") 英特爾軟硬件構(gòu)建模塊如何幫助優(yōu)化RAG應(yīng)用
英特爾軟硬件構(gòu)建模塊如何幫助優(yōu)化RAG應(yīng)用
深入研究檢索增強(qiáng)生成 (Retrieval Augmented Generation, RAG),該創(chuàng)新方法定義了企業(yè)和機(jī)構(gòu)如何利用大語言模型(LLM)來發(fā)揮其數(shù)據(jù)的價(jià)值。本文將探索若干英特爾 軟硬件構(gòu)建模塊如何幫助優(yōu)化RAG應(yīng)用,在簡(jiǎn)化部署和支持?jǐn)U展的同時(shí),增強(qiáng)其上下文感知能力和實(shí)時(shí)響應(yīng)性能。
1為您的應(yīng)用量身定制GenAI
ChatGPT的面世改變了AI的發(fā)展格局。企業(yè)爭(zhēng)相利用這項(xiàng)新技術(shù)打造新產(chǎn)品,提高競(jìng)爭(zhēng)優(yōu)勢(shì)和生產(chǎn)力,實(shí)現(xiàn)更加經(jīng)濟(jì)高效的運(yùn)營。
生成式AI(GenAI)模型,如Grok-1(逾3,000億參數(shù))和GPT-4(數(shù)萬億參數(shù)),利用來自互聯(lián)網(wǎng)等文本來源的海量數(shù)據(jù)進(jìn)行訓(xùn)練。這些第三方大語言模型適用于通用用例。然而,企業(yè)的大多數(shù)用例都需要使用自身的數(shù)據(jù)來訓(xùn)練和/或增強(qiáng)AI模型,這樣模型產(chǎn)出的結(jié)果才能對(duì)業(yè)務(wù)更有幫助。以下是生成式AI在各行各業(yè)的應(yīng)用示例。
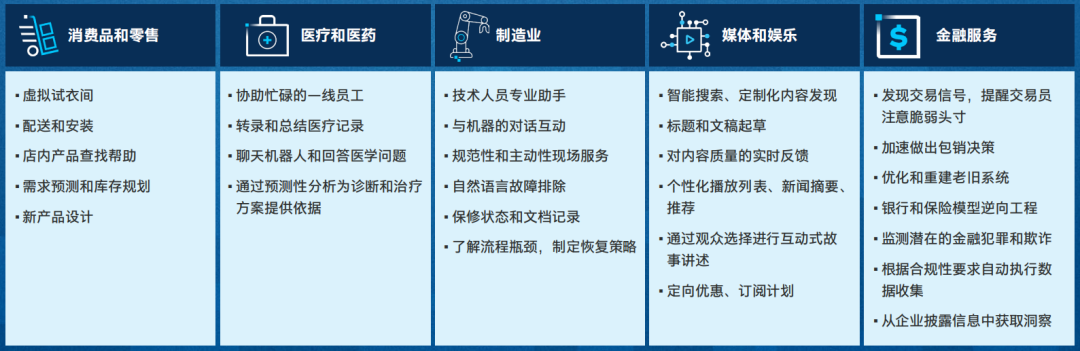
來源:由《麻省理工科技評(píng)論》根據(jù)“Retail in the Age of Generative AI(生成式AI時(shí)代的零售)”、“The Great Unlock: Large Language Models in Manufacturing(大解鎖:制造業(yè)中的大語言模型)”、“Generative AI Is Everything Everywhere, All at Once(生成式AI無處不在、每時(shí)每刻都在發(fā)生)”和“Large Language Models in Media & Entertainment(媒體和娛樂行業(yè)中的大語言模型)”(Databricks,2023年4月至6月)中的數(shù)據(jù)編寫。
雖然企業(yè)可以用自有的數(shù)據(jù)對(duì)模型進(jìn)行調(diào)優(yōu),但重新訓(xùn)練模型需要額外的時(shí)間和資源。好在現(xiàn)在有了一種頗受歡迎的技術(shù),即檢索增強(qiáng)生成(RAG),它可以利用企業(yè)專有的數(shù)據(jù)來增強(qiáng)開源預(yù)訓(xùn)練模型,從而創(chuàng)建特定領(lǐng)域的LLM,得出針對(duì)具體業(yè)務(wù)的結(jié)果。此外,RAG無需與第三方大型基礎(chǔ)模型共享數(shù)據(jù),因此能夠讓企業(yè)更好地保護(hù)數(shù)據(jù)安全。
在本指南中,我們將介紹RAG如何與英特爾多種優(yōu)化技術(shù)和平臺(tái)搭配使用,為GenAI系統(tǒng)帶來出色的價(jià)值和性能。
2檢索增強(qiáng)生成(RAG)是什么?
