨機采樣來選擇單詞,而不是總采用排名最高的單詞。通過延續生成了“北京是一座充滿活力的城市”。人類反饋強化學習(RLHF)即基于人類反饋對大語言模型進行強化學習,通過人工標注來構建獎懲網絡,強化學習基于獎懲網絡對模型進行迭代優化,改善生成內容的質量。
快遞快運終端系統是快遞小哥、快運司機、網點管理者日常使用的系統,是物流作業人員最多、作業流程最末端、服務形態最多元的系統。大模型帶來了新的方法來解決小哥提出的問題、遇到的異常、需要的支持,并提供幫助網點管理者進行運營和經營管理的工具。
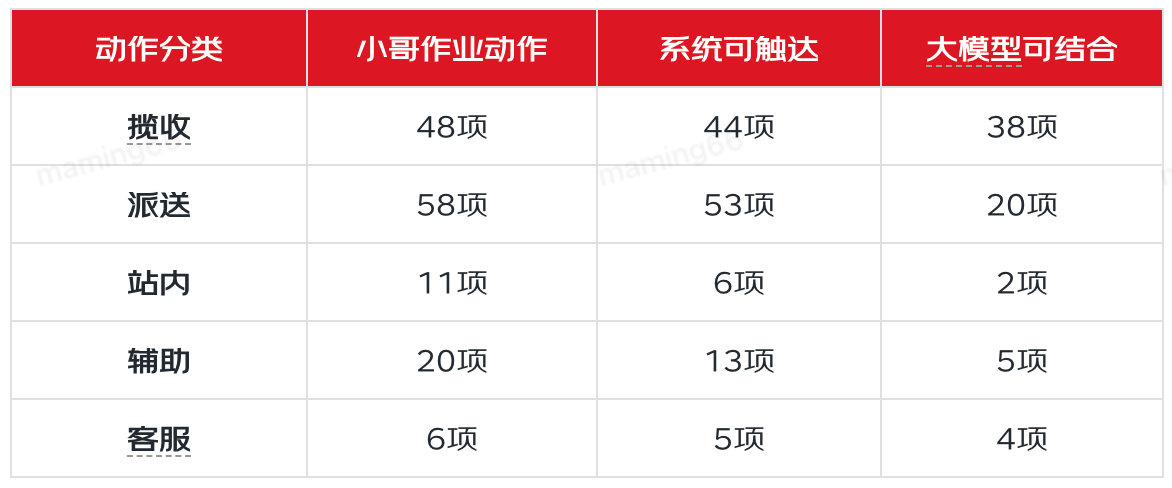
提升小哥作業效率,就需要了解小哥日常工作中有哪些作業動作,然后根據作業動作的特點,來分析大模型有什么樣的機會來實現效率提升。通過調研和分析,小哥有143項作業動作,可分類為:攬收、派送、站內、輔助、客戶服務五大類,其中22項動作是系統外的線下動作,其他動作中有69項被認為有大模型結合的機會。在69項中我們選取了小哥攬收信息錄入、外呼、發短信、查詢運單信息、聚合查詢、知識問答、精準提示等場景,通過大模型與大數據、GIS、語音等技術的結合,為小哥提供高效、易用的作業工具。
二、智能操作
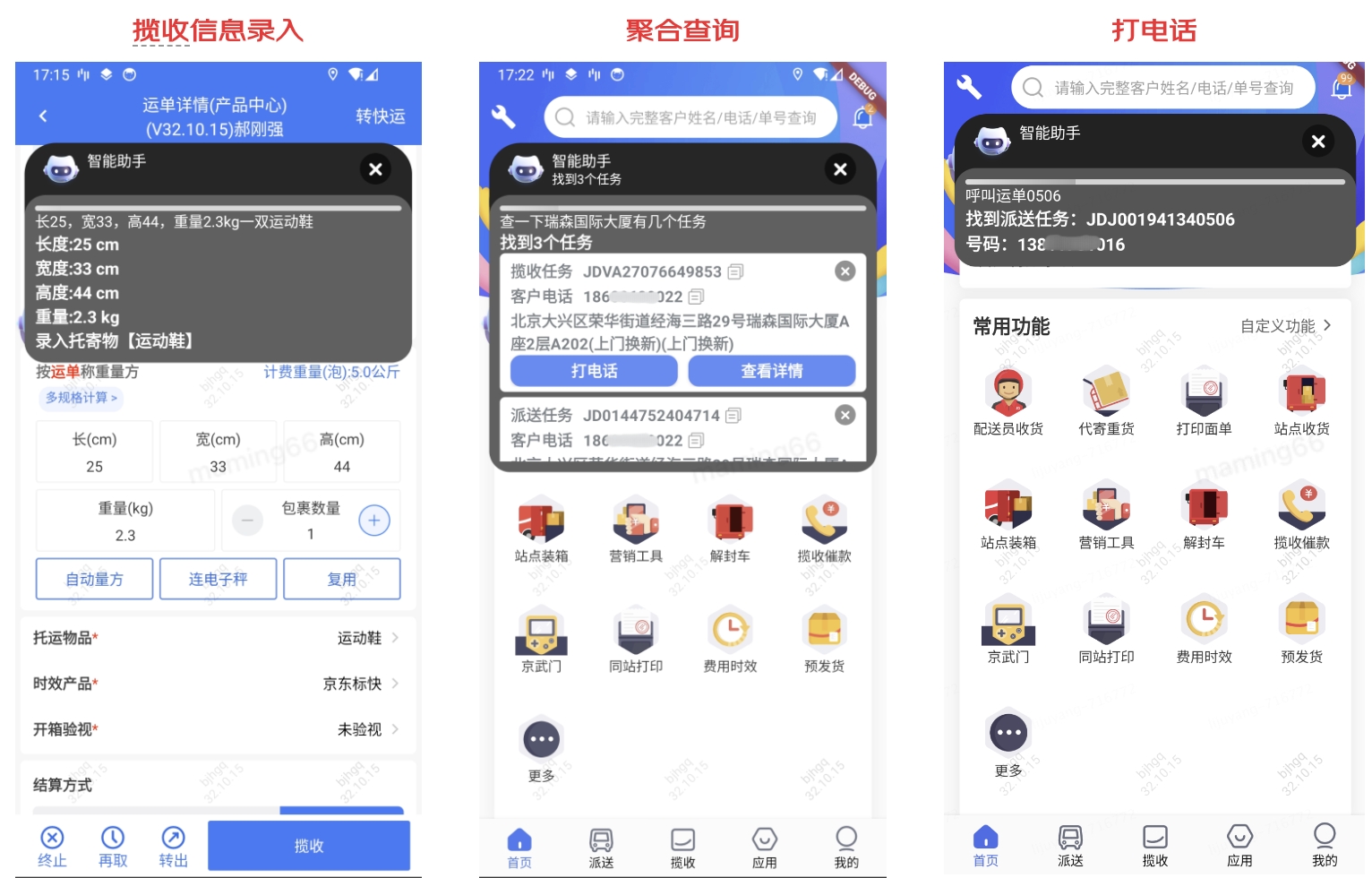
小哥日常作業中,會頻繁給客戶打電話、發短信。出于客戶個人隱私安全的考慮,面單中隱藏了電話,所以外呼前需要小哥一次次在系統中查找電話,經常是掃單號、在詳情頁點擊外呼按鈕、撥打電話等一系列動作。通過小哥語音,大模型可以幫助我們分析小哥的意圖,識別出撥打電話,就可以通過語音中提到的運單尾號、地址等特征完成外呼。
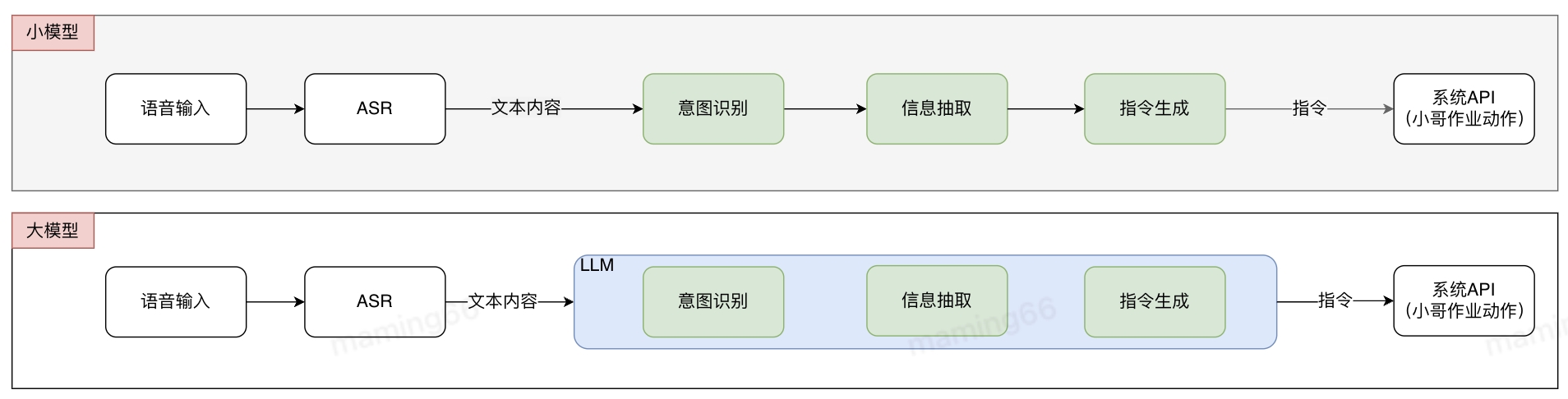
基于常規算法的解決方式是多個小模型組合成pipline,各小模型分別進行標注和訓練,pipline存在誤差傳遞問題。使用大模型后,不需要進行標記和訓練,可以直接投入使用,減少了算法開發的難度和周期,提升研發交付效率。在接收到小哥語音輸入后,語音識別(ASR)將語音轉化為文字,文字通過大模型意圖識別、信息抽取等方式生成指令,并調用系統API實現作業功能。
小哥智能助手中智能操作的實現方法如下:
在小哥發短信時,需要查找電話,在短信界面編輯文字,通過語音+大模型,識別小哥需要給客戶發短信,并通過大模型對短信內容進行再加工,完成正式的短信編寫。
在填寫攬收信息時,小哥需要頻繁切換電子稱、卷尺、工業機來完成稱重量方和信息錄入等作業動作,同時攬收還需要填寫托寄物、時效產品、增值服務等內容,如果通過語音+大模型,就可以減少工業機的多次輸入,會直接識別語音,分析出小哥的輸入意圖和內容,將信息正確填寫。
小哥查詢信息,也可以通過語音輸入,大模型識別意圖,進行結果的反饋。如下是通過大模型實現的意圖識別示例:

三、智能問答
業務快速發展的同時,也對小哥作業提出了非常高的要求,據不完全統計,僅終端相關文件就有915個,如貨物處理規程、安全操作標準、KA客戶服務要求等等。對于小哥來說,記憶并掌握這么多業務要求無疑是一項巨大的挑戰,小哥對標準作業流程或規范了解不全面,會影響服務質量,也會影響一線作業效率,造成時間和成本浪費。
