 高并發場景下的庫存管理,理論與實戰能否兼得?
高并發場景下的庫存管理,理論與實戰能否兼得?
前言
本篇文章,是一篇實戰后續篇,是基于之前我發了一篇關于如何構建高并發系統文章的延伸: 高并發系統的藝術:如何在流量洪峰中游刃有余
而這篇文章,從實踐出發,解決一個真實場景下的高并發問題:秒殺場景下的系統庫存扣減問題。
隨著互聯網業務的不斷發展,選擇在網上購物的人群不斷增加,這種情況下,會衍生出一些促銷活動,類似搶購場景或者熱銷熱賣場景,在高峰時段的下單數量會非常大,也意味著對數據庫中暢銷商品的庫存操作十分頻繁,需要頻繁查庫存和更新庫存。這屬于高讀寫場景,比起單獨的并發讀和并發寫來說,業務場景更復雜一些。那么這種高并發為了保證庫存數據一致性,一般會在數據庫更新時進行加鎖操作,以保證系統不會發生超賣情況。
我們應該如何應對呢?大家可以根據我之前那篇文章中的思維導圖,跟隨我的思路,一起來看如何解決當前場景下的高并發問題。
?
小試牛刀
面對庫存扣減的場景,我們第一個考慮到是數據一致性問題,因為超賣會對我們的履約和客戶信譽造成影響。所以一般情況下,在數據庫更新時進行加鎖操作,以保證系統不會發生超賣情況。所以更多方案是提高數據庫性能方法,比如增加硬件性能,優化樂觀鎖,提升鎖效率,優化SQL性能等。對于一些大型系統,也衍生出一些基于分片的庫存方案,通過分庫分表增加并發吞吐量。
當然那這樣不夠,因為MySQL數據庫的讀寫的并發上線能力是有限的,我們還是需要再進一步優化我們的方案。這里就要參考之前我寫的那篇文章中的思維導論了,這里常見解決方案就是,引入緩存機制。
如下圖所示,我們把讀請求進行緩存,每次庫存校驗時,我們引入redis緩存,讀請求通過緩存,增加接口性能,然后庫存扣減時,在進行緩存同步。
?
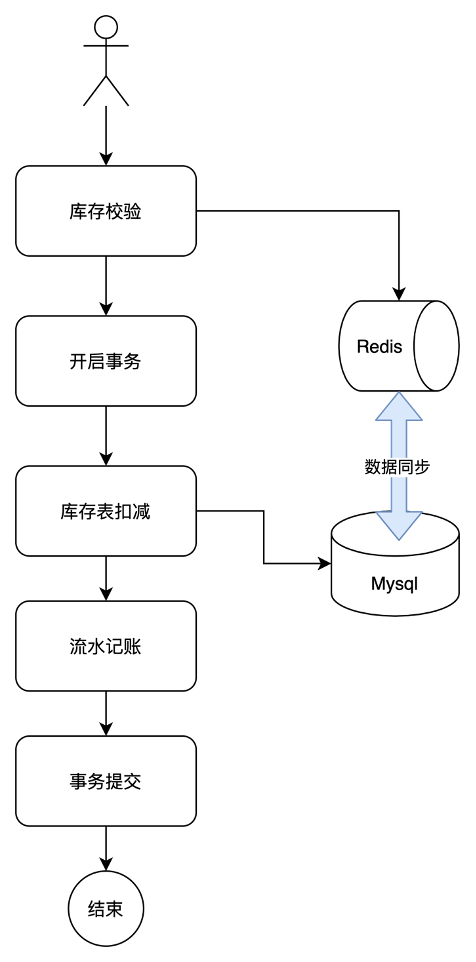