RAG技術(shù)將動(dòng)態(tài)、依賴查詢的數(shù)據(jù)添加到模型的提示流中,再從存儲(chǔ)在矢量數(shù)據(jù)庫中的專有知識(shí)庫中檢索相關(guān)數(shù)據(jù)。提示和檢索到的上下文可以豐富模型的輸出,從而帶來更加相關(guān)和準(zhǔn)確的結(jié)果。因?yàn)閿?shù)據(jù)不會(huì)被發(fā)送給管理模型的第三方,因此,RAG可讓企業(yè)在保護(hù)數(shù)據(jù)隱私性和完整性的同時(shí)更好地通過LLM充分利用數(shù)據(jù)。RAG工作流程的關(guān)鍵構(gòu)成可簡(jiǎn)單分為四個(gè)步驟:用戶查詢處理、檢索、上下文整合和輸出生成。下圖展示了這一基本流程。
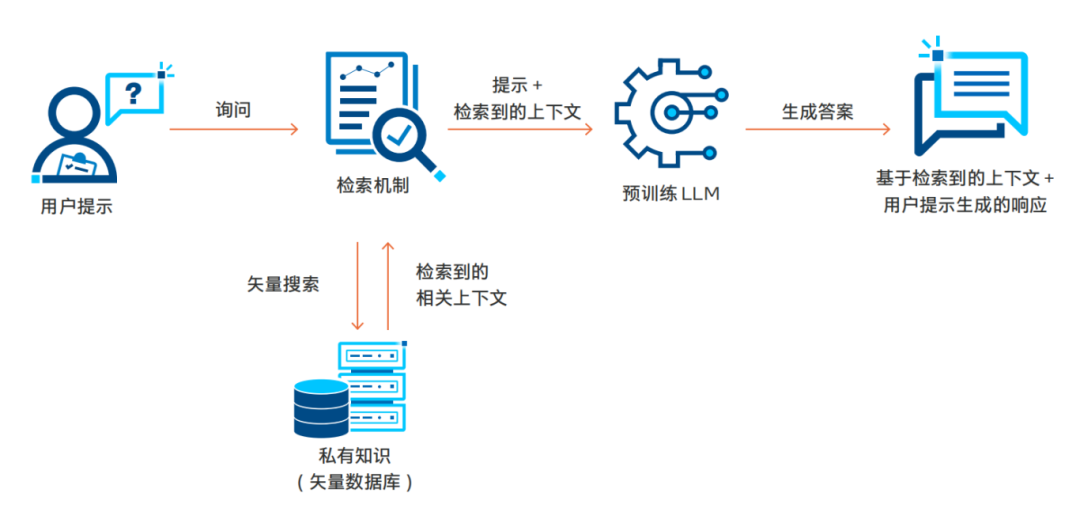
RAG的實(shí)用性不僅限于文本,它還可以極大地改變視頻搜索和交互式文檔探索的方式,甚至使聊天機(jī)器人能夠利用PDF內(nèi)容來回答問題。
RAG的應(yīng)用過程通常被稱為“RAG 管線”,因其從用戶提示開始,整個(gè)數(shù)據(jù)處理流程都是一致的。用戶提示首先進(jìn)入關(guān)鍵步驟“檢索機(jī)制”中。在這一步,相關(guān)提示會(huì)被轉(zhuǎn)換為矢量嵌入,接著使用矢量搜索在預(yù)先構(gòu)建的矢量數(shù)據(jù)庫(如PDF、日志、轉(zhuǎn)錄文本等)中找到相似的內(nèi)容。檢索到最相關(guān)的數(shù)據(jù)后,RAG會(huì)將其與用戶提示整合,然后傳送給模型用于推理服務(wù)和最終輸出生成。這種上下文整合為模型提供了在預(yù)訓(xùn)練階段無法獲得的額外信息,使模型能夠更好地契合用戶的任務(wù)或興趣領(lǐng)域。由于RAG無需重新訓(xùn)練或調(diào)優(yōu)模型,因此能夠高效地添加數(shù)據(jù)來為L(zhǎng)LM提供上下文。下一節(jié)將探討RAG解決方案的架構(gòu)和堆棧。
3標(biāo)準(zhǔn)RAG解決方案的架構(gòu)
下圖所示的RAG解決方案架構(gòu)展示了標(biāo)準(zhǔn)RAG實(shí)施方案的構(gòu)建模塊。RAG實(shí)施流程主要包括:①構(gòu)建知識(shí)庫、②查詢和上下文檢索、③響應(yīng)生成和④跨應(yīng)用產(chǎn)出監(jiān)控幾個(gè)核心部分。
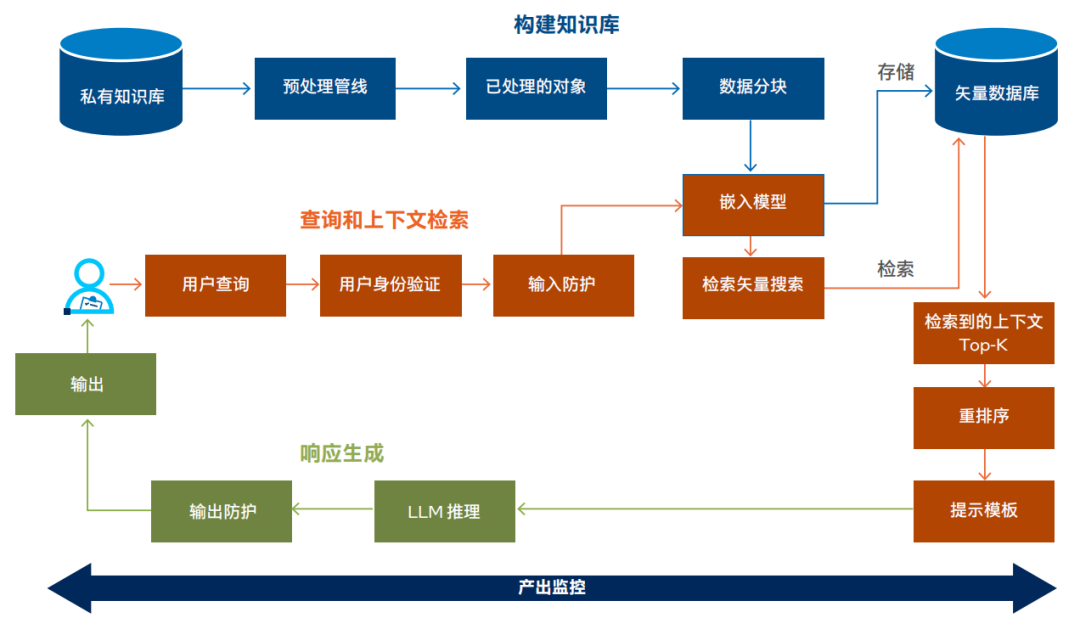
RAG LLM架構(gòu)
讓我們展開談?wù)勂渲袔讉€(gè)核心部分:
①構(gòu)建知識(shí)庫:
? 數(shù)據(jù)收集:從基于文本的來源(如轉(zhuǎn)錄文本、PDF和數(shù)字化文檔)中收集數(shù)據(jù)建立私有知識(shí)庫。
? 數(shù)據(jù)處理管線:利用特定RAG管線來提取文本、格式化內(nèi)容以進(jìn)行處理,并將數(shù)據(jù)分塊成可管理的大小。
? 矢量化:通過嵌入模型處理數(shù)據(jù)塊,將文本轉(zhuǎn)換為矢量,可包括用于豐富上下文的元數(shù)據(jù)。