小哥不了解流程、規則或者遇到運營問題,目前通過問站長/站助/其他小哥、提報IT工單、聯系終端小秘等方式解決,但是被咨詢人也會因為對業務規則、流程了解不全面而無法給出正確的回答。大模型出現后能夠更清晰的理解小哥的問題和意圖,提供更加簡潔的回答,提高回答的準確率,降低了小哥的理解成本。
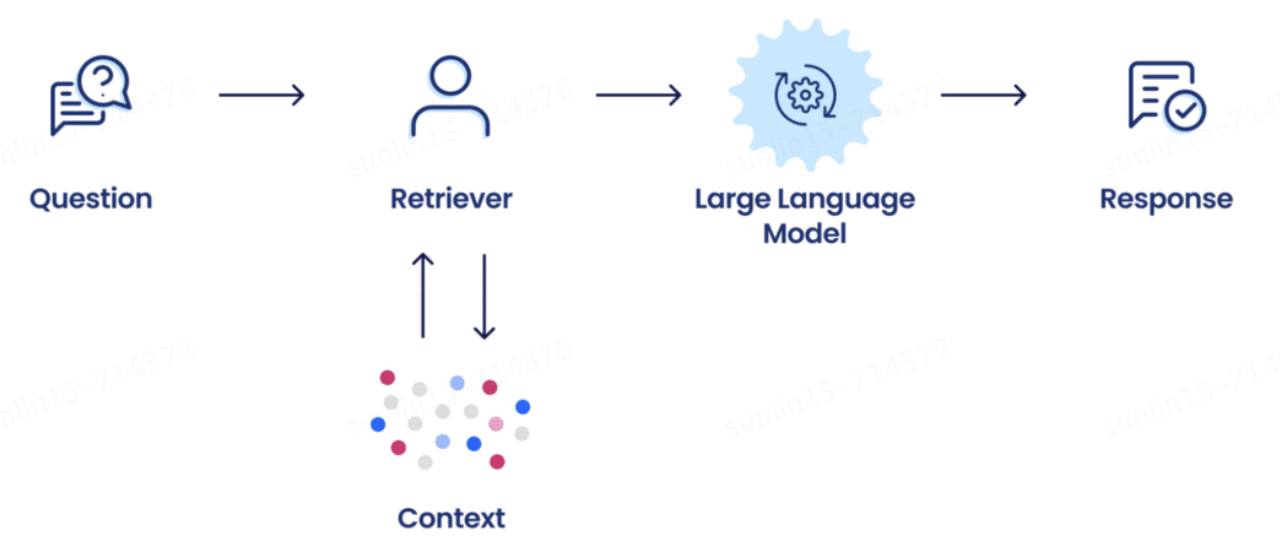
通過Prompt+檢索增強生成(RAG)實現了第一階段的智能問答。之所以需要檢索增強生成是因為大模型目前存在幻覺、知識過時等問題,RAG實現從外部知識庫中檢索相關信息進行回答,提高答案的準確性。
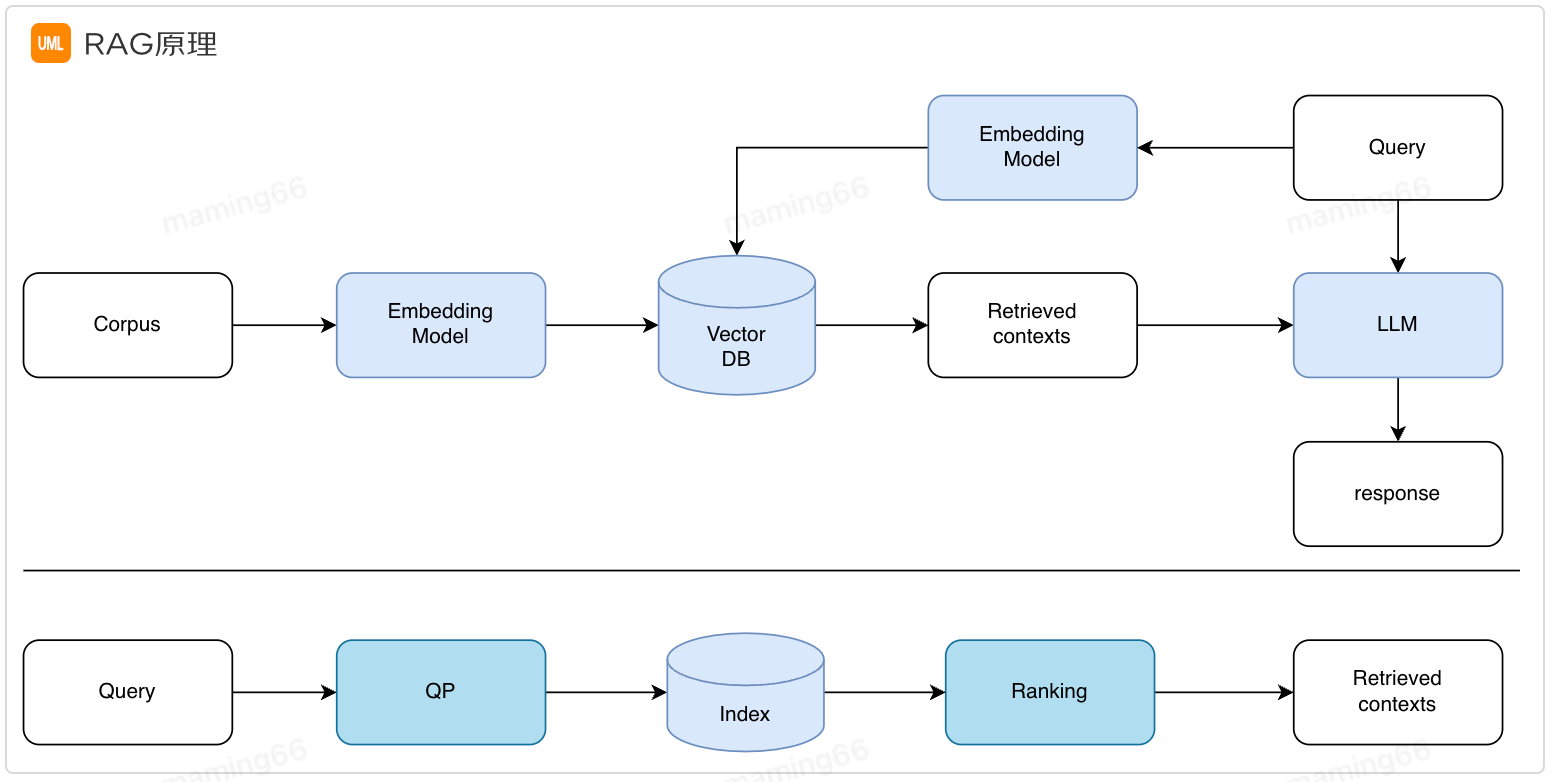
小哥智能助手中智能問答的實現方法如下:
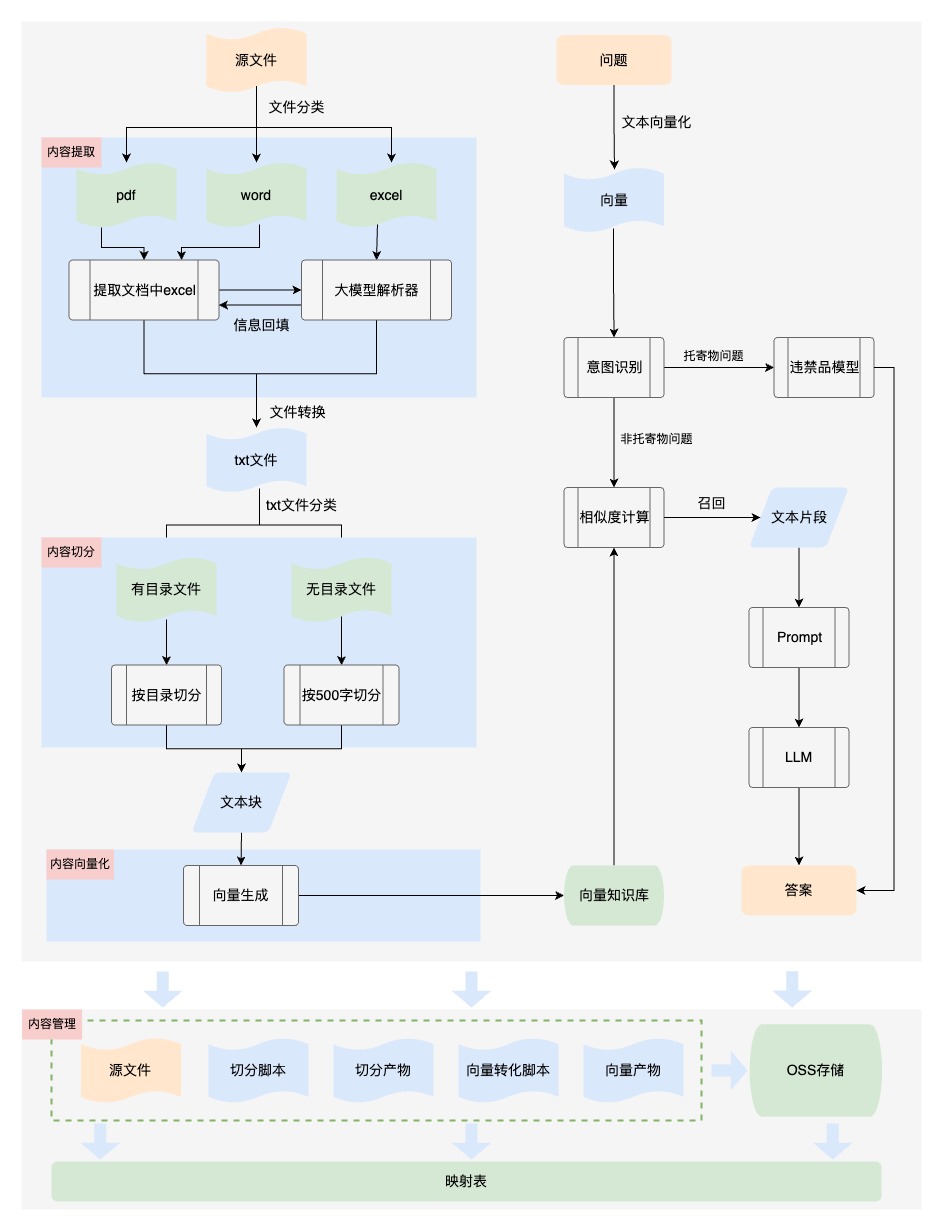
【內容提取】業務文檔格式多樣,也包含各種內容元素,比如包含表格的文檔,只進行文字提取,無法保證內容的結構性、可讀性,輸入給大模型后無法理解,導致回答不準確。所以我們對文件內容進行提取時,將文件中的表格轉換為語義化的內容,保證知識的可讀性。如下是業務文檔中的表格內容:

【內容切分】大模型能夠找到的相關知識的質量和數量決定了回答的正確性和完整性,但是由于大模型token的數量限制,我們必須將文檔內容切分。最初我們設置300個字符為一個知識塊進行切分,從回答的效果上看,有很多問題回答的內容不完整,因為單純的按照字數切分會破壞內容的完整性,需要引入段落切分,保持段落完整性。

具體實現方法如下:
a. 內容提取
第一版采用了DocumentLoaderUtil直接提取文本,將文本信息存入txt文件,具體實現方式如下:
from src.document_loader.document_loader import DocumentLoaderUtil processor = DocumentLoaderUtil(file_path=path_ori, pic_save_dir=dir_save_picture) texts = processor.load() texts = json.dumps(texts, ensure_ascii=False, indent=4) with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt"), "w") as f: f.write(texts)
優化后處理DOCX文件:
1.讀取文檔信息時,遇到表格,將表格單獨存儲到excel中,并在文本中使用特殊占位符標注表格位置;
2.結合大模型對表格進行語義化處理,使表格信息轉化成語義化文本;
3.根據特殊占位符將語義化文本回填至文檔對應位置;
# 提取word中的表格 def extract_tables_to_excel(docx_path, excel_result_path): doc = Document(docx_path) docx_name = os.path.splitext(os.path.basename(docx_path))[0] folder_path = os.path.join(excel_result_path, docx_name) if