") 一文速覽:人工智能(AI)算法與GPU運(yùn)行原理詳解
一文速覽:人工智能(AI)算法與GPU運(yùn)行原理詳解
本文介紹人工智能的發(fā)展歷程、CPU與GPU在AI中的應(yīng)用、CUDA架構(gòu)及并行計(jì)算優(yōu)化,以及未來趨勢(shì)。
一、人工智能發(fā)展歷程
當(dāng)今,人工智能(Artificial Intelligence)已經(jīng)深刻改變了人類生活的方方面面,并且在未來仍然會(huì)繼續(xù)發(fā)揮越來越重要的影響力?
“人工智能”這一概念在1956年于美國(guó)達(dá)特茅斯學(xué)院舉辦的一次學(xué)術(shù)集會(huì)上被首次提出,自此開啟了人工智能研究的新紀(jì)元?自此之后,人工智能在曲折中不斷發(fā)展前進(jìn)?
1986年,神經(jīng)網(wǎng)絡(luò)之父Geoffrey Hinton提出了適用于多層感知機(jī)(Multilayer Perceptron,MLP)的反向傳播(Back propagation,BP)算法,并且使用Sigmoid函數(shù)實(shí)現(xiàn)非線性映射,有效解決了非線性分類和學(xué)習(xí)問題?
1989年,YannLeCun設(shè)計(jì)了第一個(gè)卷積神經(jīng)網(wǎng)絡(luò),并將其成功應(yīng)用于手寫郵政編碼識(shí)別任務(wù)中?
20世紀(jì)90年代,Cortes等人提出支持向量機(jī)(SupportVector Machine, SVM)模型,隨后SVM迅速發(fā)展成為機(jī)器學(xué)習(xí)的代表性技術(shù)之一,在文本分類?手寫數(shù)字識(shí)別?人臉檢測(cè)和生物信息處理等方面取得了巨大成功?
進(jìn)入21世紀(jì),隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展與計(jì)算機(jī)硬件系統(tǒng)性能的提高,人工智能迎來了新的重大發(fā)展機(jī)遇?特別是2011年以來,以深度神經(jīng)網(wǎng)絡(luò)為代表的深度學(xué)習(xí)技術(shù)高速發(fā)展,人類在通向人工智能的道路上接連實(shí)現(xiàn)了許多重大突破?
二、CPU和GPU在人工智能中的應(yīng)用
GPU最初是用于圖像處理的,但由于高性能計(jì)算需求的出現(xiàn),GPU因其高度 并行的硬件結(jié)構(gòu)而得以顯著提升其并行計(jì)算和浮點(diǎn)計(jì)算能力,且性能遠(yuǎn)超于CPU。
由于訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)的計(jì)算強(qiáng)度非常大,因而在CPU上訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的時(shí)間往往非常長(zhǎng)?
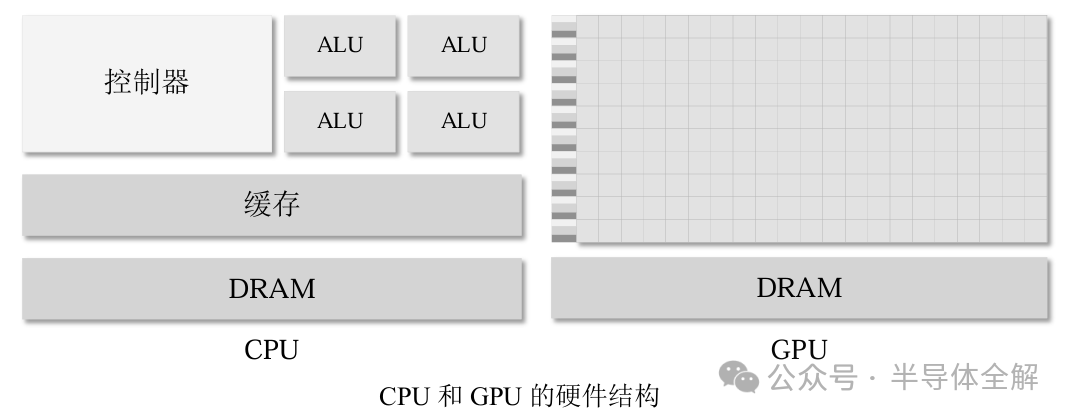
如圖所示,CPU主要由控制器、算數(shù)邏輯單元(Arithmetic and Logic Unit,ALU)和儲(chǔ)存單元三個(gè)主要部分組成,CPU的計(jì)算能力主要取決于計(jì)算核心ALU的數(shù)量,而ALU又大又重,使得CPU常用來處理具有復(fù)雜控制邏輯的串行程序以提高性能。
