") 用于自然語言處理的神經(jīng)網(wǎng)絡(luò)有哪些
用于自然語言處理的神經(jīng)網(wǎng)絡(luò)有哪些
自然語言處理(Natural Language Processing, NLP)是人工智能領(lǐng)域的一個重要分支,旨在讓計算機能夠理解和處理人類語言。隨著深度學習技術(shù)的飛速發(fā)展,神經(jīng)網(wǎng)絡(luò)模型在NLP領(lǐng)域取得了顯著進展,成為處理自然語言任務(wù)的主要工具。本文將詳細介紹幾種常用于NLP的神經(jīng)網(wǎng)絡(luò)模型,包括遞歸神經(jīng)網(wǎng)絡(luò)(RNN)、長短時記憶網(wǎng)絡(luò)(LSTM)、卷積神經(jīng)網(wǎng)絡(luò)(CNN)、變換器(Transformer)以及預(yù)訓練模型如BERT等。
一、遞歸神經(jīng)網(wǎng)絡(luò)(RNN)
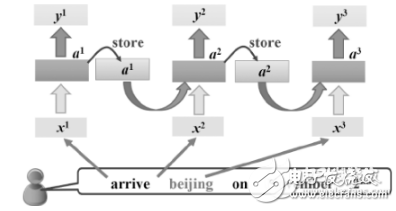
遞歸神經(jīng)網(wǎng)絡(luò)是一種能夠處理序列數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò),其結(jié)構(gòu)類似于鏈表,特別適合于處理具有時間依賴性的數(shù)據(jù)。在自然語言處理中,RNN被廣泛應(yīng)用于文本分類、語言建模、情感分析、命名實體識別等任務(wù)。
1. 基本原理
RNN的核心思想是通過將前面的信息傳遞到后面來捕捉序列數(shù)據(jù)中的依賴關(guān)系。具體來說,RNN中的每個節(jié)點都有一個隱藏狀態(tài),用于存儲之前的信息,并將其傳遞到下一個節(jié)點。通過這種方式,RNN能夠記憶之前的信息并利用它們來預(yù)測下一個單詞或字符等。
2. 優(yōu)缺點
優(yōu)點 :
- 能夠處理任意長度的序列數(shù)據(jù)。
- 能夠記憶并利用序列中的歷史信息。
缺點 :
- 存在梯度消失和梯度爆炸的問題,難以捕捉長距離依賴關(guān)系。
- 不支持并行處理,計算效率較低。
3. 應(yīng)用場景
RNN適用于需要處理序列數(shù)據(jù)的任務(wù),如文本生成、機器翻譯等。然而,由于其缺點,RNN在處理長文本時性能受限,因此在實際應(yīng)用中常被LSTM等變體模型所取代。
二、長短時記憶網(wǎng)絡(luò)(LSTM)
長短時記憶網(wǎng)絡(luò)是RNN的一種變體,通過引入門控機制來解決傳統(tǒng)RNN存在的梯度消失和梯度爆炸問題。LSTM在自然語言處理領(lǐng)域的應(yīng)用非常廣泛,特別是在機器翻譯、文本分類、情感分析等方面。
1. 基本結(jié)構(gòu)
LSTM的模型結(jié)構(gòu)包括三個門控單元:輸入門、遺忘門和輸出門。這些門分別負責控制新信息的輸入、舊信息的遺忘和輸出的內(nèi)容。LSTM的關(guān)鍵在于它的記憶單元,它能夠記住歷史信息并將其傳遞到后續(xù)的時間步中。
2. 優(yōu)缺點
優(yōu)點 :
- 能夠處理長序列數(shù)據(jù),捕捉長距離依賴關(guān)系。
- 解決了RNN的梯度消失和梯度爆炸問題。
缺點 :
- 參數(shù)較多,計算復(fù)雜度較高。
- 仍然不支持并行處理。
3. 應(yīng)用場景
LSTM適用于需要處理長序列數(shù)據(jù)的任務(wù),如機器翻譯、問答系統(tǒng)等。在這些任務(wù)中,LSTM能夠記住歷史信息并利用它們來生成更準確的輸出。
三、卷積神經(jīng)網(wǎng)絡(luò)(CNN)
卷積神經(jīng)網(wǎng)絡(luò)是一種能夠?qū)W習局部特征的神經(jīng)網(wǎng)絡(luò),在計算機視覺領(lǐng)域取得了巨大成功。近年來,CNN也在自然語言處理領(lǐng)域得到了應(yīng)用,特別是在文本分類、情感分析等任務(wù)中。
