") 如何構(gòu)建三層bp神經(jīng)網(wǎng)絡模型
如何構(gòu)建三層bp神經(jīng)網(wǎng)絡模型
- 引言
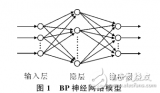
BP神經(jīng)網(wǎng)絡(Backpropagation Neural Network)是一種前饋神經(jīng)網(wǎng)絡,通過反向傳播算法進行訓練。三層BP神經(jīng)網(wǎng)絡由輸入層、隱藏層和輸出層組成,具有較好的泛化能力和學習能力。本文將介紹如何構(gòu)建三層BP神經(jīng)網(wǎng)絡模型。
- 神經(jīng)網(wǎng)絡基礎知識
2.1 神經(jīng)元模型
神經(jīng)元是神經(jīng)網(wǎng)絡的基本單元,每個神經(jīng)元接收輸入信號,通過激活函數(shù)處理后輸出信號。一個神經(jīng)元的數(shù)學模型可以表示為:
y = f(∑(w_i * x_i + b))
其中,x_i是輸入信號,w_i是權(quán)重,b是偏置,f是激活函數(shù)。
2.2 激活函數(shù)
激活函數(shù)用于將神經(jīng)元的輸入信號轉(zhuǎn)換為輸出信號。常見的激活函數(shù)有Sigmoid函數(shù)、Tanh函數(shù)和ReLU函數(shù)等。Sigmoid函數(shù)的數(shù)學表達式為:
f(x) = 1 / (1 + e^(-x))
2.3 損失函數(shù)
損失函數(shù)用于衡量神經(jīng)網(wǎng)絡預測值與真實值之間的差異。常見的損失函數(shù)有均方誤差(MSE)和交叉熵損失(Cross-Entropy Loss)等。
- 三層BP神經(jīng)網(wǎng)絡結(jié)構(gòu)
3.1 輸入層
輸入層是神經(jīng)網(wǎng)絡的第一層,接收外部輸入信號。輸入層的神經(jīng)元數(shù)量與問題的特征維度相同。
3.2 隱藏層
隱藏層是神經(jīng)網(wǎng)絡的中間層,用于提取特征并進行非線性變換。隱藏層的神經(jīng)元數(shù)量可以根據(jù)問題的復雜度進行調(diào)整。通常,隱藏層的神經(jīng)元數(shù)量大于輸入層和輸出層的神經(jīng)元數(shù)量。
3.3 輸出層
輸出層是神經(jīng)網(wǎng)絡的最后一層,用于生成預測結(jié)果。輸出層的神經(jīng)元數(shù)量取決于問題的輸出維度。
- 初始化參數(shù)
在構(gòu)建三層BP神經(jīng)網(wǎng)絡模型之前,需要初始化網(wǎng)絡的參數(shù),包括權(quán)重和偏置。權(quán)重和偏置的初始化方法有以下幾種:
4.1 零初始化
將所有權(quán)重和偏置初始化為0。這種方法簡單,但可能導致神經(jīng)元輸出相同,無法學習有效的特征。
4.2 隨機初始化
將權(quán)重和偏置初始化為小的隨機值。這種方法可以避免神經(jīng)元輸出相同,但可能導致梯度消失或梯度爆炸。
4.3 He初始化
He初始化是一種針對ReLU激活函數(shù)的權(quán)重初始化方法。對于每一層的權(quán)重矩陣W,其元素W_ij的初始化公式為:
W_ij ~ N(0, sqrt(2 / n_j))
其中,n_j是第j個神經(jīng)元的輸入數(shù)量。
4.4 Xavier初始化
Xavier初始化是一種針對Sigmoid和Tanh激活函數(shù)的權(quán)重初始化方法。對于每一層的權(quán)重矩陣W,其元素W_ij的初始化公式為:
W_ij ~ U(-sqrt(6 / (n_i + n_j)), sqrt(6 / (n_i + n_j)))
其中,n_i是第i個神經(jīng)元的輸入數(shù)量,n_j是第j個神經(jīng)元的輸入數(shù)量。
- 前向傳播
前向傳播是神經(jīng)網(wǎng)絡從輸入層到輸出層的信號傳遞過程。在三層BP神經(jīng)網(wǎng)絡中,前向傳播的過程如下:
5.1 輸入層
將輸入信號x傳遞給輸入層的神經(jīng)元。
5.2 隱藏層
對于隱藏層的每個神經(jīng)元,計算其輸入加權(quán)和:
z_j = ∑(w_ij * x_i + b_j)
然后,將輸入加權(quán)和通過激活函數(shù)f轉(zhuǎn)換為輸出信號:
a_j = f(z_j)
5.3 輸出層
對于輸出層的每個神經(jīng)元,同樣計算其輸入加權(quán)和:
z_k = ∑(w_ji * a_j + b_k)
將輸入加權(quán)和通過激活函數(shù)f轉(zhuǎn)換為輸出信號:
y_k = f(z_k)
- 反向傳播
反向傳播是神經(jīng)網(wǎng)絡從輸出層到輸入層的誤差傳遞過程。在三層BP神經(jīng)網(wǎng)絡中,反向傳播的過程如下:
6.1 計算損失梯度
首先,計算輸出層的損失梯度。對于每個輸出神經(jīng)元k,損失梯度可以表示為:
d_Lk = ?L / ?z_k = f'(z_k) * (y_k - t_k)
其中,L是損失函數(shù),t_k是目標值。
-
BP神經(jīng)網(wǎng)絡
關注
2文章
127瀏覽量
30889 -
函數(shù)
+關注
關注
3文章
4374瀏覽量
64383 -
模型
+關注
關注
1文章
3500瀏覽量
50112 -
神經(jīng)元
+關注
關注
1文章
368瀏覽量
18776
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論