 如何使用FP8新技術加速大模型訓練
如何使用FP8新技術加速大模型訓練

利用 FP8 技術加速 LLM 推理和訓練越來越受到關注,本文主要和大家介紹如何使用 FP8 這項新技術加速大模型的訓練。
使用 FP8 進行大模型訓練的優勢

FP8 是一種 8 位浮點數表示法,FP8 的詳細介紹可以參考此鏈接:
https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html#Introduction-to-FP8
其中,使用 FP8 進行大模型訓練具有以下優勢:
新一代 GPU 如NVIDIA Ada Lovelace、Hopper架構配備了最新一代的 Tensor Core,可以支持 FP8 數據精度的矩陣運算加速。相比之前的 FP16 或 BF16 的數據類型,FP8 的 Tensor Core 可提供兩倍的 TFlops 算力。
除了計算上的性能加速之外,FP8 本身的數據類型占用的比特數比 16 比特或 32 比特更少,針對一些內存占用比較大的 Operation,可以降低內存占用消耗。
FP8 數據類型不僅適用于模型的訓練,同樣也可用于推理加速,相對于以前常見的 INT8 的推理方法,使用 FP8 進行模型的訓練和推理,可以保持訓練和推理階段模型性能及數據算法的一致,帶來了更好的精度保持,避免了使用 INT8 進行額外的精度校正。

當然,FP8 對比 FP16 或者 FP32 在數值表示范圍上引入了新的挑戰,從上面的表格中可以看到,FP8 數據類型所能表示的數值范圍較小,精度較低。因此需要針對 FP8 引入更細粒度的算法改進,如針對每個 Tensor 進行 Scaling 的方法。對于 FP8 訓練中的挑戰,NVIDIA 提出了一種 Delayed Scaling 的方法針對 FP8 Tensor 在訓練過程中引入動態 Scaling,使得在 FP8 訓練過程中在加速矩陣運算的同時借助 per-Tensor scaling 的方法保持精度。

上述方法目前已被 NVIDIA 技術團隊實現,并集成到了Transformer Engine軟件包中。Transformer Engine 是 NVIDIA 提供的開源的訓練工具包,專門針對 FP8 大模型訓練實現了一系列功能,包含針對大模型所常見模型結構如 Transformer 層等,同時針對 FP8 提供了 Delayed Scaling 這一方法的實現。
目前,Transformer Engine 已支持 PyTorch、JAX、Paddle 等主流框架,并與其它框架相兼容,且為了支持大模型訓練,還實現了對模型及 Sequence Level 并行的方法。
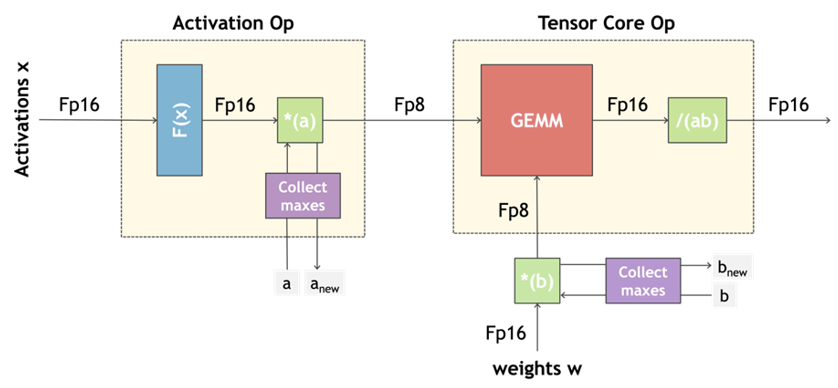
使用 Transformer Engine 十分簡單方便,只需調用 Layer 層或 Transformer 層,并將 FP8 的 Delayed Scaling Recipe 包含在模型的定義的 context 中。剩下的訓練過程中,所有 Tensor 的 Scaling 以及額外的輔助操作都可由 Transformer Engine 進行處理,無需額外操作 (參考上圖右側的示例)。