1. 基本原理
CNN中的核心是卷積層,卷積層通過在輸入數(shù)據(jù)上滑動一個指定大小的窗口來提取不同位置的特征。這些特征被進一步處理并輸出一個固定維度的向量表示。為了處理序列數(shù)據(jù),通常需要在卷積層上添加池化層或全局平均池化層來提取序列數(shù)據(jù)的局部或全局特征。
2. 優(yōu)缺點
優(yōu)點 :
- 能夠并行處理數(shù)據(jù),計算效率高。
- 能夠捕捉局部特征并減少計算量。
缺點 :
- 相比RNN和LSTM,CNN在處理序列數(shù)據(jù)時難以捕捉長距離依賴關(guān)系。
- 需要固定長度的輸入序列。
3. 應(yīng)用場景
CNN適用于處理定長序列數(shù)據(jù)的任務(wù),如文本分類、情感分析等。在這些任務(wù)中,CNN能夠高效地提取文本特征并進行分類或情感判斷。
四、變換器(Transformer)
變換器是一種基于注意力機制的模型,能夠處理語音、文本等序列數(shù)據(jù)。在自然語言處理領(lǐng)域,Transformer被廣泛應(yīng)用于機器翻譯、文本分類等任務(wù),并取得了顯著成效。
1. 基本原理
Transformer模型主要由編碼器(Encoder)和解碼器(Decoder)兩部分組成。編碼器負責將輸入序列轉(zhuǎn)換為一系列隱藏狀態(tài)表示,而解碼器則利用這些隱藏狀態(tài)表示來生成輸出序列。Transformer的核心是注意力機制,它能夠通過計算輸入數(shù)據(jù)之間的相關(guān)性來動態(tài)地調(diào)整模型的注意力分配。
2. 優(yōu)缺點
優(yōu)點 :
- 能夠并行處理數(shù)據(jù),計算效率高。
- 能夠捕捉長距離依賴關(guān)系。
- 相比RNN和LSTM,Transformer在訓練過程中更容易優(yōu)化。
缺點 :
- 需要大量的訓練數(shù)據(jù)和計算資源。
- 對于短文本或單個單詞級別的任務(wù)可能不如RNN或LSTM有效。
3. 應(yīng)用場景
Transformer適用于需要處理長序列數(shù)據(jù)且對計算效率有較高要求的### 場景的任務(wù),如機器翻譯、文本摘要、語音識別等。
在機器翻譯中,Transformer憑借其出色的長距離依賴捕捉能力和高效的并行計算能力,顯著提升了翻譯的質(zhì)量和速度。相比傳統(tǒng)的基于RNN或LSTM的模型,Transformer能夠更準確地理解源語言的語義信息,并生成更流暢、更自然的目標語言文本。
在文本摘要領(lǐng)域,Transformer同樣表現(xiàn)出色。它能夠從長文本中快速提取關(guān)鍵信息,并生成簡潔明了的摘要。這一能力得益于Transformer的注意力機制,使得模型能夠?qū)W⒂谖谋局械闹匾糠郑雎缘羧哂嗷驘o關(guān)的信息。
此外,Transformer還被廣泛應(yīng)用于語音識別任務(wù)中。通過結(jié)合語音信號的時序特性和Transformer的注意力機制,模型能夠更準確地識別語音中的單詞和句子,提高語音識別的準確率和魯棒性。
五、預(yù)訓練模型:BERT及其變體
近年來,預(yù)訓練模型在自然語言處理領(lǐng)域引起了廣泛關(guān)注。BERT(Bidirectional Encoder Representations from Transformers)是一種基于Transformer結(jié)構(gòu)的預(yù)訓練模型,它通過在大規(guī)模文本數(shù)據(jù)上進行無監(jiān)督學習,獲得了豐富的語言表示能力。
1. 基本原理
