") 深入探討DeepSeek大模型的核心技術(shù)
深入探討DeepSeek大模型的核心技術(shù)

導(dǎo)讀
本文深入探討了DeepSeek大模型的核心技術(shù),從公司背景、模型能力、訓(xùn)推成本到核心技術(shù)細(xì)節(jié)進(jìn)行了全面分析。
一、關(guān)于DeepSeek公司及其大模型
1.1 公司概況
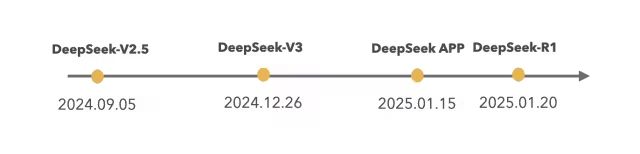
DeepSeek 2023年7月成立于杭州,是幻方量化旗下的子公司,全稱(chēng)是杭州深度求索人工智能基礎(chǔ)技術(shù)研究有限公司。 "成立時(shí)間才一年多"、"最近推出的V3已經(jīng)能和OpenAI的4o媲美"、"訓(xùn)練成本不到600W美元"、"API定價(jià)僅是國(guó)內(nèi)其他頭部廠商幾十分之一"、"APP已經(jīng)在中美APP store登上免費(fèi)應(yīng)用榜首"; 以上是最近關(guān)于DeepSeek的一些新聞熱點(diǎn)信息,下面我們從官網(wǎng)看下: DeepSeek近半年相繼推出了3個(gè)主要的大模型版本,分別是DeepSeek V2.5、DeepSeek V3、DeepSeek-R1(無(wú)一例外的都是用了MOE架構(gòu))。在這之前還推出了DeepSeek-VL、DeepSeek Coder、DeepSeek Math。
1.2 模型能力
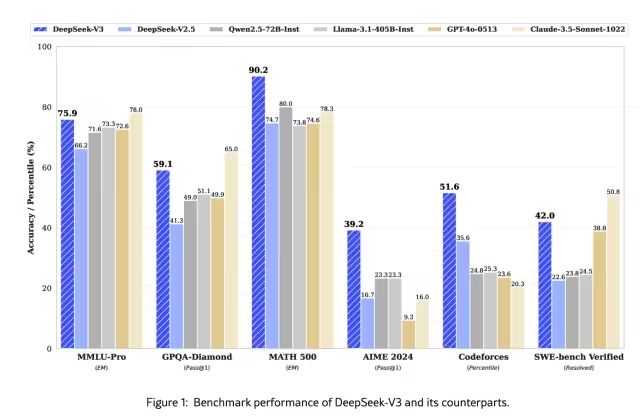
DeepSeek模型已經(jīng)對(duì)標(biāo)國(guó)內(nèi)Qwen、海外Llama、GPT 4o,從公布的榜單評(píng)測(cè)上看:DeepSeek-V3 在開(kāi)源模型中位列榜首,與世界上最先進(jìn)的閉源模型不分伯仲。
1.3訓(xùn)推成本
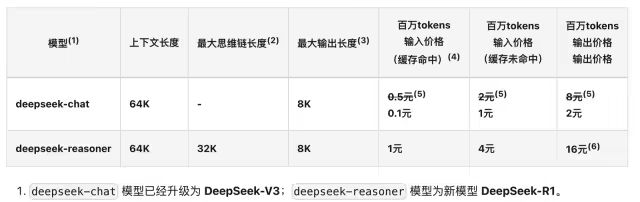
推理成本(API報(bào)價(jià)):百萬(wàn)Token輸入價(jià)格能達(dá)到1元。
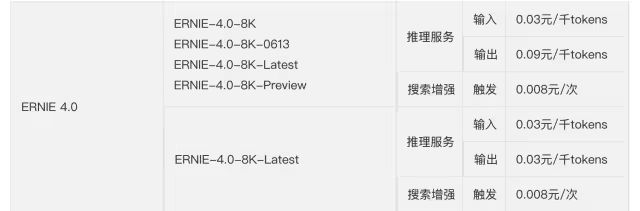
訓(xùn)練成本:從技術(shù)報(bào)告中看DeepSeek用的是H800的GPU做的訓(xùn)練,而且只有2千張左右的H800,整個(gè)V3的正式訓(xùn)練成本不超過(guò)600W美元。
1、預(yù)訓(xùn)練階段,每萬(wàn)億的Token 訓(xùn)練V3使用2048個(gè)H800GPU集群,只需要180K 個(gè)H800 GPU小時(shí),大概3.7天(180000/2048/24)
2、整個(gè)預(yù)訓(xùn)練總耗時(shí)2664K GPU小時(shí)(不到2個(gè)月),加上 上下文擴(kuò)展和后訓(xùn)練,總耗時(shí)大概2788KGPU耗時(shí)。
3、按照H800 每小時(shí)2美元租賃,總的訓(xùn)練成本不超過(guò)600W美元

DeepSeek-V3 Technical Report? ? 這么低的推理和訓(xùn)練成本不由引出以下的問(wèn)題: 模型采用了什么樣的網(wǎng)絡(luò)架構(gòu)? 訓(xùn)練的精度、框架和并行策略是怎樣的? 模型的部署和優(yōu)化方案是怎樣的? 在硬件層的計(jì)算和通信上做了什么優(yōu)化?
