") 揭示大模型剪枝技術(shù)的原理與發(fā)展
揭示大模型剪枝技術(shù)的原理與發(fā)展
當(dāng)你聽到「剪枝」二字,或許會聯(lián)想到園丁修整枝葉的情景。而在 AI 大模型領(lǐng)域,這個詞有著特殊的含義 —— 它是一種通過“精簡”來提升大模型效率的關(guān)鍵技術(shù)。隨著 GPT、LLaMA 等大模型規(guī)模的持續(xù)膨脹,如何在保持性能的同時降低資源消耗,已成為亟待解決的難題。本文將揭示大模型剪枝技術(shù)的原理與發(fā)展,帶你一次性讀懂剪枝。
隨著人工智能的快速發(fā)展,大模型以其卓越的性能在眾多領(lǐng)域中占據(jù)了重要地位。然而,大模型驚人的參數(shù)規(guī)模也帶來了一系列挑戰(zhàn),如高昂的訓(xùn)練成本、巨大的存儲需求和推理時的計算負擔(dān)。為了解決這些問題,大模型剪枝技術(shù)應(yīng)運而生,成為壓縮大模型的關(guān)鍵手段。本文將簡要介紹大模型剪枝技術(shù)的背景及原理、代表性方法和研究進展。
背景及原理
當(dāng)今大模型的“身軀”越來越龐大,對資源的需求也日益增加。如 LLaMA 3.1,且不說其訓(xùn)練算力高達 24000塊 H100,訓(xùn)練數(shù)據(jù)量高達 15T tokens(Qwen 2.5 在 18T tokens 的數(shù)據(jù)集上進行了預(yù)訓(xùn)練,成為目前訓(xùn)練數(shù)據(jù)最多的開源大模型),單看表 1 和表 2 中 LLaMA 3.1 在推理和微調(diào)時的內(nèi)存需求,對普通用戶而言就是難以承受之重。這些龐大的需求不僅對硬件資源提出了極高的要求,也限制了模型的可擴展性和實用性。大模型剪枝技術(shù)通過減少模型中的參數(shù)數(shù)量,旨在降低這些需求,同時盡量保持模型的性能。
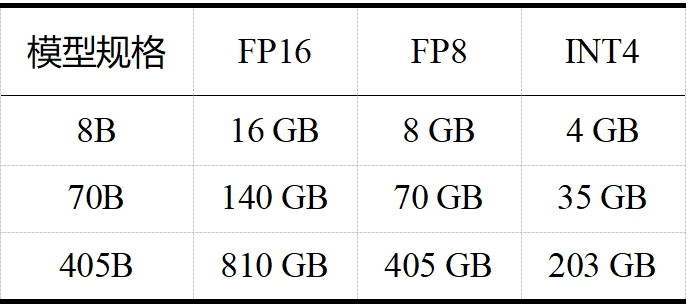
表 1 LLaMA 3.1 推理內(nèi)存需求(不包括 KV 緩存)
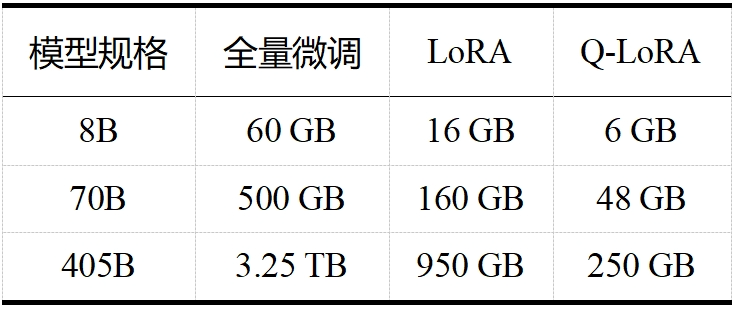
表 2 LLaMA 3.1 微調(diào)內(nèi)存需求