但這種方式存在很大問題: 所有請求都會在這里等待鎖,獲取鎖有去扣減庫存。在并發量不高的情況下可以使用,但是一旦并發量大了就會有大量請求阻塞在這里,導致請求超時,進而整個系統雪崩;而且會頻繁的去訪問數據庫,大量占用數據庫資源,所以在并發高的情況下這種方式不適用。同時這個方案還會存在mysq和redis的數據同步不一致的情況,導致高并發情況下,出現超賣。
所以這種方案雖然簡單,但是無法滿足高并發場景,我們必須得pass。
循序漸進
為此,我們可以進行一次優化,通過架構維度進行調整。
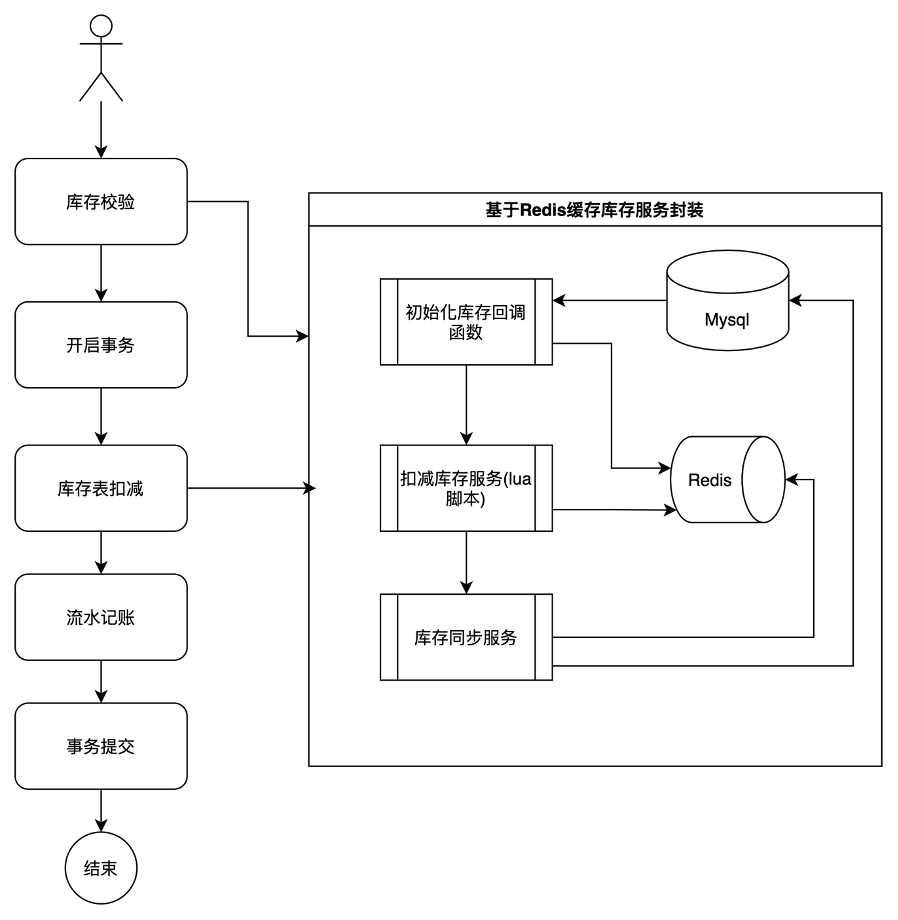
在這個方案中,我們將庫存操作封裝成一個單獨模塊,這個方案的優化點在于,所有庫存的查詢和扣減都圍繞redis進行。當發生庫存扣減操作時,會直接更新redis,同時采用異步流程,更新MySQL數據庫。這樣以來,我們的性能會比直接訪問MySQL數據庫高效不少,并發能力會有不少提升。
流程如下:
?
?
但這個方案依然有缺陷,它的點在于redis的單點性能問題。該方案的最大并發性能取決于redis的單點處理能力。而如果想要進一步提升并發能力,該方案不具備水平擴展能力。那么,這個方案,依然不是我們最優的選擇。
大顯身手
那么接下來,我們需要考慮的是如何可以實現我們業務系統并發能力的水平擴展能力。當然這里也不是憑空來想,我們可以思考一下,業內成熟的一些中間件是如何實現高并發的,這里我們可以兩個我們常見的框架:kafka和elasticsearch。
上述我們常見的兩個中間件框架,都以可以水平能力擴展著稱。那么仔細思考一下他們的技術架構不難發現,他們的核心其實都是采用了一種所謂的分片實現的。那么問題來了,我們的庫存扣減,能不能實現分片呢?或者換一個思路思考這個問題:我們的庫存邏輯是否可以轉化為分布式庫存進行存儲和擴展呢?
