 RaftKeeper v2.1.0版本發布,性能大幅提升!
RaftKeeper v2.1.0版本發布,性能大幅提升!
RaftKeeper 是一款高新能分布式共識服務,完全兼容 Zookeeper 但性能更出色,更多關于 RaftKeeer 參考Github,我們將 RaftKeeper 大規模應用到 ClickHouse 場景中,用于解決 ZooKeeper 的性能瓶頸問題,同時 RaftKeeper 也可以用于其它大數據組件比如 HBase。
v2.1.0 作為 v2.0.0 后的重要版本,引入了一系列新特性,包括異步創建 snapshot。該版本的最大亮點在于性能優化:寫請求性能提升 11%,讀寫混合場景更是大幅提升了 118% 。本文將從工程細節的角度深入解析新版本的改進與優化。
一、性能優化效果
在性能測試中,我們使用了raftkeeper-bench工具,測試環境為三個節點組成的集群,每個節點配置為 16 核 CPU、32GB 內存和 100GB 存儲空間。測試對象包括 RaftKeeper v2.1.0、RaftKeeper v2.0.4 和 ZooKeeper 3.7.1,均采用默認配置。
測試分為兩組:
第一組測試純 create 操作的性能,create 操作的 value 大小為 100 字節。結果顯示,RaftKeeper v2.1.0 相較于 v2.0.4 性能提升了 11%,相較于 ZooKeeper 性能提升了 143%。
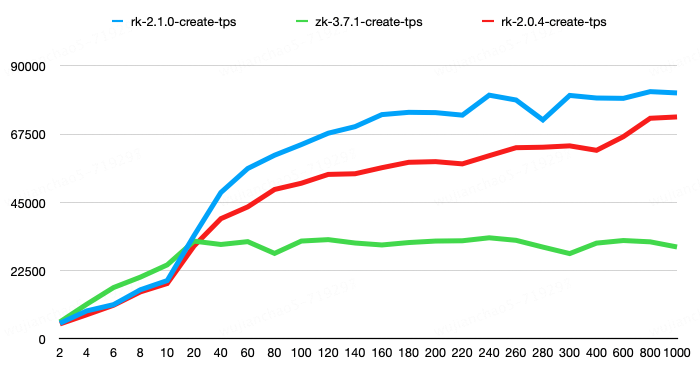
第二組請求比例為 create-1%、set-8%、get-45%、list-45%、delete-1%。其中,list 請求結果包含 100 個子節點,每個子節點大小為 50 字節;get、set、create 請求的節點 value 大小為 100 字節。結果顯示,RaftKeeper v2.1.0 相較于 v2.0.4 性能提升了 118%,相較于 ZooKeeper 性能提升了 198%。
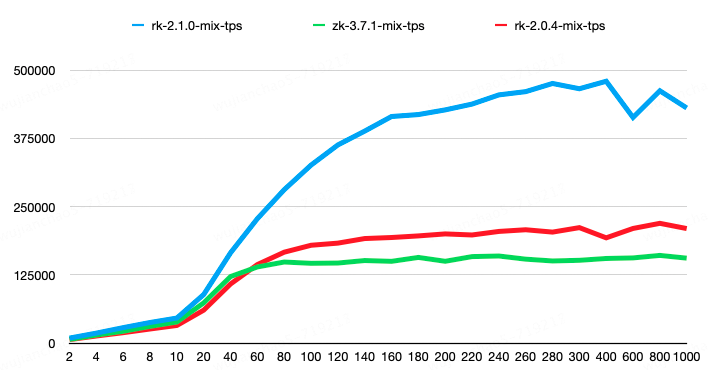
rk2.1.0 版本在測試中 avgRT 和 TP99 指標均優于 rk2.0.4,具體可以參考測試報告。
二、性能優化
接下來從工程細節的角度,介紹一些 v2.1.0 的優化點。
1. 響應并行序列化
RaftKeeper 被我們廣泛應用到 ClickHouse 中,下圖是一個規模較大的 RaftKeeper 集群的火焰圖,通過火焰圖發現 ResponseThread 線程消耗不少 CPU 時間片,其中大概三分之一時間片用于序列化響應。
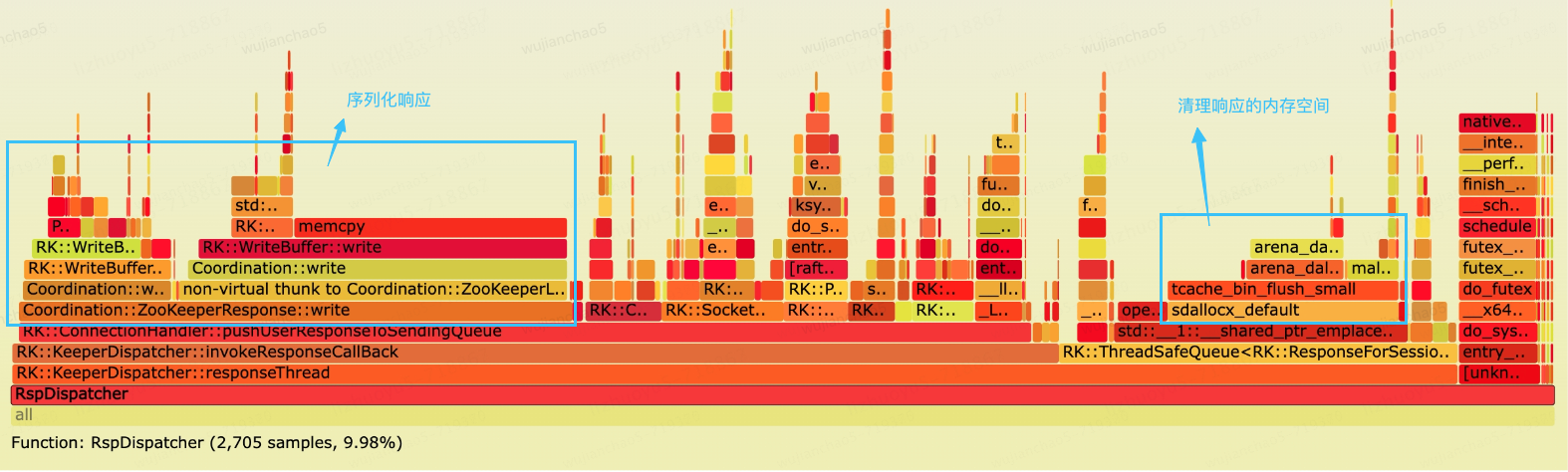
ResponseThread 負責序列化響應并且轉發給 IO 線程,它是一個單線程,串行執行序列化會增大延遲。我們可以把響應的序列化交給 IO 線程來做,以并發的方式提高吞吐。