相比之下,GPU由許多SP(Streaming Processor,流處理器)和存儲(chǔ)系統(tǒng)組成,SP又被稱為CUDA核心,類似CPU中的ALU,若干個(gè)SP被組織成一個(gè)SM(Streaming Multiprocessors,流多處理器)。
GPU中的SP數(shù)量眾多且體積較小,這賦予了GPU強(qiáng)大的并行計(jì)算和浮點(diǎn)運(yùn)算能力,常用來優(yōu)化那些控制邏輯簡(jiǎn)單而數(shù)據(jù)并行性高的任務(wù),且側(cè)重于提高并行程序的吞吐量。
圖形處理器(GraphicsProcessing Unit, GPU)具有強(qiáng)大的單機(jī)并行處理能力,特別適合計(jì)算密集型任務(wù),已經(jīng)廣泛應(yīng)用于深度學(xué)習(xí)訓(xùn)練?
然而單個(gè)GPU的算力和存儲(chǔ)仍然是有限的,特別是對(duì)于現(xiàn)在的很多復(fù)雜深度學(xué)習(xí)訓(xùn)練任務(wù)來說,訓(xùn)練的數(shù)據(jù)集十分龐大,使用單個(gè)GPU訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)(DeepNeural Network ,DNN)模型需要漫長(zhǎng)的訓(xùn)練時(shí)間?
例如,使用一塊Nvidia M40 GPU在ImageNet-1K上訓(xùn)練ResNet-50 90個(gè)epoch需要14天時(shí)間?此外,近年來深度神經(jīng)網(wǎng)絡(luò)的模型參數(shù)規(guī)模急劇增加,出現(xiàn)了很多參數(shù)量驚人的“巨模型”?
由于在訓(xùn)練這些大規(guī)模DNN模型時(shí),無法將全部模型參數(shù)和激活值放入單個(gè)GPU中,因此無法在單GPU上訓(xùn)練這些超大規(guī)模DNN模型?
隨著計(jì)算機(jī)體系結(jié)構(gòu)的飛速發(fā)展,并行(Parallelism)已經(jīng)在現(xiàn)代的計(jì)算機(jī)體系結(jié)構(gòu)中廣泛存在,目前的計(jì)算機(jī)系統(tǒng)普遍具有多核或多機(jī)并行處理能力?
按照存儲(chǔ)方式的不同,并行計(jì)算機(jī)體系結(jié)構(gòu)通常分為兩種:共享存儲(chǔ)體系結(jié)構(gòu)和分布存儲(chǔ)體系結(jié)構(gòu)?
對(duì)于共享存儲(chǔ)體系結(jié)構(gòu),處理器通常包含多個(gè)計(jì)算核,通常可以支持多線程并行?然而由于存儲(chǔ)和算力的限制,使用單個(gè)計(jì)算設(shè)備上往往無法高效訓(xùn)練機(jī)器學(xué)習(xí)模型?多核集群系統(tǒng)是目前廣泛使用的多機(jī)并行計(jì)算平臺(tái),已經(jīng)在機(jī)器學(xué)習(xí)領(lǐng)域得到廣泛應(yīng)用?
多核集群系統(tǒng)通常以多核服務(wù)器為基本計(jì)算節(jié)點(diǎn),節(jié)點(diǎn)間則通過Infiniband高速互聯(lián)網(wǎng)絡(luò)互聯(lián)?此外,在深度學(xué)習(xí)訓(xùn)練領(lǐng)域,單機(jī)多卡(One Machine Multiple GPUs)和多機(jī)多卡(Multiple Machines Multiple GPUs)計(jì)算平臺(tái)也已經(jīng)發(fā)展成為并行訓(xùn)練神經(jīng)網(wǎng)絡(luò)的主流計(jì)算平臺(tái)?