not os.path.exists(folder_path): os.makedirs(folder_path) table_count = 0 for table in doc.tables: table_count += 1 data = [[cell.text for cell in row.cells] for row in table.rows] df = pd.DataFrame(data) # 保存DataFrame到Excel文件 excel_path = os.path.join(folder_path, f"【表格{table_count}】.xlsx") df.to_excel(excel_path, index=False, header=False) return folder_path # 根據占位符插入表格內容 def replace_marker_in_txt(file_path, marker, replacement_text): # 讀取原始文件內容 with open(file_path, 'r+', encoding='utf-8') as file: content = file.read() if replacement_text is None: replacement_text = '' # 替換特定標記 content = content.replace(marker, replacement_text) file.seek(0) file.write(content) file.truncate() # txt中插入表格 def insertTable(folder_path, txt_path): for filename in os.listdir(folder_path): filepath = os.path.join(folder_path, filename) filename_without_extension, _ = os.path.splitext(filename) # 處理表格為語義化文本 result = excel_to_txt_single(filepath) # 占位符替換處理后的文本 replace_marker_in_txt(txt_path, filename_without_extension, result)
優化后處理PDF文件:
1.讀取文檔信息提取表格,結合大模型對表格進行語義化處理,使表格信息轉化成語義化文本;
2.尋找表格內容并替換內容;
# 處理pdf
def process_pdf(file_path, file_name, output_directory, save_directory, txt_file):
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
content = DocumentLoaderUtil(file_path, save_directory).load()
content = [doc['page_content'] for doc in content]
with open(txt_file, 'w', encoding='utf-8') as f:
