") 從原理聊JVM(一):染色標(biāo)記和垃圾回收算法
從原理聊JVM(一):染色標(biāo)記和垃圾回收算法

導(dǎo)讀
JAVA簡單易用的特性,能夠讓研發(fā)人員在不了解JVM的底層運(yùn)行機(jī)制的情況下依舊能夠編寫出功能完善的代碼。
但是對(duì)JVM的理解,是一個(gè)程序員普通和優(yōu)秀的分水嶺。全面地了解JVM的工作原理,能夠更好地優(yōu)化自己的代碼,并解決一些潛在的性能問題。
本文及后續(xù)文章將從原理聊起,對(duì)JVM的內(nèi)存分配、GC、編譯等知識(shí)進(jìn)行分析和總結(jié)。
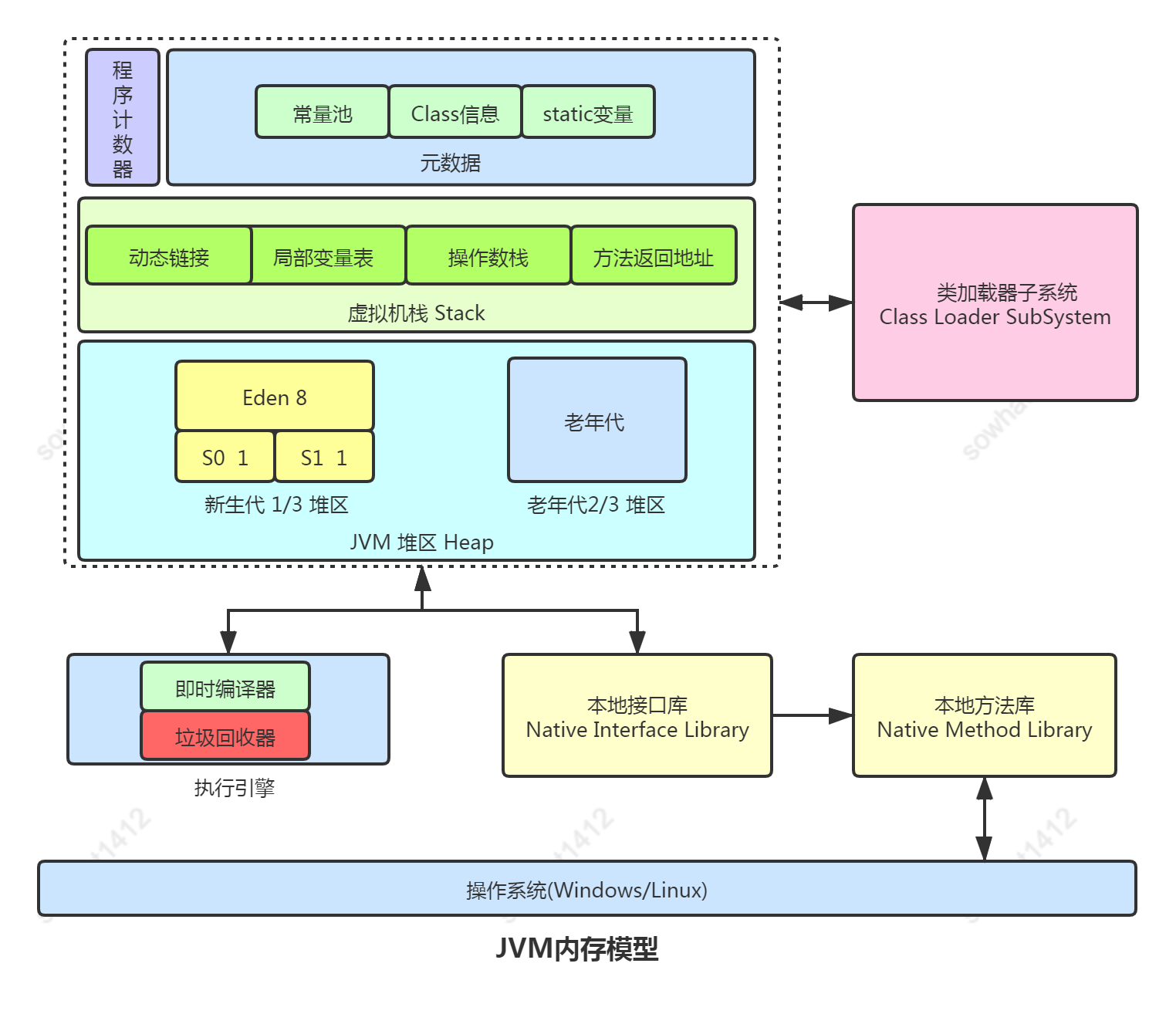
1 JVM運(yùn)行時(shí)內(nèi)存劃分
1.1 運(yùn)行時(shí)數(shù)據(jù)區(qū)域
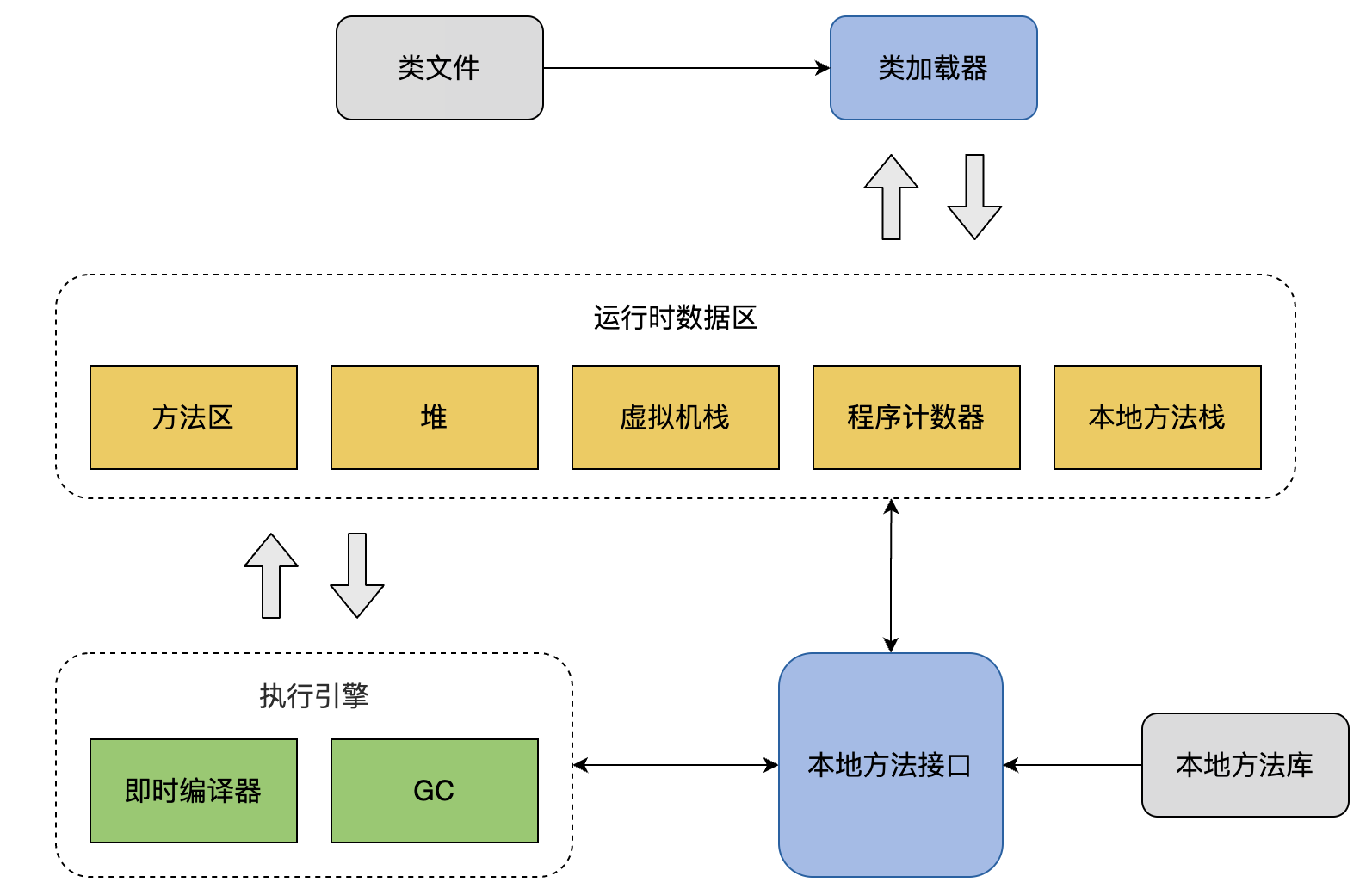
??