BERT的核心思想是利用大規(guī)模語料庫進行預(yù)訓練,學習文本中單詞和句子的上下文表示。在預(yù)訓練階段,BERT采用了兩種任務(wù):遮蔽語言模型(Masked Language Model, MLM)和下一句預(yù)測(Next Sentence Prediction, NSP)。MLM任務(wù)通過隨機遮蔽輸入文本中的一部分單詞,要求模型預(yù)測這些被遮蔽的單詞;NSP任務(wù)則要求模型判斷兩個句子是否是連續(xù)的文本片段。這兩個任務(wù)共同幫助BERT學習文本中的語言知識和語義關(guān)系。
2. 優(yōu)缺點
優(yōu)點 :
- 強大的語言表示能力,能夠捕捉豐富的上下文信息。
- 靈活的遷移學習能力,可以方便地應(yīng)用于各種NLP任務(wù)。
- 提高了模型的泛化能力和性能。
缺點 :
- 需要大量的計算資源和訓練數(shù)據(jù)。
- 模型參數(shù)較多,計算復(fù)雜度較高。
3. 應(yīng)用場景
BERT及其變體模型被廣泛應(yīng)用于各種NLP任務(wù)中,包括文本分類、命名實體識別、問答系統(tǒng)、文本生成等。通過微調(diào)(Fine-tuning)預(yù)訓練模型,可以將其快速適應(yīng)到特定的NLP任務(wù)中,并取得優(yōu)異的性能表現(xiàn)。例如,在文本分類任務(wù)中,可以通過微調(diào)BERT模型來學習不同類別的文本特征;在問答系統(tǒng)中,可以利用BERT模型來理解和回答用戶的問題;在文本生成任務(wù)中,可以借助BERT模型來生成連貫、自然的文本內(nèi)容。
六、未來展望
隨著深度學習技術(shù)的不斷發(fā)展和計算資源的日益豐富,神經(jīng)網(wǎng)絡(luò)在自然語言處理領(lǐng)域的應(yīng)用將會更加廣泛和深入。未來,我們可以期待以下幾個方面的進展:
- 更高效的模型架構(gòu) :研究人員將繼續(xù)探索更加高效、更加適合NLP任務(wù)的神經(jīng)網(wǎng)絡(luò)架構(gòu),以提高模型的計算效率和性能。
- 更豐富的預(yù)訓練任務(wù) :除了現(xiàn)有的MLM和NSP任務(wù)外,未來可能會引入更多種類的預(yù)訓練任務(wù)來進一步豐富模型的語言表示能力。
- 跨語言理解和生成 :隨著全球化的加速和互聯(lián)網(wǎng)的發(fā)展,跨語言理解和生成將成為NLP領(lǐng)域的一個重要研究方向。未來的模型將能夠更好地理解和生成多種語言的文本內(nèi)容。
- 多模態(tài)融合 :未來的NLP系統(tǒng)可能會融合文本、圖像、語音等多種模態(tài)的信息,以實現(xiàn)更加全面、準確的理解和生成能力。
總之,神經(jīng)網(wǎng)絡(luò)在自然語言處理領(lǐng)域的應(yīng)用前景廣闊,我們有理由相信,在未來的發(fā)展中,神經(jīng)網(wǎng)絡(luò)將繼續(xù)推動NLP技術(shù)的進步和應(yīng)用拓展。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103054 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14059 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22530
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)模型用于解決什么樣的問題 神經(jīng)網(wǎng)絡(luò)模型有哪些
RNN在自然語言處理中的應(yīng)用
自然語言處理中的卷積神經(jīng)網(wǎng)絡(luò)的詳細資料介紹和應(yīng)用
淺談圖神經(jīng)網(wǎng)絡(luò)在自然語言處理中的應(yīng)用簡述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論