 閉卷開考全國一卷,AI大模型高考數學全部不及格?!
閉卷開考全國一卷,AI大模型高考數學全部不及格?!

電子發燒友網報道(文/周凱揚)當下的大模型除了卷商業化變現外,又開辟出了一個新的“賽博斗蛐蛐”賽道,以各種評測標準來測試大模型在語言、數學、推理和代碼方面的綜合成績。作為國內最權威的考試之一,高考則是最能代表學生綜合能力的一次考驗,而大模型這個特殊身份的考生,如果參加高考究竟會獲得怎樣的成績,也激起了網友的好奇之心。
上海人工智能實驗室的大模型評測體系OpenCompass在近日舉辦了這么一次測試,讓6大開源模型和GPT-4o參加一次特殊的“高考”,然而這些大模型獲得的成績卻讓不少人大跌眼鏡。
閉卷開考全國一卷
在這次大模型參加高考中,OpenCompass的首輪測試采用了全國新課標I卷的語數外試卷作為題源,該卷的覆蓋省份包括江蘇、浙江、河北、福建、山東、湖北、湖南、廣東等。為了方便測試,除了省去其他非統一學科外,其中英語省去了30分的聽力,所以其單科總分變為了120分。
為了做到“閉卷”,這些受測的模型中,包括Mistral的開源對話模型Mixtral 8x22B、零一萬物的Yi-1.5-34B大模型、智譜AI的GLM-4-9B、上海人工智能實驗室推出的InternLM2-20B-WQX大語言模型以及阿里巴巴的Qwen2-57B和Qwen2-72B。
以上開源模型的開源時間均早于本屆高考,發布時間最新的是InternLM專門在高考前夕推出的文曲星系列大模型,InternLM2-WQX。即便如此,其發布于6月4日的時間也滿足了閉卷考試的前提。唯一的例外是商用閉源模型GPT-4o,但其成績也僅僅是作為評測參考。
在閱卷評分上,OpenCompass請到了多位有閱卷經驗的高中教師對主觀題答案進行評分,每份考卷都由至少3位教師評閱取平均分,甚至對分差較大的題目進行了二次審核。另外值得關注的是,為了保證閱卷老師在主客觀題上產生對大模型“先入為主”的觀念,OpenCompass在閱卷之后才告知閱卷老師答案由大模型生成,并對成績做一個整體分析。
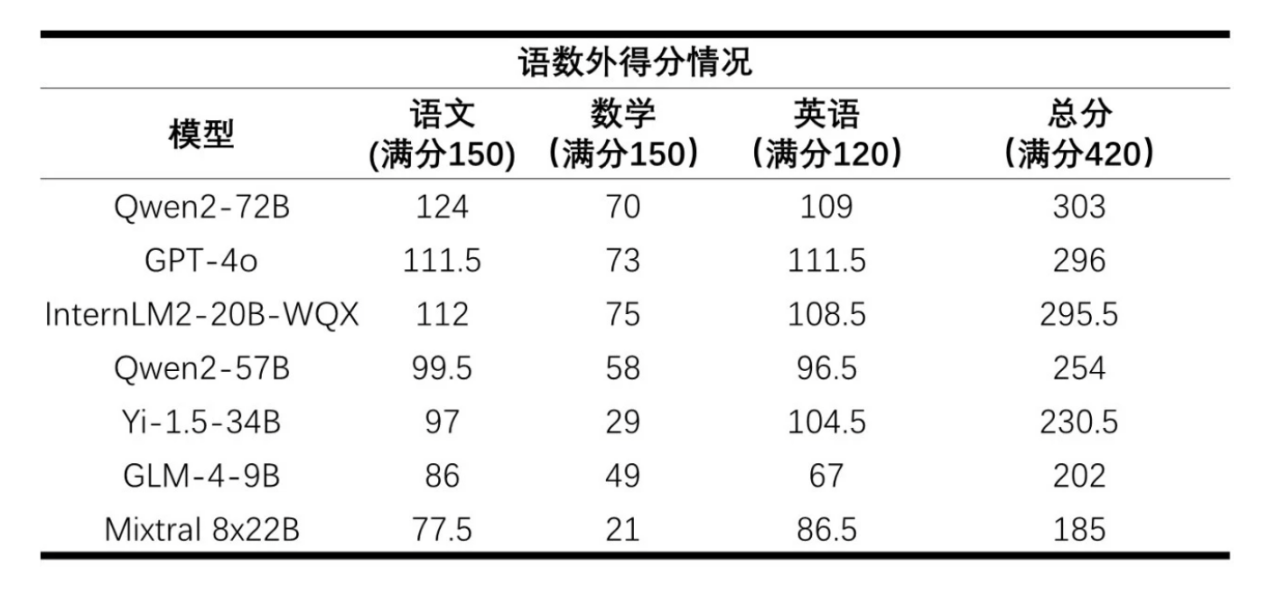