當前 Transformer Engine 已與NVIDIA NeMo、Megatron-LM以及HuggingFace 等業界開源社區訓練框架融合,便于在大模型的訓練中根據自己的需求方便調用 FP8 訓練能力。比如:
在 NeMo 中想要打開 FP8 訓練,只需要在配置文件中將 transformer_engine 和 FP8 分別設為 True,就可以方便的增加 FP8 的支持
在 Megatron-LM 中,只需要將 config 文件中的 FP8 設置為 hybrid,就可以用 FP8 進行大模型加速訓練的過程。
FP8 旨在提升模型訓練速度,目前已在 Hopper GPU 上對 Llama 系列模型進行 FP8 訓練性能測評,結果顯示在 7B、13B 到 70B 等不同大小的模型下,使用 FP8 進行訓練吞吐對比 BF16 其性能可提升 30% 至 50%。
FP8 在大模型訓練中的特點,可簡單總結為以下幾點:
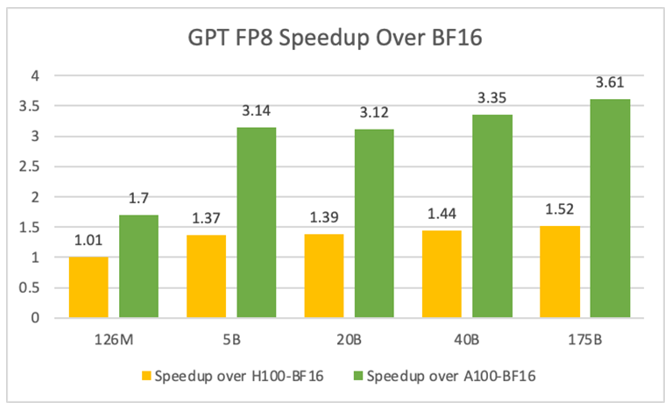
與之前的一些更高精度的方法相比,比如 FP32、TF32、FP16、BF16 等格式,FP8 具有更高的 Flops 數值。理論估計 FP8 相比 FP32 有四倍的算力提升,比 BF16 有兩倍的提升。在下面的表格中可以看到,在實際端到端訓練任務的過程中,在不同的模型規模下,訓練速度可以獲得約 1.37 倍到 1.52 倍的加速。
與更高精度的表示方法相比,FP8 有 E5M2 和 E4M3 兩種表示方式 (其中 E 為指數位,M 為尾數位)。E5M2 的指數位更多,意味著其數值表示范圍更大,梯度通常數值跨度更大,因此 E5M2 更適合用在 backward 當中。而 E4M3 是一種精度更高但動態范圍較小的表達方式,因此它更適合在 forward 過程中處理 weights 和 activations。這種混合形式,可以在大模型的訓練過程中根據情況靈活的運用這兩種方式。對比以前進行的混合精度或低精度訓練,TF32 可以無縫替換 FP32,但到了 BF16 的 AMP 階段,我們不僅需要處理計算的低精度,還需對整個 Loss 和梯度進行 scaling。在 FP16 AMP 中,我們會針對整個網絡維護一個 loss scale factor,而精度降至 8 比特時,就需要更精細地制定一套 recipe 來維護 FP8 的精度表現,即在 FP8 訓練過程中,我們需要進行 per-tensor scaling。但是在進行 per-tensor 時,會引入數值不穩定的問題,因此我們需要謹慎處理。
NVIDIA Transformer Engine 為用戶提供了相應的 recipe,通過簡單傳入參數,即可方便地利用 FP8 的高算力,同時保持模型收斂性的表現。需要注意的是,并不是訓練中的每個算子都要使用到 FP8,其主要應用于線性層中的前向與后向矩陣乘運算中。而對于某些精度敏感的層,我們仍會使用高精度計算,比如梯度更新、softmax 激活等。Transformer Engine 集成了很多 FP8 所需的可以保證精度的 recipe,并且 Transformer Engine 還集成到如 PyTorch、TensorFlow、Jax、Paddlepaddle 等更上層的訓練框架,同時一些針對 LLM 訓練的框架,如 Megatron-LM、NeMo Framework、DeepSpeed 等,也都集成了 FP8 能力。

