") AI初出企業(yè)Cerebras已申請IPO!稱發(fā)布的AI芯片比GPU更適合大模型訓(xùn)練
AI初出企業(yè)Cerebras已申請IPO!稱發(fā)布的AI芯片比GPU更適合大模型訓(xùn)練
電子發(fā)燒友網(wǎng)報道(文/李彎彎)近日,據(jù)外媒報道,研發(fā)出世界最大芯片的明星AI芯片獨角獸Cerebras Systems已向證券監(jiān)管機構(gòu)秘密申請IPO。
Cerebras成立于2016年,總部在美國加州,專注于研發(fā)比GPU更適用于訓(xùn)練AI模型的晶圓級芯片,為復(fù)雜的AI應(yīng)用構(gòu)建計算機系統(tǒng),并與阿布扎比科技集團G42等機構(gòu)合作構(gòu)建超級計算機。基于其最新旗艦芯片構(gòu)建的服務(wù)器可輕松高效地訓(xùn)練萬億參數(shù)模型。
Cerebras已發(fā)布第三代AI芯片
技術(shù)實力方面,Cerebras公司采用獨特的晶圓級集成技術(shù),將整片晶圓作為一個單獨的芯片來使用,實現(xiàn)了前所未有的集成度和性能。這種技術(shù)使得Cerebras的AI芯片在晶體管數(shù)量、計算能力和內(nèi)存帶寬等方面均達(dá)到了業(yè)界領(lǐng)先水平。
Cerebras的AI芯片具有強大的計算能力,能夠支持訓(xùn)練業(yè)界最大的AI模型,包括參數(shù)規(guī)模高達(dá)數(shù)十萬億個的模型。這種高性能計算能力使得研究人員能夠更快地測試想法、使用更多數(shù)據(jù)并解決新問題。
Cerebras的AI芯片采用了先進的通信架構(gòu),實現(xiàn)了全局性的低延遲、高帶寬通信。這種通信架構(gòu)使得多個Cerebras芯片之間能夠高效地進行數(shù)據(jù)傳輸和協(xié)作,進一步提升了AI應(yīng)用的性能。
產(chǎn)品方面,Cerebras的核心產(chǎn)品線WSE(Wafer Scale Engine)系列已經(jīng)過更新三代。2019年8月,Cerebras發(fā)布第一顆芯片WSE,WSE作為Cerebras標(biāo)志性產(chǎn)品,是史上最大的AI芯片之一。其設(shè)計突破了傳統(tǒng)半導(dǎo)體制造的界限,采用了獨特的晶圓級集成(Wafer-Scale Integration, WSI)技術(shù),將整個晶圓作為一個單獨的芯片來使用,這在當(dāng)時是前所未有的。
這顆芯片采用臺積電16nm制程,在46225mm2面積上集成了40萬個AI核心和1.2萬億顆晶體管。同時,該芯片配備了18GB的片上靜態(tài)隨機存取存儲器(SRAM),這一容量遠(yuǎn)大于大多數(shù)芯片的片外存儲(DDR)。帶寬達(dá)到100Pb/s(1Pb=1000TB),這一數(shù)值比現(xiàn)有芯片的相關(guān)參數(shù)高出一個單位(3個數(shù)量級)。
2021年,Cerebras推出第二代芯片WSE-2,搭載WSE-2芯片的AI超算系統(tǒng)CS-2也同期發(fā)布。WSE-2在繼承了WSE的晶圓級集成技術(shù)的基礎(chǔ)上,進一步提升了制程工藝和性能,成為當(dāng)時業(yè)界領(lǐng)先的AI芯片之一。該芯片采用臺積電7nm制程,相較于前代產(chǎn)品WSE的16nm工藝,進一步縮小了晶體管的尺寸,提高了集成度。與WSE相同,WSE-2也采用了整片晶圓作為單一芯片,面積約為462255mm2。晶體管數(shù)量達(dá)到了創(chuàng)紀(jì)錄的2.6萬億個,相較于WSE的1.2萬億個晶體管,實現(xiàn)了翻倍的增長。
WSE-2集成了85萬個專為AI應(yīng)用優(yōu)化的稀疏線性代數(shù)計算(SLAC)核心,相較于WSE的40萬個核心,有了顯著的提升。片上內(nèi)存提升至40GB,相較于WSE的18GB,增加了近一倍。內(nèi)存帶寬高達(dá)20PB/s,相較于WSE的9PB/s,也有了顯著的提升。
今年3月,Cerebras推出了第三代晶圓級芯片WSE-3和AI超級計算機CS-3。WSE-3采用臺積電5nm制程,有90萬個AI核心和4萬億顆晶體管。配備了44GB的片上SRAM緩存,相較于前代產(chǎn)品有了顯著提升。這一大容量片上內(nèi)存能夠支持更大規(guī)模的AI模型訓(xùn)練,無需進行分區(qū)或重構(gòu),大大簡化了訓(xùn)練工作流程。WSE-3的內(nèi)存帶寬高達(dá)21PB/s,峰值A(chǔ)I算力高達(dá)125 PetaFLOPS,相當(dāng)于每秒能夠執(zhí)行12.5億億次浮點計算。