?方法區(qū)
屬于共享內(nèi)存區(qū)域,存儲(chǔ)已被虛擬機(jī)加載的類信息、常量、靜態(tài)變量、即時(shí)編譯器編譯后的代碼等數(shù)據(jù)。運(yùn)行時(shí)常量池,屬于方法區(qū)的一部分,用于存放編譯期生成的各種字面量和符號(hào)引用。
JDK1.8之前,Hotspot虛擬機(jī)對(duì)方法區(qū)的實(shí)現(xiàn)叫做永久代,1.8之后改為元空間。二者區(qū)別主要在于永久代是在JVM虛擬機(jī)中分配內(nèi)存,而元空間則是在本地內(nèi)存中分配的。很多類是在運(yùn)行期間加載的,它們所占用的空間完全不可控,所以改為使用本地內(nèi)存,避免對(duì)JVM內(nèi)存的影響。根據(jù)《Java虛擬機(jī)規(guī)范》的規(guī)定,如果方法區(qū)無法滿足新的內(nèi)存分配需求時(shí),將拋出OutOfMemoryError異常。
?堆
線程共享,主要是存放對(duì)象實(shí)例和數(shù)組。如果在Java堆中沒有內(nèi)存完成實(shí)例分配,并且堆也無法再擴(kuò)展時(shí),Java虛擬機(jī)將會(huì)拋出OutOfMemoryError異常。PS:實(shí)際上寫入時(shí)并不完全共享,JVM會(huì)為線程在堆上劃分一塊專屬的分配緩沖區(qū)來提高對(duì)象分配效率。詳見:TLAB
?虛擬機(jī)棧
線程私有,方法執(zhí)行的過程就是一個(gè)個(gè)棧幀從入棧到出棧的過程。每個(gè)方法在執(zhí)行時(shí)都會(huì)創(chuàng)建一個(gè)棧幀(Stack Frame)用于存儲(chǔ)局部變量表、操作數(shù)棧、動(dòng)態(tài)鏈接、方法出口等信息。如果線程入棧的棧幀超過限制就會(huì)拋出StackOverFlowError,如果支持動(dòng)態(tài)擴(kuò)展,那么擴(kuò)展時(shí)申請(qǐng)內(nèi)存失敗則拋出OutOfMemoryError。
?本地方法棧
和虛擬機(jī)棧的功能類似,區(qū)別是作用于Native方法。
?程序計(jì)數(shù)器
線程私有,記錄著當(dāng)前線程所執(zhí)行的字節(jié)碼的行號(hào)。其作用主要是多線程場(chǎng)景下,記錄線程中指令的執(zhí)行位置。以便被掛起的線程再次被激活時(shí),CPU能從其掛起前執(zhí)行的位置繼續(xù)執(zhí)行。唯一一個(gè)在 Java 虛擬機(jī)規(guī)范中沒有規(guī)定任何 OutOfMemoryError 情況的區(qū)域。注意:如果線程執(zhí)行的是個(gè)java方法,那么計(jì)數(shù)器記錄虛擬機(jī)字節(jié)碼指令的地址。如果為native(底層方法),那么計(jì)數(shù)器為空。
1.2 對(duì)象的內(nèi)存布局
在 HotSpot 虛擬機(jī)中,對(duì)象分為如下3塊區(qū)域:
?對(duì)象頭(Header)運(yùn)行時(shí)數(shù)據(jù):哈希碼、GC分代年齡、鎖狀態(tài)標(biāo)志、偏向線程ID、偏向時(shí)間戳等。類型指針:對(duì)象的類型元數(shù)據(jù)的指針,如果對(duì)象是數(shù)據(jù),還會(huì)記錄數(shù)組長度。
?對(duì)象實(shí)例數(shù)據(jù)(Instance Data)包含對(duì)象真正的內(nèi)容,即其包括父類所有字段的值。
?對(duì)齊填充(Padding)對(duì)象大小必須是是8字節(jié)的整數(shù)倍,所以對(duì)象大小不滿足這個(gè)條件時(shí),需要用對(duì)齊填充來補(bǔ)齊。
2 標(biāo)記的方法和流程
2.1 判斷對(duì)象是否需要被回收
要分辨一個(gè)對(duì)象是否可以被回收,有兩種方式:引用計(jì)數(shù)法和可達(dá)性算法。
?引用計(jì)數(shù)法就是在對(duì)象被引用時(shí),計(jì)數(shù)加1,引用斷開時(shí),計(jì)數(shù)減1。那么一個(gè)對(duì)象的引用計(jì)數(shù)為0時(shí),說明這個(gè)對(duì)象可以被清除。這個(gè)算法的問題在于,如果A對(duì)象引用B的同時(shí),B對(duì)象也引用A,即循環(huán)引用,那么雖然雙方的引用計(jì)數(shù)都不為0,但如果僅僅被對(duì)方引用實(shí)際上沒有存在的價(jià)值,應(yīng)該被GC掉。
?可達(dá)性算法通過引用計(jì)數(shù)法的缺陷可以看出,從被引用一方去判定其是否應(yīng)該被清理過于片面,所以我們可以通過相反的方向去定位對(duì)象的存活價(jià)值:一個(gè)存活對(duì)象引用的所有對(duì)象都是不應(yīng)該被清除的(Java中軟引用或弱引用在GC時(shí)有不同判定表現(xiàn),不在此深究)。這些查找起點(diǎn)被稱為GC Root。
2.2 哪些對(duì)象可以作為GC Root呢?