我們也針對大模型訓練的不同場景,對 FP8 的收斂性進行了測試和驗證。
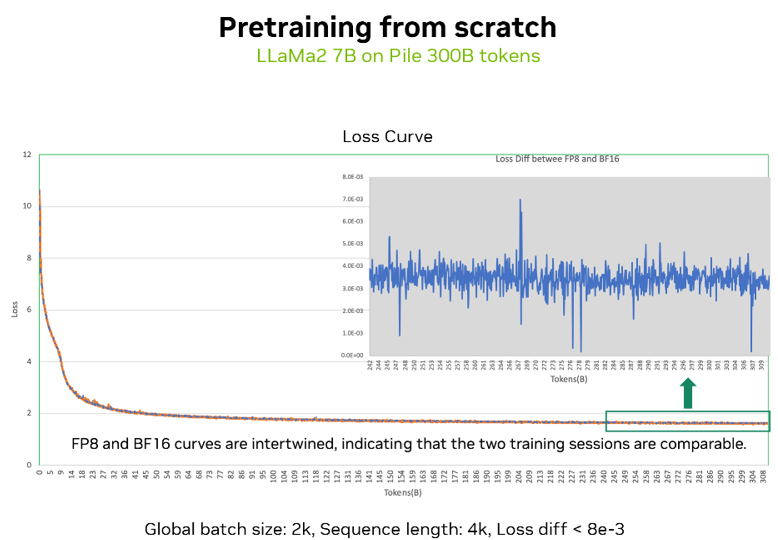
上圖展示了一個從零開始預訓練的損失曲線驗證,使用 Llama2 7B 模型,在 Pile 的 300 billion tokens 預訓練數據集上,分別進行了 FP8 和 BF16 兩種精度下的模型訓練,可以看到兩種精度的損失曲線吻合度極高,數值差異不到 1%。
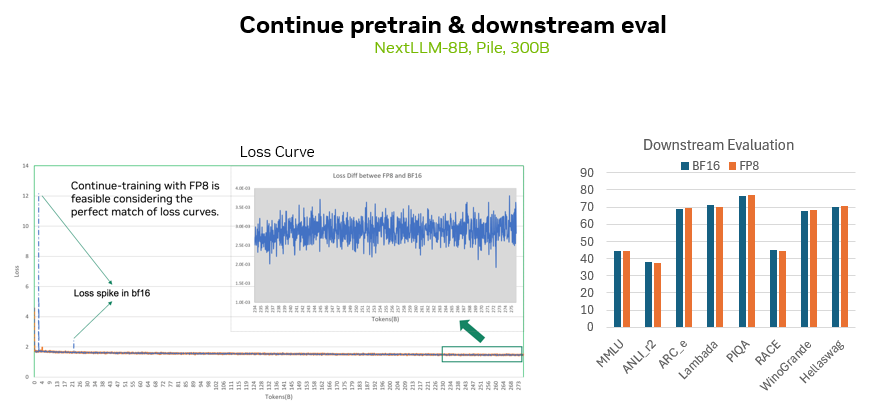
此外,我們還使用 NVIDIA 開發的一個 8B 模型進行了繼續預訓練測試,數據集同樣為 300 billion tokens,也可以看到 FP8 精度下和 BF16 的損失曲線差距也是很小的。同時在包括 MMLU 等多個下游任務上,也可以看到兩種精度所訓練的模型的下游精度也是比較吻合的。
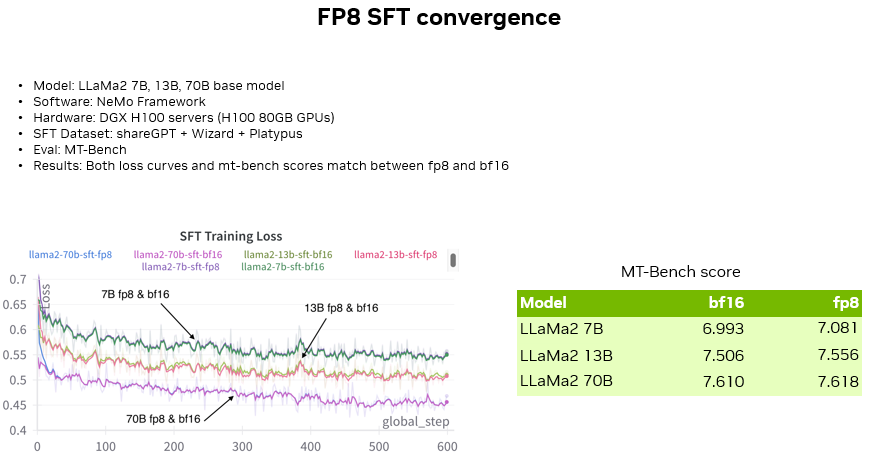
除了預訓練階段,我們也對 SFT 階段的 FP8 訓練精度進行了驗證,包括對 Llama2 7B、13B、70B 模型分別進行了 SFT (使用 NeMo 框架,數據集為開源社區中三個流行的英文數據集,MT-Bench 作為 SFT 精度驗證)。
可以看到對比了三種不同大小模型在兩種精度下的 SFT Loss 曲線,可以看到 Loss 曲線吻合度非常高,并隨著模型大小的增大,損失曲線明顯下降。
除了 Loss 曲線,也可以看到在 MT-Bench 測評集上三個模型在兩種精度下的 Score 也非常接近。
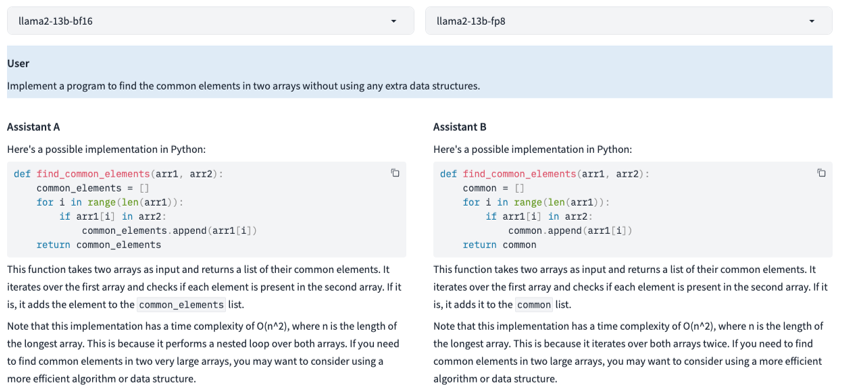
上圖是一個 SFT 模型生成效果的對比示例,可以看到在使用 13B 模型時,Prompt 為一個簡單編程任務的情況下,可以看到 FP8 和 BF16 生成的內容也是非常接近和類似。
FP8 訓練案例分享
零一萬物的雙語 LLM 模型:
FP8 端到端訓練與推理的卓越表現
零一萬物是一家專注于大語言模型的獨角獸公司,他們一直致力于在 LLM 模型,及其基礎設施和應用的創新。其可支持 200K 文本長度的開源雙語模型,在 HuggingFace 預訓練榜單上,與同等規模的模型中對比表現出色[1]。在零一萬物發布的千億模型 AI Infra 技術上,他們成功地在 NVIDIA GPU 上進行了端到端 FP8 訓練和推理,并完成了全鏈路的技術驗證,取得了令人矚目的成果。