剪枝“流派”的開山鼻祖是圖靈獎得主、深度學(xué)習(xí)“三巨頭”之一 Yann LeCun,他在 1989 年 NeurIPS 會議上發(fā)表的《Optimal Brain Damage》[1]是第一篇剪枝工作。后來剪枝“流派”逐漸開枝散葉,如今可主要分為兩大類:非結(jié)構(gòu)化剪枝和結(jié)構(gòu)化剪枝。非結(jié)構(gòu)化剪枝通過移除單個權(quán)重或神經(jīng)元得到稀疏權(quán)重矩陣,這種方法易于實現(xiàn)且性能指標較高,但需要專門的硬件或軟件支持來加速模型;結(jié)構(gòu)化剪枝通過去除基于特定規(guī)則的連接來實現(xiàn),如層級剪枝、塊級剪枝等,這種方法不需要專門的軟硬件支持,但算法更為復(fù)雜。
兩類剪枝方法在大模型上都有很多的嘗試和應(yīng)用,但考慮到通用性,我們主要關(guān)注結(jié)構(gòu)化剪枝,本文的第二部分也將主要介紹 LLM 結(jié)構(gòu)化剪枝的經(jīng)典文章 LLM-Pruner。
下面談一談剪枝的理論基礎(chǔ)。首先,所謂的理論基礎(chǔ)只是暫時的,在一個高速發(fā)展的學(xué)科中,很難確保今天的理論不會被明天的實驗推翻。在傳統(tǒng)上,人們一直認為剪枝的基礎(chǔ)是 DNN 的過參數(shù)化,即深度神經(jīng)網(wǎng)絡(luò)參數(shù)比擬合訓(xùn)練數(shù)據(jù)所需參數(shù)更多,可以剪去一部分以降低網(wǎng)絡(luò)復(fù)雜度而盡量不影響其性能。 在 2019 年,有學(xué)者提出了彩票假設(shè)(ICLR 2019 best paper)[2]:一個隨機初始化的神經(jīng)網(wǎng)絡(luò)里包括一個子網(wǎng)絡(luò),當(dāng)該子網(wǎng)絡(luò)被單獨訓(xùn)練時,能在最多相同迭代次數(shù)后達到原始網(wǎng)絡(luò)訓(xùn)練后的性能——就好比一堆彩票中存在一個中獎子集,只要買了這個子集就能獲得最大收益。 隨后,又有學(xué)者在《What’sHiddenin a Randomly Weighted Neural Network?》