消息傳遞接口(MessagePassing Interface, MPI)在分布式存儲(chǔ)系統(tǒng)上是被廣泛認(rèn)可的理想程序設(shè)計(jì)模型,也為機(jī)器學(xué)習(xí)模型的并行與分布式訓(xùn)練提供了通信技術(shù)支撐?機(jī)器學(xué)習(xí)模型并行訓(xùn)練的本質(zhì)是利用多個(gè)計(jì)算設(shè)備協(xié)同并行訓(xùn)練機(jī)器學(xué)習(xí)模型?
機(jī)器學(xué)習(xí)模型的并行訓(xùn)練過程一般是,首先將訓(xùn)練數(shù)據(jù)或模型部署到多個(gè)計(jì)算設(shè)備上,然后通過這些計(jì)算設(shè)備協(xié)同并行工作來加速訓(xùn)練模型?
機(jī)器學(xué)習(xí)模型的并行訓(xùn)練通常適用于以下兩種情況:
(1)當(dāng)模型可以載入到單個(gè)計(jì)算設(shè)備時(shí),訓(xùn)練數(shù)據(jù)非常多,使用單個(gè)計(jì)算設(shè)備無法在可接受的時(shí)間內(nèi)完成模型訓(xùn)練;
(2)模型參數(shù)規(guī)模非常大,無法將整個(gè)模型載入到單個(gè)計(jì)算設(shè)備上;機(jī)器學(xué)習(xí)模型并行訓(xùn)練的目的往往是為了加速模型訓(xùn)練,機(jī)器學(xué)習(xí)模型訓(xùn)練的總時(shí)間往往是由單次迭代或者單個(gè)epoch的計(jì)算時(shí)間與收斂速度共同作用的結(jié)果?訓(xùn)練模型使用的優(yōu)化算法決定了收斂速度,而使用合適的并行訓(xùn)練模式則可以加快單次迭代或者單個(gè)epoch的計(jì)算?在并行訓(xùn)練機(jī)器學(xué)習(xí)模型時(shí),首先要把數(shù)據(jù)分發(fā)到多個(gè)不同的計(jì)算設(shè)備上?
按照數(shù)據(jù)分發(fā)方式的不同,模型的并行訓(xùn)練模式一般可以分為數(shù)據(jù)并行?模型并行和流水線并行?
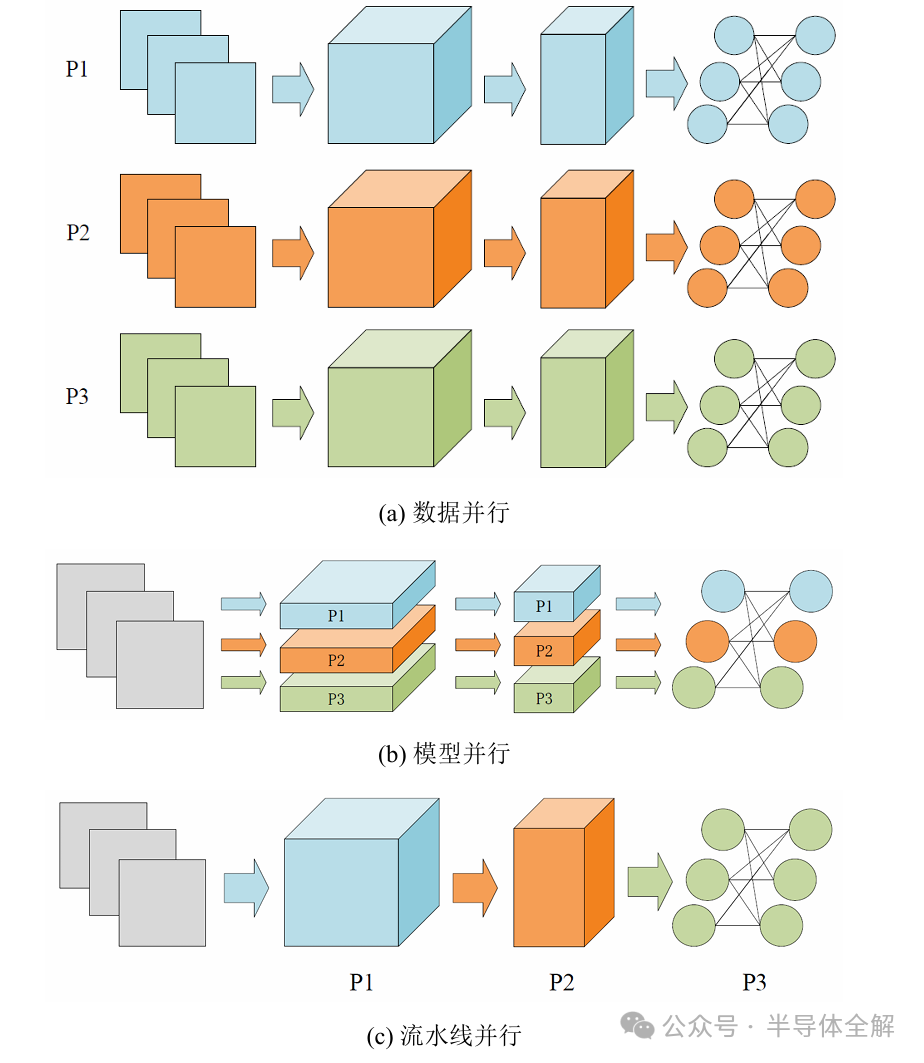
上圖是三種并行訓(xùn)練模式的示意圖?
