") 特倫托大學(xué)與Inria合作:使用GAN生成人體的新姿勢(shì)圖像
特倫托大學(xué)與Inria合作:使用GAN生成人體的新姿勢(shì)圖像
意大利Trento大學(xué)和法國(guó)國(guó)立計(jì)算機(jī)及自動(dòng)化研究院研究人員(Aliaksandr Siarohin、Enver Sangineto、Stephane Lathuiliere、Nicu Sebe)合作,使用GAN(對(duì)抗生成網(wǎng)絡(luò))生成人體的新姿勢(shì)圖像。研究人員提出的可變形跳躍連接和最近鄰損失函數(shù),更好地捕捉了局部的紋理細(xì)節(jié),緩解了之前研究生成圖像模糊的問(wèn)題,生成了更可信、質(zhì)量更好的圖像。
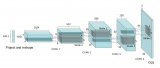
網(wǎng)絡(luò)架構(gòu)
生成視覺(jué)內(nèi)容的深度學(xué)習(xí)方法,最常用的就是變分自動(dòng)編碼器(VAE)和生成對(duì)抗網(wǎng)絡(luò)(GAN)。VAE基于概率圖模型,通過(guò)最大化相應(yīng)數(shù)據(jù)的似然的下界進(jìn)行訓(xùn)練。GAN模型基于兩個(gè)網(wǎng)絡(luò):一個(gè)生成網(wǎng)絡(luò)和一個(gè)判別網(wǎng)絡(luò)。兩個(gè)網(wǎng)絡(luò)同時(shí)訓(xùn)練,生成網(wǎng)絡(luò)嘗試“愚弄”判別網(wǎng)絡(luò),而判別網(wǎng)絡(luò)則學(xué)習(xí)如何分辨真實(shí)圖像和虛假圖像。
現(xiàn)有的姿勢(shì)生成方面的工作大部分基于條件GAN,這里研究人員也使用了條件GAN。之前一些工作使用了兩段式方法:第一個(gè)階段進(jìn)行姿勢(shì)集成,第二個(gè)階段進(jìn)行圖像改良。研究人員則使用了端到端的方法。
既然使用GAN,那網(wǎng)絡(luò)架構(gòu)的設(shè)計(jì)就包括兩部分,生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)。其中,一般而言,判別網(wǎng)絡(luò)的設(shè)計(jì)相對(duì)容易。這符合直覺(jué),比如,判別畫作的真假要比制作一幅足以以假亂真的贗品容易得多。因此,我們首先考慮判別網(wǎng)絡(luò)的情形。
判別網(wǎng)絡(luò)
我們考慮判別網(wǎng)絡(luò)的輸入和輸出。
首先是相對(duì)簡(jiǎn)單的輸出。判別網(wǎng)絡(luò)的輸出,基本上就是兩種,一種是離散的分類結(jié)果,真或假,一種是連續(xù)的標(biāo)量,表明判別網(wǎng)絡(luò)對(duì)圖像是否為真的信心(confidence)。這里研究人員選擇了后者作為判別網(wǎng)絡(luò)的輸出。