中提出了“近似加強版”彩票假設(shè)(CVPR 2020)[3]:在一個隨機權(quán)重的足夠過參數(shù)化的神經(jīng)網(wǎng)絡(luò)中,存在一個子網(wǎng)絡(luò),無需訓(xùn)練,其性能與相同參數(shù)量訓(xùn)練過的網(wǎng)絡(luò)相當(dāng)。 再隨后,又有學(xué)者聲稱自己證明了這個“近似加強版”的彩票假設(shè),并在標題里宣稱 Pruning is all you need(ICML 2020)[4]。也就是說,如圖 1 所示,以后不需要訓(xùn)練了,我們只用找一個足夠大的網(wǎng)絡(luò),剪啊剪啊就能得到一個性能很好的子網(wǎng)絡(luò)。這個說法如果成立當(dāng)然是極好的,因為基于梯度的優(yōu)化算法訓(xùn)練時間長,且是次優(yōu)的,但問題在于缺乏有效的純剪枝算法,所以目前剪枝的基本流程還是:訓(xùn)練、剪枝、微調(diào)。另外,作者是用二值小網(wǎng)絡(luò)+推廣證明的,太過理想化,而且沒有考慮非線性的情況。近年來,雖然彩票假設(shè)及其衍生理論在一些研究領(lǐng)域取得了進展,例如圖中獎彩票(KDD 2023)[5]和對偶彩票假設(shè)(ICLR 2022)[6],但在大模型領(lǐng)域,我們尚未觀察到具有顯著影響力的研究工作。

圖 1 LLaMA 3.1 微調(diào)內(nèi)存需求
代表性方法:LLM-Pruner
本節(jié)將以首個針對大模型的結(jié)構(gòu)化剪枝框架——LLM-Pruner(NeurIPS 2023)[7]為例,介紹大模型剪枝的基本流程。該框架特點為任務(wù)無關(guān)的壓縮、數(shù)據(jù)需求量少、快速和全自動操作,主要包括以下三個步驟:(1)分組階段
本階段的主要工作是根據(jù)依賴性準則,將 LLM 中互相依賴的神經(jīng)元劃分為一組。依賴性準則為:若 i 是 j 的唯一前驅(qū),則 j 依賴于 i;若 j 是 i 的唯一后繼,則 i 依賴于 j。在具體操作中,需要分別將網(wǎng)絡(luò)中每個神經(jīng)元作為初始節(jié)點,依賴關(guān)系沿方向傳導(dǎo),傳導(dǎo)過程中遍歷的神經(jīng)元為一組,一組需同時剪枝。以圖 2 中 Group Type B(即 MHA,多頭注意力)為例,從 Head 1 開始傳導(dǎo),Head 1 是上面兩個虛線圈神經(jīng)元的唯一前驅(qū),是下面六個虛線圈神經(jīng)元的唯一后繼,它們都依賴于 Head 1,故被劃分為一組。
