 Redis Cluster之故障轉移
Redis Cluster之故障轉移
1. Redis Cluster 簡介
Redis Cluster 是 Redis 官方提供的 Redis 集群功能。
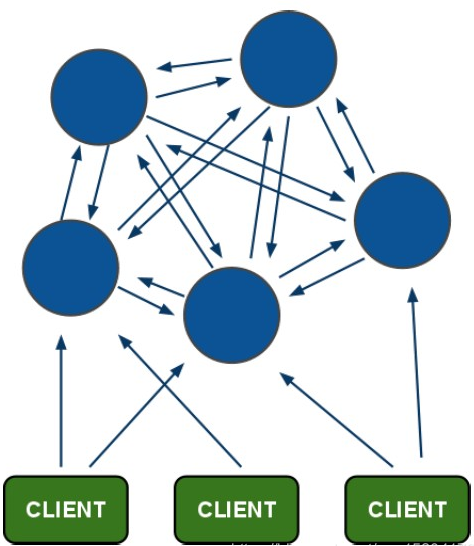
為什么要實現 Redis Cluster?
Redis 是單線程的(從網絡 I/O 處理到實際的讀寫命令處理),無論單核CPU 下內存多大,如果需要大量計算能力,還是需要采用分布式以增加 CPU 資源。
隨著公司發展,用戶數量增多,并發越來越多,業務需要更高的 QPS,而主從復制中單機的 QPS(10W)可能無法滿足業務需求。
數據量的考慮:現有服務器內存不能滿足業務數據的需要時,單純向服務器添加內存不能達到要求,此時需要考慮分布式需求,把數據分布到不同服務器上。
網絡流量需求:業務的流量已經超過服務器的網卡的上限值,可以考慮使用分布式來進行分流。
離線計算,需要中間環節緩沖等別的需求。
Redis Cluster 缺點
當節點數量很多時,性能不會很高。
解決方案:使用smart智能客戶端操作集群達到通信效率最大化。客戶端內部負責計算維護鍵,槽以及節點的映射,用于快速定位到目標節點。智能客戶端知道由哪個節點負責管理哪個槽,而且當節點與槽的映射關系發生改變時,客戶端也會知道這個改變,這是一種非常高效的方式。
集群的限制
key 批量操作支持有限:例如 mget、mset 必須在一個 slot。
key 事務和 Lua 支持有限:操作的 key 必須在一個節點。
key 是數據分區的最小粒度:不支持 bigkey 分區。
不支持多個數據庫:集群模式下只有一個 db0。
復制只支持一層:不支持樹形復制結構。
Redis Cluster 滿足容量和性能的擴展性,很多業務“不需要”。
大多數時客戶端性能會“降低”。 命令無法跨節點使用:mget、keys、scan、flush、sinter 等。 Lua 和事務無法跨節點使用。
客戶端維護更復雜:SDK 和應用本身消耗(例如更多的連接池)。
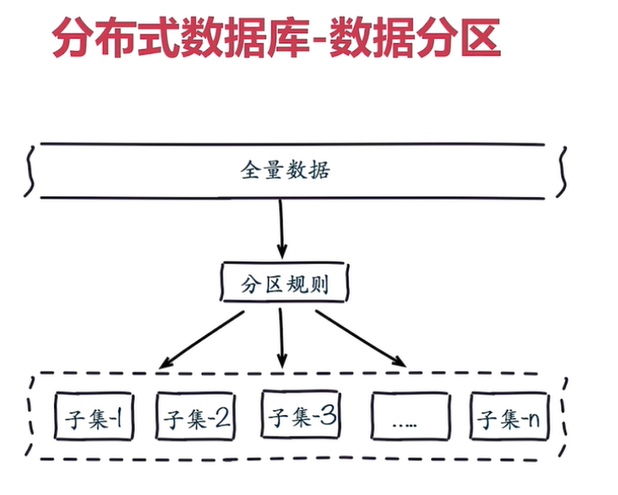
數據分布
為什么要做數據分布?