1.JAVA虛擬機(jī)棧中的本地變量引用對(duì)象
2.方法區(qū)中靜態(tài)變量引用的對(duì)象
3.方法區(qū)中常量引用的對(duì)象
4.本地方法棧中JNI引用的對(duì)象
2.3 快速找到GC Root - OopMap
棧與寄存器都是無狀態(tài)的,保守式垃圾收集會(huì)直接線性掃描棧,再判斷每一串?dāng)?shù)字是不是引用,而HotSpot采用準(zhǔn)確式垃圾收集方式,所有對(duì)象都存放在OopMap(Ordinary Object Pointer)中,當(dāng)GC發(fā)生時(shí),直接從這個(gè)map中尋找GC Root。
將GC Root存放到OopMap有兩個(gè)觸發(fā)時(shí)間點(diǎn):
1.類加載完成后,HotSpot就會(huì)把對(duì)象內(nèi)什么偏移量上是什么類型的數(shù)據(jù)計(jì)算出來。
2.即時(shí)編譯過程中,也會(huì)在特定的位置記錄下棧里和寄存器里哪些位置是引用。
2.4 更新OopMap的時(shí)機(jī) - 安全點(diǎn)
導(dǎo)致OopMap更新的指令非常多,所以HotSpot只在特定位置進(jìn)行記錄更新,這些位置叫做安全點(diǎn)。安全點(diǎn)位置的選取的標(biāo)準(zhǔn)是:“是否具有讓程序長時(shí)間執(zhí)行”。比如方法調(diào)用、循環(huán)跳轉(zhuǎn)、異常跳出等等。
2.5 可達(dá)性分析過程
三色標(biāo)記法
?白色:表示垃圾回收過程中,尚未被垃圾收集器訪問過的對(duì)象,在可達(dá)性分析開始階段,所有對(duì)象都是白色的,即不可達(dá)。
?黑色:被垃圾收集器訪問過的對(duì)象,且這個(gè)對(duì)象所有的引用均掃描過。黑色的對(duì)象是安全存活的,如果其他對(duì)象被訪問時(shí)發(fā)現(xiàn)其引用了黑色對(duì)象,該黑色對(duì)象也不會(huì)再被掃描。
?灰色:被垃圾收集器訪問過的對(duì)象,但這個(gè)對(duì)象至少有一個(gè)引用的對(duì)象沒有被掃描過。那么標(biāo)記階段就是從GC Root的開始,沿著其引用鏈將每一個(gè)對(duì)象從白色標(biāo)記為灰色最后標(biāo)記為黑色的過程。
標(biāo)記過程中不一致問題
由于這個(gè)階段是層層遞進(jìn)的標(biāo)記,所以過程中難免出現(xiàn)不一致的情況導(dǎo)致原本是黑色的對(duì)象被標(biāo)記為白色,比如,當(dāng)前掃描到B對(duì)象了,C對(duì)象尚未被訪問時(shí),標(biāo)記情況如下:

那么如果這時(shí)A對(duì)象取消了對(duì)B對(duì)象的引用,而GC Root增加了對(duì)C對(duì)象的引用,GC Root作為黑色標(biāo)記不會(huì)再次被掃描,那么C對(duì)象在標(biāo)記階段結(jié)束后仍然會(huì)保持白色,就會(huì)被清除掉。
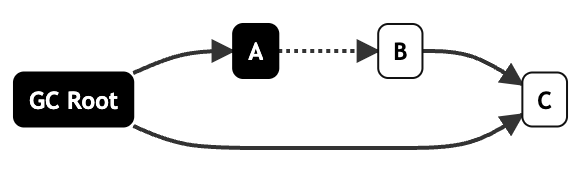
解決方式
?增量更新
當(dāng)黑色對(duì)象增加了對(duì)白色對(duì)象的引用時(shí),將其從黑色改為灰色,等并發(fā)標(biāo)記階段結(jié)束后,從GC Root開始順著對(duì)象圖再將灰色對(duì)象重新掃描一次,這個(gè)掃描過程會(huì)STW,不會(huì)再次產(chǎn)生不一致問題。CMS就采用了這種方式。
?原始快照(SATB)
當(dāng)灰色對(duì)象刪除了白色對(duì)象的引用時(shí),將其記錄在線程獨(dú)占的SATB Queue中,讓其在標(biāo)記階段結(jié)束后被再次掃描。 G1、Shenandoah采用了這種方式。
示例
我們通過一個(gè)例子來展示兩種處理方式的不同,比如正常標(biāo)記到對(duì)象A時(shí),將其標(biāo)記為灰色:

此時(shí),用戶線程發(fā)生如下行為:
1.GC Root直接引用了C
2.A取消了引用B
理論上,C仍然是可達(dá)對(duì)象,不應(yīng)被清除,而B不可達(dá),應(yīng)當(dāng)被清除。
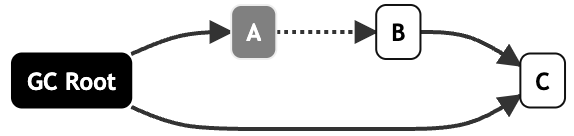
增量更新會(huì)記錄行為1,將GC Root標(biāo)記為灰色,B不能訪問到被標(biāo)記為可以回收:
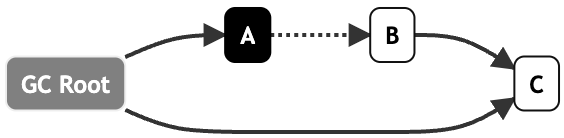
等到重新標(biāo)記階段再次訪問灰色的GC Root,順序?qū)C Root和C標(biāo)記為黑色:
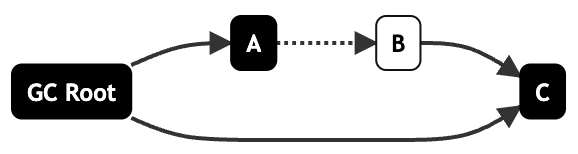
而原始快照會(huì)記錄行為2,將發(fā)生引用變化的對(duì)象全部記錄下來,等到重新標(biāo)記階段再次訪問這些灰色,將其標(biāo)記為黑色并順著對(duì)象圖掃描。
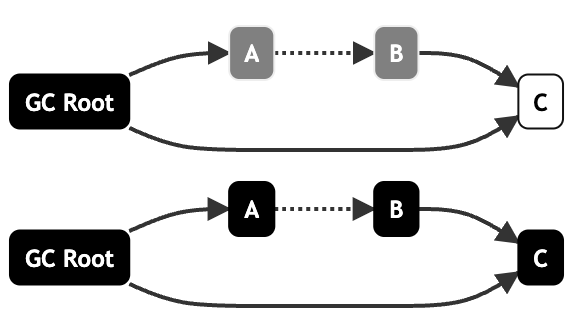
那么最終B作為浮動(dòng)垃圾就被保存下來了,只能等到下一次GC時(shí)才能被回收。
3 分代模型
3.1 分代假說
弱分代假說(WeakGenerationalHypothesis):絕大多數(shù)對(duì)象都是朝生夕滅的。 強(qiáng)分代假說(StrongGenerationalHypothesis):熬過越多次垃圾收集過程的對(duì)象就越難以消亡。 跨代引用假說(IntergenerationalReferenceHypothesis):跨代引用相對(duì)于同代引用來說僅占極少數(shù)。