for line in content:
f.write(line + 'n')
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
# 特殊pdf二次處理
def handle_exception(extension, file_path, file_name, output_directory, save_directory):
try:
if extension == '.pdf':
individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)
text, txt_file = convert_pdf_to_txt(file_path, os.path.join(save_directory, 'txt'))
else:
return
with open(txt_file, 'w', encoding='utf-8') as output_file:
output_file.write(text)
replace_similar_module_in_txt(individual_file_names, txt_file, file_path)
except FileNotFoundError as e:
with open('error.md', 'a') as file:
file.write(f"文件未找到錯誤:{file_path}n")
except Exception as e:
with open('error.md', 'a') as file:
file.write(f"handle_exception處理異常時發生錯誤:{file_path}n")
# 查找表格位置并替換為語義化內容
def replace_similar_module_in_txt(individual_file_names, txt_file, file_path):
# 讀取文本文件的原始內容
with open(txt_file, 'r', encoding='utf-8') as file:
txt_content = file.read()
for excel_path in individual_file_names:
excel_content = read_excel_content(excel_path)
# 查找最相似的片段
most_similar_part = find_most_similar_part(txt_content, excel_content, threshold=0.02)
if most_similar_part:
# 替換成語義化文本
replacement_text = excel_to_txt_single(excel_path)
txt_content = safe_replace(txt_content, most_similar_part, replacement_text)
else:
# 找不到時 將內容追加到文檔后
replacement_text = excel_to_txt_single(excel_path)