全量數據,單機 Redis 節點無法滿足要求,按照分區規則把數據分到若干個子集當中。
常用數據分布之順序分布
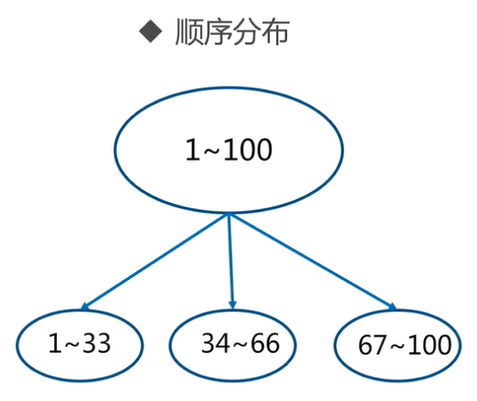
順序分區常用在關系型數據庫的設計。
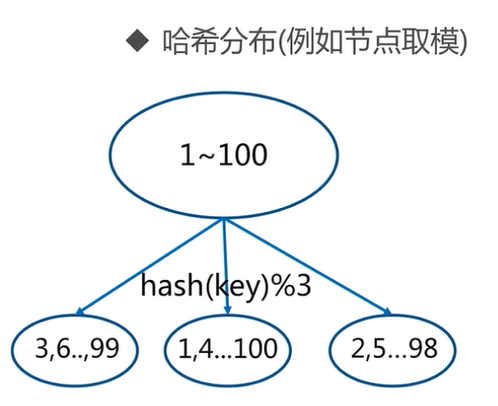
常用數據分布之哈希分布
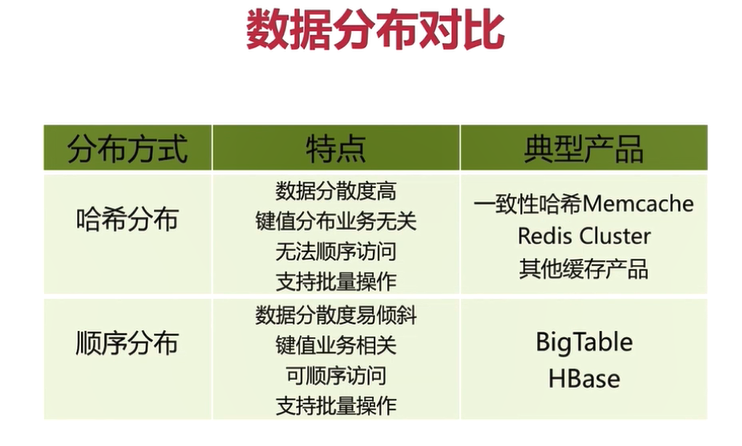
虛擬槽分區
虛擬槽分區是 Redis Cluster 采用的分區方式。
預設虛擬槽,每個槽就相當于一個數字,有一定范圍。每個槽映射一個數據子集,一般比節點數大。
Redis Cluster 中預設虛擬槽的范圍為 0 到 16383
每個key 通過 CRC16 校驗后對 16384 取模來決定這個 key 存放在哪個槽(slot)。
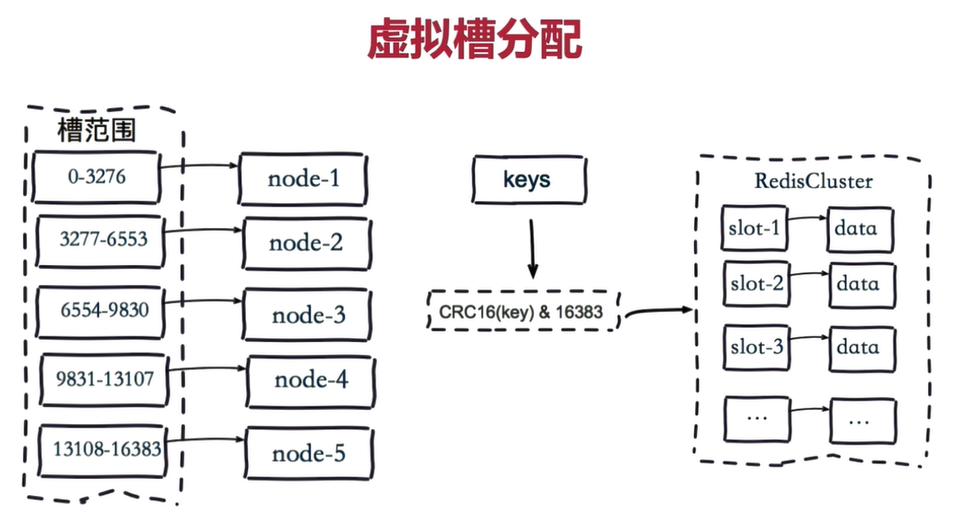
步驟:
把 16384 個槽按照節點數量進行平均分配,由節點進行管理。
對每個 key 按照 CRC16 規則進行 hash 運算。
把 hash 結果對 16383 進行取余。
把余數發送給 Redis 節點。
節點接收到數據,驗證是否在自己管理的槽編號的范圍。
如果在自己管理的槽編號范圍內,則把數據保存到數據槽中,然后返回執行結果。
如果在自己管理的槽編號范圍外,則會把數據發送給正確的節點,由正確的節點來把數據保存在對應的槽中。