數(shù)據(jù)并行(DataParallelism)是當(dāng)前最流行的DNN并行訓(xùn)練方法?
當(dāng)前流行的許多深度學(xué)習(xí)框架如Tensor Flow, PyTorch和Horovod等都提供了方便使用的API來支持?jǐn)?shù)據(jù)并行?
如圖(a)所示,在數(shù)據(jù)并行中,每個(gè)計(jì)算設(shè)備都擁有全部的并且完全一致的模型參數(shù),然后被分配到不同的批處理訓(xùn)練數(shù)據(jù)?當(dāng)所有計(jì)算設(shè)備上的梯度通過參數(shù)服務(wù)器或者Allreduce這樣的集合通信操作來實(shí)現(xiàn)求和之后,模型參數(shù)才會(huì)更新?
深度神經(jīng)網(wǎng)絡(luò)通常是由很多層神經(jīng)元連續(xù)堆疊而成,每一層神經(jīng)元形成了全連接層(Fully Connected Layers)?卷積層(Convolutional Layers)等不同類型的運(yùn)算子(Operator)?
傳統(tǒng)的模型并行(ModelParallelism)是將神經(jīng)網(wǎng)絡(luò)模型水平切分成不同的部分,然后分發(fā)到不同的計(jì)算設(shè)備上?
如圖(b)所示,模型并行是將不同運(yùn)算子的數(shù)據(jù)流圖(Data flow Graph)切分并存儲(chǔ)在多個(gè)計(jì)算設(shè)備上,同時(shí)保證這些運(yùn)算子作用于同一個(gè)批處理訓(xùn)練數(shù)據(jù)?由于這種切分是將運(yùn)算子從水平層次進(jìn)行切分,因此通常模型并行也稱為運(yùn)算子并行(Operator Parallelism)或水平并行(Horizontal Parallelism)?
當(dāng)把神經(jīng)網(wǎng)絡(luò)模型按層進(jìn)行垂直切分時(shí),模型并行可進(jìn)一步歸類為流水線并行(Pipeline Parallelism)?如圖(c)所示,流水線并行是將神經(jīng)網(wǎng)絡(luò)按層切分成多個(gè)段(Stage),每個(gè)Stage由多個(gè)連續(xù)的神經(jīng)網(wǎng)絡(luò)層組成?然后所有Stage被分配到不同的計(jì)算設(shè)備上,這些計(jì)算設(shè)備以流水線方式并行地訓(xùn)練?神經(jīng)網(wǎng)絡(luò)的前向傳播從第一個(gè)計(jì)算設(shè)備開始,向后做前向傳播,直到最后一個(gè)計(jì)算設(shè)備完成前向傳播?隨后,神經(jīng)網(wǎng)絡(luò)的反向傳播過程從最后一個(gè)計(jì)算設(shè)備開始,向前做反向傳播,直到第一個(gè)計(jì)算設(shè)備完成反向傳播?
在算法加速方面,目前加速算法的研究主要是利用不同平臺(tái)的計(jì)算能力完成?主流的加速平臺(tái)包括專用集成電路(Application Specific Integrated Circuit, ASIC)?現(xiàn)場(chǎng)可編程邏輯門陣列(Field-Programmable Gate Array, FPGA)芯片和圖形處理器(Graphics Processing Unit, GPU)等?