判別網(wǎng)絡(luò)的輸入,最簡(jiǎn)單的情形,就是接受一張圖像,可能是真實(shí)圖像,也可能是生成網(wǎng)絡(luò)偽造的圖像(即生成網(wǎng)絡(luò)的輸出)。不過(guò),具體到這個(gè)特定的問(wèn)題,從原始圖像生成同一人物的新姿勢(shì)圖像,那么,其實(shí)模型還可以給判別網(wǎng)絡(luò)提供一些額外的信息,幫助判別網(wǎng)絡(luò)判斷圖像的真假。
首先可以提供的是原始圖像。其次,是相關(guān)的姿勢(shì)信息,具體而言,包括從原始圖像中提取的姿勢(shì)信息,也包括目標(biāo)姿勢(shì)信息。因此,實(shí)際上判別網(wǎng)絡(luò)接受的輸入是4個(gè)tensor構(gòu)成的元組(xa, Ha, y, Hb)。其中,xa是表示原始圖像的tensor,Ha與Hb分別表示原始圖像的姿勢(shì)和目標(biāo)姿勢(shì)。y是真實(shí)圖像(xb)或生成網(wǎng)絡(luò)的輸出。
如前所述,判別網(wǎng)絡(luò)的工作相對(duì)簡(jiǎn)單,因此判別網(wǎng)絡(luò)的輸入層也就不對(duì)這4個(gè)tensor組成的元組做什么特別的處理了,直接連接(concatenate)就行了。
生成網(wǎng)絡(luò)
如前所述,生成網(wǎng)絡(luò)的設(shè)計(jì)需要多費(fèi)一點(diǎn)心思。
同樣,我們先考慮生成網(wǎng)絡(luò)的輸出,很簡(jiǎn)單,生成網(wǎng)絡(luò)的輸出就是圖像,具體而言,是一個(gè)表示圖像的tensor。
那么,生成網(wǎng)絡(luò)的輸入是什么呢?其實(shí)很簡(jiǎn)單,從判別網(wǎng)絡(luò)的輸入,我們不難得到生成網(wǎng)絡(luò)的輸入。判別網(wǎng)絡(luò)的輸入,正如我們前面提到的,是4個(gè)tensor構(gòu)成的元組(xa, Ha, y, Hb)。其中,這個(gè)y正是生成網(wǎng)絡(luò)需要生成的,所以我們?nèi)サ魕,得到(xa, Ha, Hb)。這個(gè)差不多就可以作為生成網(wǎng)絡(luò)的輸入了。生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)兩者輸入上的相似性,很符合直覺(jué)。那些有助于判別圖像真假的信息,同樣有助于偽造虛假的圖像。
不過(guò),圖像多少存在噪點(diǎn),因此,為了處理數(shù)據(jù)樣本的噪點(diǎn)問(wèn)題,以更好地學(xué)習(xí)以假亂真的技術(shù),生成網(wǎng)絡(luò)還額外接受一個(gè)噪聲向量z作為輸入。因此,生成網(wǎng)絡(luò)的輸入為(z, xa, Ha, Hb)。判別網(wǎng)絡(luò)就不操心噪點(diǎn)的問(wèn)題,這是因?yàn)榕袆e網(wǎng)絡(luò)的工作要容易很多,不是嗎?