需要注意的是:Redis Cluster 的節點之間會共享消息,每個節點都會知道是哪個節點負責哪個范圍內的數據槽。
虛擬槽分布方式中,由于每個節點管理一部分數據槽,數據保存到數據槽中。當節點擴容或者縮容時,對數據槽進行重新分配遷移即可,數據不會丟失。
虛擬槽分區特點:
使用服務端管理節點、槽、數據。例如 Redis Cluster。
可以對數據打散,又可以保證數據分布均勻
2. Redis Cluster 架構
1)節點
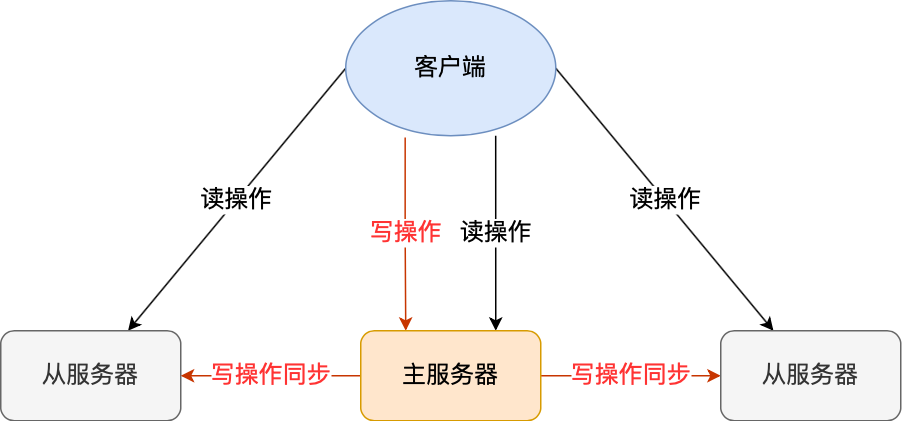
Redis Cluster 是分布式架構的:即 Redis Cluster 中有多個節點,每個節點都負責進行數據讀寫操作。
每個節點之間會進行通信。
2)meet 操作
meet 操作是節點之間完成相互通信的基礎,meet 操作有一定的頻率和規則。
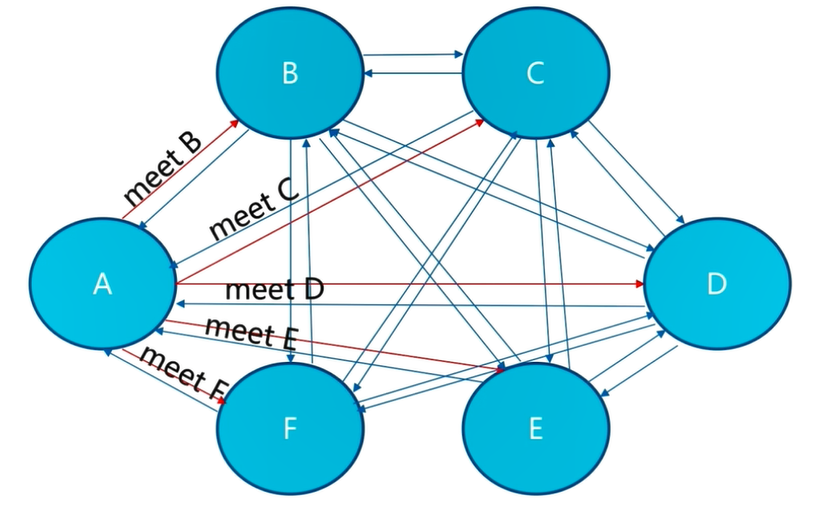
所有的 Redis 節點彼此互連,內部使用二進制協議優化傳輸速度和帶寬。
客戶端與 Redis 節點直連,不需要中間 proxy 層。客戶端不需要連接集群所有節點,連接集群中任何一個可用節點即可。
3)分配槽
把 16384 個槽平均分配給節點進行管理,每個節點只能對自己負責的槽進行讀寫操作。
由于每個節點之間都彼此通信,每個節點都知道其他節點負責管理的槽范圍。
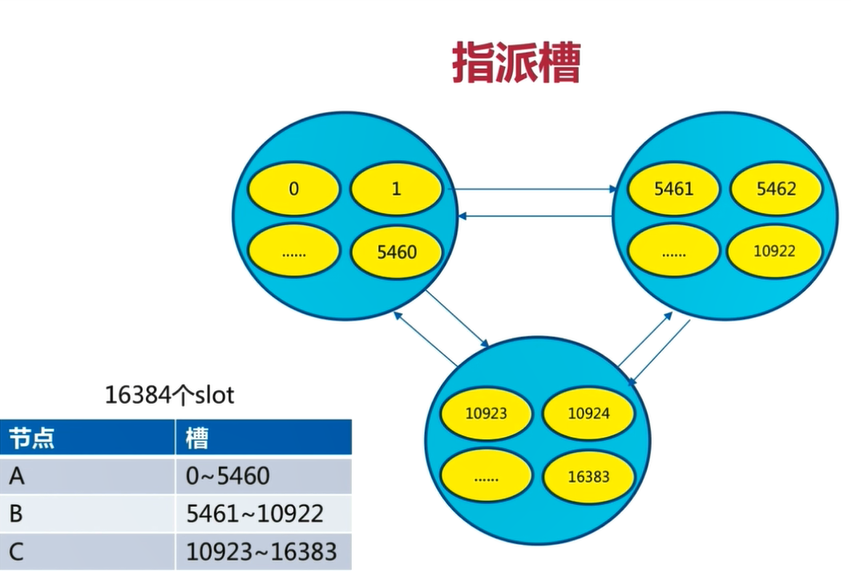