上述假說是根據(jù)實(shí)際經(jīng)驗(yàn)得來的,由此垃圾收集器通常分為“年輕代”和“年老代”:
?年輕代用來存放不斷生成且生命周期短暫的對(duì)象,收集動(dòng)作相對(duì)高頻
?年老代用來存放經(jīng)歷多次GC仍然存活的對(duì)象,收集動(dòng)作相對(duì)低頻
3.2 空間分配擔(dān)保
如果在GC后新生代存貨對(duì)象過多,Survivor無法容納,那么將會(huì)把這些對(duì)象直接送入年老代,這就叫年老代進(jìn)行了“分配擔(dān)保”。 為了保證年老代能夠足夠空間容納這些直接晉升的對(duì)象,在發(fā)生Minor GC之前,虛擬機(jī)必須先檢查年老代最大可用的連續(xù)空間,如果大于新生代所有對(duì)象總空間或者歷次晉升的平均大小,就會(huì)進(jìn)行MinorGC,否則將進(jìn)行FullGC以同時(shí)清理年老代。
3.3 記憶集和卡表
記憶集是一種用于記錄從非收集區(qū)域指向收集區(qū)域的指針集合的抽象數(shù)據(jù)結(jié)構(gòu)。
記憶集的作用
新生代發(fā)生垃圾收集時(shí)(Minor GC),如果想確定這個(gè)新生代對(duì)象是否被年老代的對(duì)象引用,則需要掃描整個(gè)年老代,成本非常高。
如果我們能知道哪一部分年老代可能存在對(duì)新生代的引用,就可以降低掃描范圍。
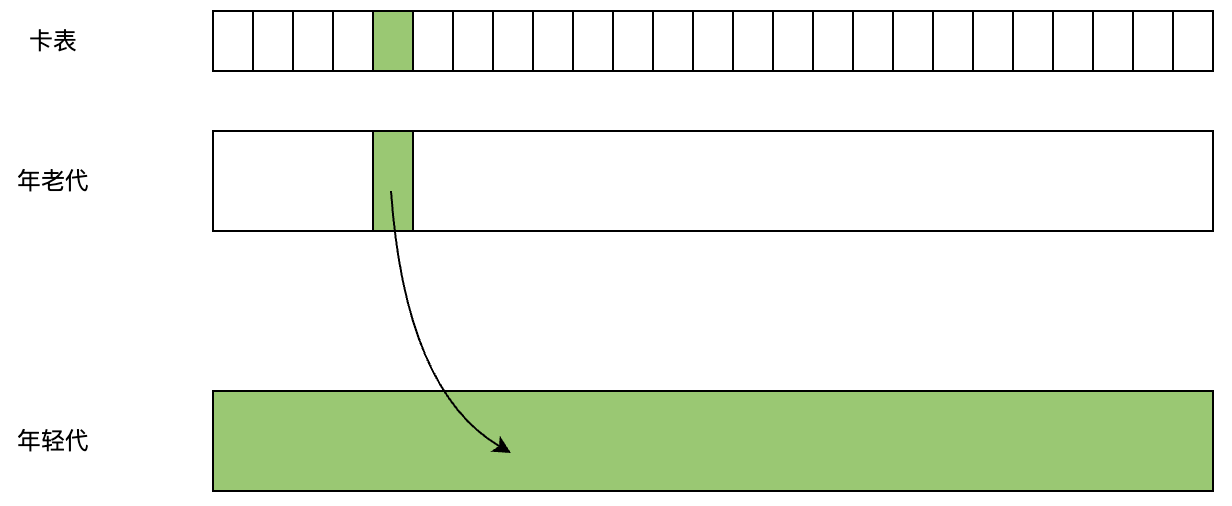
所以我們可以在新生代建立一個(gè)全局?jǐn)?shù)據(jù)結(jié)構(gòu)叫“記憶集(Remembered Set)”,這個(gè)結(jié)構(gòu)把年老代分為若干個(gè)小塊,標(biāo)記了哪些小塊內(nèi)存中存在引用了新生代對(duì)象的情況,等到Minor GC時(shí),只掃描這部分存在跨代引用的內(nèi)存塊即可。雖然在對(duì)象變化時(shí)增加了維護(hù)記憶集的成本,但相比垃圾收集時(shí)掃描整個(gè)年老代來說是值得的。
JVM通常在對(duì)象增加引用前設(shè)置寫屏障判斷是否發(fā)生跨代引用,如果有跨代情況,則更新記憶集。
卡表
實(shí)現(xiàn)記憶集時(shí),可以有不同精度的粒度:可以指向內(nèi)存地址,也可以指向某個(gè)對(duì)象,或者指向某一塊內(nèi)存區(qū)域。精度越低,維護(hù)成本越低。指向某一塊內(nèi)存區(qū)域的實(shí)現(xiàn)方式就是“卡表”。卡表通常就是一個(gè)byte數(shù)組,數(shù)組中每一個(gè)元素代表某一塊內(nèi)存,其值是1或者0:當(dāng)發(fā)生跨代引用時(shí),就表示該元素“dirty”了,那么將將其設(shè)置為1,否則就是0。
