 構建云原生機器學習平臺流程
構建云原生機器學習平臺流程

結合機器學習和云原生技術兩者的優勢,云原生機器學習平臺為機器學習提供了高效、靈活的運行環境。下面,AI部落小編為您分享構建云原生機器學習平臺的流程。
1.數據收集與處理
數據收集是機器學習的起步,涉及從各種來源獲取數據。收集到的數據通常需要進行預處理,包括數據清洗、標準化和歸一化等,以確保數據的質量和一致性。
在云原生環境中,數據收集和處理可以通過分布式計算框架來實現。這些框架能夠處理大規模數據,并支持多種數據存儲格式。
2.特征提取
特征提取是從原始數據中提取有意義的特征,以便于模型學習。特征提取可以通過手動方式或自動化方式實現。在云原生環境中,可以利用容器化技術來封裝特征提取的算法和工具,實現快速部署和擴展。
3.模型訓練
模型訓練是機器學習的核心步驟,涉及選擇合適的算法和訓練數據集,并使用這些數據來訓練模型。在云原生環境中,模型訓練可以利用容器編排技術來實現資源的動態分配和管理。此外,還可以使用分布式訓練框架來加速訓練過程。
云原生機器學習平臺通常提供可視化的訓練界面和豐富的算法庫,方便用戶進行模型開發和調試。
4.模型評估
模型評估是使用測試數據集來評估模型的性能,并進行調整和優化。在云原生環境中,可以利用容器化技術和自動化測試工具來實現模型評估的自動化和持續集成。
云原生機器學習平臺通常提供豐富的評估指標和可視化工具,方便用戶對模型的性能進行監控和分析。
5.模型部署
模型部署是將訓練好的模型部署到生產環境中,用于預測和決策。在云原生環境中,模型部署可以利用微服務架構和容器編排技術來實現服務的快速部署和擴展。
云原生機器學習平臺通常提供自助式的彈性算法服務,支持一鍵部署多種模型格式。這些服務具備低延時、高吞吐的特點,并支持分組發布、藍綠發布以及根據流量動態擴縮容等必備功能。
6.平臺監控與維護
云原生機器學習平臺的監控與維護是確保平臺穩定運行的關鍵。平臺需要提供全面的監控工具,包括日志監控、資源監控和性能監控等。
此外,平臺還需要提供自動化的維護功能,如自動化備份、自動化升級和自動化故障恢復等。
總之,構建云原生機器學習平臺是一個復雜而系統的過程,涉及數據收集、處理、特征提取、模型訓練、評估、部署和監控等多個環節。
AI部落小編溫馨提示:以上就是小編為您整理的《構建云原生機器學習平臺流程》相關內容,更多關于云原生機器學習的專業科普及petacloud.ai優惠活動可關注我們。
-
機器學習
+關注
關注
66文章
8499瀏覽量
134333 -
云原生
+關注
關注
0文章
259瀏覽量
8240
發布評論請先 登錄
云原生環境里Nginx的故障排查思路

