") 機器學習入門需要掌握的八大基礎(chǔ)概念
機器學習入門需要掌握的八大基礎(chǔ)概念
準備好開始AI了嗎?可能你已經(jīng)開始了在機器學習領(lǐng)域的實踐學習,但是依然想要擴展你的知識并進一步了解那些你聽過卻沒有時間了解的話題。
這些機器學習的專業(yè)術(shù)語能夠簡要地介紹最重要的機器學習概念—包括商業(yè)界和科技界都感興趣的話題。在你遇到一位AI指導者之前,這是一份不詳盡,但清楚易懂又方便在工作、面試前快速瀏覽的內(nèi)容。
1 自然語言處理
自然語言處理對于許多機器學習方法來說是一個常用的概念,它使得計算機理解并使用人所讀或所寫的語言來執(zhí)行操作成為了可能。
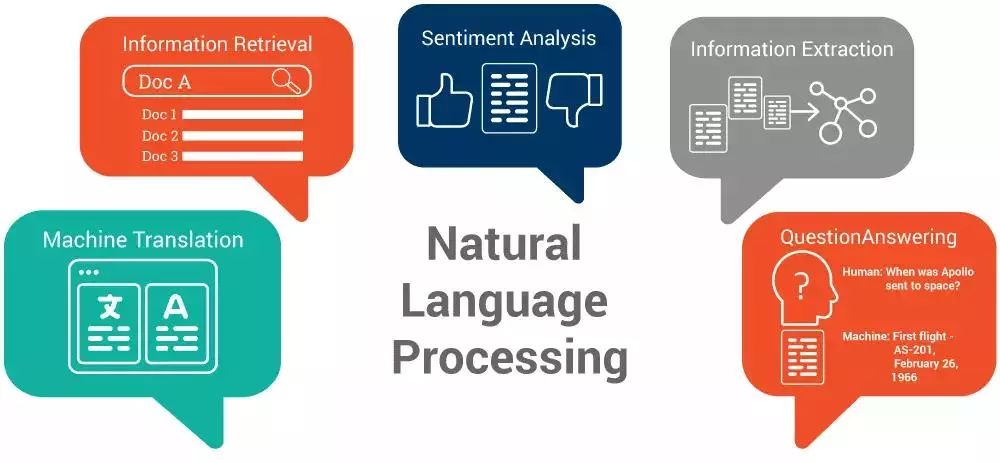
自然語言處理最重要的最有用的實例:
① 文本分類和排序這項任務(wù)的目標是對一個文本進行預測標簽(類別)或?qū)α斜碇邢嚓P(guān)聯(lián)的文本進行排序。它能夠用于過濾垃圾郵件(預測一封電子郵件是否是垃圾郵件),或進行文本內(nèi)容分類(從網(wǎng)絡(luò)上篩選出那些與你的競爭者相關(guān)的文章)。
② 情感分析句子分析是為了確定一個人對某個主題的看法或情感反應(yīng),如正面或負面情緒,生氣,諷刺等。它廣泛應(yīng)用于用戶滿意度調(diào)查(如對產(chǎn)品的評論進行分析)。
③ 文件摘要文件摘要是用一些方法來得到長文本(如文檔,研究論文)短且達意的描述。對自然語言處理方向感興趣嗎?