二、DeepSeek訓(xùn)推核心技術(shù)
2.1 DeepSeek-V3模型網(wǎng)絡(luò)架構(gòu)
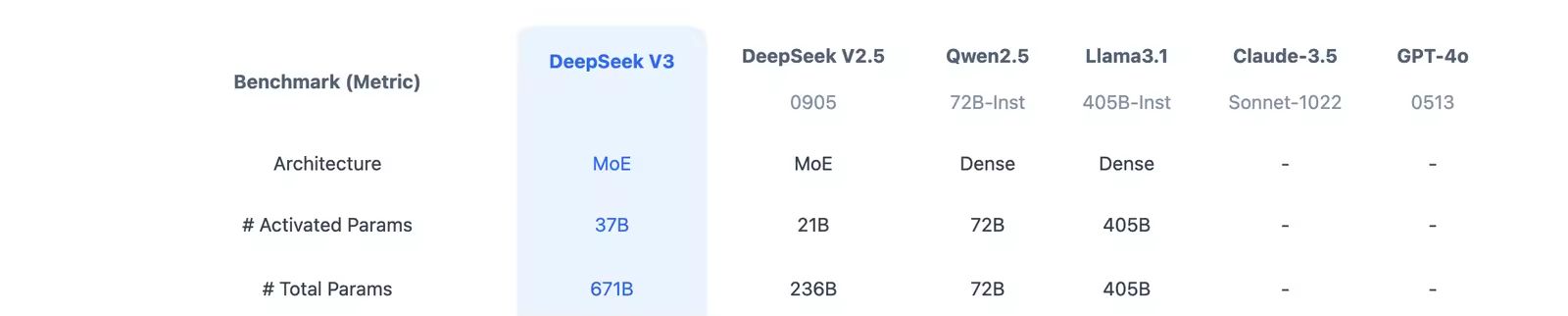
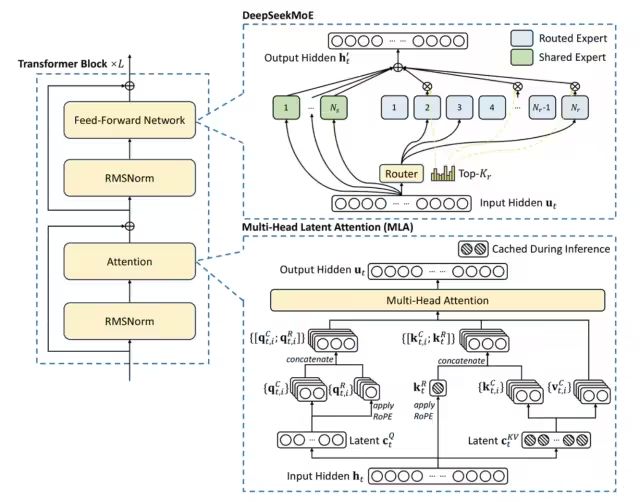
DeepSeekV3 整體預(yù)訓(xùn)練用了14.8萬(wàn)億的高質(zhì)量Token,并且在后期做了SFT和RL,模型參數(shù)量達(dá)到671B,但是每個(gè)Token僅激活37B參數(shù)。為了做到高效的推理和訓(xùn)練,DeepSeekV3自研了MLA注意力機(jī)制和無(wú)輔助損失負(fù)載均衡策略的MoE架構(gòu)。
從技術(shù)報(bào)告中看出,是經(jīng)典的Transformer架構(gòu),比較亮眼的就是前饋網(wǎng)絡(luò)使用的DeepSeekMoE架構(gòu)、Attention機(jī)制使用MLA架構(gòu),其實(shí)這兩個(gè)在DeepSeekV2模型已經(jīng)被驗(yàn)證使用過(guò)。
與DeepSeek-V2相比,V3額外引入了一種無(wú)輔助損失的負(fù)載均衡策略,用于DeepSeekMoE,以減輕因需要保證Expert負(fù)載均衡而導(dǎo)致的性能下降。
2.1.1 DeepSeekMoE
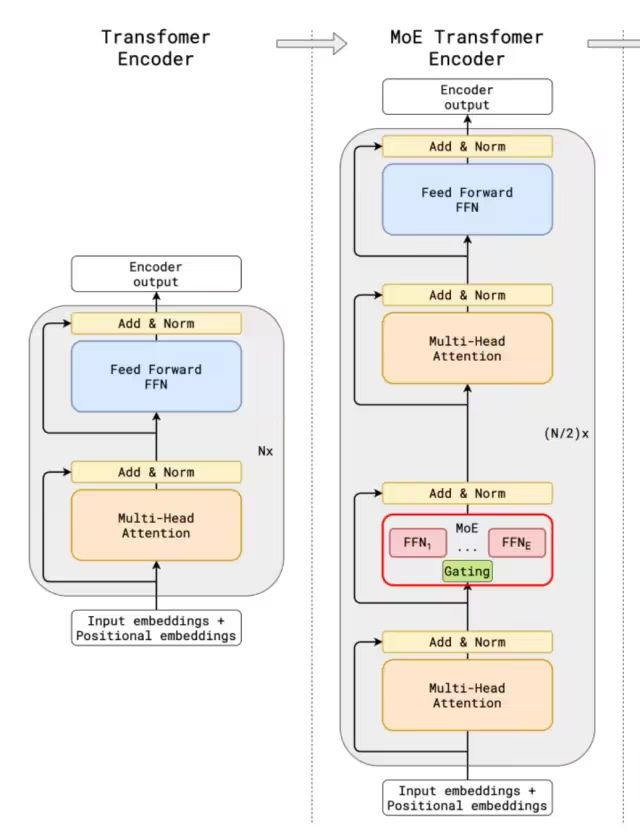
第一個(gè)將MoE架構(gòu)引入Transformer網(wǎng)絡(luò)的就是GShard架構(gòu)了,與傳統(tǒng)大模型架構(gòu)相比,MoE架構(gòu)在數(shù)據(jù)流轉(zhuǎn)過(guò)程中集成了一個(gè)專(zhuān)家網(wǎng)絡(luò)層。 可以看出傳統(tǒng)的MoE基本兩部分組成:Gating門(mén)控網(wǎng)絡(luò)、稀疏MoE層;
●稀疏 MoE 層: 這些層代替了傳統(tǒng) Transformer 模型中的前饋網(wǎng)絡(luò) (FFN) 層。MoE 層包含若干“專(zhuān)家”(例如 8 個(gè)),每個(gè)專(zhuān)家本身是一個(gè)獨(dú)立的神經(jīng)網(wǎng)絡(luò)。在實(shí)際應(yīng)用中,這些專(zhuān)家通常是前饋網(wǎng)絡(luò) (FFN),但它們也可以是更復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu),甚至可以是 MoE 層本身,從而形成層級(jí)式的 MoE 結(jié)構(gòu)。
●門(mén)控網(wǎng)絡(luò)或路由: 這個(gè)部分用于決定哪些Token被發(fā)送到哪個(gè)專(zhuān)家。Token的路由方式是 MoE 使用中的一個(gè)關(guān)鍵點(diǎn),因?yàn)槁酚善饔蓪W(xué)習(xí)的參數(shù)組成,并且與網(wǎng)絡(luò)的其他部分一同進(jìn)行預(yù)訓(xùn)練。