有了以上的思路,我們就可以開始構建我們的架構方案了。接下來,我先把架構圖貼出來:
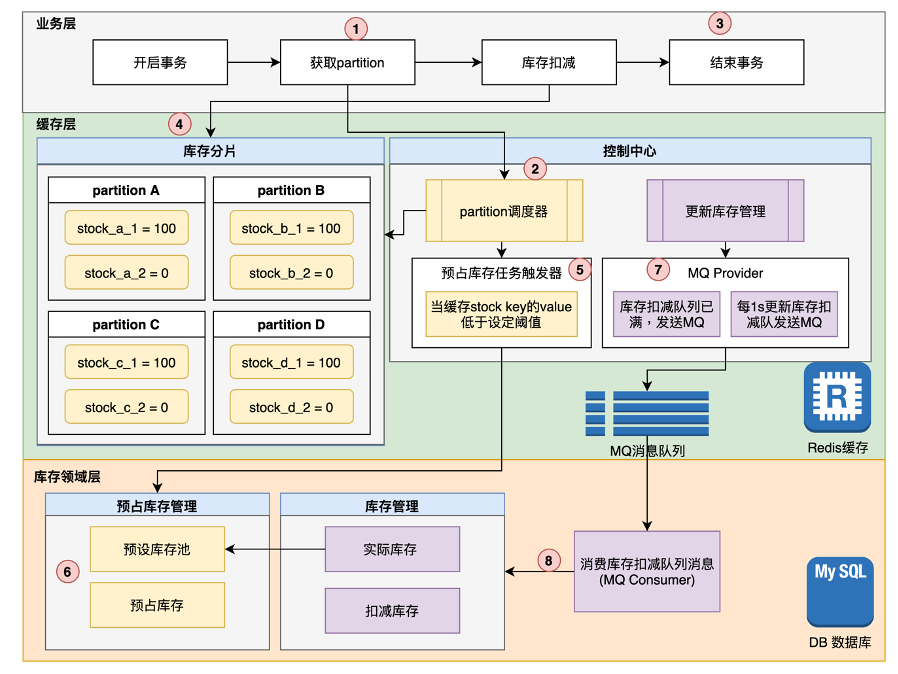
在這個架構方案中,是以Redis緩存為實現基礎,結合Mysql數據存儲,通過一套控制機制,保證庫存的分布式管理。在該方案中,有一些特定的業務模塊單元需要說明。
1. partition
熟悉kafka的人對partition一定不陌生。在本架構方案之中,該業務架構中的partition的概念是一組基于redis來實現的庫存分片,分別存儲一部分庫存大小。
在一個partition中,會存有一定量的預占庫存量,當有請求服務進行庫存扣減時,只需要選擇其中一個partition即可,這樣以來,就可以減輕單節點的壓力,同時可以基于redis集群的可擴展性,實現partition的水平擴展。
分布式系統常見的一個問題就是數據傾斜問題,因為嚴重的數據傾斜,會讓我們分布式方案瞬間瓦解,導致單點承擔高并發。那么該方案下的數據傾斜問題如何解決呢?
最終,我想到的解決方案類似養寵物狗時買的那種定時投喂儀器,每天通過定時定量投喂,來保證寵物狗不會被餓到或者吃撐。
如果最初把所有庫存全部平均到每個partition中,當有多個大庫存扣減打到一個partition上時,會造成該partition上出現庫存被消耗光,而失去后續提供庫存扣減能力。為了解決這個問題,我在partition中采取的是動態庫存注入和子域隔離的方案。具體方案如下圖:
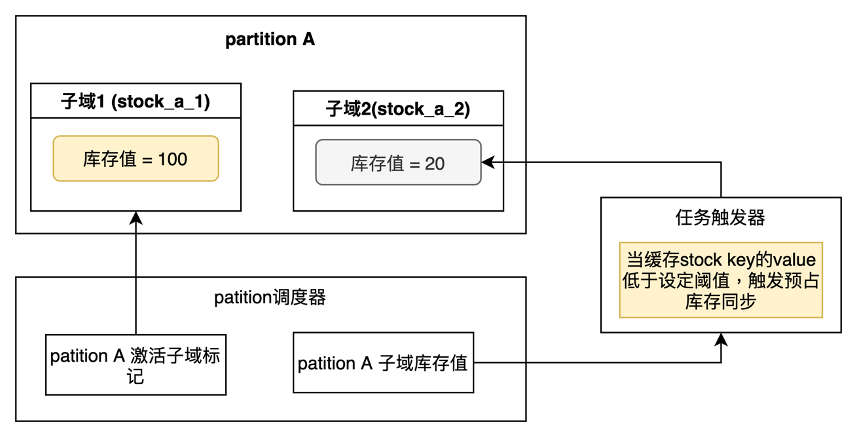
每個partition會有兩個子域,調度器中會記錄每個partition當前激活的子域,每次庫存扣減,會扣減激活的子域中的庫存值。而當激活的子域庫存值低于設定閾值是,會切換子域,冷卻當前子域,激活另一個子域。被冷卻的子域會觸發任務觸發器,實現預占庫存的數據同步。
子域中會存儲一定額度的庫存值,不會存儲很大的量,這樣就可以保證動態的預占庫存實現,從而解決庫存傾斜的問題。
當然為了更好的管理partition,我們需要單獨開發一個partition調度器模塊,來負責管理管理眾多partition資源,那么這個調度器的具體功能包括:
1.調度器中有一個注冊表,會記錄 Partition的key值,外部服務獲取partition key是需要通過調度器獲取,調度器會記錄每個partition的庫存余量和partition和子域信息。
2.當partition無法再獲取預占庫存,且庫存耗盡時,調度器會從注冊表中摘除該partition信息。
3. 調度器可以采用隨機或者輪訓的方式獲取partition,同時每次也會校驗partition剩余庫存是否滿足業務扣減數量,如果剩余庫存小于業務扣減數量,將會跳過該partition節點。