? 矢量數(shù)據(jù)庫存儲(chǔ):將矢量化數(shù)據(jù)存儲(chǔ)在可擴(kuò)展的矢量數(shù)據(jù)庫中,以便進(jìn)行高效檢索。
②查詢和上下文檢索:
? 查詢提交:用戶或子系統(tǒng)通過聊天式界面或API調(diào)用提交查詢,并通過安全服務(wù)進(jìn)行身份驗(yàn)證。
? 查詢處理:采取輸入保護(hù)措施來確保安全性和合規(guī)性,然后進(jìn)行查詢矢量化。
? 矢量搜索和重排序:進(jìn)行初始矢量搜索以檢索相關(guān)矢量,然后使用更復(fù)雜的模型重排序以優(yōu)化結(jié)果。
③響應(yīng)生成:
? LLM推理和響應(yīng)生成:將頂層上下文與用戶查詢結(jié)合,再通過預(yù)訓(xùn)練或調(diào)優(yōu)的LLM進(jìn)行處理,然后再進(jìn)行后處理以提升質(zhì)量和增強(qiáng)安全性。
? 響應(yīng)交付:通過界面將最終響應(yīng)返回給用戶或子系統(tǒng),確保答案的連貫性和上下文準(zhǔn)確性。
④產(chǎn)出監(jiān)控:
? 檢索性能:監(jiān)控檢索過程的時(shí)延和準(zhǔn)確性,并保留記錄以用于審核。
? 重排序的效率:跟蹤重排序的表現(xiàn),確保上下文相關(guān)性和速度。
? 推理服務(wù)質(zhì)量:觀察LLM推理的時(shí)延和質(zhì)量,維護(hù)日志以便審核和改進(jìn)。
? 安全防護(hù)有效性:監(jiān)控輸入和輸出處理的安全防護(hù)(guardrail),確保合規(guī)性和內(nèi)容安全性。
4RAG相關(guān)技術(shù)
開發(fā)RAG應(yīng)用通常會(huì)從集成RAG框架開始,例如Haystack、LlamaIndex、LangChain和英特爾研究院的fastRAG。這些框架可通過提供優(yōu)化和集成關(guān)鍵的AI工具鏈來簡(jiǎn)化開發(fā)過程。
我們從知識(shí)庫構(gòu)建、查詢和上下文檢索以及響應(yīng)生成這三個(gè)關(guān)鍵步驟來考量RAG工具鏈。通常,RAG框架提 供涵蓋整個(gè)工具鏈的API。不管是選擇使用這些抽象,還是選擇利用獨(dú)立組件,都需要深思熟慮并從工程角度慎重考慮。

英特爾提供的優(yōu)化技術(shù)/方案填補(bǔ)了工具鏈和硬件之間的缺口,并且在提升這些工具鏈與英特爾 至強(qiáng) 處理器兼容性及功能的同時(shí),增強(qiáng)了跨工具鏈的性能。這些優(yōu)化被集成到現(xiàn)有框架中,或者作為附加的擴(kuò)展進(jìn)行分發(fā),目的是減少開發(fā)人員對(duì)大量低級(jí)別編程的需求。這種抽象使得開發(fā)人員能夠利用增強(qiáng)的性能和針對(duì)其特定用例量身定制的解決方案,專注于高效構(gòu)建RAG應(yīng)用。
接下來,本文將對(duì)工具鏈的多個(gè)組成部分進(jìn)行更詳細(xì)的探討。
構(gòu)建知識(shí)庫 + 上下文檢索:
? 集成框架:Haystack和LangChain作為常見RAG框架,為矢量數(shù)據(jù)庫和搜索算法提供了高級(jí)抽象,使得開發(fā)人員能夠在基于Python的環(huán)境中管理復(fù)雜的過程。
? 矢量數(shù)據(jù)庫技術(shù):Pinecone、Redis和Chroma是支持主流搜索算法的關(guān)鍵矢量數(shù)據(jù)庫解決方案。英特爾研究院提供的可擴(kuò)展矢量搜索(Scalable Vector Search, SVS)技術(shù)也很有發(fā)展前景,預(yù)計(jì)將在2024年初與各大矢量數(shù)據(jù)庫集成。
? 嵌入和模型可訪問性:通過Hugging Face API進(jìn)行集成的嵌入模型往往可無縫整合到RAG框架中。這大大提升了納入先進(jìn)自然語言處理(NLP)的簡(jiǎn)便性。
響應(yīng)生成:
? 低級(jí)別優(yōu)化:oneAPI高性能庫可以優(yōu)化PyTorch、TensorFlow和ONNX等主流AI框架,因此您可以使用熟悉的開源工具,因?yàn)樗鼈円厌槍?duì)英特爾 硬件進(jìn)行了優(yōu)化。
? 高級(jí)推理優(yōu)化:英特爾 Extension for PyTorch等擴(kuò)展添加了高級(jí)量化推理技術(shù),可助力提升了大語言模型的性能。
如您所見,RAG涉及多個(gè)相關(guān)聯(lián)的部分,在單一平臺(tái)(如英特爾 至強(qiáng) 處理器)上進(jìn)行管理可簡(jiǎn)化配置、部署和維護(hù)。
下一節(jié)將深入探討RAG應(yīng)用的復(fù)雜性,包括幫助團(tuán)隊(duì)實(shí)現(xiàn)成功部署的各種考量因素和技術(shù)。
5加速RAG應(yīng)用與落地
RAG管線的許多步驟需要耗費(fèi)大量計(jì)算資源,而同時(shí),終端用戶又對(duì)低時(shí)延響應(yīng)有著較高要求。此外,由于RAG經(jīng)常用于處理機(jī)密數(shù)據(jù),因此整個(gè)管線的安全性都至關(guān)重要。英特爾 技術(shù)賦能RAG管線,助力提升各個(gè)計(jì)算平臺(tái)的安全性能和充分發(fā)揮專為特定領(lǐng)域或行業(yè)量身定制的生成式AI的優(yōu)勢(shì)。
計(jì)算需求
一般來說,LLM推理是RAG管線計(jì)算最密集的階段,特別是在實(shí)時(shí)應(yīng)用環(huán)境中。然而,創(chuàng)建初始知識(shí)庫(處理數(shù)據(jù)和生成嵌入)對(duì)計(jì)算的需求同樣可能很高(取決于數(shù)據(jù)的復(fù)雜性和體量)。英特爾在通用計(jì)算技術(shù)、AI加速器和機(jī)密計(jì)算方面的進(jìn)步為應(yīng)對(duì)整個(gè)RAG管線的計(jì)算挑戰(zhàn)提供了重要基石,同時(shí)還能提高數(shù)據(jù)隱私和安全性。