和傳統(tǒng)的MoE架構(gòu)相比,DeepSeekMoE使用更細(xì)粒度的專(zhuān)家,并將一些專(zhuān)家隔離為共享專(zhuān)家,減少專(zhuān)家間的知識(shí)冗余。
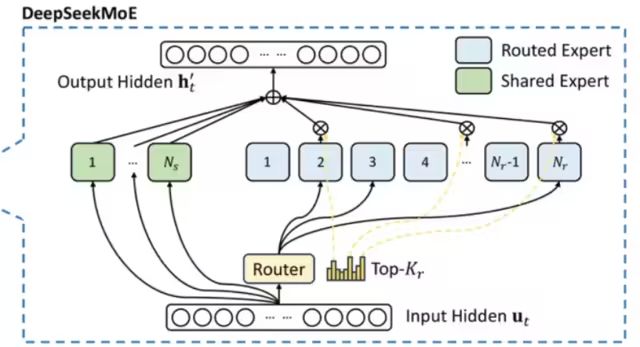
門(mén)控網(wǎng)絡(luò)路由策略:TopK表示第t個(gè)Token和所有路由專(zhuān)家計(jì)算出的親和力分?jǐn)?shù)中K個(gè)最高分?jǐn)?shù)的集合,在DeepSeekV3中,使用sigmoid函數(shù)計(jì)算親和力分?jǐn)?shù),然后在所有選擇的親和力分?jǐn)?shù)中應(yīng)用歸一化來(lái)生成門(mén)控值。? 通常在MoE模型的訓(xùn)練過(guò)程中,不同專(zhuān)家因?yàn)槁酚刹呗缘囊蛩貢?huì)導(dǎo)致接收的訓(xùn)練數(shù)據(jù)分布不均,比如所有的Token都被發(fā)送到只有少數(shù)幾個(gè)受歡迎的專(zhuān)家,那么有些專(zhuān)家就可能沒(méi)有被訓(xùn)練到。 業(yè)界通用的解決方案就是引入輔助損失,但是,有時(shí)候過(guò)大的輔助損失會(huì)損害模型性能。 為了在負(fù)載均衡和模型性能之間取得更好的平衡,DeepSeek開(kāi)創(chuàng)了一種無(wú)輔助損失的負(fù)載均衡策略:為每個(gè)專(zhuān)家引入一個(gè)偏差項(xiàng)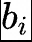 ,并將其添加到相應(yīng)的親和力分?jǐn)?shù)
,并將其添加到相應(yīng)的親和力分?jǐn)?shù)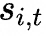 中以確定top-K路由,具體來(lái)說(shuō):如果其對(duì)應(yīng)的專(zhuān)家過(guò)載,我們將偏差項(xiàng)減少γ;如果其對(duì)應(yīng)的專(zhuān)家負(fù)載不足,我們將偏差項(xiàng)增加γ,其中γ是一個(gè)稱(chēng)為偏差更新速度的超參數(shù)。
中以確定top-K路由,具體來(lái)說(shuō):如果其對(duì)應(yīng)的專(zhuān)家過(guò)載,我們將偏差項(xiàng)減少γ;如果其對(duì)應(yīng)的專(zhuān)家負(fù)載不足,我們將偏差項(xiàng)增加γ,其中γ是一個(gè)稱(chēng)為偏差更新速度的超參數(shù)。
門(mén)控網(wǎng)絡(luò)本質(zhì)上就是一個(gè)softmax疊加一個(gè)分類(lèi)網(wǎng)絡(luò),那么輔助loss往往就是添加一個(gè)懲罰項(xiàng),對(duì)輸出過(guò)大的 logits 進(jìn)行懲罰,鼓勵(lì)模型生成更加適度的 logits 值,防止模型生成過(guò)于極端的輸出。
2.1.2 MLA 多頭潛在注意力