2. 異步更新庫存
第二個核心模塊就是更新庫存管理了,這塊你可以理解為異步流程機制,通過異步化操作,來減輕系統的高并發對數據庫的沖擊。
更新庫存會有一個明細表,記錄每個partition庫存扣減信息,明細表會有一個同步狀態,有兩種情況可以出發庫存同步MQ消息:
第一. 當每個partition中的明細數據條數超過設定閾值,會自動觸發一次MQ消息。
第二. 每間隔額定設定時間(默認設置1秒), 會觸發一次當前時間段內每個partition產生的庫存扣減明細信息,然后發送一次MQ消息。
兩中觸發方案相互獨立,互不影響,通過同步狀態和明細ID實現冪等。
3. 預占庫存管理和庫存管理
接下來就是關于庫存的底層數據結構設計了。這里會引入一個在電商行業很共識的概念:預占庫存。
在庫存領域層中,庫存分為預占庫存和庫存兩個模塊,這里面的庫存關系實例如下:
假設當前商品的庫存值為10000件,當前partition觸發一次預占庫存任務,領取400件, 然后假設此時收到MQ庫存消費更新消息,更新30件。隨后partition又觸發一次預占庫存任務,零陵區了100件。庫存變化如下圖所示:
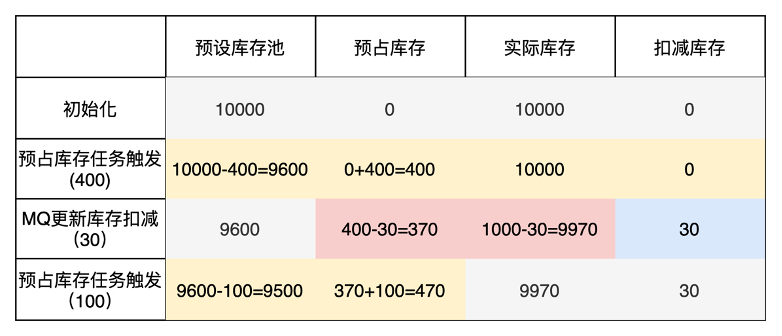
其中 實際庫存= 預設庫存池 + 預占庫存。
每次預占庫存任務觸發,會從預設庫存池中扣減,如果預占庫存池清空,則partition就無法在獲取預占庫存,調度器會將它從注冊表中摘除。
而每次MQ更新庫存消息,會更新實際庫存量,同時對預占庫存和扣減庫存值進行修改,這個操作具有事務性。
總結
通過這次的案例分析,我們其實是通過方法論結合實際業務場景的方式出發,設計了我們的系統架構。剝離業務場景,其實本質就是通過緩存和異步流程來實現系統的高并發,同時讓系統具備擁有水平擴展的能力。但這個方法論在與實際業務結合時,還是會有很多很多需要思考和細化的點,比如分布式思想的使用,比如預占庫存的邏輯設計等等。
審核編輯 黃宇
-
庫存管理
+關注
關注
0文章
13瀏覽量
6841 -
Partition
+關注
關注
0文章
4瀏覽量
7905 -
調度器
+關注
關注
0文章
98瀏覽量
5471
發布評論請先 登錄
鴻蒙5開發寶藏案例分享---應用并發設計
如何去實現一種基于SpringMVC的電商高并發秒殺系統設計
ATC'22頂會論文RunD:高密高并發的輕量級 Serverless 安全容器運行時 | 龍蜥技術
模糊控制理論在庫存貨位管理中的應用
負荷管理系統中的并發通信設計與實現
物聯網是如何驅動庫存管理的
懂高并發性能調優是在技術進階賽道變得厲害的加分項
【源碼版】基于SpringMVC的電商高并發秒殺系統設計思路

TurMass? 如何幫助解決 UWB 定位系統大規模終端標簽高并發通信沖突問題?






 工商網監
工商網監
評論