和大多數(shù)軟件應(yīng)用一樣,RAG也能從專為滿足終端用戶事務(wù)需求而量身定制的可擴(kuò)展基礎(chǔ)設(shè)施中受益。隨著事務(wù)需求的增加,開發(fā)人員可能會(huì)因計(jì)算基礎(chǔ)設(shè)施負(fù)載過重而面臨時(shí)延增加,且基礎(chǔ)設(shè)施還會(huì)因矢量數(shù)據(jù)庫查詢和推理計(jì)算而趨于飽和。因此,獲得隨時(shí)可用的計(jì)算資源來擴(kuò)展系統(tǒng)和快速處理新增需求對(duì)企業(yè)至關(guān)重要。另外,實(shí)施關(guān)鍵優(yōu)化以提升諸如嵌入生成、矢量搜索與推理等關(guān)鍵步驟的性能也非常重要。
數(shù)據(jù)隱私和安全性
? 安全AI處理:英特爾 軟件防護(hù)擴(kuò)展(Intel Software Guard Extensions,英特爾 SGX)和英特爾 Trust Domain Extensions(英特爾 TDX)在處理過程中在CPU內(nèi)存中進(jìn)行機(jī)密計(jì)算和數(shù)據(jù)加密,提高了數(shù)據(jù)安全性。這些技術(shù)對(duì)于處理敏感信息至關(guān)重要,有助于利用管線各部分的加密數(shù)據(jù)創(chuàng)建更安全的RAG應(yīng)用。對(duì)于需要在矢量嵌入生成、檢索或推理過程中更安全地處理敏感數(shù)據(jù)的RAG應(yīng)用來說,這是一個(gè)重要特性。
? 采取適當(dāng)防護(hù):在RAG應(yīng)用中,防護(hù)涉及采取措施來管理LLM在RAG系統(tǒng)內(nèi)的行為。這包括監(jiān)控模型的響應(yīng)、幫助遵守指導(dǎo)原 則和最佳實(shí)踐,以及控制其輸出來降低毒性、不公平偏見和隱私泄露的風(fēng)險(xiǎn)。在RAG應(yīng)用中采取防護(hù)措施有助于LLM得到用戶的信任和負(fù)責(zé)任的運(yùn)用,同時(shí)符合系統(tǒng)的整體目標(biāo)和要求。
開源優(yōu)化
嵌入優(yōu)化
? 量化嵌入模型:英特爾 至強(qiáng) 處理器可以利用量化嵌入模型來優(yōu)化從文檔中生成矢量嵌入的過程。例如,bge-small-en-v1.5-rag-int8-static 是一個(gè)使用英特爾 Neural Compressor進(jìn)行量化的BAAI/BGE-small-en-v1.5版本,與Optimum-Intel兼容。按照Massive Text Embedding Benchmark (MTEB) 性能指標(biāo)計(jì)算,使用量化模型進(jìn)行檢索和重排序任務(wù)時(shí),浮點(diǎn)(FP32)和量化INT8版本之間的差異小于2%,同時(shí)提高了吞吐量(見腳注1和3)。
在最近與Hugging Face合作進(jìn)行的一項(xiàng)研究中,我們?cè)u(píng)估了以每秒文檔數(shù)為指標(biāo)達(dá)到峰值編碼性能所需吞吐量。總體而言,無論模型大小,量化模型在各種批大小下均較基線bfloat16(BF16) 模型取得高達(dá)4倍的改進(jìn)。
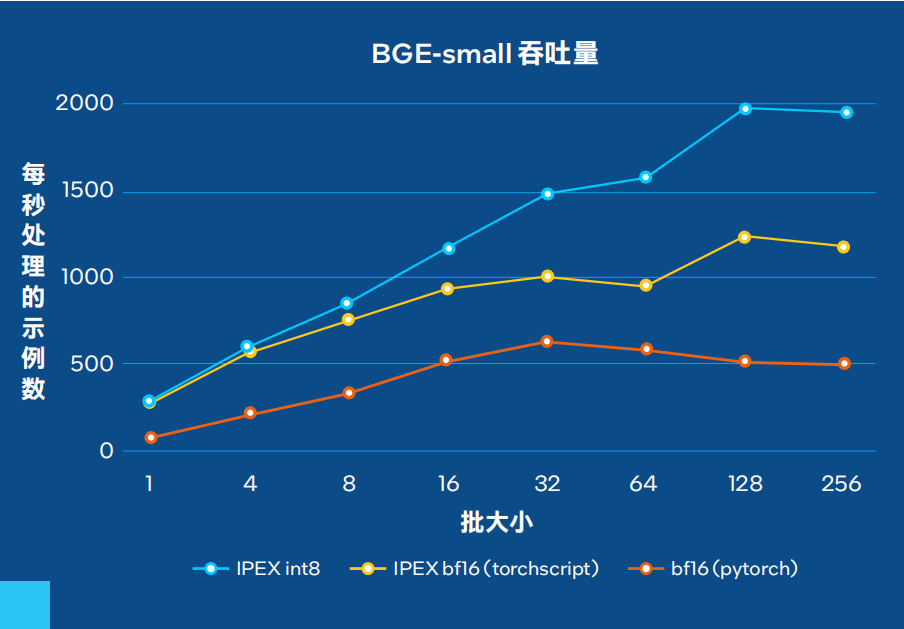
圖1. BGE-small吞吐量
矢量搜索優(yōu)化