大模型推理過(guò)程KV Cache機(jī)制一般是限制推理效率的一大瓶頸,而標(biāo)準(zhǔn)的Transformer 架構(gòu)里面的MHA架構(gòu)會(huì)產(chǎn)出非常多的KV Cache,為了減少對(duì)應(yīng)的KV Cache業(yè)界實(shí)踐過(guò)很多方案,例如PagedAttention、多查詢(xún)注意力(MQA)和分組查詢(xún)注意力(GQA),但是性能相比原生的MHA有一定差距。
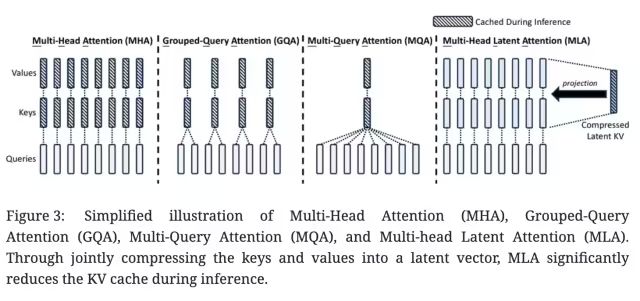
DeepSeek-V2,提出一種創(chuàng)新的注意力機(jī)制:多頭潛在注意力(MLA)。
相比MQA的KV共用和GQA的KV分組,MLA的核心是注意力鍵和值的低秩聯(lián)合壓縮,以減少推理過(guò)程中的鍵值(KV)緩存。相比MHA具有更好的性能,但需要的 KV 緩存量要少得多。

低秩矩陣是指其秩(rank)遠(yuǎn)小于其行數(shù)和列數(shù)的矩陣。
假設(shè)我們有一個(gè)矩陣,其實(shí)際結(jié)構(gòu)允許它被分解為兩個(gè)較小的矩陣的乘積。這種情況通常意味著原矩陣是低秩的。
假設(shè)我們有一個(gè)4×5的矩陣A,這個(gè)矩陣可以通過(guò)兩個(gè)更小的矩陣的乘積來(lái)表示,比如一個(gè)4×2的矩陣B和一個(gè)2×5的矩陣C。這意味著原始矩陣A的信息可以通過(guò)這兩個(gè)較小的矩陣來(lái)捕捉,表明A是一個(gè)低秩矩陣。
低秩壓縮計(jì)算核心過(guò)程:
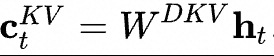
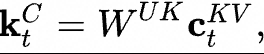
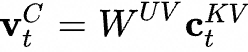
這里的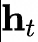 表示第t個(gè)Token的輸入,
表示第t個(gè)Token的輸入,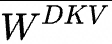 表示KV的向下投影矩陣,將做降維壓縮表示,實(shí)際得到
表示KV的向下投影矩陣,將做降維壓縮表示,實(shí)際得到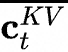 就是要緩存的KV壓縮隱向量;
就是要緩存的KV壓縮隱向量;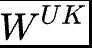 和
和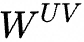 是向上做升維的投影矩陣,將Token的壓縮隱向量復(fù)原為原始KV矩陣;
是向上做升維的投影矩陣,將Token的壓縮隱向量復(fù)原為原始KV矩陣;
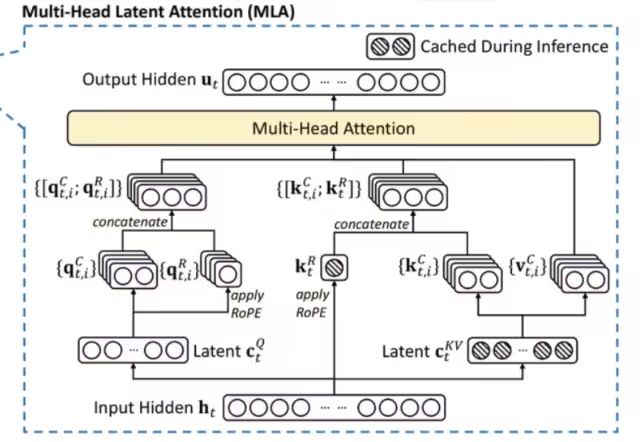
MLA 模塊架構(gòu)圖
具體的Attention計(jì)算推導(dǎo)過(guò)程可以參考:MLA的推導(dǎo)細(xì)節(jié)
2.2訓(xùn)練推理核心技術(shù)
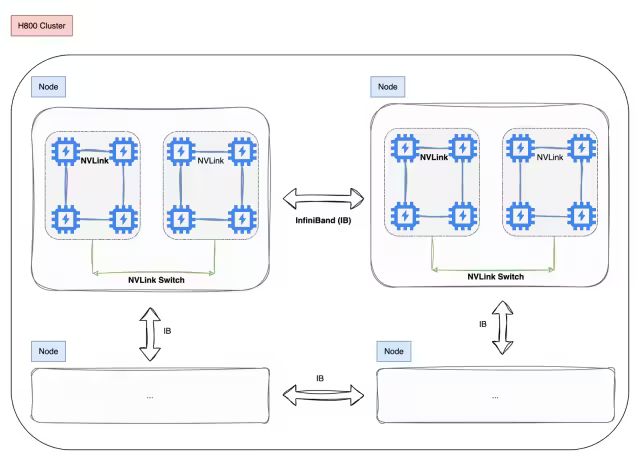
2.2.1 訓(xùn)練框架HAI-LLM