判別網(wǎng)絡(luò)的輸入是直接連接的,生成網(wǎng)絡(luò),因?yàn)槊媾R的任務(wù)要困難很多,因此并不直接連接xa、Ha、Hb。因?yàn)椋琀a是基于xa提取的姿勢(shì)信息,所以,兩者之間存在著一致性,或者說(shuō),緊密的聯(lián)系。而Hb是目標(biāo)姿勢(shì),與xa和Ha的關(guān)系不那么緊密。因此,分開(kāi)來(lái)處理比較好。研究人員正是這么做的,將xa和Ha連接起來(lái),使用編碼器的一個(gè)卷積流處理,而Hb則使用另一個(gè)卷積流處理,兩者之間不共享權(quán)重。
姿勢(shì)的表示
上面我們提到了Ha和Hb,也就是姿勢(shì)信息,可是這些姿勢(shì)信息到底是如何表示的呢?
表示姿勢(shì)最簡(jiǎn)單的方法就是找出各個(gè)關(guān)節(jié)(抽象成點(diǎn)),然后將這些關(guān)節(jié)連起來(lái)(線),用點(diǎn)線組合(關(guān)節(jié)位置)來(lái)表示姿勢(shì)。
從圖像中提取姿勢(shì)(關(guān)節(jié)位置)后,還需要轉(zhuǎn)換成生成網(wǎng)絡(luò)能夠理解的形式。以往的工作發(fā)現(xiàn)用熱圖的效果不錯(cuò),這里研究人員也同樣使用熱圖來(lái)表示姿勢(shì)。也就是說(shuō),如果我們用P(xa)表示從x中提取的姿勢(shì)(P為pose即姿勢(shì)的首字母),那么Ha= H(P(xa))(H為heat map即熱圖的首字母)。其中,Ha由k張熱圖組成,Hj(1<=j<=k)是一個(gè)維數(shù)與原始圖像一致的二維矩陣。熱圖與關(guān)節(jié)位置滿足以下關(guān)系:
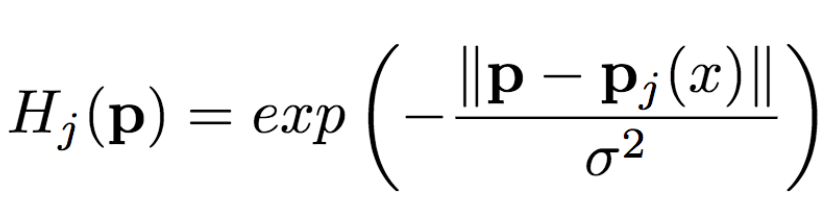
其中,pj為第j個(gè)關(guān)節(jié)位置,σ = 6像素。
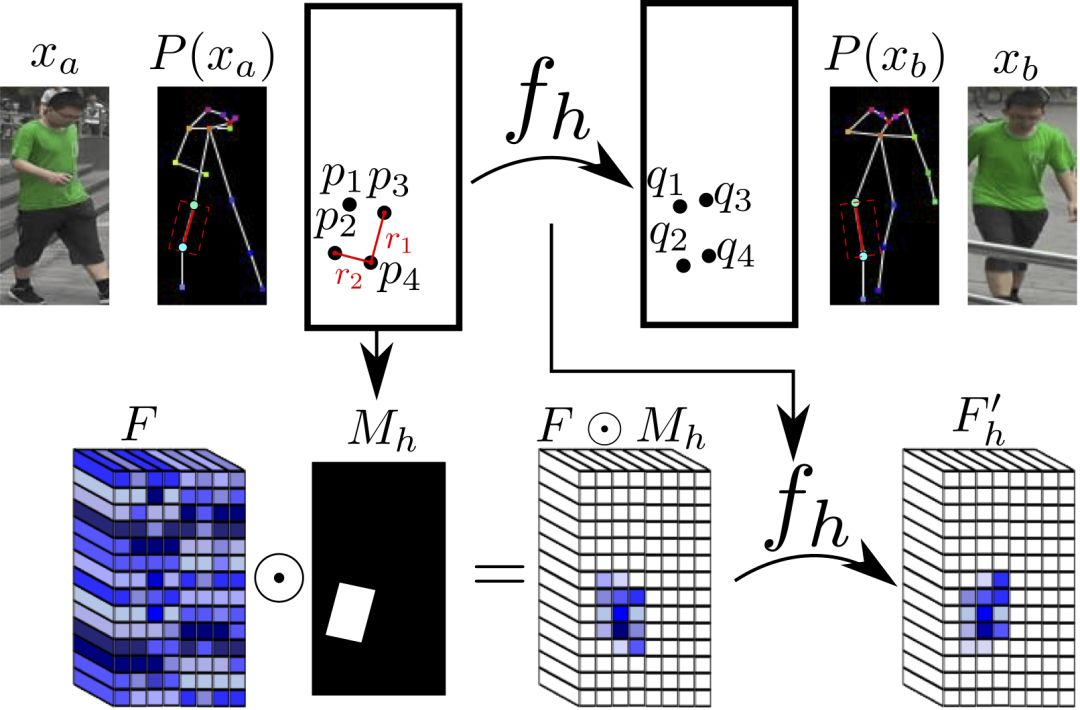
整個(gè)網(wǎng)絡(luò)架構(gòu)如下圖所示:
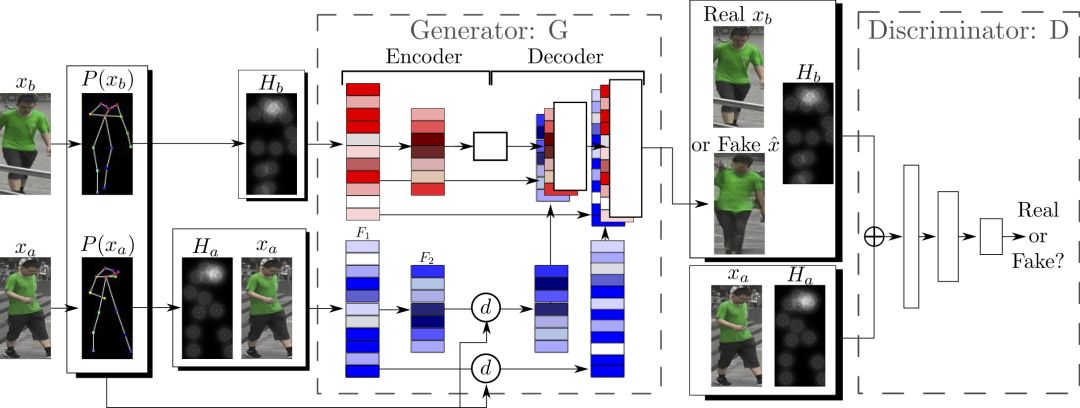
可變形跳躍連接
姿勢(shì)的轉(zhuǎn)變,可以看成是一個(gè)空間變形問(wèn)題。常見(jiàn)的思路是由編碼器編碼相關(guān)的變形信息,然后由解碼器將編碼的變形信息加以還原。而由編碼器和解碼器組成的網(wǎng)絡(luò)架構(gòu),常用的為U-Net。因此,以往的一些研究廣泛使用基于U-Net的方法完成基于姿勢(shì)的人像圖片生成任務(wù)。然而,普通的U-Net跳躍連接不太適合較大的空間變形,因?yàn)樵诳臻g變形較大的情況下,輸入圖像和輸出圖像的局部信息沒(méi)有對(duì)齊。
既然,較大的空間變形有局部信息不對(duì)齊的問(wèn)題,那將空間變形分拆成不同的部分,這樣每個(gè)部分之間就對(duì)齊了。