客戶端訪問任意節點時,對數據 key 按照 CRC16 規則進行 hash 運算,然后將運算結果對 16383 進行取余,如果余數在當前訪問的節點管理的槽范圍內,則直接返回對應的數據
如果不在當前節點負責管理的槽范圍內,則會告訴客戶端去哪個節點獲取數據,由客戶端去正確的節點獲取數據。
4)復制
Cluster 自動做 master+slave 的主從復制和讀寫分離、master+slave 高可用和主備切換、支持多個 master 的 hash slot 即數據分布式存儲。
3. 故障轉移
集群自動故障轉移過程分為故障發現和節點恢復。節點下線分為主觀下線和客觀下線:
當超過半數的主節點(master)認為故障節點為主觀下線時,則標記這個節點為客觀下線狀態。
從節點(slave)負責對客觀下線的主節點(master)觸發故障恢復流程,保證集群的可用性。
節點失效機制:選舉
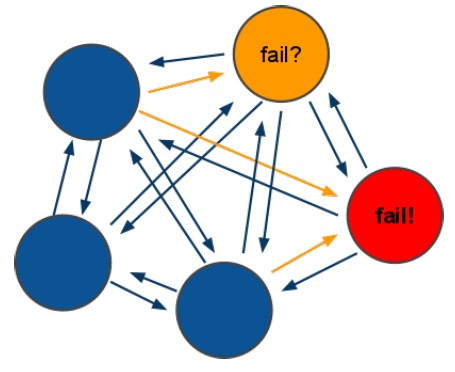
ping/pong 模式
Redis Cluster 通過 ping/pong 消息實現故障發現。
ping/pong 不僅能傳遞節點與槽的對應消息,也能傳遞其他狀態,比如:節點主從狀態,節點故障等。
故障發現就是通過這種模式來實現,分為主觀下線和客觀下線。
集群中所有 master 參與投票,如果半數以上 master 節點與其中一個 master 節點通信超時(cluster-node-timeout),則認為該 master 節點掛掉。
什么時候整個集群不可用(cluster_state:fail)?