DeepSeek-V3在一個(gè)配備了2048個(gè)NVIDIA H800 GPU的集群上進(jìn)行訓(xùn)練,使用的是自研的HAI-LLM框架,框架實(shí)現(xiàn)了四種并行訓(xùn)練方式:ZeRO 支持的數(shù)據(jù)并行、流水線(xiàn)并行、張量切片模型并行和序列并行。
這種并行能力支持不同工作負(fù)載的需求,可以支持?jǐn)?shù)萬(wàn)億規(guī)模的超大模型并擴(kuò)展到數(shù)千個(gè) GPU,同時(shí)還自研了一些配套的高性能算子haiscale,可以幫助 HAI-LLM 極大優(yōu)化大模型訓(xùn)練的顯存效率和計(jì)算效率。
2.2.2 核心算法DualPipe-創(chuàng)新流水線(xiàn)并行算法
i.通信計(jì)算重疊優(yōu)化
DeepSeek-V3應(yīng)用了16路流水線(xiàn)并行(PP),跨越8個(gè)節(jié)點(diǎn)的64路專(zhuān)家并行(EP),以及ZeRO-1數(shù)據(jù)并行(DP)。
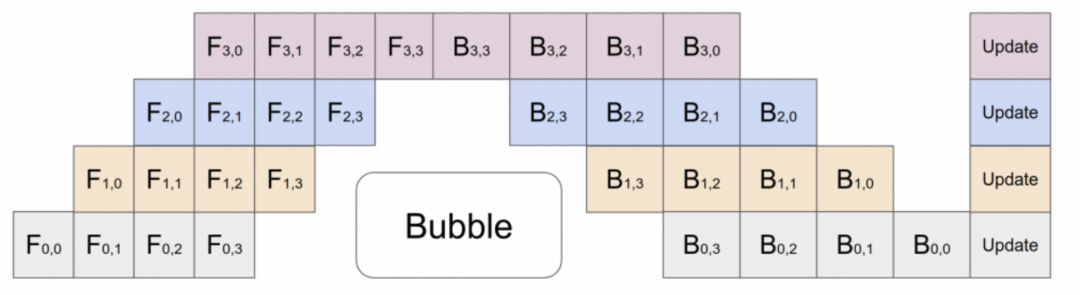
與現(xiàn)有的流水線(xiàn)并行方法相比,DualPipe的流水線(xiàn)氣泡更少。同時(shí)重疊了前向和后向過(guò)程中的計(jì)算和通信階段,解決了跨節(jié)點(diǎn)專(zhuān)家并行引入的沉重通信開(kāi)銷(xiāo)的挑戰(zhàn)。
DualPipe的關(guān)鍵思想是重疊一對(duì)單獨(dú)的前向和后向塊中的計(jì)算和通信:將每個(gè)塊劃分為四個(gè)組件:注意力、all-all調(diào)度、MLP和all-all組合
例如,假設(shè)我們有兩個(gè)計(jì)算塊,A和B:
1.在塊A進(jìn)行前向傳播計(jì)算時(shí),可以同時(shí)進(jìn)行塊B的后向傳播通信過(guò)程。
2.當(dāng)塊A完成前向傳播計(jì)算后,開(kāi)始它的通信過(guò)程;而塊B則開(kāi)始它的前向傳播計(jì)算。

通過(guò)優(yōu)化排列這些功能模塊,并精確調(diào)控用于通信和計(jì)算的 GPU SM資源分配比例,系統(tǒng)能夠在運(yùn)行過(guò)程中有效隱藏全節(jié)點(diǎn)通信和 PP 通信開(kāi)銷(xiāo)。 可以看出DeepSeek在PP這塊,做了大量的通信計(jì)算重疊優(yōu)化,從技術(shù)報(bào)告中看出,即使是細(xì)粒度的all-all專(zhuān)家通信,all-all的通信開(kāi)銷(xiāo)幾乎為0。

●計(jì)算通信重疊
在深度學(xué)習(xí)大規(guī)模分布式訓(xùn)練過(guò)程中,通信的速度往往落后于計(jì)算的速度,如何在通信的gap期間內(nèi)并行做一些計(jì)算就是高性能計(jì)算和通信重疊,是實(shí)現(xiàn)高效訓(xùn)練的關(guān)鍵因素。
●流水線(xiàn)并行氣泡問(wèn)題
一些大的模型會(huì)采用流水線(xiàn)并行策略,將模型的不同層放在不同的GPU上,但是不同層之間有依賴(lài)關(guān)系,后面層需要等前面的計(jì)算完才能開(kāi)始計(jì)算,會(huì)導(dǎo)致GPU在一段時(shí)間是閑置的,如下圖所示:
ii.跨節(jié)點(diǎn)全對(duì)全通信 DeepSeek還專(zhuān)門(mén)定制了高效的跨節(jié)點(diǎn)all-all通信內(nèi)核(包括調(diào)度和組合)。 具體來(lái)說(shuō):跨節(jié)點(diǎn) GPU 通過(guò) IB 完全互連,節(jié)點(diǎn)內(nèi)通信通過(guò) NVLink 處理,每個(gè)Token最多調(diào)度到 4個(gè)節(jié)點(diǎn),從而減少 IB 通信量。同時(shí)使用warp專(zhuān)業(yè)化技術(shù)做調(diào)度和組合的優(yōu)化。
在調(diào)度過(guò)程中,(1) IB 發(fā)送,(2) IB 到 NVLink 轉(zhuǎn)發(fā),以及 (3) NVLink 接收分別由各自的 warp 處理。分配給每個(gè)通信任務(wù)的 warp 數(shù)會(huì)根據(jù)所有 SM 上的實(shí)際工作負(fù)載動(dòng)態(tài)調(diào)整。
在合并過(guò)程中,(1) NVLink 發(fā)送,(2) NVLink 到 IB 的轉(zhuǎn)發(fā)和累積,以及 (3) IB 接收和累積也由動(dòng)態(tài)調(diào)整的 warp 處理。
通過(guò)這種方式,IB 和 NVLink 的通信實(shí)現(xiàn)完全重疊,每個(gè) token 能夠在不產(chǎn)生 NVLink 額外開(kāi)銷(xiāo)的情況下,在每個(gè)節(jié)點(diǎn)上平均高效選擇 3.2 個(gè)專(zhuān)家。這意味著,雖然 DeepSeek-V3 實(shí)際只選擇 8 個(gè)路由專(zhuān)家,但它可以將這個(gè)數(shù)字?jǐn)U展到最多 13 個(gè)專(zhuān)家(4 個(gè)節(jié)點(diǎn) × 3.2 個(gè)專(zhuān)家/節(jié)點(diǎn)),同時(shí)保持相同的通信成本。
DSV3采用了1個(gè)共享專(zhuān)家和256個(gè)路由專(zhuān)家的MoE架構(gòu),每個(gè)token會(huì)激活8個(gè)路由專(zhuān)家。
2.2.3 用于FP8訓(xùn)練的混合精度框架
這里并沒(méi)有將全量參數(shù)FP8量化訓(xùn)練,大多數(shù)計(jì)算密集型操作都在FP8中進(jìn)行,而一些關(guān)鍵操作則戰(zhàn)略性地保留其原始數(shù)據(jù)格式,以平衡訓(xùn)練效率和數(shù)值穩(wěn)定性。 哪些算子啟用FP8量化去計(jì)算?取舍邏輯是什么? ■大多數(shù)核心計(jì)算過(guò)程,即 GEMM 運(yùn)算,都以 FP8 精度實(shí)現(xiàn) ■涉及對(duì)低精度計(jì)算的敏感性的算子,仍然需要更高的精度 ■一些低成本算子也可以使用更高的精度 以下組件保留了原始精度(例如,BF16 或 FP32):Embedding模塊、輸出頭、MoE 門(mén)控模塊、Normalization算子以及Attention算子。 ? 如何提高低精度訓(xùn)練精度? ■細(xì)粒度量化