同時可以看到sdallocx_default函數占用了不少時間片,該函數是 jemelloc 釋放內存的函數,函數對于時間片的消耗沒有問題,但是該操作在基于 mutex 的同步隊列中執行會增加鎖的時間。
/// responses_queue是一個基于mutex的同步隊列,在tryPop方法中釋放response_for_session會增加lock的時間
復制代碼
解決的方式是在 tryPop 方法前先釋放 response_for_session 的內存空間。
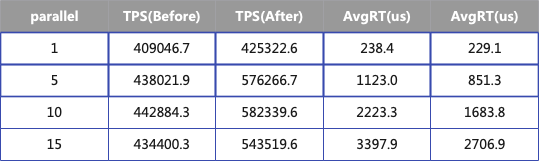
下面的表格展示了優化前后的性能指標,測試共有四組每組使用不同的并發度,其中響應大小為 50bytes,當并發度為 10 的時候,TPS 增加 31%,AvgRT 降低 32%。
2. 優化 List 請求
依然是同一個 RaftKeeper 集群,通過火焰圖發現,List 請求處理幾乎消耗了 request-processor 線程所有的 CPU 時間片。在 RaftKeeper 的執行鏈路中 request-processor 負責處理用戶的請求,它是一個單線程,所以比較容易成為瓶頸點。
通過火焰圖可以發現兩個瓶頸點:1.為字符串分配內存空間;2.插入 vector。
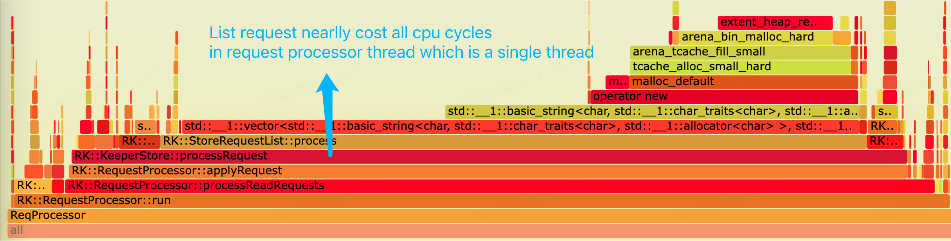
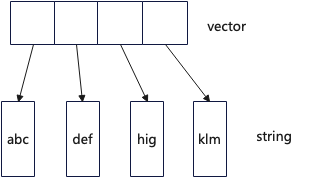
List 請求返回的結果是一個 std::vector動態數組,其內存 layout 如下圖所示,每個成員是一個字符串,每個字符串需要分配一塊動態內存用于保存數據,所以當字符串多的時候需要大量的動態內存分配。
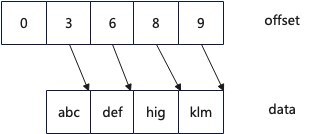
一個很直觀的優化思路,可以設計一個 compact strings,數據采用緊湊的方式存儲,在以下的設計中,采用兩個連續內存空間,一個用于存儲數據,一個用于存儲 offset,具體參考:CompactStrings實現。
優化后從火焰圖方面看 List 請求處理在 CPU 的占比從 5.46%下降到 3.37%,進行 List 請求的 benchmark 測試,TPS 從 45.8w/s 增長到 61.9w/s,同時 TP99 更低。
優化前:
復制代碼
3. 優化無用的系統調用
系統調用會引起用戶態和內核態的上下文切換,往往系統調用函數會有比較大的開銷,我們通過 bpftrace 對 RaftKeeper 進行了 profile
BPFTRACE_MAX_PROBES=1024 bpftrace -p 4179376 -e '
復制代碼
發現大量的getsockname和getsockopt系統調用占用了不少開銷。
Execution count:
復制代碼
這些系統調用本不該存在,經過排查發現是在打印日志的時候錯誤的進行了調用。