④ 命名實體識別命名實體識別算法是用于處理一系列雜亂的文本并識別目標(實體)預定義的類別,如人,公司名稱,日期,價格,標題等等。它能夠?qū)㈦s亂的文本信息轉(zhuǎn)換成規(guī)則的類表的格式,來實現(xiàn)文本的快速分析。
⑤ 語音識別語音識別技術(shù)是用于得到人所講的一段語音信號的文本表達。你可能聽說過Siri助手?這就是語音識別應(yīng)用的一個最好的例子。
⑥ 自然語言的理解和生成自然語言的理解是通過計算機,將人類生成的文本轉(zhuǎn)換成更正式的表達。反過來,自然語言生成技術(shù)是將一些正式又有邏輯性的表達轉(zhuǎn)換成類人的生成文本。如今,自然語言理解和生成主要用于聊天機器人和報告的自動生成。
從概念上來說,它與實體命名識別任務(wù)是相反的。
⑦ 機器翻譯機器翻譯是將一段文本或語音自動從一種語言翻譯成另一種語言的一項任務(wù)。
2 數(shù)據(jù)庫
數(shù)據(jù)庫是機器學習一個必要的組成部分。如果你想構(gòu)建一個機器學習系統(tǒng),你要么可以從公眾資源中得到數(shù)據(jù),要么需要自己收集數(shù)據(jù)。所有的用于構(gòu)建和測試機器學習模型的數(shù)據(jù)集合成為數(shù)據(jù)庫。基本上,數(shù)據(jù)科學家會將數(shù)據(jù)劃分為三個部分:
訓練數(shù)據(jù):訓練數(shù)據(jù)是用于訓練模型。這意味著機器學習模型需要認識并通過學習得到數(shù)據(jù)的模式以及確定預測過程中最重要的數(shù)據(jù)特征。
驗證數(shù)據(jù):驗證數(shù)據(jù)是用于微調(diào)模型參數(shù)和比較不同模型來確定最優(yōu)的模型。驗證數(shù)據(jù)應(yīng)該不同于訓練數(shù)據(jù),且不能用于訓練階段。否則,模型將出現(xiàn)過擬合現(xiàn)象,且對新的數(shù)據(jù)泛化不佳。
測試數(shù)據(jù):這看起來似乎有些單調(diào),但這通常是第三個也是最后的測試集(經(jīng)常也被稱為對抗數(shù)據(jù))。一旦最終的模型確定,它就用于測試模型在從未見過的數(shù)據(jù)集上的表現(xiàn),如這些數(shù)據(jù)從未在構(gòu)建模型或確定模型時使用過。
圖像:混合使用t-SNE和Jonker-Volgenant算法得到的MNIST數(shù)據(jù)庫的可視化結(jié)果。T-SNE是一種廣泛使用的降維算法,通過壓縮數(shù)據(jù)的表達來得到更好的可視化和進一步處理。
3 計算機視覺
計算機視覺是一個專注于分析并深層次理解圖像和視頻數(shù)據(jù)的人工智能領(lǐng)域。計算機視覺領(lǐng)域最常見的問題包括:
① 圖像分類圖像分類是教模型去識別給定的圖像的一種計算機視覺任務(wù)。例如,訓練一個模型去識別公共場景下的多個物體(這可以應(yīng)用于自動駕駛)。
② 目標檢測目標檢測是教模型從一系列預定義的類別中檢測出某一類別的實例,并用矩形框框注出來的一種計算機視覺任務(wù)。例如,利用目標檢測來構(gòu)建人臉識別系統(tǒng)。模型可以在圖片中檢測出每張臉并畫出對應(yīng)的矩形框(順便說下,圖像分類系統(tǒng)只能識別出一張圖片中是否有臉的存在,而不能檢測出臉的位置,而目標檢測系統(tǒng)就可以)。

③ 圖像分割圖像分割是訓練模型去標注類的每一個像素值,并能大致確定給定像素所屬的預定義類別的一種計算機視覺任務(wù)。

顯著性檢測
顯著性檢測是訓練模型產(chǎn)生最顯著區(qū)域的一種計算機視覺任務(wù)。這可以用于確定視頻中廣告牌的位置。
4 監(jiān)督學習
監(jiān)督學習是用實例來教模型學習的一類機器學習模型集合。這意味著用于監(jiān)督學習任務(wù)的數(shù)據(jù)需要被標注(指定正確的,真實類別)。例如,如果我們想要構(gòu)建一個機器學習模型用于識別一個給定的文本是否被標記過的,我們需要給模型提供一個標記過的樣本集 (文本+信息,是否該文本被標記過)。給定一個新的,未見過的例子,模型能夠預測它的目標,例如,規(guī)定樣本的標簽,1表示標記過的而0表示未標記的。
5 無監(jiān)督學習
相比于監(jiān)督學習,無監(jiān)督學習模型是通過觀察來進行自我學習。算法所用的數(shù)據(jù)是未標記過的(即提供給算法的是沒有真實標簽值的數(shù)據(jù))。無監(jiān)督學習模型能夠發(fā)現(xiàn)不同輸入之間的相關(guān)關(guān)系。最重要的無監(jiān)督學習技術(shù)是聚類方法。對于給定的數(shù)據(jù),模型能夠得到輸入的不同聚類(對于相似的數(shù)據(jù)聚合在同一類中),并能將新的、未見過的輸入歸入到相似的聚類中。

6 強化學習
強化學習區(qū)別于先前我們提到的那些方法。強化學習算法一種“游戲”的過程,其目標是最大化 “游戲獎勵”。該算法通過反復的實驗來嘗試確定不同的 “走法”,并查看哪種方式能夠最大化 “游戲收益”
最廣為人知的強化學習例子就是教計算機來解決魔方問題或下象棋,但是強化學習能解決的問題不僅只有游戲。最近,強化學習大量地應(yīng)用于實時競價,其模型負責為一個廣告競拍價格而它的報酬是用戶的轉(zhuǎn)換率。
想要學習人工智能在實時競價和程序化廣告中的應(yīng)用嗎?