? 針對(duì)CPU優(yōu)化的工作負(fù)載:在英特爾 至強(qiáng) 處理器上,矢量搜索操作得到了高度優(yōu)化,特別是在第三代及以后的處理器中引入了英特爾 高級(jí)矢量擴(kuò)展 512(Intel Advanced Vector Extensions 512,英特爾AVX-512)之后。英特爾 AVX-512利用融合乘加 (FMA) 指令,將乘法和加法合并為一個(gè)運(yùn)算,從而增強(qiáng)了內(nèi)積計(jì)算,這是矢量搜索中的一個(gè)基本運(yùn)算。這一功能減少了計(jì)算所需的指令數(shù)量,顯著提高了吞吐量和性能。
? 可擴(kuò)展矢量搜索 (SVS):可擴(kuò)展矢量搜索(SVS)技術(shù)提供快速的矢量搜索能力,可助力優(yōu)化檢索時(shí)間并提升整體系統(tǒng)性能。它通過使用局部自適應(yīng)矢量量化(LVQ)來優(yōu)化基于圖形的相似度搜索,在保持準(zhǔn)確性的同時(shí)盡可能降低內(nèi)存帶寬要求。其結(jié)果是顯著減少了距離計(jì)算時(shí)延,并在吞吐量和內(nèi)存要求方面獲得了更好的表現(xiàn)(如下圖所示)。
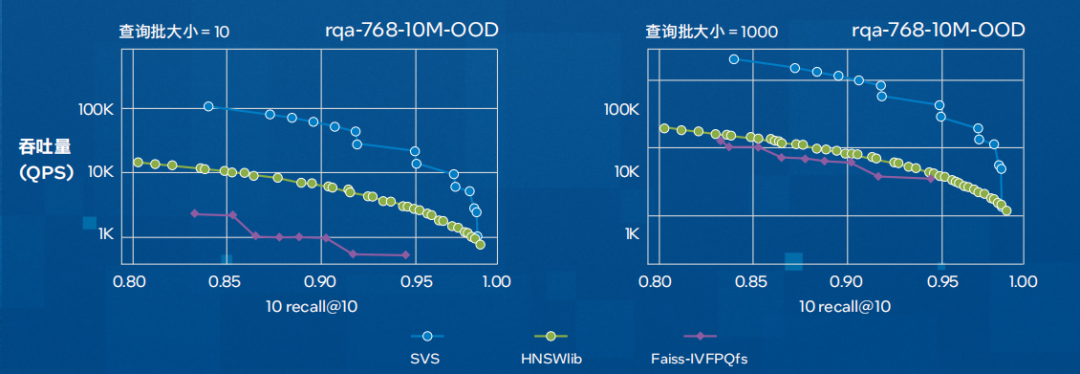
圖2. SVS與其它被廣泛采用的實(shí)現(xiàn)方案(HNSWlib與Faiss-IVFPQfs)在每秒查詢數(shù)量(吞吐量)方面的性能對(duì)比。該圖展示了在rqa-768-10M-OOD數(shù)據(jù)集(由密集通道檢索模型 RocketQA[QDLL21]使用分布外查詢生成的1000萬個(gè)768維嵌入向量)上,QPS和召回率的關(guān)系曲線。(腳注2和3)
推理優(yōu)化
RAG主要涉及推理運(yùn)算,這一過程可由英特爾 至強(qiáng) 處理器通過先進(jìn)的模型壓縮技術(shù)提供支持。這些技術(shù)支持在較低精度(BF16和INT8)下進(jìn)行運(yùn)算,并且不會(huì)造成明顯的性能損失。在本節(jié)中,我們將簡(jiǎn)要介紹各種針對(duì)推理的優(yōu)化和機(jī)會(huì)。
? 英特爾 高級(jí)矩陣擴(kuò)展(Intel Advanced Matrix Extensions,英特爾 AMX):第四代和第五代英特爾 至強(qiáng) 可擴(kuò)展處理器內(nèi)置英特爾 AMX,能夠提高矩陣運(yùn)算的效率并優(yōu)化內(nèi)存管理。
? 先進(jìn)的開源推理優(yōu)化工具:英特爾貢獻(xiàn)并擴(kuò)展了主流深度學(xué)習(xí)框架,如PyTorch、TensorFlow、Hugging Face、DeepSpeed等。對(duì)于RAG工作流程,英特爾關(guān)注的是通過實(shí)施量化等模型壓縮技術(shù)來優(yōu)化LLM的機(jī)會(huì)。英特爾 Extension for PyTorch目前提供多種先進(jìn)的LLM化配方,如 SmoothQuant、僅權(quán)重量化和混合精度 (FP32/BF16)。下圖顯示了在雙路第五代英特爾 至強(qiáng) 平臺(tái)上運(yùn)行的INT8量化Llama 2和GPT-J模型的推理時(shí)延。
