 利用Arm Kleidi技術實現PyTorch優化
利用Arm Kleidi技術實現PyTorch優化

作者:Arm 基礎設施事業部高級產品經理 Ashok Bhat
PyTorch 是一個廣泛應用的開源機器學習 (ML) 庫。近年來,Arm 與合作伙伴通力協作,持續改進 PyTorch 的推理性能。本文將詳細介紹如何利用 Arm Kleidi 技術提升 Arm Neoverse 平臺上的 PyTorch 推理表現。Kleidi 技術可以通過 Arm Compute Library (ACL) 和 KleidiAI 庫獲取。
PyTorch 提供兩種主要的執行模式:即時執行模式 (Eager Mode) 和圖模式 (Graph Mode)。即時執行模式是一種動態執行模式,操作會以 Python 代碼編寫的方式立即執行,該模式非常適用于實驗與調試。而圖模式則是在執行前將一系列 PyTorch 操作編譯成靜態計算圖,從而實現性能優化和高效的硬件加速。通過使用 torch.compile 函數,可以方便地將 PyTorch 代碼轉換為圖模式,通常能夠顯著提升執行速度。
PyTorch 即時執行模式
CPU 推理性能提升高達三倍
PyTorch 即時執行模式使用 oneDNN,針對具有 ACL 內核的 Arm Neoverse 處理器進行了優化。可以通過以下的 PyTorch 軟件棧圖進行了解。
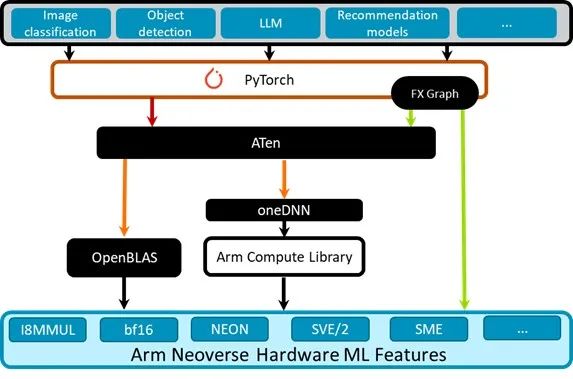
圖 1:PyTorch 軟件棧
PyTorch 中的 FX Graph 是用于可視化和優化 PyTorch 模型的一種中間表示形式。
ATen 是支撐 PyTorch 框架的基礎張量庫。它提供了核心張量類別和大量數學運算,構成了 PyTorch 模型的基本組件。
oneDNN 是一個性能庫,為包括 Arm 和 x86 在內的各種硬件架構提供常見深度學習原語的優化實現方案。在這些架構上,ATen 使用 oneDNN 作為性能增強后端。這意味著當 PyTorch 遇到支持的操作時,會將計算委托給 oneDNN,后者可以使用針對特定硬件的優化來提高執行效率。