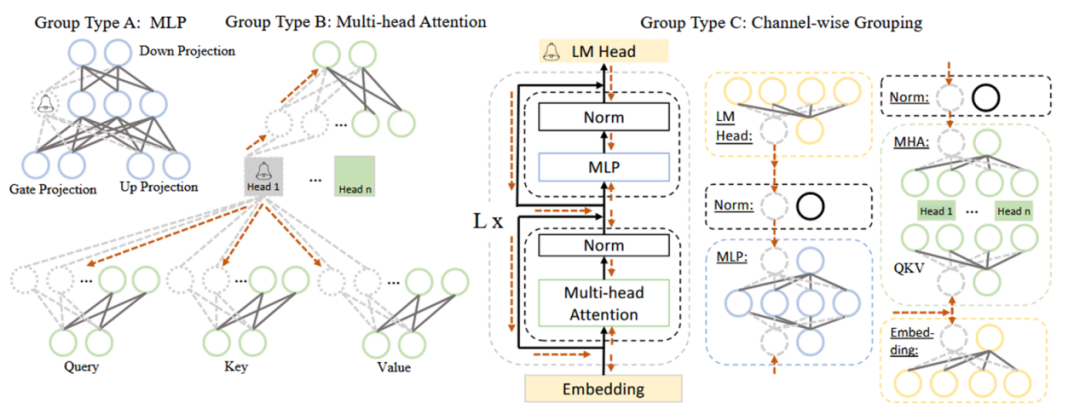
圖 2 LLaMA 中耦合結(jié)構(gòu)的簡化示例 (2)評估階段
本階段的主要工作是根據(jù)重要性準則評估每個組對模型整體性能的貢獻,貢獻小的組將被修剪。常見的重要性準則有:L1 范數(shù)(向量中各元素絕對值之和)、L2 范數(shù)(向量中各元素平方和的開平方)、損失函數(shù)的 Taylor 展開一階項、損失函數(shù)的 Taylor 展開二階項等。LLM-Pruner 采用損失函數(shù)的 Taylor 展開來計算重要性,并提出了兩條計算組重要性的路徑:權(quán)重向量級別和單個參數(shù)級別。
權(quán)重向量級別的重要性公式如下所示, 代表每個神經(jīng)元的權(quán)重向量,H 是 Hessian 矩陣, 表示 next-token prediction loss。一般來說由于模型在訓(xùn)練數(shù)據(jù)集上已經(jīng)收斂,即 , 所以一階項通常為 0 。然而,由于 LLM-Pruner 所用數(shù)據(jù)集 D 并不是原始訓(xùn)練數(shù)據(jù),故 。同時,由于 Hessian 矩陣的計算復(fù)雜度過高, 所以只計算了一階項。
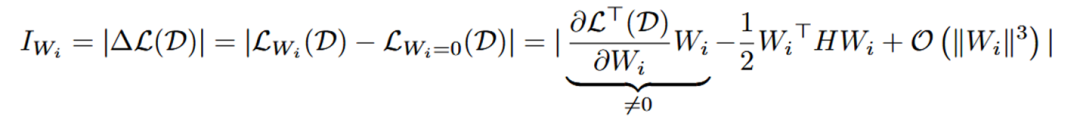
單個參數(shù)級別的重要性公式如下所示, 內(nèi)的每個參數(shù)都被獨立地評估其重要性,其中 Hessian 矩陣用 Fisher 信息矩陣進行了近似。在 LLM-Pruner 的源碼中,這兩個公式被如圖 3 所示的代碼片段表示。
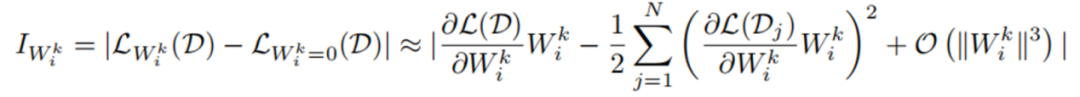
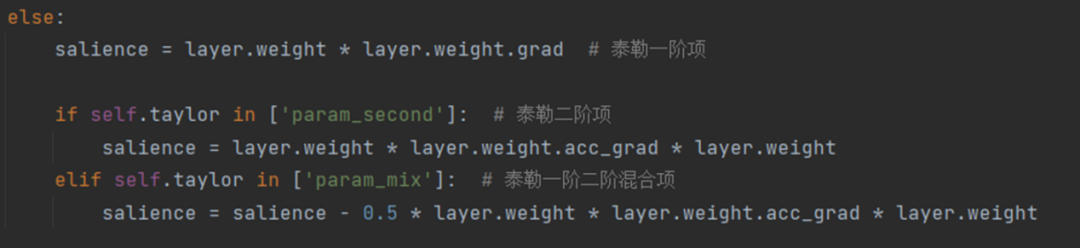
圖 3 評估重要性的源碼
最后,通過對每組內(nèi)權(quán)重向量或參數(shù)的重要性進行累加/累乘/取最大值/取最后一層值,就得到了每組的重要性,再按剪枝率剪去重要性低的組即可。
(3)微調(diào)階段