研究人員基于以上的想法提出了可變形跳躍連接(deformable skip connection),將全局變形分解為一組由關(guān)節(jié)的子集定義的局部仿射變換,然后再將這些局部仿射變換組合起來(lái)以逼近全局變形。
分解人體
如前所述,局部仿射變換是由關(guān)節(jié)的子集定義的。因此我們先要?jiǎng)澐株P(guān)節(jié)的子集,也就是,分解人體。研究人員將人體分解為10個(gè)部分,頭、軀干、左上臂、右上臂、左前臂、右前臂、左大腿、左小腿、右大腿、右小腿。
每個(gè)部分具體區(qū)塊的劃分,基于關(guān)節(jié)進(jìn)行。
頭部和軀干的區(qū)塊定義很簡(jiǎn)單,只要對(duì)齊軸線,劃出包圍所有關(guān)節(jié)的矩形即可。
四肢的情形比較復(fù)雜。四肢由兩個(gè)關(guān)節(jié)組成,研究人員使用一個(gè)傾斜的矩形來(lái)劃分四肢區(qū)塊。這個(gè)矩形的一條邊r1為平行于關(guān)節(jié)連線的直線,另一條邊r2和r1垂直,長(zhǎng)度等于軀干對(duì)角線均值的三分之一(統(tǒng)一使用此值)。這樣我們就得到了一個(gè)矩形。
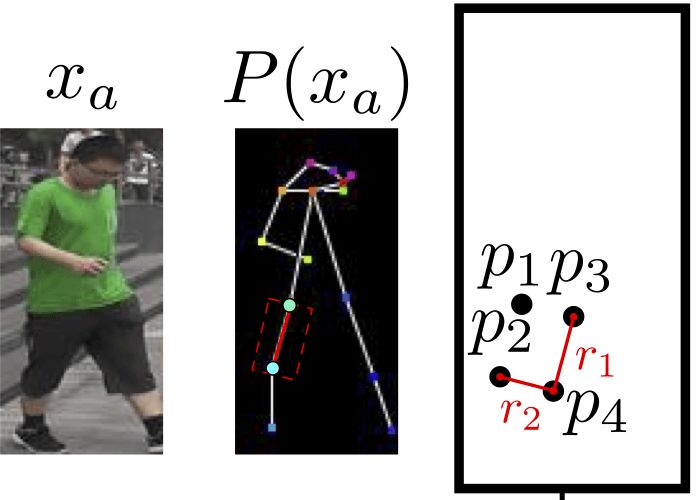
上圖為一個(gè)例子。我們可以將切分的區(qū)域表示為Rha= {p1, ..., p4}。其中,R代表區(qū)域(region的首字母),h表示這是人體的第h個(gè)區(qū)域,a表示這一區(qū)域?qū)儆趫D像xa,p1到p4為區(qū)域矩形的四個(gè)頂點(diǎn),注意,這些并非關(guān)節(jié)。
仿射變換
然后,我們可以計(jì)算Rha的二元掩膜Mh(p),除了Rha內(nèi)的點(diǎn)之外,其余位置的值均為零。
類似地,Rhb= {q1, ..., q4}為圖像xb中對(duì)應(yīng)的矩形局域。匹配Rha與Rhb中的點(diǎn),可以計(jì)算出這一部分的仿射變換fh的6個(gè)參數(shù)kh:
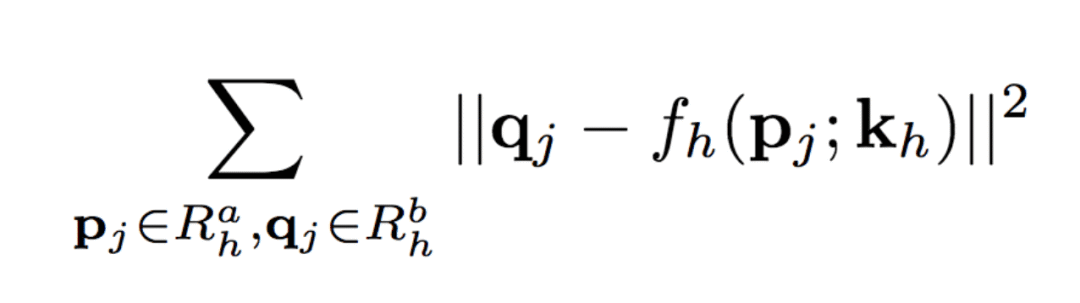
以上的仿射變換的參數(shù)向量kh基于原始圖像的分辨率計(jì)算,然后根據(jù)不同卷積特征映射的特定分辨率分別計(jì)算相應(yīng)的版本。類似地,可以計(jì)算每個(gè)二元掩膜Mh的不同分辨率的版本。
實(shí)際圖像中,相應(yīng)的區(qū)域可能被其他部分遮蔽,或者位于圖像邊框之外,或者未被成功檢測(cè)到。對(duì)于這種情況,研究人員直接將Mh設(shè)定為所有元素值為0的矩陣,不計(jì)算fh。(其實(shí),當(dāng)缺失的區(qū)域?yàn)樗闹珪r(shí),如果對(duì)稱的身體部分未缺失,例如右上臂缺失,而左上臂被成功檢測(cè)到,那么可以拷貝對(duì)稱部分的信息。)