Arm Compute Library 于 2016 年首次發布,提供針對 Arm 進行優化的關鍵 ML 原語,包括卷積、池化、激活函數、全連接層、歸一化。這些原語利用 Arm Neoverse 核心上針對特定 ML 和特定硬件的功能和指令來實現高性能。我們已將 Arm Compute Library 集成到 oneDNN 中,以便在 Arm 平臺上加速 ATen 操作。
Arm Neoverse CPU 包含有助于加速 ML 的硬件擴展,其中包括 Neon、SVE/SVE2、BF16 和 I8MM,通過有效地進行向量處理、BF16 運算和矩陣乘法來加速 ML 任務。
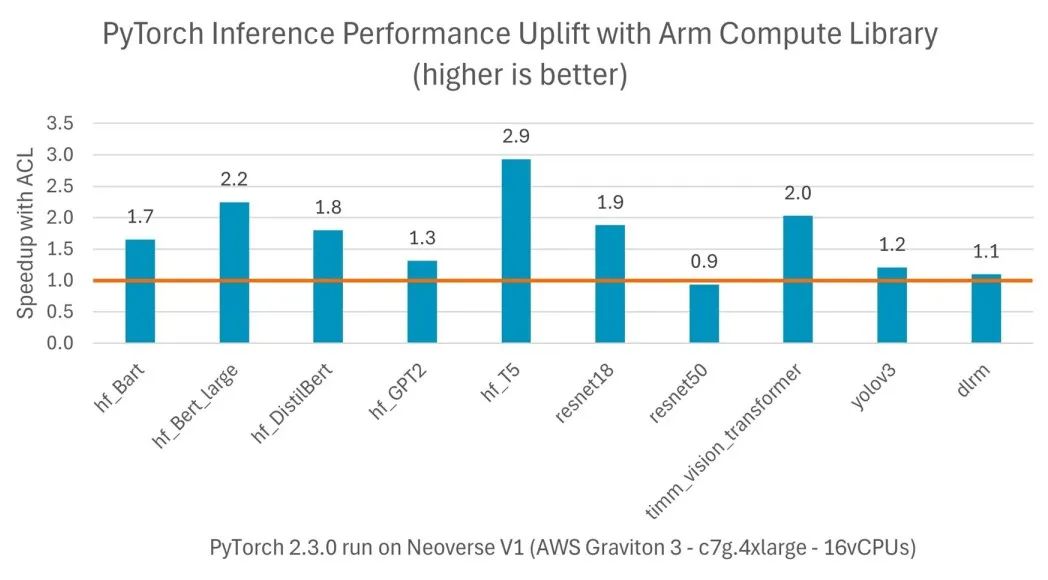
圖 2:各種模型在即時執行模式下實現的性能提升
PyTorch 圖模式(使用 torch.compile)
比 PyTorch 即時執行模式進一步提高兩倍
PyTorch 2.0 引入了 torch.compile,與默認的即時執行模式相比,可提高 PyTorch 代碼的速度。與即時執行模式不同,torch.compile 將整個模型預編譯成針對特定硬件平臺優化的單圖。從 PyTorch 2.3.1 開始,官方 AArch64 安裝包均包含 torch.compile 優化。在基于亞馬遜云科技 (AWS) Graviton3 的 Amazon EC2 實例上,對于各種自然語言處理 (NLP)、計算機視覺 (CV) 和推薦模型,這些優化可以為 TorchBench 模型推理帶來比即時執行模式高出兩倍的性能。
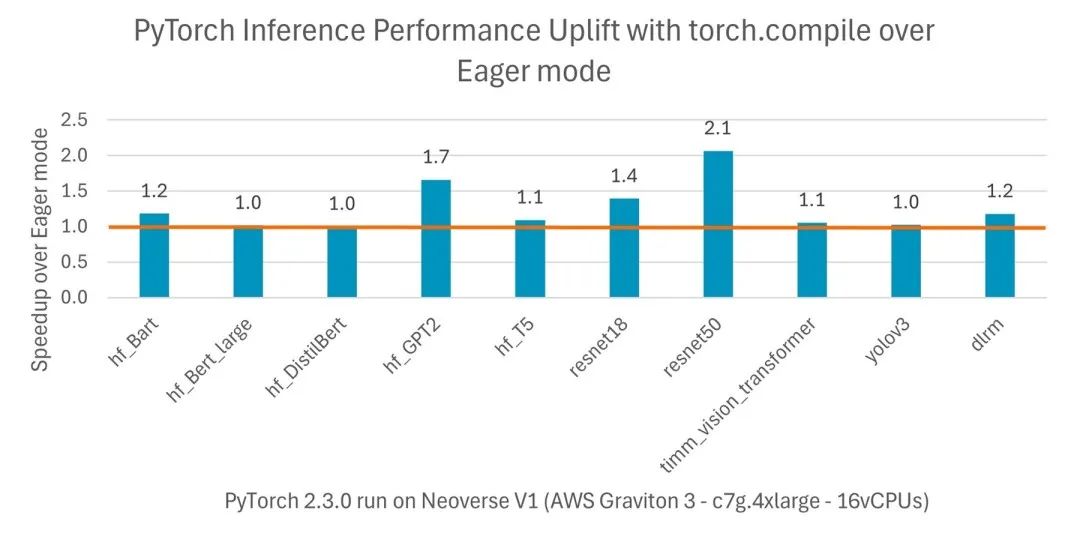
圖 3:各種模型在編譯模式下實現的性能提升
下一步通過 KleidiAI 庫
提升生成式 AI 推理性能
目前,我們已經研究了 Arm Compute Library 如何在即時執行模式和編譯模式下提升 PyTorch 推理性能。接下來,我們來看 PyTorch 即將推出什么新功能。Arm 目前正在努力提升 PyTorch 中的大語言模型 (LLM) 推理性能,并以 Llama 和 Gemma 為主要 LLM 示例。