如果集群任意 master 掛掉,且當前 master 沒有 slave,則集群進入 fail 狀態。也可以理解成集群的 [0-16383] slot 映射不完全時進入 fail 狀態。
如果集群超過半數以上 master 掛掉,無論是否有 slave,集群進入 fail 狀態。
鏈接:https://www.cnblogs.com/juno3550/p/14840433.html
-
Cluster
+關注
關注
0文章
9瀏覽量
9246 -
Redis
+關注
關注
0文章
385瀏覽量
11346
原文標題:3. 故障轉移
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【經驗分享】在Omni3576上編譯Redis-8.0.2源碼,并安裝及性能測試
【幸狐Omni3576邊緣計算套件試用體驗】Redis最新8.0.2版本源碼安裝及性能測試
Redis 再次開源!
Redis實戰筆記

華為云 Flexus X 加速 Redis 案例實踐與詳解
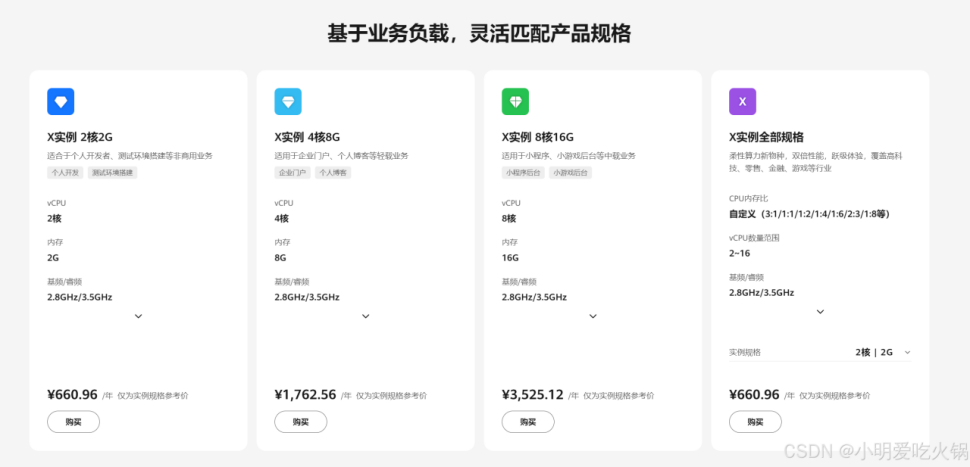
云服務器 Flexus X 實例,Docker 集成搭建 Redis 集群
性能與可靠性并重,Flexus X 實例助力 Redis 三主三從集群高效運行
華為云Flexus X實例,Redis性能加速評測及對比
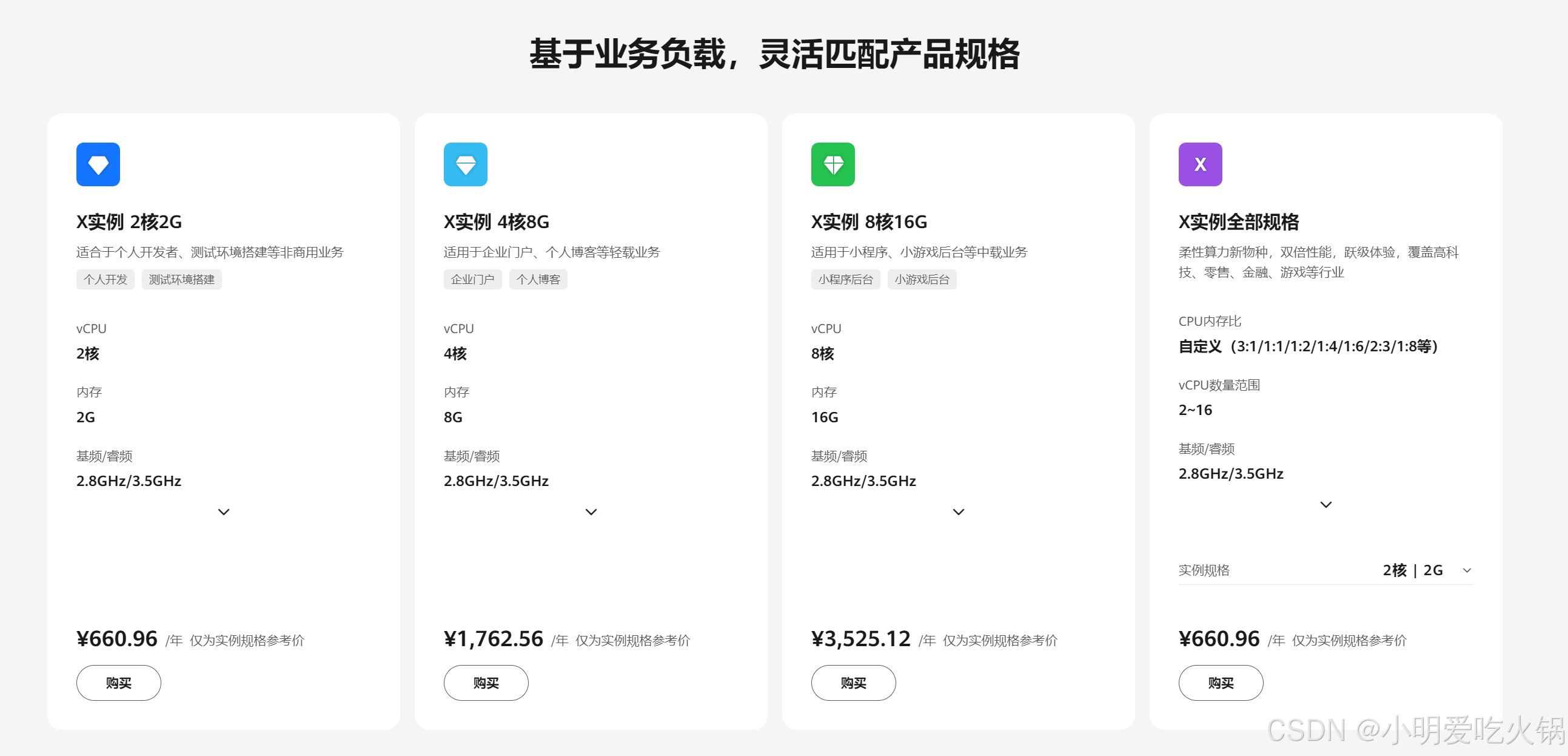
華為云 Flexus X 輕松實現 Redis 一主多從高效部署

Redis使用重要的兩個機制:Reids持久化和主從復制

Redis緩存與Memcached的比較
恒訊科技分析:云數據庫rds和redis區別是什么如何選擇?
K8S學習教程(二):在 PetaExpress KubeSphere容器平臺部署高可用 Redis 集群





 工商網監
工商網監
評論