對(duì)于數(shù)據(jù)集中的每對(duì)真實(shí)圖像(xa, xb),(fh(), Mh)及其分辨率較低的變體只需計(jì)算一次。
另外,這也是整個(gè)模型中唯一與人體相關(guān)的部分,因此,整個(gè)模型可以很容易地?cái)U(kuò)展,用于解決其他可變形物體的生成任務(wù)。
仿射變換示意圖
組合仿射變換
一旦計(jì)算出人體各個(gè)區(qū)域的(fh(), Mh)后,這些局部的仿射變換可以組合起來(lái)逼近全局姿勢(shì)變形。
具體而言,研究人員首先基于每個(gè)區(qū)域計(jì)算:
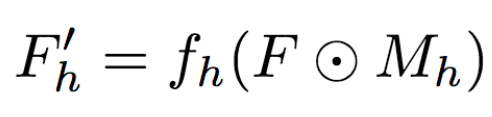
然后,研究人員將其組合:
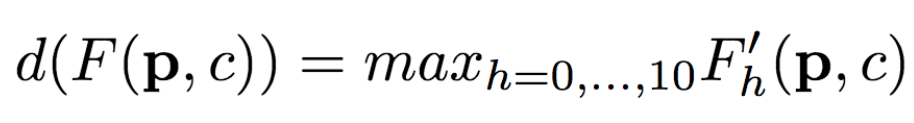
其中,F(xiàn)'0= F(未變形),可以提供背景點(diǎn)的紋理信息。這里,研究人員選用了最大激活,研究人員還試驗(yàn)了平均池化,平均池化的效果要稍微差一點(diǎn)。
最近鄰損失
訓(xùn)練生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)時(shí),除了標(biāo)準(zhǔn)的條件對(duì)抗損失函數(shù)LcGAN外,研究人員還使用了最近鄰損失LNN。
LcGAN的具體定義為:
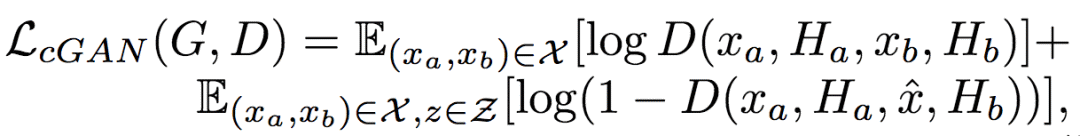
其中,帶帽子的x為生成網(wǎng)絡(luò)的生成圖像G(z, xa, Ha, Hb)。
在標(biāo)準(zhǔn)的LcGAN之外,之前的一些研究配合使用基于L1或L2的損失函數(shù)。比如,L1計(jì)算生成圖像和真實(shí)圖像之間像素到像素的差別:
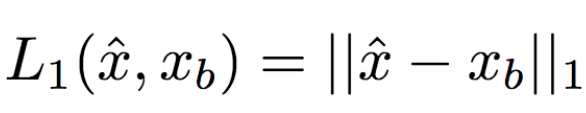
然而,L1和L2會(huì)導(dǎo)致生成模糊的圖像。研究人員猜想,其原因可能是這兩類損失函數(shù)無(wú)法容納生成圖像和真實(shí)圖像間細(xì)小的空間不對(duì)齊。比如,假定生成網(wǎng)絡(luò)生成的圖像看起來(lái)很可信,在語(yǔ)義上也與真實(shí)圖像相似,但是兩張圖片服飾上的紋理細(xì)節(jié)的像素沒(méi)有對(duì)齊。L1和L2都會(huì)懲罰這樣不精確的像素級(jí)別的對(duì)齊,盡管在人類看來(lái),這些并不重要。為了緩和這一問(wèn)題,研究人員提出了新的最近鄰LNN:

其中,N(p)是點(diǎn)p的n x n局部近鄰。g(x(p))是點(diǎn)p附近的補(bǔ)丁的向量表示,g(x(p))由卷積過(guò)濾器得出。研究人員通過(guò)比較生成圖像和真實(shí)圖像之間的補(bǔ)丁表示(g()),以便高效地計(jì)算LNN。具體而言,研究人員選用了在ImageNet上訓(xùn)練過(guò)的VGG-19的第二個(gè)卷積層(conv12)。VGG-19的頭兩個(gè)卷積層(conv11和conv12)的卷積跨距均為1,因此,圖像x在conv12中的特征映射Cx和原始圖像x具備相同的分辨率。利用這一事實(shí),研究人員得以在conv1_2上直接計(jì)算最近鄰,這不會(huì)損害空間準(zhǔn)確度,即g(x(p)) = Cx(p)。據(jù)此,LNN的定義變?yōu)椋?/p>