經優化的 INT4 內核
今年早些時候,Arm 軟件團隊和合作伙伴共同優化了 llama.cpp 中的 INT4 和 INT8 內核,以利用更新的 DOT 和 MLA 指令。在 AWS Graviton3 處理器上,這些內核在即時評估方面比現有 GEMM MMLA 內核提升了 2.5 倍,并且在文本生成方面比默認的 vec_dot 內核提升了兩倍。這些經優化的新內核也是 Arm KleidAI 庫的一部分。
今年早些發布的 KleidiAI 庫是一個開源庫,具有針對 Arm CPU 上的 AI 任務進行優化的微內核。對于微內核,可將它視為能夠提升特定 ML 操作性能的軟件。開發者可以通過包含相關的 .c 和 .h 文件及公共頭文件來使用這些微內核。無需包含庫的其余部分。
Kleidi 與 PyTorch 的集成
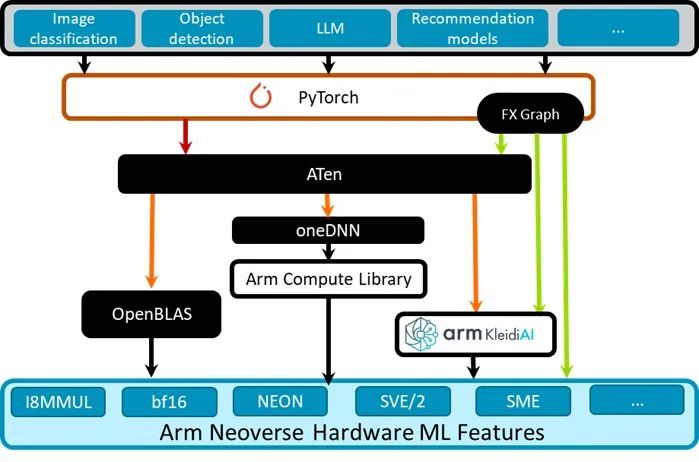
圖 4:Kleidi 技術與 PyTorch 的集成
我們引入了兩種新的 ATen 操作:torch.ops.aten._kai_weights_pack_int4() 和 torch.ops.aten._kai_input_quant_mm_int4(),兩者均使用 KleidiAI 庫中高度優化的打包技術和 GEMM 內核。gpt-fast 利用這些 PyTorch 算子來 (1) 使用對稱的每通道量化將權重量化為 INT4,并添加包含量化尺度的額外數組;(2) 動態量化激活矩陣并使用 AArch64 I8MM 擴展來執行激活矩陣和權重的 INT8 矩陣乘法。
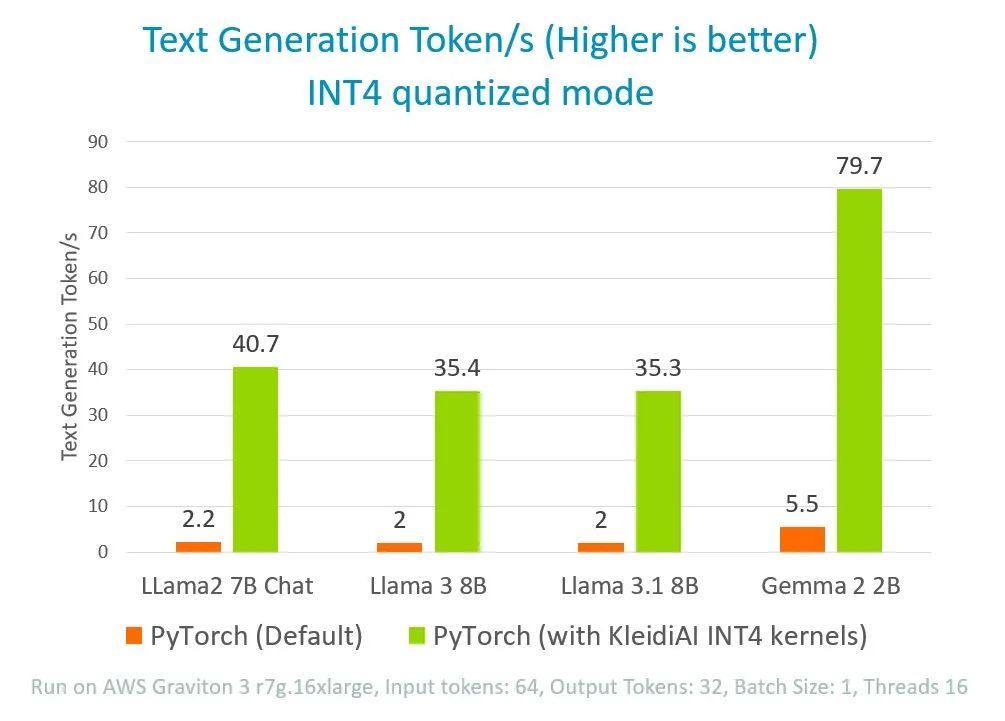
圖 5:通過在 PyTorch 中集成 KleidiAI
來提升 4 位量化 LLM 模型性能
通過這種方法,與目前默認的 PyTorch 實現方案相比,我們可以將 Llama 的推理性能提高 18 倍,將 Gemma 的推理性能提高 14 倍。