txt_content += replacement_text
with open(txt_file, 'w', encoding='utf-8') as file:
file.write(txt_content)
b. 內容切分
第一版按照字符數切分,固定300字符+15%的滑動窗口。核心代碼如下:
from src.text_splitter.text_splitter import TextSplitterUtil
splitter_name = "RecursiveCharacterTextSplitter"
splitter_args = {
"chunk_size": 300,
"chunk_overlap": round(300 * 0.15),
"length_function": len,
}
splitter = TextSplitterUtil(splitter_name, splitter_args)
with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt")) as f:
texts = json.load(f)
texts_splitted = splitter.create_documents(
texts=[t["page_content"] for t in texts],
metadatas=[{"source": f"{path_ori}_{ti}"} for ti, t in enumerate(texts)],
)
print(texts_splitted)
優化后按照段落+500字符+10%的重疊進行切分。經過測試回歸發現,效果明顯提升。
import os
import json
import re
import csv
# 按優先級順序存儲正則表達式
def find_all_matches(doc, patterns):
last_end = 0
matches = []
# 搜索所有的匹配項
for pattern in patterns:
for match in pattern.finditer(doc):
start, end = match.span()
# 如果當前匹配塊前有未匹配的內容,則將其作為單獨的匹配塊
if start > last_end:
matches.append(doc[last_end:start])
matches.append(match.group())
last_end = end
if last_end < len(doc):
matches.append(doc[last_end:])
return matches
def trim_regex_title(path_ori):
with open(path_ori, 'r', encoding='utf-8') as file:
document = file.read()
# 使用非貪婪匹配 .*? 來捕獲標題后的內容,直到遇到下一個標題或文檔末尾
# 初始化 matches 為空列表,用于存儲找到的匹配項
# 按優先級順序存儲正則表達式
patterns = [