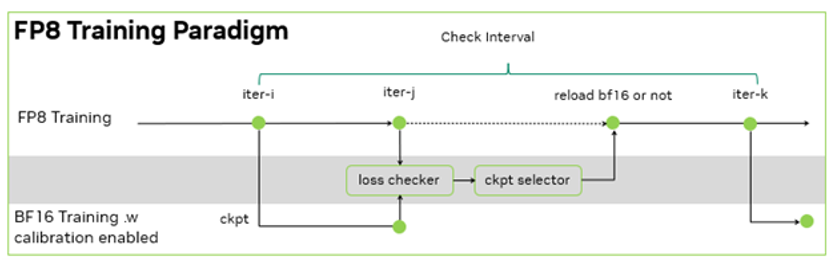
零一萬物的訓練框架是基于 NVIDIA Megatron-LM 開發的 Y 訓練框架, 其 FP8 訓練基于 NVIDIA Transformer Engine。在此基礎上,零一萬物團隊進一步的設計了訓練容錯方案:由于沒有 BF16 的 baseline 來檢查千億模型 FP8 訓練的 loss 下降是否正常,于是,每間隔一定的步數,同時使用 FP8 和 BF16 進行訓練,并根據 BF16 和 FP8 訓練的 loss diff 和評測指標的差異,決定是否用 BF16 訓練修正 FP8 訓練。
由于 FP8 訓練的過程中需要統計一定歷史窗口的量化信息,用于 BF16 到 FP8 的數據裁切轉換,因此在 BF16 訓練過程中,也需要在 Transformer Engine 框架內支持相同的統計量化信息的邏輯,保證 BF16 訓練可以無縫切換到 FP8 訓練,且不引入訓練的效果波動。在這個過程中,零一萬物基于 NVIDIA 軟硬結合的技術棧,在功能開發、調試和性能層面,與 NVIDIA 團隊合作優化,完成了在大模型的 FP8 訓練和驗證。其大模型的訓練吞吐相對 BF16 得到了 1.3 倍的性能提升。
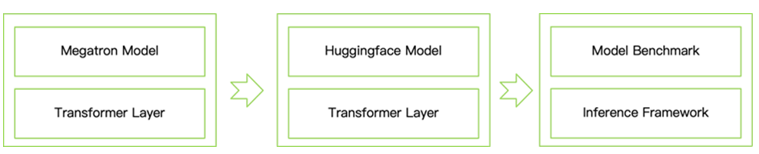
在推理方面,零一萬物基于NVIDIA TensorRT-LLM開發了 T 推理框架。這個框架提供了從 Megatron 到 HuggingFace 模型的轉化,并且集成了 Transformer Engine 等功能,能夠支持 FP8 推理,大大減小了模型運行時需要的顯存空間,提高了推理速度,從而方便社區的開發者來體驗和開發。具體過程為:
將 Transformer Engine 層集成到 Hugging Face 模型定義中。
開發一個模型轉換器,將 Megatron 模型權重轉換為 HuggingFace 模型。
加載帶有校準額外數據的 HuggingFace 模型,并使用 FP8 精度進行基準測試。取代 BF16 張量以節省顯存占用,并在大批量推理中獲得 2 至 5 倍的吞吐提升。
Inflection AI 的 FP8 訓練