Cerebras 的AI芯片被認(rèn)為更適合大模型訓(xùn)練
Cerebras的芯片被認(rèn)為比GPU更適合用于大模型訓(xùn)練。其WSE系列芯片具有龐大的規(guī)模和驚人的性能。例如,WSE-3擁有超過4萬億個晶體管和46225mm2的硅片面積,堪稱全球最大的AI芯片。與之相比,傳統(tǒng)GPU的規(guī)模和性能通常較小。Cerebras的芯片能夠在單個設(shè)備上容納和訓(xùn)練比當(dāng)前熱門模型大得多的下一代前沿模型。
Cerebras的芯片搭載了大量的核心和內(nèi)存。例如,WSE-3擁有900,000個核心和44GB內(nèi)存,這使得它能夠同時處理大量的數(shù)據(jù)和計算任務(wù)。傳統(tǒng)GPU的核心數(shù)量和內(nèi)存通常較小,可能需要多個GPU協(xié)同工作才能達(dá)到類似的性能。
Cerebras采用了片上內(nèi)存的設(shè)計,這意味著內(nèi)存和計算核心都在同一個芯片上,從而大大減少了數(shù)據(jù)傳輸?shù)拈_銷和延遲。相比之下,傳統(tǒng)GPU的內(nèi)存和計算核心是分離的,需要通過PCIe等接口進行數(shù)據(jù)傳輸,這可能導(dǎo)致性能瓶頸和延遲。
Cerebras的CS-3系統(tǒng)是基于WSE-3推出的,具備強大的系統(tǒng)支持。該系統(tǒng)擁有高達(dá)1.2PB的內(nèi)存容量,能夠訓(xùn)練比GPT-4和Gemini模型大10倍的下一代前沿模型。在大模型訓(xùn)練中,Cerebras的CS-3系統(tǒng)相較于GPU具有更低的代碼復(fù)雜性和更高的易用性。開發(fā)人員可以更加高效地實現(xiàn)和訓(xùn)練大模型。
Cerebras的芯片通過保持整個晶圓的完整性來降低互連和網(wǎng)絡(luò)成本以及功耗。這使得Cerebras的芯片在功耗和成本方面相較于多個GPU協(xié)同工作具有優(yōu)勢。
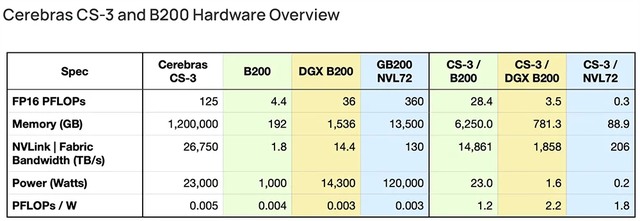
今年4月,Cerebras發(fā)文比較Cerebras CS-3與英偉達(dá)B200,稱CS-3和英偉達(dá)DGX B200是2024年上市的兩款最令人興奮的AI硬件新品。從對比數(shù)據(jù)來看,無論AI訓(xùn)練性能還是能效,CS-3都做到倍殺DGX B200。
寫在最后
目前,AI大模型訓(xùn)練基本離不開GPU的支持,Cerebras發(fā)布的WSE系列芯片,給業(yè)界帶來了新的思路,尤其是其今年發(fā)布的第三代產(chǎn)品WSE-3,能夠支持訓(xùn)練業(yè)界最大的AI模型,包括參數(shù)規(guī)模高達(dá)24萬億個的模型。如果其能夠順利上市,一是對于其自身后續(xù)發(fā)展更有利,二是對于英偉達(dá)來說它可能會成長為一個較大的競爭對手。
-
gpu
+關(guān)注
關(guān)注
28文章
4788瀏覽量
129422 -
ipo
+關(guān)注
關(guān)注
1文章
1218瀏覽量
32714 -
AI芯片
+關(guān)注
關(guān)注
17文章
1911瀏覽量
35244 -
大模型
+關(guān)注
關(guān)注
2文章
2603瀏覽量
3215
發(fā)布評論請先 登錄
相關(guān)推薦
GPU是如何訓(xùn)練AI大模型的
亞馬遜轉(zhuǎn)向Trainium芯片,全力投入AI模型訓(xùn)練
訓(xùn)練AI大模型需要什么樣的gpu
為什么ai模型訓(xùn)練要用gpu
AI大模型的訓(xùn)練數(shù)據(jù)來源分析
如何訓(xùn)練自己的AI大模型
Cerebras提交IPO申請,估值達(dá)41億美元
GPU服務(wù)器在AI訓(xùn)練中的優(yōu)勢具體體現(xiàn)在哪些方面?
蘋果AI模型訓(xùn)練新動向:攜手谷歌,未選英偉達(dá)
蘋果承認(rèn)使用谷歌芯片來訓(xùn)練AI
ai大模型和ai框架的關(guān)系是什么
AI初創(chuàng)公司Cerebras秘密申請IPO
摩爾線程與師者AI攜手完成70億參數(shù)教育AI大模型訓(xùn)練測試
AI訓(xùn)練,為什么需要GPU?

最強AI芯片發(fā)布,Cerebras推出性能翻倍的WSE-3 AI芯片






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論