const auto socket_name = sock.isStream() ? sock.address().toString() : sock.peerAddress().toString();
復制代碼
4. 線程池優化
下圖是一次 benchmark(讀寫 4:6 的比例)RaftKeeper 的火焰圖,進行性能瓶頸分析發現,發現 request-processor 線程的 CPU 時間片大部分時間(超過 60%)消耗在條件變量等待的調用。
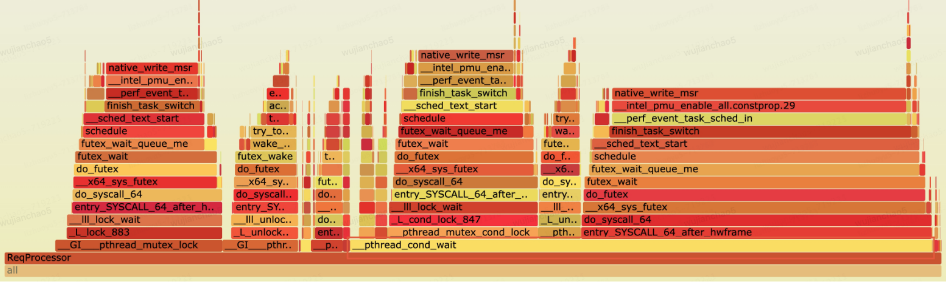
在 RaftKeeper 的主執行鏈路中 request-processor 線程負責處理用戶請求,它的主要流程可以簡單抽象為:1. 對于寫請求,單線程處理;2. 對于讀請求,通過線程池并發處理,然后調用 request_thread->wait()阻塞等待所有讀取請求完成。
/// 1. process read-request by a thread pool
復制代碼
增加監控指標分別統計讀和寫請求的執行時間發現,在讀請求和寫請求數量幾乎相同的情況下,讀請求的處理延時是寫請求的 3 倍。
因為每個請求的處理時間很短,到這里可以推測出,線程池任務調度的時間不可忽視,所以出現了性能下降。解決方式是去掉線程池,單線程處理讀請求,以下 benchmark 是優化前后 benchmark 結果,TPS 提升 13%。
優化前:
復制代碼
三、Snapshot 優化
1. 異步 snapshot
在 RaftKeeper 整個請求處理鏈路中,創建 snapshot 是在主鏈路中進行處理的,當數據量大的時候會長時間阻塞用戶請求,造成請求超時、leader 切換等引起服務不可用的問題,在我們線上場景中對于 6000w 的數據做 snapshot 需要 180s。
為了解決以上問題,新版本中支持了異步 snapshot,當需要創建 snapshot 的時候首先將整個 DataTree 拷貝一份,這一步在主線程中處理,然后在后臺將拷貝的 DataTree 序列化到磁盤中。
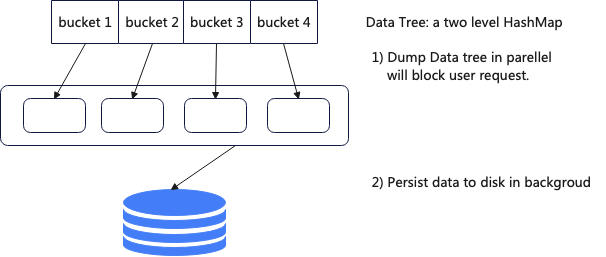
采用這用方式 6000w 的數據做 snaphot 對用戶的阻塞時間從 180s 降低到了 4.5s,但是這種方案也有一些負面效果,需要額外消耗大于 50%的內存。
為了進一步降低對用戶的阻塞時間,對 DataTree 拷貝進行了進一步優化。DataTree 拷貝其實是一個計算密集型的任務,所以可以采用向量化的方式,同時會遍歷 hashmap 可以適當進行 prefetch。
inline void memcopy(char * __restrict dst, const char * __restrict src, size_t n)
復制代碼
上面的拷貝函數基于 SSE 指令集,優化后 DataTree 拷貝時間從 4.5s 降低到 3.5s。
2. Snapshot 加載速度優化