Inflection AI 是一家專注于 AI 技術創新的公司,他們的使命是創造人人可用的 AI,所以他們深知大模型的訓練對于 AI 生成內容的精準性和可控性至關重要。因此,在他們推出的 Inflection-2 模型中,采用了 FP8 技術對其模型進行訓練優化。
與同屬訓練計算類別的 Google 旗艦模型 PaLM 2 相比,在包括知名的 MMLU、TriviaQA、HellaSwag 以及 GSM8k 等多項標準人工智能性能基準測試中,Inflection-2 展現出了卓越的性能,成功超越了 PaLM 2,彰顯了其在模型訓練方面的領先性,同時也印證了 FP8 混合精度訓練策略能夠保證模型正常收斂并取得良好的性能[2]。
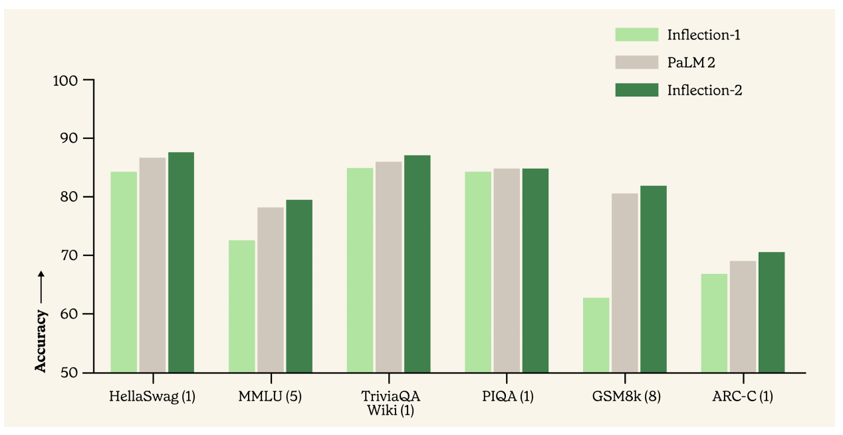
此圖片由Inflection AI 制作,
如果您有任何疑問或需要使用此圖片,
結語
FP8 技術在推動 AI 模型的高效訓練和快速推理方面有巨大的潛力,NVIDIA 的技術團隊也在和我們的客戶一起不斷探索完善應用 FP8 訓練和推理方法,未來我們也會持續為大家進行介紹以及最佳實踐分享。
-
大模型
+關注
關注
2文章
3146瀏覽量
4076 -
LLM
+關注
關注
1文章
325瀏覽量
845
原文標題:如何使用 FP8 加速大模型訓練
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
計算精度對比:FP64、FP32、FP16、TF32、BF16、int8

【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
摩爾線程發布Torch-MUSA v2.0.0版本 支持原生FP8和PyTorch 2.5.0
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
摩爾線程GPU原生FP8計算助力AI訓練


【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
采用FP8混合精度,DeepSeek V3訓練成本僅557.6萬美元!

FP8數據格式在大型模型訓練中的應用

PyTorch GPU 加速訓練模型方法
FP8模型訓練中Debug優化思路





 工商網監
工商網監
評論