re.compile(r'((?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+)([sS]*?)(?=n(?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|d+.)[^n]+|$)'),
re.compile(r'(n.+?)(?=n.+|$)'),
re.compile(r'(?s)(nd+.d+s+.*?)(?=nd+.d+s+|$)')
]
matches = find_all_matches(document, patterns)
page_contents = []
for match in matches:
section_content = match.strip()
page_contents.append({
'page_content': section_content,
'metadata': {
'source': path_ori,
},
})
# 組裝成500字
# 創建一個空列表用于存儲處理后的page_checks
page_checks = []
# 用于累積不足500字符的內容
accumulated_content = ""
for page in page_contents:
page_content = page['page_content']
# 如果當前行內容加上累積的內容超過500字符,則需要分割
if len(accumulated_content) + len(page_content) > 500:
# 如果之前有累積的內容,先處理
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = ""
# 處理當前行的內容
start_index = 0
while start_index < len(page_content):
end_index = min(start_index + 500, len(page_content))
page_check_dict = {
"page_content": page_content[start_index:end_index],
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
# 更新start_index以便獲取下一個500字符的片段,與前一個片段有50字符重疊
start_index += 450
else:
# 如果當前累積內容與新行內容總和不超過500字符 繼續累積內容
if len(accumulated_content) + len(page_content) < 500:
accumulated_content += page_content
else:
# 累積內容已足夠,創建一個page_check
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
accumulated_content = page_content
# 處理文件末尾的累積內容
if accumulated_content:
page_check_dict = {
"page_content": accumulated_content,