神經(jīng)網(wǎng)絡(luò)是一個非常廣泛的機器學習模型集合。它的主要思想是模擬人類大腦的行為來處理數(shù)據(jù)。就像大腦中真實神經(jīng)元之間相互連接形成的網(wǎng)絡(luò)一樣,人工神經(jīng)網(wǎng)絡(luò)由多層組成。每層都是一系列神經(jīng)元的集合,這些神經(jīng)元負責檢測不同的食物。一個神經(jīng)網(wǎng)絡(luò)能夠連續(xù)地處理數(shù)據(jù),這意味著只有第一層才與輸入直接相連,隨著模型層數(shù)的增加,模型將學到越來越復雜的數(shù)據(jù)結(jié)構(gòu)。當層數(shù)大量地增加,模型通常就是一個所謂的深度學習模型。很難給一個深度網(wǎng)絡(luò)確定一個特定的網(wǎng)絡(luò)層數(shù),10年前通常3層神經(jīng)網(wǎng)絡(luò)就可謂深,而如今通常需要20層。
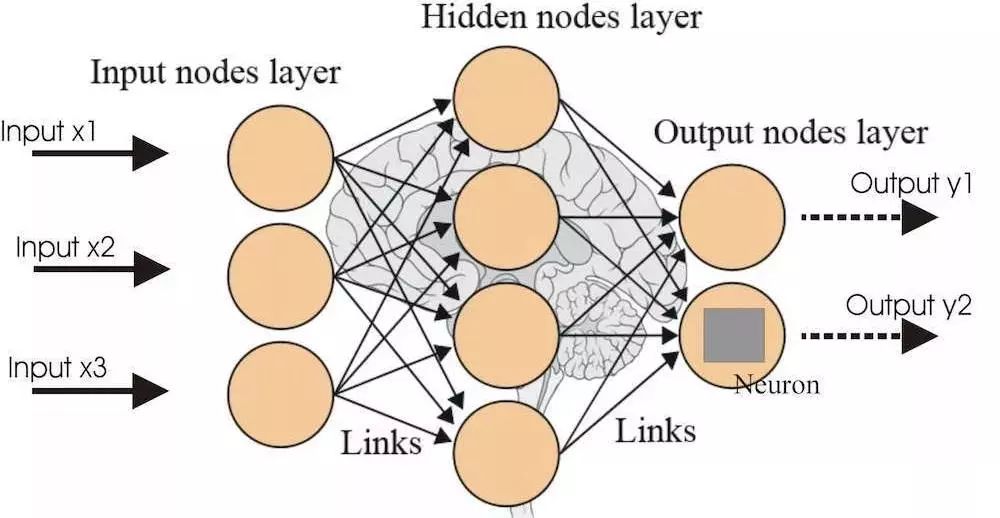
神經(jīng)網(wǎng)絡(luò)有許許多多不同的變體,最常用的是:
? 卷積神經(jīng)網(wǎng)絡(luò)—它給計算機視覺任務(wù)帶來了巨大的突破(而如今,它同樣對于解決自然語言處理問題有很大幫助)。
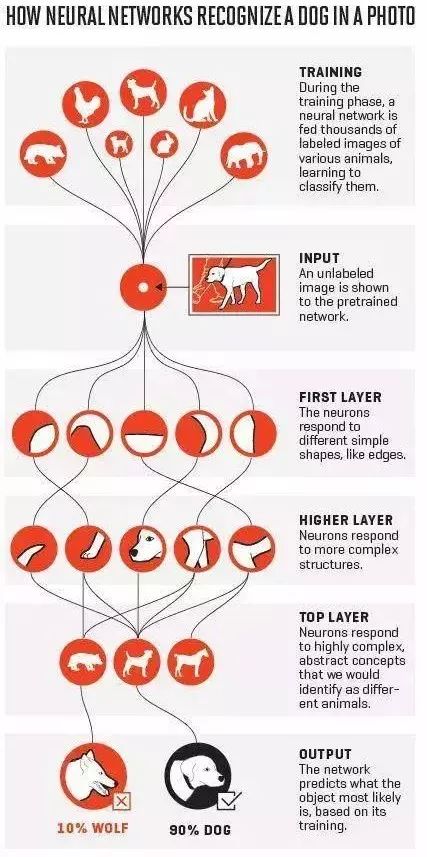
? 循環(huán)神經(jīng)網(wǎng)絡(luò)—被設(shè)計為處理具有序列特征的數(shù)據(jù),如文本或股票票價。這是個相對古老的神經(jīng)網(wǎng)絡(luò),但隨著過去20年現(xiàn)代計算機計算能力的突飛猛進,使得它的訓練變得容易并在很多時候得以應(yīng)用。
? 全連接神經(jīng)網(wǎng)絡(luò)—這是處理靜態(tài)/表格式數(shù)據(jù)最簡單的模型。
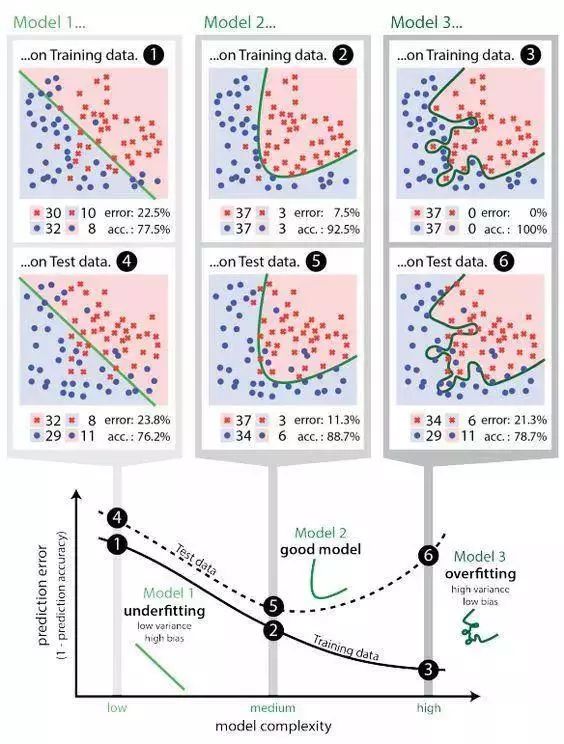
8 過擬合
當模型從不充分的數(shù)據(jù)中學習會產(chǎn)生偏差,這對模型會有負面的影響。這是個很常見,也很重要的問題。