AI大模型高考語數外得分 / 上海人工智能實驗室
從總分來看,阿里巴巴的通義千問大模型Qwen2-72B排名第一,其次是成績相近的GPT-4o和InternLM2-20B-WQX。然而單從數學這一門科目來看,所有的大模型都沒有及格,Mixtral 8x22B甚至只獲得了21分的成績。
語言能力依然是LLM的強項,但“應試”能力仍有提升空間
在這次“高考測試”中,不少大模型都在語文和英語上獲得了不錯的成績,尤其是在英語試卷上,GPT-4o更是在英語上獲得了111.5的高分。在語文上,還是國內的模型更具優勢,尤其是在文言文閱讀、古詩文閱讀和名句默寫上。
有趣的一點是,在語文作文上,各大模型都沒有拉開較大差距。但據上海人工智能實驗室的觀察,大模型的作文都傾向于將“首先”“其次”和“然后”這樣表達先后順序的詞放在段首。此外,目前多數大模型都沒有對一些“應試”類題型做出優化,比如在語文考試中,閱讀理解中的一些本體、喻體、暗喻等概念,大模型尚不能完全理解,所以在語言文字運用題型上,比如補寫句子等題目就普遍得分不高。
而在英語考試中,盡管各大模型整體表現良好,但部分模型并不適應完形填空、七選五這樣非傳統問答式的題型,會出現答案錯位的情況,因此得分率依然處于一個較低的水平。
在英語續寫和作文的撰寫上,大模型都存在忽略題目要求的現象,普遍出現了超出字數限制而扣分的情況,且單段文字過長。在故事續寫這樣的題型中,部分大模型也會展開不合實際的聯想,比如InternLM2-20B-WQX的作答中,就出現了出租車內司機撥通銀行內線電話的離譜情節。
數學不及格,主觀問答題成為最大短板
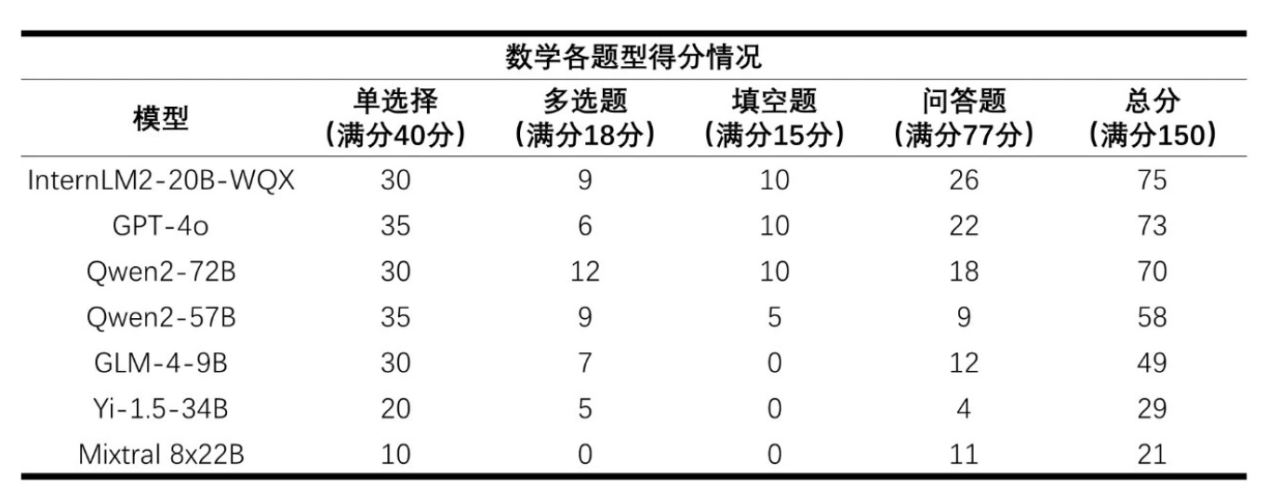
AI大模型數學各題型得分 / 上海人工智能實驗室
相較語言能力測試成績,AI大模型在數學能力測試上獲得的成績就顯得不盡如人意了。最高分為InternLM2-20B-WQX取得的75分,可以說在數學這門學科上,幾乎所有的大模型都敗下陣來。全國新課標I卷的數學試卷中存在兩道帶圖題,對于不支持多模態輸入的大模型而言,只能選擇輸入題干文字從而將圖片舍棄,這也是失分嚴重的原因之一。