"metadata": {"source": path_ori}
}
page_checks.append(page_check_dict)
return page_checks
c. 向量化 Embedding
用戶的問題往往非常口語化,而文檔和知識往往都是非常的專業和正式。比如用戶的問題是:“我去年已經離職了,現在自己干,如何交公積金?”。從文檔中需要檢索出“靈活就業人員”辦理公積金的材料和流程。內容檢索只能進行精確匹配,對于近義詞、語義關聯詞的檢索效果較差。文本向量化后,搜索就可以通過計算詞語之間的相似度,實現對近義詞和語義關聯詞的模糊匹配,從而擴大了搜索的覆蓋范圍并提高了準確性。Embedding 就是將這些離散的文本內容轉換成連續的向量。我們將向量存儲到Vearch庫中,選擇相似度top9的向量對應的內容文本輸入給大模型,通過Prompt進行回答。
from src.embedding.get_embedding import get_openai_embedding
model_key = "xxxx"
model_name = "text-embedding-ada-002-2"
texts_embedding = [
get_openai_embedding(
text=t.page_content, model_name=model_name, model_key=model_key
)
for t in texts_splitted
]
d. 內容管理
我們為向量創建索引,以便于檢索和更新,同時將各階段產物包括源文件、切分腳本、切分文本塊、向量嵌入腳本、向量存儲通過oss進行管理,并建立映射表。當業務知識進行更新時,可以對向量庫中的內容進行更新替換。

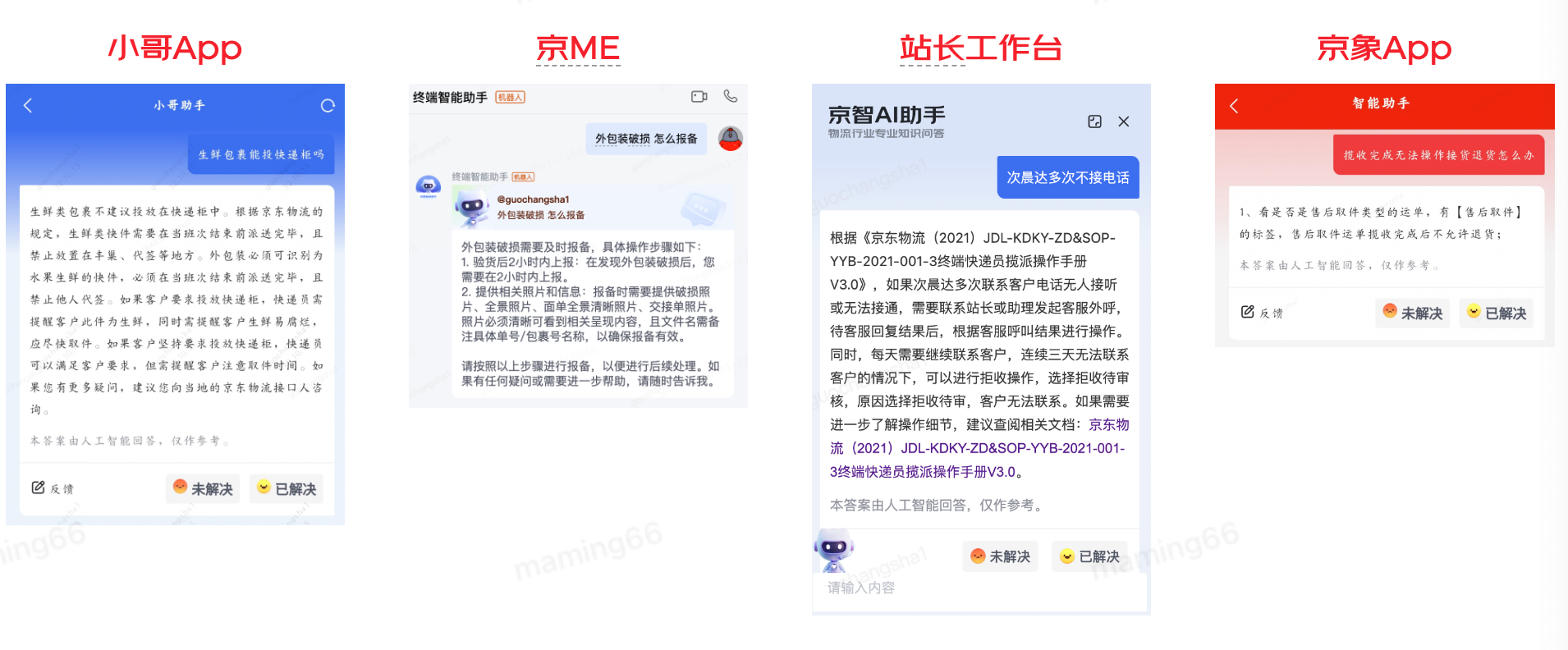
通過持續優化智能問答準確率90%,目前已接入小哥App、京ME、站長工作臺、京象App等,功能如下:
四、智能提示
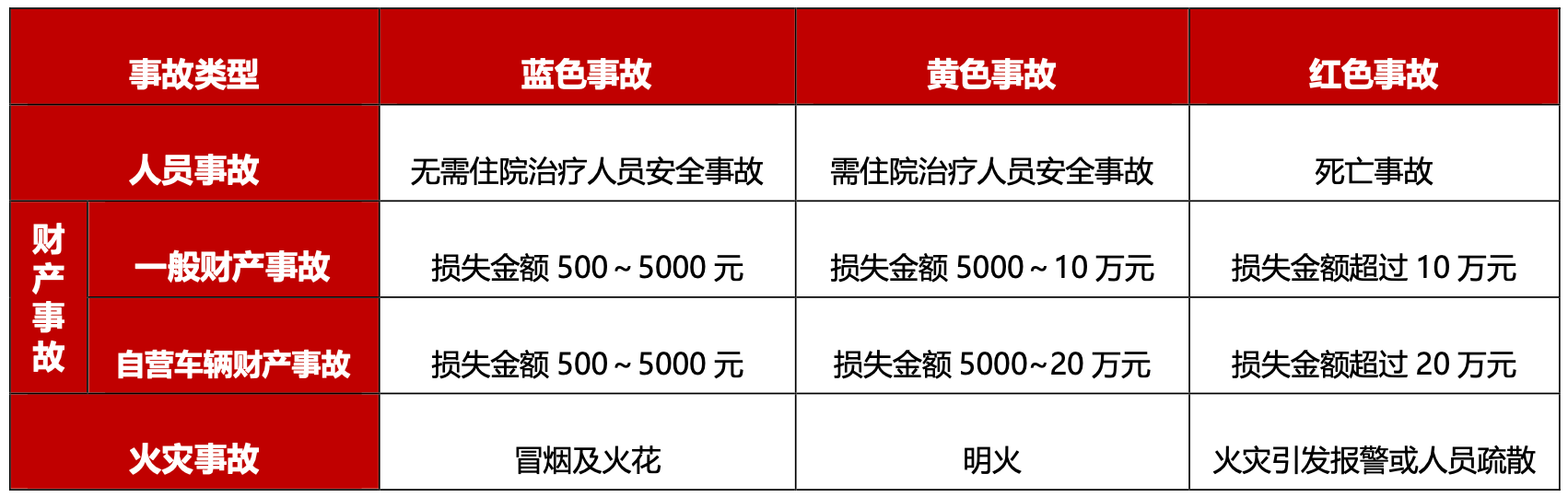
小哥作業流程規范,以及履約中的時效預測和提醒等等,都可以使用大模型將復雜的業務文檔和流程規范轉化為小哥容易理解和執行的操作提示,在任務下發、臨期提醒方面也可以發揮大模型的理解和總結能力,使小哥關注到最需要關注的信息,幫助小哥做進一步的作業決策。比如KA商家對攬收打包方式、交接方式有各自不同的定制化需求,如果通過小哥記憶或者查資料的方式了解攬收打包要求,非常麻煩且耗時,利用大模型總結KA商家操作要求,通過語音合成(TTS)引導小哥按照客戶要求作業,能夠提升業務的履約質量。

?
小哥智能助手中智能提示的實現方法,以售后取件單下發為例:
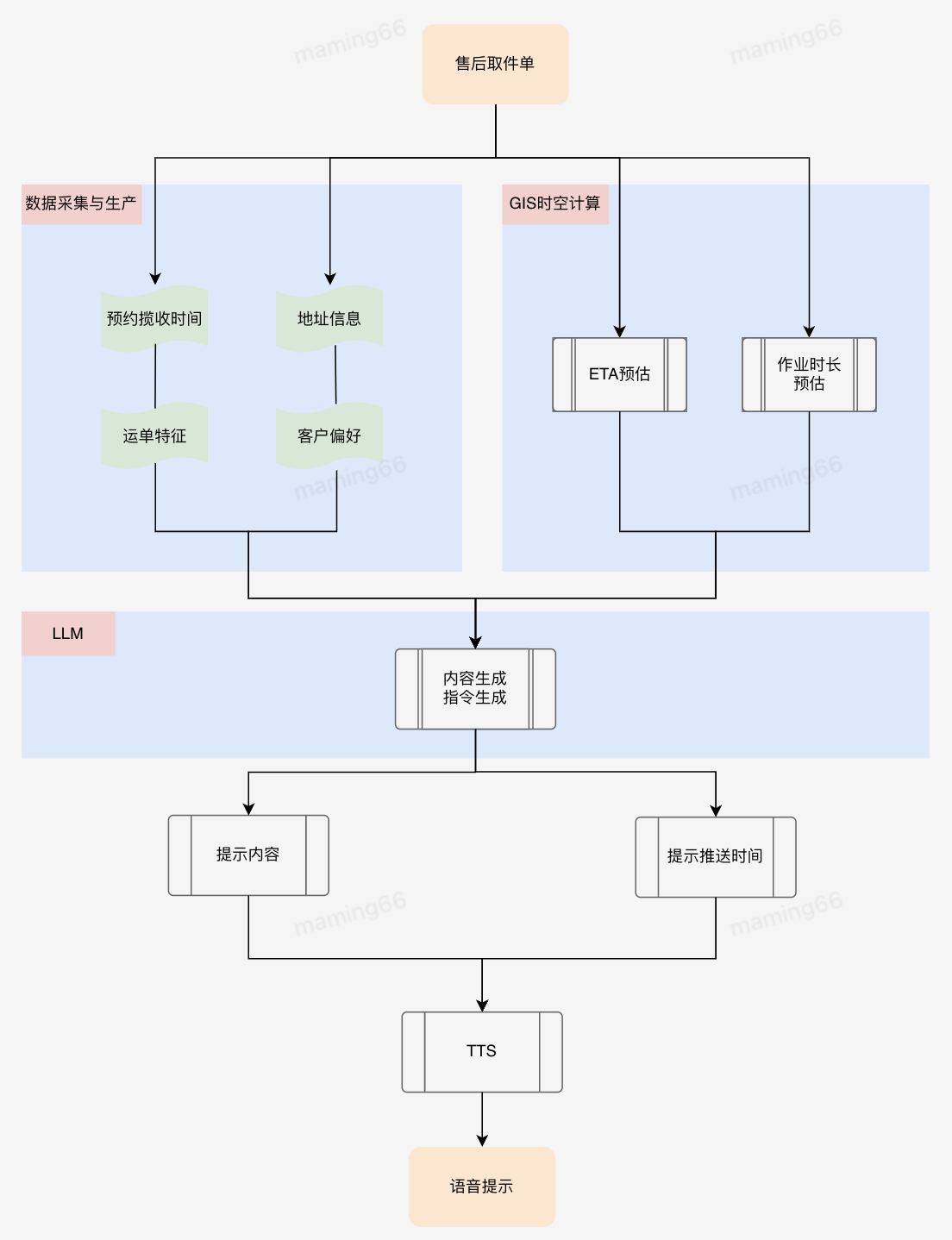
提示的差異對比如下:

五、智能體
以GPTs為代表的大模型智能體帶給了人們非常震撼的功能效果,引起的社會關注度遠超之前任何一項技術的出現。但是OpenAI也坦言在智能體這個領域,自己并沒有比其他公司掌握的更多,這也是目前很多科技公司在同一起跑線上奮力奔跑的機遇。
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators.