4 垃圾回收算法
4.1 標(biāo)記-清除(Mark-Sweep)
GC分為兩個(gè)階段,標(biāo)記和清除。首先標(biāo)記所有可回收的對(duì)象,在標(biāo)記完成后統(tǒng)一回收所有被標(biāo)記的對(duì)象。
缺點(diǎn)是清除后會(huì)產(chǎn)生不連續(xù)的內(nèi)存碎片。碎片過多會(huì)導(dǎo)致以后程序運(yùn)行時(shí)需要分配較大對(duì)象時(shí),無法找到足夠的連續(xù)內(nèi)存,而不得已再次觸發(fā)GC。

4.2 標(biāo)記-復(fù)制(Mark-Copy)
將內(nèi)存按容量劃分為兩塊,每次只使用其中一塊。當(dāng)這一塊內(nèi)存用完了,就將存活的對(duì)象復(fù)制到另一塊上,然后再把已使用的內(nèi)存空間一次清理掉。
這樣使得每次都是對(duì)半個(gè)內(nèi)存區(qū)回收,也不用考慮內(nèi)存碎片問題,簡單高效。

缺點(diǎn)需要兩倍的內(nèi)存空間。
一種優(yōu)化方式是使用eden和survivior區(qū),具體步驟如下:
eden和survivior區(qū)默認(rèn)內(nèi)存空間占比為8:1:1,同一時(shí)間只使用eden區(qū)和其中一個(gè)survivior區(qū)。標(biāo)記完成后,將存活對(duì)象復(fù)制到另一個(gè)未使用的survivior區(qū)(部分年齡過大的對(duì)象將升級(jí)到年老代)。
這種做法,相比普通的兩塊空間的標(biāo)記復(fù)制算法來說,只有10%的內(nèi)存空間浪費(fèi),而這樣做的原因是:大部分情況下,一次young gc后剩余的存活對(duì)象非常少。

4.3 標(biāo)記-整理(Mark-Compact)
標(biāo)記-整理也分為兩個(gè)階段,首先標(biāo)記可回收的對(duì)象,再將存活的對(duì)象都向一端移動(dòng),然后清理掉邊界以外的內(nèi)存。
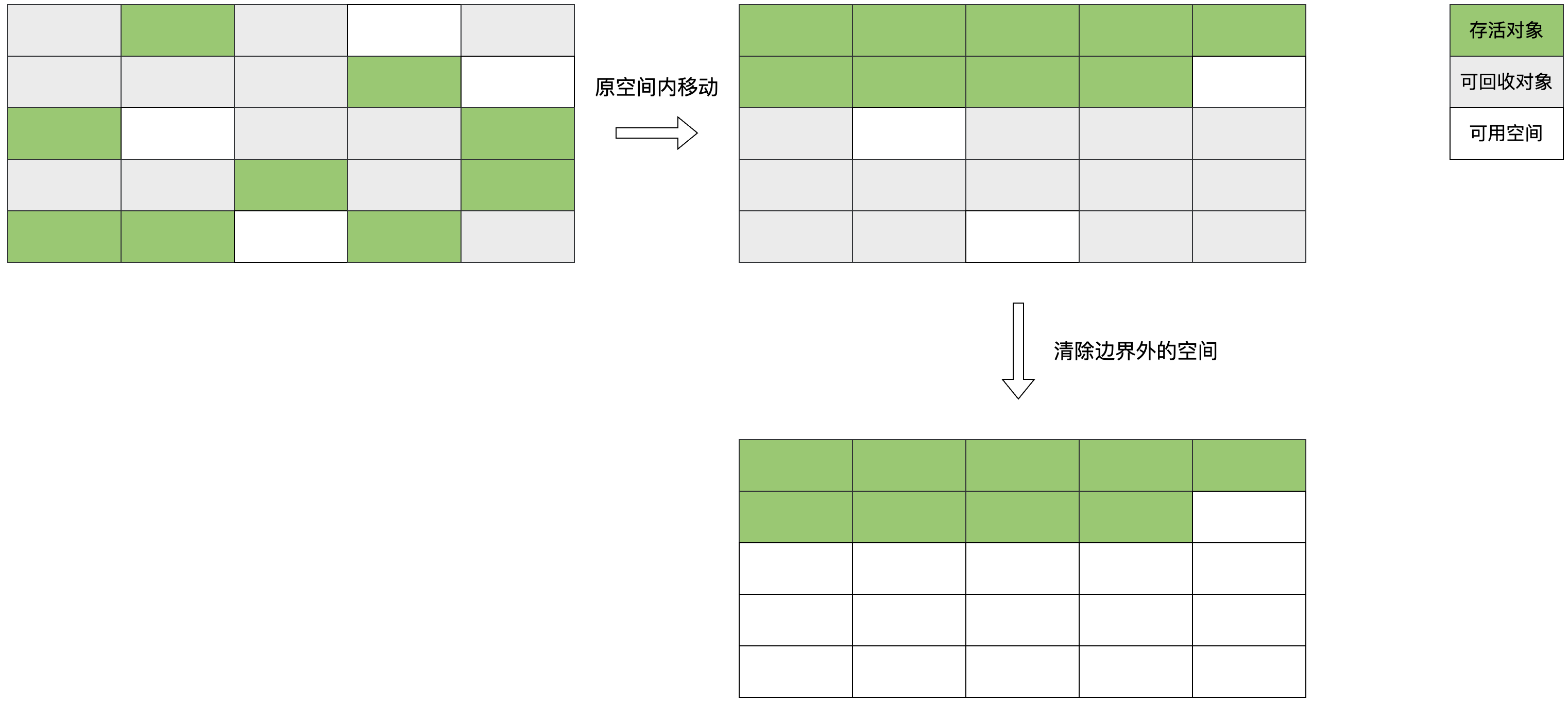
此方法避免標(biāo)記-清除算法的碎片問題,同時(shí)也避免了復(fù)制算法的空間問題。 一般年輕代中執(zhí)行GC后,會(huì)有少量的對(duì)象存活,就會(huì)選用復(fù)制算法,只要付出少量的存活對(duì)象復(fù)制成本就可以完成收集。
而年老代中因?yàn)閷?duì)象存活率高,用標(biāo)記復(fù)制算法時(shí)數(shù)據(jù)復(fù)制效率較低,且空間浪費(fèi)較大。所以需要使用標(biāo)記-清除或者標(biāo)記-整理算法來進(jìn)行回收。