本階段的主要工作是使用LoRA微調(diào)模型中每個可學(xué)習(xí)的參數(shù)矩陣W,以減輕剪枝帶來的性能損失。LoRA的公式為W+?W=W+BA,其具體步驟如圖4所示:
① 在模型的特定層中用 Wd×k+ΔWd×k 替換原有的權(quán)重矩陣 Wd×k,并把矩陣 ?Wd×k 分解成降維矩陣 Ad×r 和升維矩陣 Br×k,r << min(d, k)。
② 將 A 隨機高斯初始化,B 置為 0,凍結(jié)預(yù)訓(xùn)練模型的參數(shù) W,只訓(xùn)練矩陣 A 和矩陣 B。
③ 訓(xùn)練完成后,將 B 矩陣與 A 矩陣相乘再與矩陣 W 相加,作為微調(diào)后的模型參數(shù)。
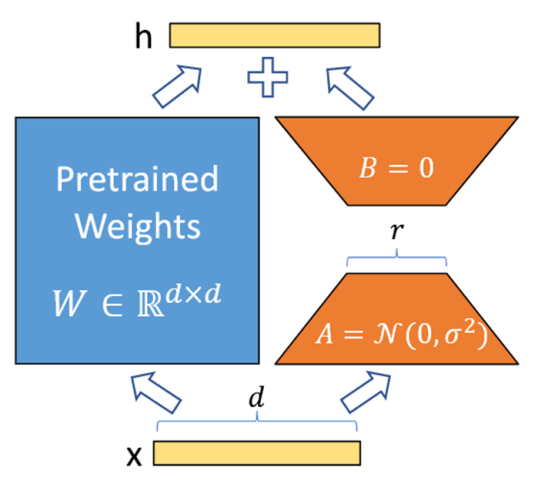
圖 4LoRA基本步驟
根據(jù)表 3 的實驗結(jié)果,剪枝 20% 后,模型的性能為原模型的 89.8%,經(jīng)過 LoRA 微調(diào)后,性能可提升至原模型的 94.97%。在大多數(shù)數(shù)據(jù)集上,剪枝后的 5.4B LLaMA 甚至優(yōu)于 ChatGLM-6B,所以如果需要一個具有定制尺寸的更小的模型,理論上用 LLM-Pruner 剪枝一個比再訓(xùn)練一個成本更低效果更好。
然而,根據(jù)表 4 的數(shù)據(jù)顯示,剪枝 50% 后模型表現(xiàn)并不理想,LoRA 微調(diào)后綜合指標也僅為原模型 77.44%,性能下降幅度較大。如何進行高剪枝率的大模型結(jié)構(gòu)化剪枝,仍是一個具有挑戰(zhàn)性的問題。
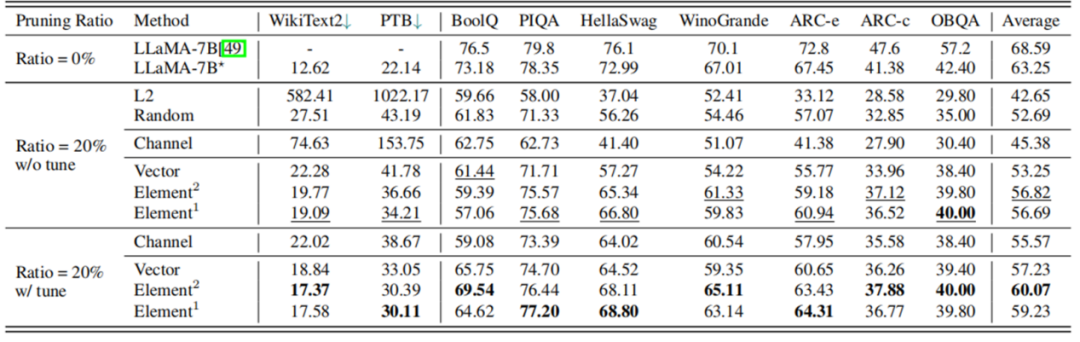
表 3LLaMA-7B 剪枝 20% 前后性能對比
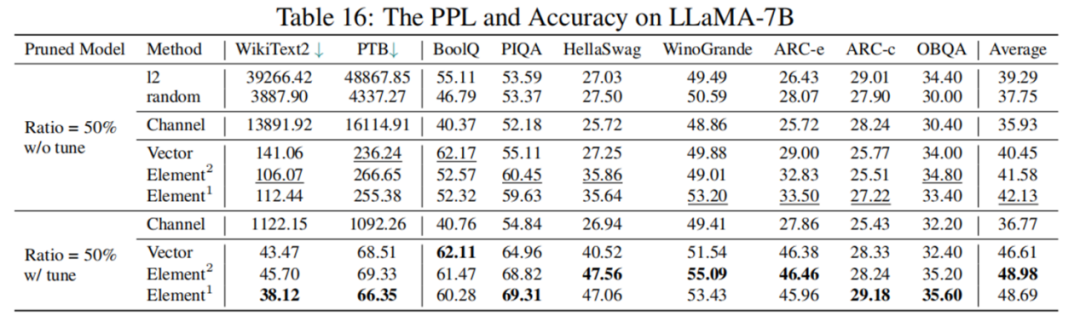
表 4LLaMA-7B 剪枝 50% 前后性能對比
研究進展