對(duì)激活,在token維度采用group-wise的量化(1*128);對(duì)權(quán)重,采用128* 128的block-wise量化
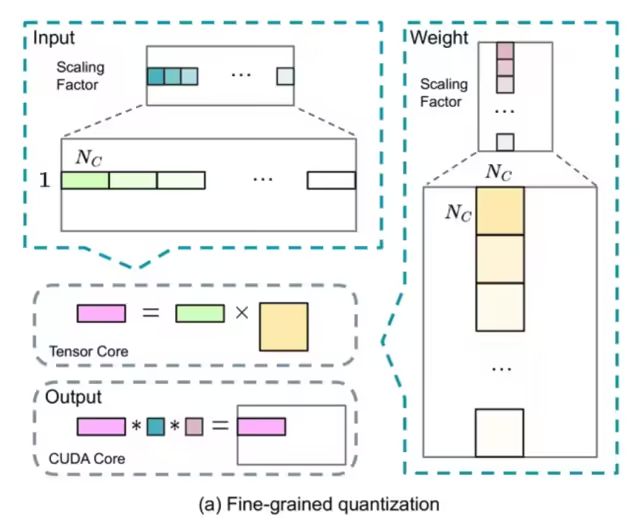
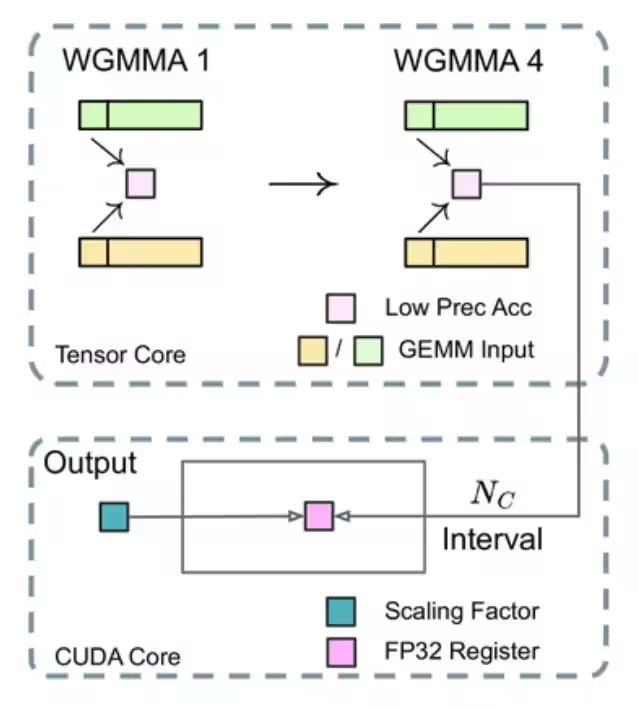
■提高累加精度
在 TensorCore 上執(zhí)行矩陣 MMA(矩陣乘法累加)操作時(shí),每當(dāng)累加達(dá)到一個(gè)間隔時(shí),這些部分結(jié)果會(huì)被傳輸?shù)?CUDA Cores 上的 FP32 寄存器中,并在那里進(jìn)行FP32 精度的累加計(jì)算。
2.2.4 MTP的訓(xùn)練目標(biāo)
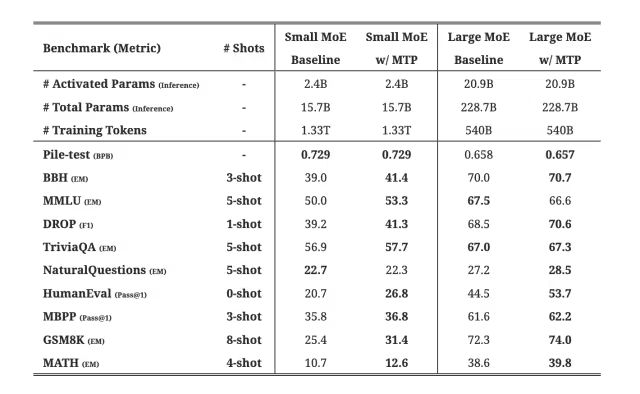
DeepSeekV3訓(xùn)練過(guò)程設(shè)置了多Token預(yù)測(cè)的目標(biāo),從技術(shù)報(bào)告的消融實(shí)驗(yàn)看出,確實(shí)提高了模型在大多數(shù)評(píng)估基準(zhǔn)上的性能,而且MTP模塊還可以用于推理加速。
2.2.5 推理部署方案
DeepSeek-V3 整體參數(shù)量達(dá)到了671B,如此多的參數(shù)量,我們看下他的一個(gè)部署方案:
推理部署采用了預(yù)填充(Prefilling)和解碼(Decoding)分離的策略,確保了在線(xiàn)服務(wù)的高吞吐量和低延遲。通過(guò)冗余專(zhuān)家部署和動(dòng)態(tài)路由策略,模型在推理時(shí)保持了高效的負(fù)載均衡。
整套部署方案下來(lái)基本是跨機(jī)分布式推理。
2.2.5.1 Prefill 階段
這個(gè)階段簡(jiǎn)單說(shuō)就是并行處理用戶(hù)的Prompt,將其轉(zhuǎn)為KV Cache。
預(yù)填充階段的最小部署單元由4個(gè)節(jié)點(diǎn)組成,每個(gè)節(jié)點(diǎn)配備32個(gè)GPU。注意力部分采用4路張量并行(TP4)和序列并行(SP),并結(jié)合8路數(shù)據(jù)并行(DP8)。其較小的TP規(guī)模(4路)限制了TP通信的開(kāi)銷(xiāo)。對(duì)于MoE部分,我們使用32路專(zhuān)家并行(EP32)
2.2.5.2 Decoder 階段
這個(gè)階段就是做自回歸的每個(gè)Token的輸出。
解碼階段的最小部署單元由40個(gè)節(jié)點(diǎn)和320個(gè)GPU組成。注意力部分采用TP4和SP,結(jié)合DP80,而MoE部分使用EP320。對(duì)于MoE部分,每個(gè)GPU只承載一個(gè)專(zhuān)家,64個(gè)GPU負(fù)責(zé)承載冗余專(zhuān)家和共享專(zhuān)家
總結(jié):為什么DeepSeekV3訓(xùn)練成本這么低?