Qwen2-72B的帶圖題答案 / 上海人工智能實驗室
以上圖中的帶圖題答案為例,大模型僅僅給出了一個解題框架,并沒有給出具體數值的答案。GPT-4o和InternLM2-20B-WQX等大模型雖然給出了具體答案和解題過程,但最終得到的是一個錯誤的答案。
之所以InternLM2-20B-WQX能在數學考試上獲得相對較高的成績,也歸功于其團隊在數學大模型上的積累。今年年初InternLM發布了數學模型書生·浦語數學(InternLM2-Math)。書生·浦語數學也是首個同時支持形式化數學語言以及解題過程評價的開源模型,如此一來不僅可以用于數學計算解答,也可以用于數學基礎研究和教學。
盡管如此,在數學考試的問答主觀題上,大模型依然成績慘淡。這是因為大模型的回答多數比較凌亂,也出現了不少常見的錯誤解答但答案正確的現象。所以在77分滿分的問答題上,最高的InternLM2-20B-WQX也只僅僅得了26分。
AI大模型是不合格的考生嗎?
根據閱卷老師的點評來看,AI大模型依然還是一個比較“死板”的考生,尤其是在主觀題上。以語文的主觀題為例,很多大模型在第一步審題就失敗了,所以答非所問。在英語題目上,大模型的實力還是毋庸置疑的,但還是會在題型和作文中出現紕漏。
至于數學依然是所有大模型的弱項,大模型更像是記住了公式但不會運用的學生,在大部分題目上更傾向于窮舉而非推理。至于帶圖的立體幾何解答題,大模型更是缺乏空間概念,導致出現離譜的解答過程和答案。由此看來,大模型的“應試”能力依然有所欠缺,但在飛速迭代下,相信未來這種障礙會越來越少。
-
AI
+關注
關注
88文章
35168瀏覽量
280173 -
AI大模型
+關注
關注
0文章
376瀏覽量
620
發布評論請先 登錄
太強了!AI PC搭載70B大模型,算力狂飆,內存開掛

湖北移動攜手華為打造AI WAN SPN智慧教育專網
學校時鐘系統,標準考場時鐘系統,AI亮相2025高考,賽思時鐘系統為教育公平筑起“精準防線”

廣凌標準化考場建設整體解決方案——全力維護高考安全公平考試環境

高考考場上,除了身份證人臉識別一體機,還有哪些高科技設備?

首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
大模型的數學能力或許一直都在關鍵在于如何喚醒它







 工商網監
工商網監
評論