大模型剪枝技術(shù)已經(jīng)成為近兩年的研究熱點,無論是在工業(yè)界還是學(xué)術(shù)界,都有許多研究人員投身于這一領(lǐng)域——這一點從表 5 和表 6 中可以明顯看出,而表格中列出的論文只是眾多大模型剪枝研究工作中的一小部分。除此之外,還有學(xué)者提出了介于結(jié)構(gòu)化剪枝和非結(jié)構(gòu)化剪枝之間的半結(jié)構(gòu)化剪枝,如 Nvidia 的 N:M 稀疏化,就是每 M 個連續(xù)元素留下 N 個非零元素,但與前兩者相比目前相關(guān)探索較少。隨著研究的不斷深入和技術(shù)的持續(xù)進步,我們有理由相信,剪枝將繼續(xù)在大模型領(lǐng)域扮演重要的角色,并推動大模型技術(shù)的創(chuàng)新和發(fā)展。
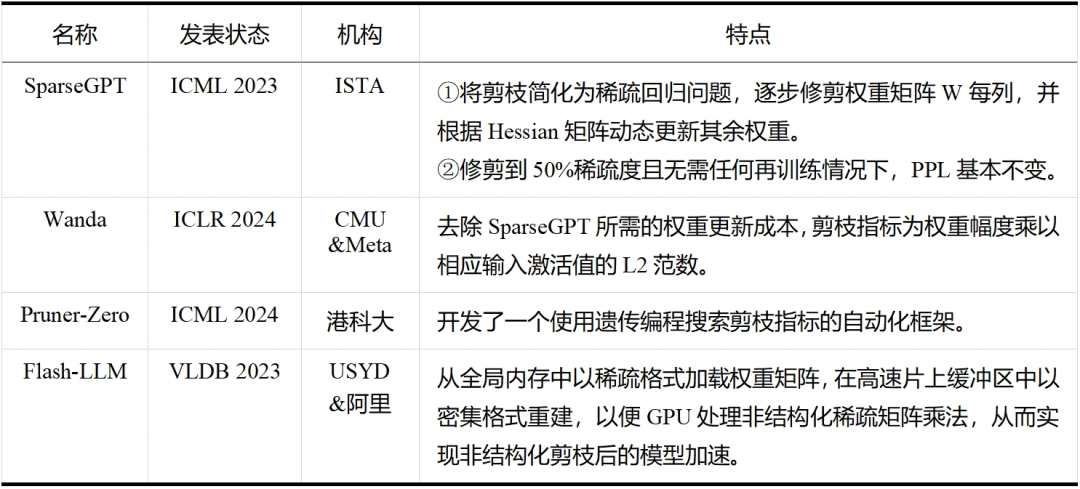
表5大模型非結(jié)構(gòu)化剪枝
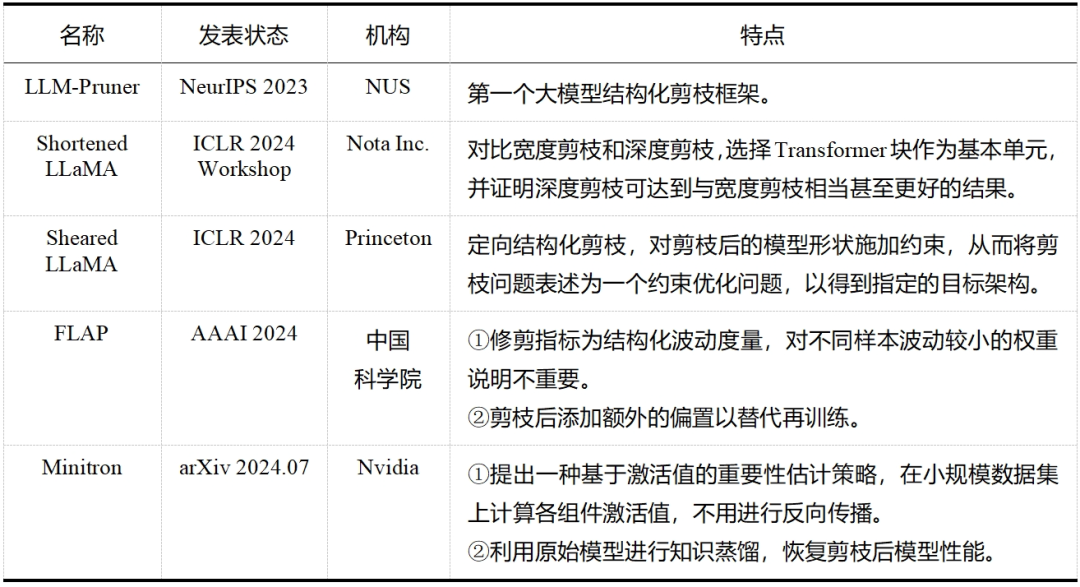
表6大模型結(jié)構(gòu)化剪枝
-
人工智能
+關(guān)注
關(guān)注
1800文章
48094瀏覽量
242229 -
大模型
+關(guān)注
關(guān)注
2文章
2793瀏覽量
3437
原文標題:一文讀懂剪枝(Pruner):大模型也需要“減減肥”?
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
研華邊緣AI平臺測試DeepSeek蒸餾版模型的最新數(shù)據(jù)

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
【「大模型啟示錄」閱讀體驗】對大模型更深入的認知
AI模型部署邊緣設(shè)備的奇妙之旅:如何實現(xiàn)手寫數(shù)字識別
車載大模型分析揭示:存儲帶寬對性能影響遠超算力
未來AI大模型的發(fā)展趨勢
AI大模型的性能優(yōu)化方法
AI大模型的發(fā)展歷程和應(yīng)用前景
大模型技術(shù)及趨勢總結(jié)
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實踐】核心技術(shù)綜述
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
張宏江深度解析:大模型技術(shù)發(fā)展的八大觀察點






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論