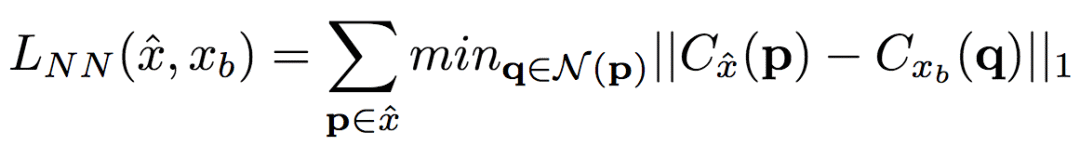
研究人員最終優(yōu)化了以上LNN的實(shí)現(xiàn),使其得以在GPU上并行運(yùn)算。
因此,最終的基于LNN的損失函數(shù)定義為:
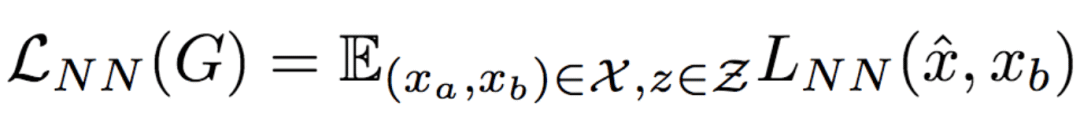
將上式與LcGAN結(jié)合,得到目標(biāo)函數(shù):
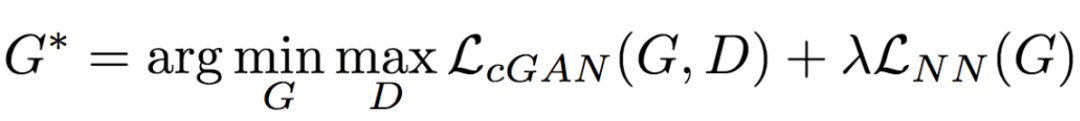
研究人員將上式中的λ的值設(shè)定為0.01,λ起到了正則化因子的作用。
實(shí)現(xiàn)細(xì)節(jié)
訓(xùn)練生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)時(shí),研究人員使用了9萬(wàn)次迭代,并使用了Adam優(yōu)化(學(xué)習(xí)率:2x10-4,β1= 0.5, β2= 0.999)。
如前所述,生成網(wǎng)絡(luò)的編碼器部分包含兩個(gè)流,每個(gè)流由以下層的序列組成:
CN641- CN1282- CN2562- CN5122- CN5122- CN5122
其中,CN641表示使用實(shí)例歸一化、ReLU激活、64個(gè)過(guò)濾器、跨距為1的卷積層,后同。
相應(yīng)的生成網(wǎng)絡(luò)的解碼器部分由以下序列組成:
CD5122- CD5122- CD5122- CN5122- CN1282- CN31
其中,CD5122與CN5122類似,只不過(guò)額外附加了50%的dropout。另外,最后一個(gè)卷積層沒(méi)有應(yīng)用實(shí)例歸一化,同時(shí)使用tanh而不是ReLU作為激活函數(shù)。
判別網(wǎng)絡(luò)使用如下序列:
CN642- CN1282- CN2562- CN5122- CN12
其中,最后一個(gè)卷積層沒(méi)有應(yīng)用實(shí)例歸一化,同時(shí)使用sigmoid而不是ReLU作為激活函數(shù)。
用于DeepFashion數(shù)據(jù)集(研究人員使用的其中一個(gè)數(shù)據(jù)集,詳見(jiàn)下節(jié))的生成網(wǎng)絡(luò)的編碼器和解碼器使用了一個(gè)額外的卷積層(CN5122),因?yàn)閿?shù)據(jù)集中的圖像有更高的分辨率。
試驗(yàn)
數(shù)據(jù)集
研究人員使用了兩個(gè)數(shù)據(jù)集:
Market-1501
DeepFashion
Market-1501包含使用6個(gè)監(jiān)控?cái)z像頭拍攝的1501人的32668張圖像。由于圖像的低分辨率(128x64),及姿勢(shì)、光照、背景和視角的多樣性,這一數(shù)據(jù)集很具挑戰(zhàn)性。研究人員首先剔除了未檢測(cè)到人體的圖像,得到了263631對(duì)訓(xùn)練圖像(一對(duì)圖像為同一人的不同姿勢(shì)圖像)。研究人員隨機(jī)選擇了12000對(duì)圖像作為測(cè)試集。
DeepFashion包含52712張服飾圖像,其中有200000對(duì)相同服飾、不同姿勢(shì)或尺碼的圖像。圖像的分辨率為256x256。研究人員選擇了同一人穿戴相同服飾但姿勢(shì)不同的圖像對(duì),其中,隨機(jī)選擇1000種服飾作為測(cè)試集,剩余12029種服飾作為訓(xùn)練集。去除未檢測(cè)到人體的圖像后,研究人員最終收集了101268對(duì)圖像作為訓(xùn)練集,8670對(duì)圖像作為測(cè)試集。
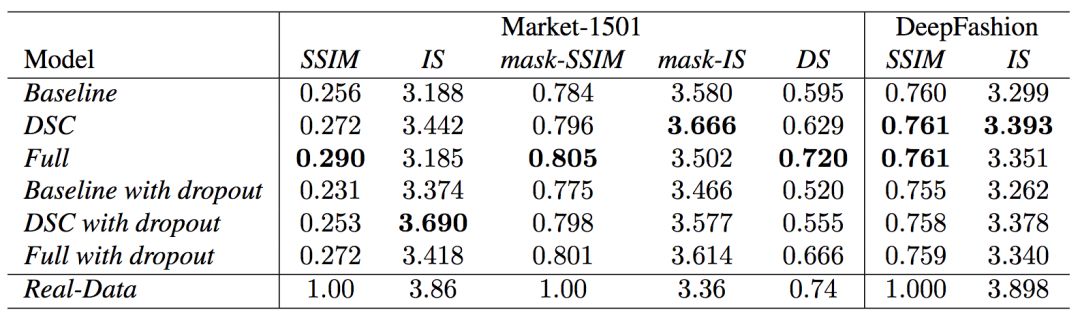
定量評(píng)估
定量評(píng)估生成內(nèi)容本身是一個(gè)正在研究中的問(wèn)題。目前的研究文獻(xiàn)中出現(xiàn)了兩種衡量標(biāo)準(zhǔn):SSIM(Structural Similarity,結(jié)構(gòu)化相似性)和IS(Inception Score)。
然而,姿勢(shì)生成任務(wù)中只有一個(gè)物體分類(人類),IS指標(biāo)卻基于外部分類器的分類神經(jīng)元計(jì)算所得的熵值,因此兩者不是十分契合。實(shí)際上,研究人員發(fā)現(xiàn)IS值與生成圖像的質(zhì)量間的相關(guān)性常常比較弱。因此,研究人員提出了一個(gè)額外的DS(Detection Score,檢測(cè)分?jǐn)?shù))指標(biāo)。DS基于最先進(jìn)的物體檢測(cè)模型SSD的檢測(cè)輸出,SSD基于Pascal VOC 07數(shù)據(jù)集進(jìn)行訓(xùn)練。這意味著,DS衡量生成圖像的真實(shí)性(有多像人)。

上為當(dāng)前最先進(jìn)模型,中為研究人員使用的模型,下為真實(shí)圖像
可以看到,總體而言,模型的表現(xiàn)超過(guò)了當(dāng)前最先進(jìn)的模型。另外,注意真實(shí)圖像的DS值不為1,這是因?yàn)镾SD不能100%檢測(cè)出人體。
定性評(píng)估
研究人員同樣進(jìn)行了定性評(píng)估。

可以很明顯地看出,由于采用了基于LNN的損失函數(shù),模型顯著減少了生成圖像的模糊程度。
DeepFashion上的定性評(píng)估結(jié)果類似。
消融測(cè)試
為了驗(yàn)證模型的有效性,研究人員還進(jìn)行了定性和定量的消融測(cè)試。