RaftKeeper 老版本中,啟動服務之后 snapshot 加載速度比較慢,線上一個作為 ClickHouse metadata 存儲的 Raftkeeper 有 6kw 的數據,在 NVMe 磁盤的服務器上加載 snapshot 需要 180s,導致服務啟動速度很慢。
加載 snapshot 主要分兩步,第一步讀取磁盤上的數據,反序列化成節點;第二步遍歷 DataTree 并構建父子關系,其中第一步是并行的,第二步是單線程的。
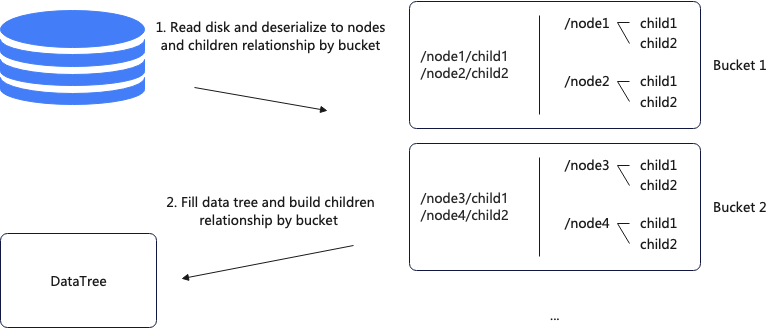
由于第二步是單線程執行,可以改成并行的方式,并行化改造的基礎是 DataTree 是一個二層 HashMap 結構,改造后每個線程負責固定的 bucket,這樣避免了并發問題。具體流程為首先從磁盤讀取數據并按照 bucket 的粒度存儲節點和父子關系,然后填充 DataTree 并構建父子關系。
優化后加載 snapshot 時間從 180s 降低到 99s,之后又通過鎖優化、snapshot 格式優化、減少數據拷貝等手段將時間降低到 22s。
四、上線效果
我們選取線上一個對 ZooKeeper 請求量大的 ClickHouse 集群,在 ClickHouse 測的監控指標看 QPS 大概為 17w/s,其中絕大部分為 List 請求。依次將其從 ZooKeeper 升級到 RaftKeeper v2.0.4 和 v2.1.0,觀察監控指標
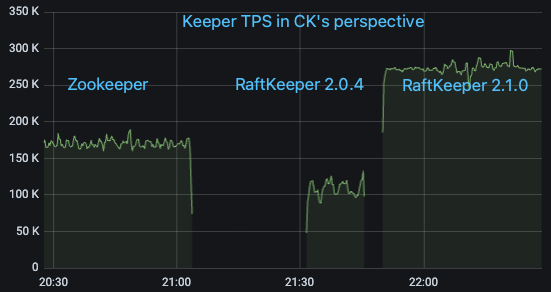
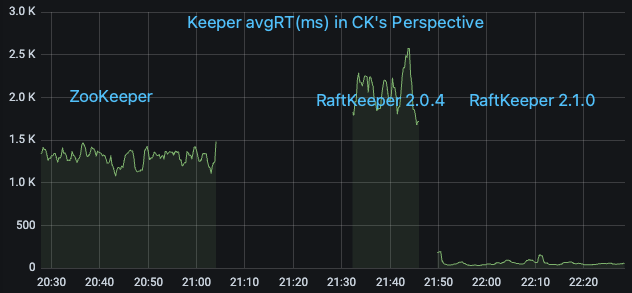
可以看到 RaftKeeper v2.0.4 的表現不及 ZooKeeper(主要原因是該場景下絕大部分請求是 list,v2.0.4 對于 list 請求性能較差),但是 v2.1.0 有比較大幅的優勢。
-
內存
+關注
關注
8文章
3115瀏覽量
75065 -
性能
+關注
關注
0文章
276瀏覽量
19328 -
zookeeper
+關注
關注
0文章
34瀏覽量
3901
發布評論請先 登錄
nonos sdk V2.1.0中使用混雜模式api,運行時崩潰了怎么解決?
RT-Thread Studio for VS Code來了 精選資料分享
STM32MP151C構建Custom Board“Eco system V2.1.0”發行版時存在不創建devicetree符號鏈接怎么解決?
串口ISP下載軟件Flash Loader Demonstrator V2.1.0的免費下載
Oculus Quest V18版本發布 大幅優化用戶體驗
RT-Thread Studio V2.1.0發布,支持用戶自制開發板支持包!

大疆智圖3.4.0版本更新 大幅提升用戶體驗
Embedded office發布安全插件V1.1版本!

芯來科技發布Nuclei Studio 2025.02版本





 工商網監
工商網監
評論