—— Stuart J. Russell and Peter Norvig
在智能操作、問答、提示的實踐過程中,我們積累了模型、Prompt、知識庫、微調等相關經驗,但是在模型編排、領域模型訓練、安全性等方面需要進一步學習和應用。同時我們也在探索終端智能體對業務異常分析、定位和解決的能力。
審核編輯 黃宇
-
機器人
+關注
關注
213文章
29508瀏覽量
211633 -
GPT
+關注
關注
0文章
368瀏覽量
15951 -
OpenAI
+關注
關注
9文章
1202瀏覽量
8650 -
大模型
+關注
關注
2文章
3033瀏覽量
3837
發布評論請先 登錄
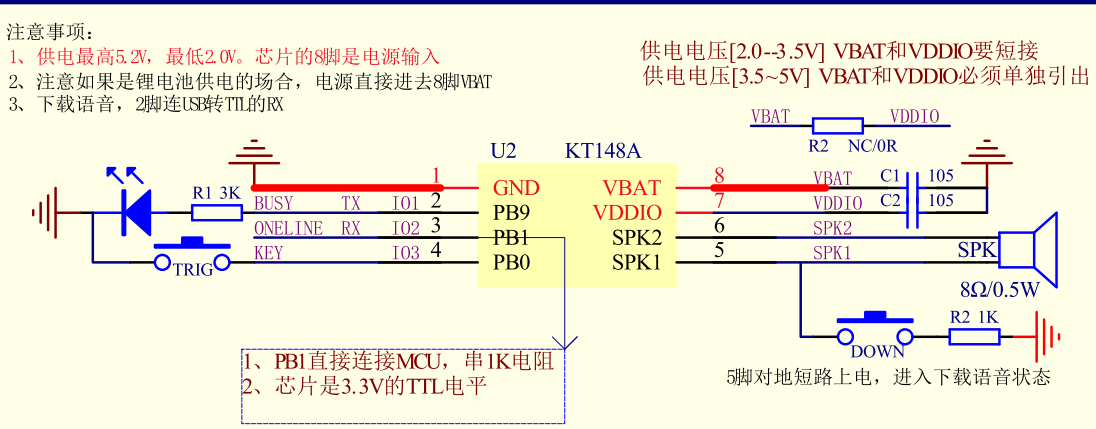
KT148A語音芯片的一線通訊起始信號6ms,一幀數據有幾個起始信號
長沙躋身“數字經濟新一線城市”
利用RAKsmart服務器托管AI模型訓練的優勢
浪潮軟件率先推出政務服務大模型,重塑全場景應用
智慧巡檢新裝備:頂堅防爆手持終端如何為一線人員減負增效

添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
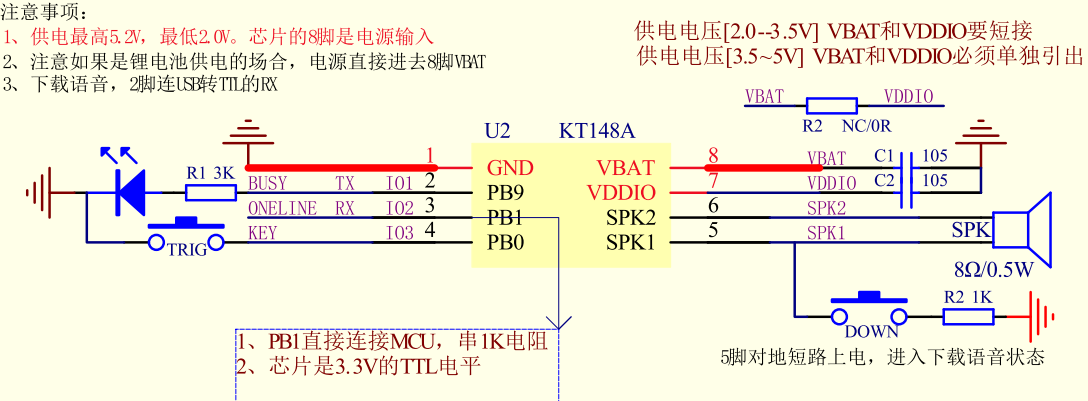
KT148A語音芯片一線串口和5V單片機MCU相連需要串電阻嗎?
澎峰科技攜手湖南第一師范,開啟大模型AI學習新模式

USB一線通監控副屏設計方案
名單公布!【書籍評測活動NO.49】大模型啟示錄:一本AI應用百科全書
本源量子榮獲2024金融科技場景應用大賽“探索實踐獎”

神話游戲熱浪推動文化輸出,第一線全棧云網安服務助力游戲企業加速全球化部署

我在大模型應用之RAG方向的探索、實踐與思考
KT148A-SOP8語音芯片接收到一線串口指令到播放聲音大概多長時間





 工商網監
工商網監
評論