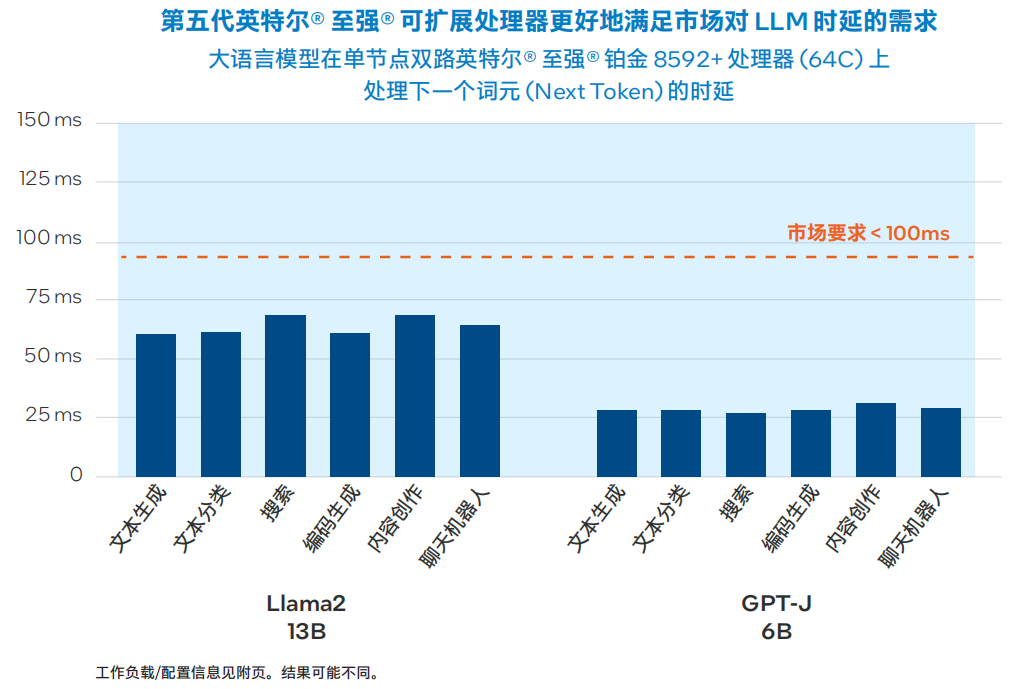
圖3. 基于第五代英特爾 至強(qiáng) 可擴(kuò)展處理器的Llama 2 13B和GPT-J 6B性能3
6RAG在企業(yè)中的應(yīng)用機(jī)遇
零售
零售商面臨的挑戰(zhàn)是向客戶推薦符合其多樣化和不斷變化的偏好的產(chǎn)品。傳統(tǒng)的推薦系統(tǒng)可能無法有效地掌握最新趨勢(shì)或個(gè)體客戶反饋,導(dǎo)致建議不太貼合實(shí)際。
采用基于RAG的推薦系統(tǒng)使零售商能夠不斷整合最新趨勢(shì)和個(gè)體客戶反饋,從而得出更個(gè)性化的產(chǎn)品建議。該系統(tǒng)通過提供相關(guān)、及時(shí)和個(gè)性化的產(chǎn)品推薦來豐富購物體驗(yàn),進(jìn)而助力提高銷量并提升客戶忠誠度。
制造業(yè)
在制造業(yè)中,設(shè)備故障導(dǎo)致的意外停機(jī)是一個(gè)重要的成本驅(qū)動(dòng)因素。傳統(tǒng)的預(yù)測(cè)性維護(hù)模型可能會(huì)遺漏故障發(fā)生前出現(xiàn)的細(xì)微異常狀況,尤其是歷史故障數(shù)據(jù)有限或缺失的復(fù)雜設(shè)備的異常狀況。
用于預(yù)測(cè)性維護(hù)的基于RAG的異常檢測(cè)系統(tǒng)可以實(shí)時(shí)分析大量運(yùn)行數(shù)據(jù),并將其與豐富的設(shè)備性能知識(shí)庫進(jìn)行比對(duì),以在故障發(fā)生之前識(shí)別出可能存在的問題。這種方法在延長(zhǎng)設(shè)備使用壽命的同時(shí),盡可能減少了停機(jī)時(shí)間和維護(hù)成本。
金融服務(wù)
由于金融數(shù)據(jù)和法規(guī)不斷變化且數(shù)量龐大,大規(guī)模提供個(gè)性化的金融建議面臨重重挑戰(zhàn)。客戶期望能夠獲得快速、相關(guān)且個(gè)性化的金融建議,而傳統(tǒng)的聊天機(jī)器人無法始終準(zhǔn)確提供這些建議。
RAG模型則能夠通過動(dòng)態(tài)拉取最新的金融數(shù)據(jù)和法規(guī)來生成個(gè)性化的建議,顯著增強(qiáng)了金融建議聊天機(jī)器人的能力。聊天機(jī)器人可以利用龐大的知識(shí)庫,為客戶提供量身定制的投資策略、實(shí)時(shí)市場(chǎng)洞察和監(jiān)管建議,從而提高客戶滿意度和參與度。
后續(xù)行動(dòng)
英特爾提供一套資源來幫您開始執(zhí)行實(shí)施方案,您可以通過英特爾 Tiber Developer Cloud 獲取硬件,也可以利用 Google Cloud Platform、Amazon Web Services和 Microsoft Azure等各大云服務(wù)平臺(tái)中無處不在的計(jì)算資源。對(duì)于需要代碼示例、演練、培訓(xùn)等內(nèi)容的開發(fā)人員,請(qǐng)?jiān)L問英特爾 開發(fā)人員專區(qū)。