所以通常可以先使用標(biāo)記清除算法,當(dāng)碎片率高時(shí),再使用標(biāo)記整理算法。
5 最后
本篇介紹了JVM中垃圾回收器相關(guān)的基礎(chǔ)知識(shí),后續(xù)會(huì)深入介紹CMS、G1、ZGC等不同垃圾收集器的運(yùn)作流程和原理,歡迎關(guān)注。
?
系列文章:
從原理聊JVM(一):染色標(biāo)記和垃圾回收算法
從原理聊JVM(二):從串行收集器到分區(qū)收集開創(chuàng)者G1
從原理聊JVM(三):詳解現(xiàn)代垃圾回收器Shenandoah和ZGC
從原理聊JVM(四):JVM中的方法調(diào)用原理
從原理聊JVM(五):JVM中的編譯過程和優(yōu)化手段?
審核編輯 黃宇
-
算法
+關(guān)注
關(guān)注
23文章
4711瀏覽量
95437 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3125瀏覽量
75294 -
JVM
+關(guān)注
關(guān)注
0文章
160瀏覽量
12631
發(fā)布評(píng)論請(qǐng)先 登錄
PCB絲印極性標(biāo)記的實(shí)用設(shè)計(jì)技巧
生活垃圾焚燒發(fā)電廠數(shù)據(jù)采集可視化管理系統(tǒng)
智能可回收箱:引領(lǐng)垃圾分類新潮流,推動(dòng)城市環(huán)保與資源循環(huán)利用發(fā)展

垃圾回收破碎機(jī)遠(yuǎn)程監(jiān)控物聯(lián)網(wǎng)系統(tǒng)方案
如何一眼定位SQL的代碼來源:一款SQL染色標(biāo)記的簡易MyBatis插件

物聯(lián)網(wǎng)+垃圾桶滿溢檢測(cè)器回收系統(tǒng)解決方案

智能垃圾投放站遠(yuǎn)程監(jiān)控智慧運(yùn)維系統(tǒng)方案
垃圾短信?手機(jī)自動(dòng)識(shí)別垃圾短信邏輯的分析
?ISP算法及架構(gòu)分析介紹

【「從算法到電路—數(shù)字芯片算法的電路實(shí)現(xiàn)」閱讀體驗(yàn)】+介紹基礎(chǔ)硬件算法模塊
【「從算法到電路—數(shù)字芯片算法的電路實(shí)現(xiàn)」閱讀體驗(yàn)】+一本介紹基礎(chǔ)硬件算法模塊實(shí)現(xiàn)的好書
談JVM xmx, xms等內(nèi)存相關(guān)參數(shù)合理性設(shè)置
名單公布!【書籍評(píng)測(cè)活動(dòng)NO.46】從算法到電路 | 數(shù)字芯片算法的電路實(shí)現(xiàn)
智能回收箱的功能和使用步驟介紹

聊聊JVM如何優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論