當你在不同的時間進入一個面包坊,而每一次所剩下的蛋糕都沒有你喜歡的,那么你可能會對這個面包坊失望,即使有很多其他的顧客可能會對剩下的蛋糕滿意。如果你是個機器學習模型,可以說你對這一小數(shù)量樣本產(chǎn)生了過擬合現(xiàn)象—要構(gòu)建一個具有偏置量的模型,其得到的表示才不會過度擬合真實數(shù)據(jù)。
當過擬合現(xiàn)象發(fā)生,它通常意味著模型將隨機噪聲當作數(shù)據(jù),并作為一個重要的信號去擬合它,這就是為什么模型在新數(shù)據(jù)上的表現(xiàn)會出現(xiàn)退化(噪聲也有差異)。這在一些非常復雜的模型如神經(jīng)網(wǎng)絡(luò)或加速梯度模型上是很常見的。
想象構(gòu)建一個模型來檢測文章中出現(xiàn)的有關(guān)奧運的特定體育項目。由于所用的訓練集與文章是由偏差的,模型可能學習到諸如 “奧運”這樣詞的特征,而無法檢測到那些未包含該詞的文章。
-
AI
+關(guān)注
關(guān)注
88文章
34553瀏覽量
276074 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3905瀏覽量
65867 -
機器學習
+關(guān)注
關(guān)注
66文章
8496瀏覽量
134216 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13616
原文標題:先搞懂這八大基礎(chǔ)概念,再談機器學習入門!
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何輕松掌握機器學習概念和在工業(yè)自動化中的應(yīng)用
EMC工程師必須具備的八大技能
Java入門需要學習什么?
全球八大發(fā)動機結(jié)構(gòu)
Python機器學習入門之pandas的使用提示
什么是機器學習? 機器學習基礎(chǔ)入門
磷酸鐵鋰電池八大缺陷及八大優(yōu)勢分析

詳細putty串口使用教程與八大使用技巧分享






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論