Market-1501
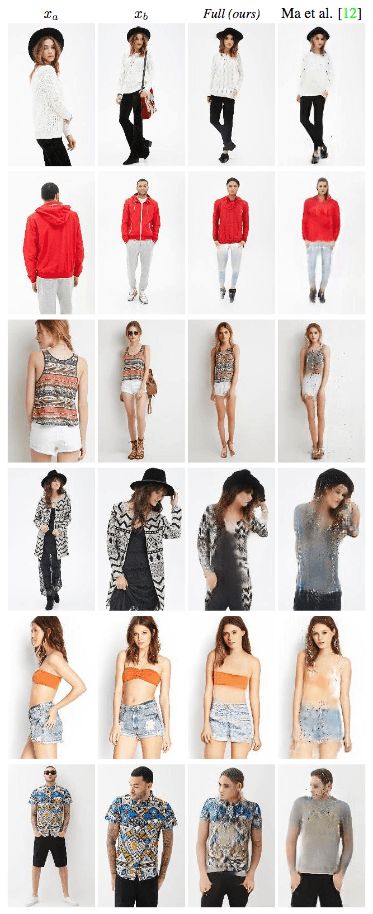
上圖為在Market-1501數(shù)據(jù)集上進(jìn)行的定性消融測(cè)試。第1、2、3列表示模型的輸入。第4列為真實(shí)圖像。第5列為基準(zhǔn)輸出(不使用可變形跳躍連接的U-Net架構(gòu),另外,生成網(wǎng)絡(luò)中,xa、Ha、Hb直接連接作為輸入,也就是說(shuō)生成網(wǎng)絡(luò)的編碼器只包含一個(gè)流,訓(xùn)練網(wǎng)絡(luò)時(shí)使用基于L1的損失函數(shù)),第6列DSC為使用基于L1的損失函數(shù)訓(xùn)練的模型,第7列Full為完整的模型。
可以看到,研究人員提出的模型生成的圖像看起來(lái)更真實(shí),也保留了更多的紋理細(xì)節(jié)。
研究人員在DeepFashion上取得了相似的結(jié)果。

研究人員也進(jìn)行了定量的消融測(cè)試,并額外試驗(yàn)了加上dropout(生成網(wǎng)絡(luò)和判別網(wǎng)絡(luò)同時(shí)應(yīng)用dropout)的效果。
-
GaN
+關(guān)注
關(guān)注
19文章
2184瀏覽量
76284 -
網(wǎng)絡(luò)架構(gòu)
+關(guān)注
關(guān)注
1文章
96瀏覽量
12853 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122546
原文標(biāo)題:特倫托大學(xué)、Inria合作研究:基于GAN生成人體的新姿勢(shì)圖像
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于擴(kuò)散模型的圖像生成過(guò)程

奧特斯與重慶大學(xué)達(dá)成校企合作協(xié)議
圖像生成對(duì)抗生成網(wǎng)絡(luò)gan_GAN生成汽車圖像 精選資料推薦
探討條件GAN在圖像生成中的應(yīng)用
FAIR和INRIA的合作提出人體姿勢(shì)估計(jì)新模型,適用于人體3D表面構(gòu)建
移動(dòng)4G網(wǎng)絡(luò),開(kāi)啟看世界杯直播新姿勢(shì)
圖像遷移最新成果:人體姿勢(shì)和舞蹈動(dòng)作遷移
基于DensePose的姿勢(shì)轉(zhuǎn)換系統(tǒng),僅根據(jù)一張輸入圖像和目標(biāo)姿勢(shì)
GAN在圖像生成應(yīng)用綜述

必讀!生成對(duì)抗網(wǎng)絡(luò)GAN論文TOP 10
生成對(duì)抗網(wǎng)絡(luò)GAN論文TOP 10,幫助你理解最先進(jìn)技術(shù)的基礎(chǔ)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論