云原生AI服務怎么樣
云原生LLMOps平臺作用
艾體寶與Kubernetes原生數據平臺AppsCode達成合作
梯度科技入選2024云原生企業TOP50榜單
軟通動力榮登2024云原生企業TOP50榜單
k8s微服務架構就是云原生嗎?兩者是什么關系
Arm推出GitHub平臺AI工具,簡化開發者AI應用開發部署流程
云原生和非云原生哪個好?六大區別詳細對比
京東云原生安全產品重磅發布
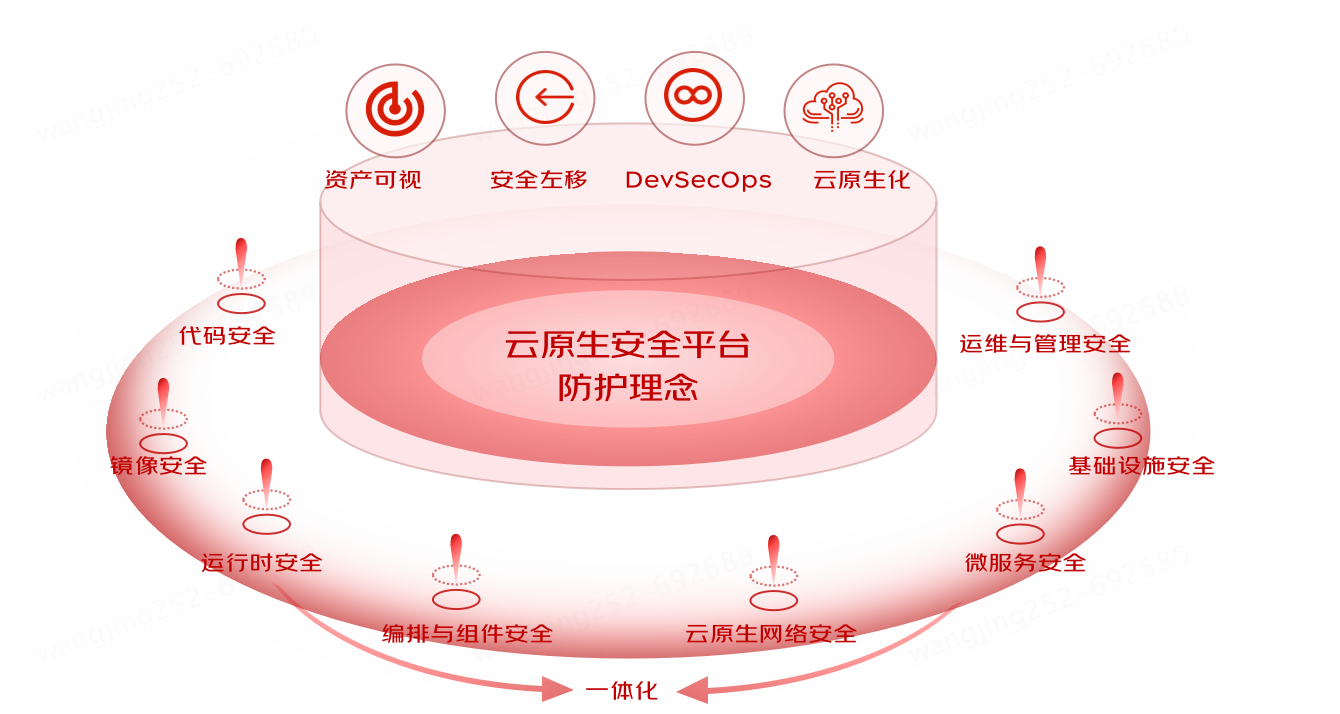
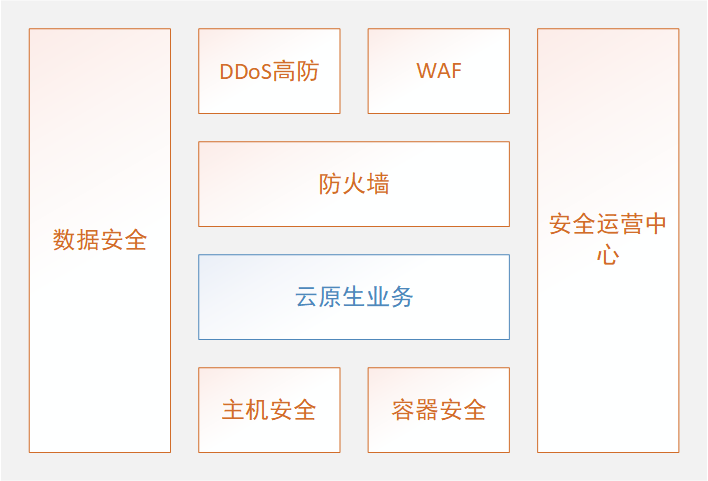
從積木式到裝配式云原生安全
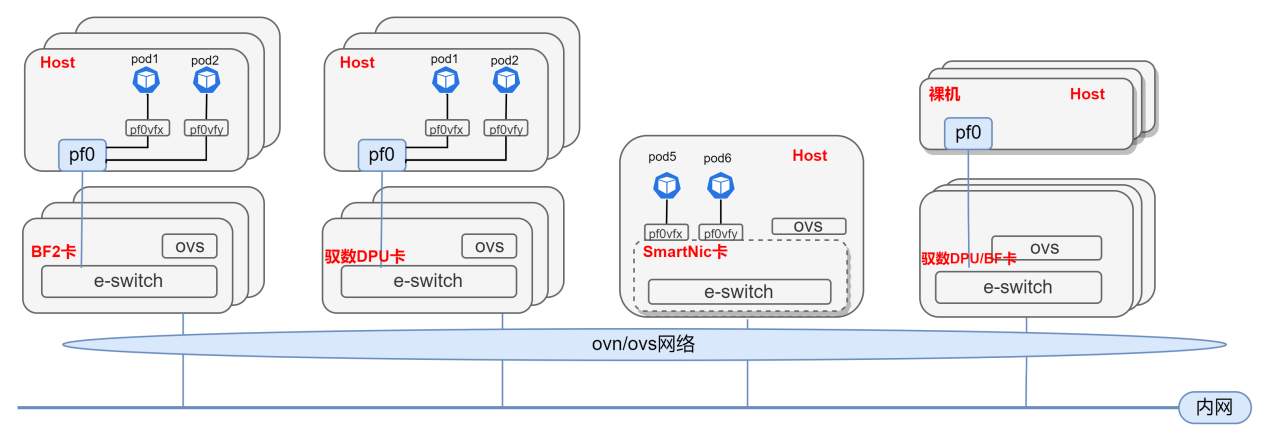
基于DPU與SmartNic的云原生SDN解決方案
首批認證!拓維信息梧桐云原生平臺獲鯤鵬原生開發技術認證






 工商網監
工商網監
評論