更多英特爾至強(qiáng)為AI加速相關(guān)解決方案內(nèi)容,歡迎點(diǎn)擊“閱讀原文”了解
1 性能聲明基于雙路英特爾 至強(qiáng) 鉑金 8480+處理器,每路56個(gè)內(nèi)核。PyTorch 模型使用單路處理器上的56個(gè)內(nèi)核進(jìn)行評(píng)估。IPEX/Optimum設(shè)置使用 ipexrun、單路處理器和22至56個(gè)內(nèi)核進(jìn)行評(píng)估。TCMalloc在所有運(yùn)行中都已安裝并定義為環(huán)境變量。
2 性能聲明基于雙路英特爾 至強(qiáng) 鉑金 8480L處理器,每路56個(gè)內(nèi)核,每路配備512 GB DDR4內(nèi)存,速度為4800 MT/s,運(yùn)行Ubuntu 22.04.12。對(duì)于 deep-96-1B數(shù)據(jù)集,我們使用具有相同特性的服務(wù)器,唯一的區(qū)別是每路配備1 TB DDR4內(nèi)存,速度為4400 MT/s。
3 實(shí)際性能受使用情況、配置和其他因素的差異影響。性能測(cè)試結(jié)果基于配置信息中顯示的日期進(jìn)行的測(cè)試,且可能并未反映所有公開可用的安全更新。沒有任何產(chǎn)品或組件是絕對(duì)安全的。具體成本和結(jié)果可能不同。英特爾技術(shù)可能需要啟用硬件、軟件或激活服務(wù)。
-
英特爾
+關(guān)注
關(guān)注
61文章
10119瀏覽量
173432 -
軟硬件
+關(guān)注
關(guān)注
1文章
312瀏覽量
19465 -
LLM
+關(guān)注
關(guān)注
1文章
316瀏覽量
617
原文標(biāo)題:看英特爾? 軟硬件如何助力加速RAG應(yīng)用落地
文章出處:【微信號(hào):英特爾中國,微信公眾號(hào):英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
阿里巴巴攜手英特爾開發(fā)一款基于FPGA的解決方案,以幫助客戶提升業(yè)務(wù)應(yīng)用的性能
英特爾高清顯卡4600幫助
英特爾的Caffe優(yōu)化是否支持這些網(wǎng)絡(luò)?
為什么選擇加入英特爾?
蘋果Mac棄用英特爾芯片的原因
英特爾Optane DC PMM硬件的相關(guān)資料分享
在英特爾ComposerXE 2015中進(jìn)行英特爾線程構(gòu)建模塊的測(cè)試
使用英特爾編譯器和英特爾TBB增強(qiáng)計(jì)算泰勒系列擴(kuò)展
如何進(jìn)行英特爾TensorFlow的優(yōu)化
軟硬件結(jié)合,英特爾助推計(jì)算力指數(shù)級(jí)提升
英特爾首個(gè)針對(duì)AI優(yōu)化的Stratix 10 NX FPGA產(chǎn)品即將發(fā)布
英特爾oneAPI 2023工具包正式上線,幫助開發(fā)者利用英特爾硬件的先進(jìn)功能

英特爾2024產(chǎn)品年鑒:AI與軟硬件的融合發(fā)展






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論