訓(xùn)練成本主要由模型架構(gòu)以及訓(xùn)練架構(gòu)所決定,而且兩者一定是相輔相成。從報(bào)告中可以看出以下幾個(gè)原因:I.MLA 機(jī)制:通過(guò)對(duì)KV做聯(lián)合低秩壓縮大幅減少KV Cache,相比業(yè)界從KV數(shù)量角度做KV Cache的減少,MLA 的壓縮實(shí)現(xiàn)很考驗(yàn)研究團(tuán)隊(duì)的基本功。 II.FP8 訓(xùn)練:通過(guò)低精度計(jì)算減少了 GPU 內(nèi)存使用和計(jì)算開(kāi)銷(xiāo),技術(shù)報(bào)告中也提到FP8混合精度訓(xùn)練框架是首次在一個(gè)極大規(guī)模的模型上驗(yàn)證了其有效性,這一點(diǎn)也看出DeepSeek的Infra工程團(tuán)隊(duì)的底蘊(yùn)。 III.MoE 架構(gòu):通過(guò)MoE稀疏激活機(jī)制大幅減少了計(jì)算量,相比Qwen和Llama的Dense架構(gòu)有很大的訓(xùn)推先天優(yōu)勢(shì),不過(guò)難題(專(zhuān)家的負(fù)載、通信、路由)也給到了Infra工程團(tuán)隊(duì)。
三、為什么是DeepSeek?
在硅谷,類(lèi)似DeepSeek這樣的AI創(chuàng)新并不少有,只是這次是一家中國(guó)公司做出了這個(gè)動(dòng)作,相比傳統(tǒng)的‘美國(guó)創(chuàng)新、中國(guó)應(yīng)用’的模式顯得格外的讓人興奮。
從最近的一些訪(fǎng)談以及DeepSeek的技術(shù)報(bào)告中也能看出以下幾點(diǎn):
1、大模型是一個(gè)知識(shí)密集型產(chǎn)業(yè),如何組織高密度人才?顯然DeepSeek做到了
2、大模型技術(shù)沒(méi)有魔法,更多時(shí)候就是考驗(yàn)基本功和驅(qū)動(dòng)力
3、不以商業(yè)化為第一要義,很多時(shí)候能輕裝上陣
四、一些個(gè)人思考
1、長(zhǎng)遠(yuǎn)來(lái)看,后續(xù)可能會(huì)有專(zhuān)門(mén)的適配Transformer架構(gòu)的芯片,就像為卷積設(shè)計(jì)了ASIC芯片
2、多Token預(yù)測(cè)、MoE架構(gòu)可能很長(zhǎng)一段時(shí)間都是大模型訓(xùn)推架構(gòu)熱門(mén)研究方向
3、在國(guó)內(nèi)做AI,應(yīng)用始終會(huì)比基礎(chǔ)研究有市場(chǎng),更有話(huà)語(yǔ)權(quán),但是基礎(chǔ)創(chuàng)新和海外的代際差距會(huì)越來(lái)越小
4、大模型訓(xùn)練和推理,軟硬件是一個(gè)協(xié)同的生態(tài),DeepSeek的出現(xiàn)將會(huì)促進(jìn)AI全行業(yè)的更加快速且低成本的迭代
5、時(shí)間比較倉(cāng)促,很多技術(shù)細(xì)節(jié)問(wèn)題值得學(xué)習(xí)深究,有錯(cuò)誤的地方勿噴~
參考資料
1、Better & Faster Large Language Models via Multi-token Prediction?
2、https://kexue.fm/archives/10091?
3、https://arxiv.org/pdf/2404.19737v1?
4、https://arxiv.org/pdf/2412.19437?
5、https://arxiv.org/pdf/2405.04434?
6、https://www.zhihu.com/question/8423473404?
7、https://arxiv.org/pdf/1811.06965
-
人工智能
+關(guān)注
關(guān)注
1805文章
48899瀏覽量
247980 -
DeepSeek
+關(guān)注
關(guān)注
1文章
790瀏覽量
1555
原文標(biāo)題:漫談DeepSeek及其背后的核心技術(shù)
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【書(shū)籍評(píng)測(cè)活動(dòng)NO.62】一本書(shū)讀懂 DeepSeek 全家桶核心技術(shù):DeepSeek 核心技術(shù)揭秘
HarmonyOS NEXT開(kāi)發(fā)實(shí)戰(zhàn):DevEco Studio中DeepSeek的使用
RK3588開(kāi)發(fā)板上部署DeepSeek-R1大模型的完整指南
鴻蒙原生應(yīng)用開(kāi)發(fā)也可以使用DeepSeek了
惠倫晶體全面接入DeepSeek等大模型技術(shù)
淺談DeepSeek核心技術(shù)與應(yīng)用場(chǎng)景
添越智創(chuàng)基于 RK3588 開(kāi)發(fā)板部署測(cè)試 DeepSeek 模型全攻略
了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
移遠(yuǎn)通信邊緣計(jì)算模組成功運(yùn)行DeepSeek模型,以領(lǐng)先的工程能力加速端側(cè)AI落地

中控技術(shù)攜手DeepSeek大模型,共鑄工業(yè)數(shù)智化新篇章
DeepSeek在FPGA/IC領(lǐng)域的創(chuàng)新應(yīng)用及未來(lái)展望

在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
Meta組建四大專(zhuān)研小組,深入探索DeepSeek模型
從MCU到SoC:汽車(chē)芯片核心技術(shù)的深度剖析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論