結論
Arm 及其合作伙伴利用 Arm Compute Library 中的 Kleidi 技術提高了 Arm Neoverse 平臺上的 PyTorch 推理性能。在即時執行模式下可實現高達兩倍的性能提升,在圖模式下(使用 torch.compile)可再提升兩倍。此外,我們還在努力將生成式 AI 模型(Llama 和 Gemma)的推理性能提升高達 18 倍。
Arm 通過部署 Kleidi 技術來實現PyTorch 上的優化,以加速在基于 Arm 架構的處理器上運行 LLM 的性能。Arm 技術專家在基于 Neoverse V2 的 AWS Graviton4 R8g.4xlarge EC2 實例上運行 Llama 3.1 展示了所實現的性能提升。如果你對這一演示感興趣,可閱讀《Arm KleidiAI 助力提升 PyTorch 上 LLM 推理性能》了解。
-
ARM
+關注
關注
134文章
9340瀏覽量
376152 -
cpu
+關注
關注
68文章
11063瀏覽量
216479 -
機器學習
+關注
關注
66文章
8499瀏覽量
134330 -
pytorch
+關注
關注
2文章
809瀏覽量
13868 -
Neoverse
+關注
關注
0文章
12瀏覽量
4775
原文標題:如何在 Arm Neoverse 平臺上使用 Kleidi 技術加速 PyTorch 推理?
文章出處:【微信號:Arm社區,微信公眾號:Arm社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Arm KleidiAI助力提升PyTorch上LLM推理性能
ARM程序設計優化策略與技術
Pytorch模型訓練實用PDF教程【中文】
在Ubuntu 18.04 for Arm上運行的TensorFlow和PyTorch的Docker映像
解讀最佳實踐:倚天 710 ARM 芯片的 Python+AI 算力優化

Arm推出AI優化的Arm終端CSS以及新的Arm Kleidi軟件






 工商網監
工商網監
評論