其中,ASIC芯片定制化程度較高,設(shè)計(jì)開發(fā)周期長(zhǎng),難以應(yīng)對(duì)迅速變化的市場(chǎng)需求;FPGA芯片是一種可編程的集成電路芯片,自由度相對(duì)較高,投入使用比ASIC快,成本與ASIC相比較低,但是由于FPGA芯片仍屬于硬件并行設(shè)計(jì)的范疇,通用性和成本與GPU相比欠佳?
三、什么是CUDA?
CUDA(ComputeUnified Device Architecture)全稱統(tǒng)一計(jì)算架構(gòu),作為NIVIDA公司官方提出的GPU編程模型,它提供了相關(guān)接口讓開發(fā)者可以使用GPU完成通用計(jì)算的加速設(shè)計(jì),能夠更加簡(jiǎn)單便捷地構(gòu)建基于GPU的應(yīng)用程序,充分發(fā)揮GPU的高效計(jì)算能力和并行能力?
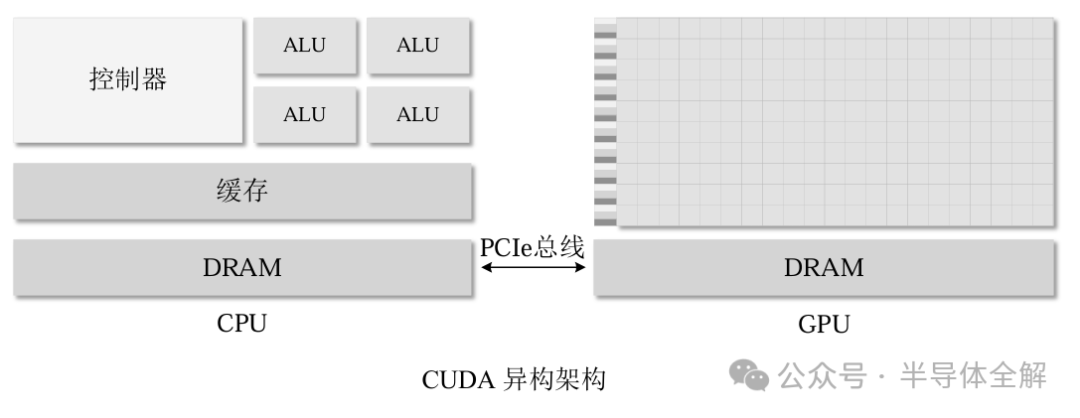
CUDA同時(shí)支持C/C++,Python等多種編程語言,使得并行算法具有更高的可行性?由于GPU不是可以獨(dú)立運(yùn)行的計(jì)算平臺(tái),因此在使用CUDA編程時(shí)需要與CPU協(xié)同實(shí)現(xiàn),形成一種CPU+GPU的異構(gòu)計(jì)算架構(gòu),其中CPU被稱為主機(jī)端(Host),GPU被稱為設(shè)備端(Device)?
GPU主要負(fù)責(zé)計(jì)算功能,通過并行架構(gòu)與強(qiáng)大的運(yùn)算能力對(duì)CPU指派的計(jì)算任務(wù)進(jìn)行加速。通過 CPU/GPU 異構(gòu)架構(gòu)和CUDA C語言,可以充分利用GPU資源來加速一些算法。
典型的GPU體系結(jié)構(gòu)如下圖所示,GPU和CPU的主存都是采用DRAM實(shí)現(xiàn),存儲(chǔ)結(jié)構(gòu)也十分類似?但是CUDA將GPU內(nèi)存更好地呈現(xiàn)給程序員,提高了GPU編程的靈活性?

CUDA程序?qū)崿F(xiàn)并行優(yōu)化程序設(shè)計(jì)的具體流程主要分為三個(gè)步驟:
1?將數(shù)據(jù)存入主機(jī)端內(nèi)存并進(jìn)行初始化,申請(qǐng)?jiān)O(shè)備端內(nèi)存空間并將主機(jī)端的數(shù)據(jù)裝載到設(shè)備端內(nèi)存中;
2?調(diào)用核函數(shù)在設(shè)備端執(zhí)行并行算法,核函數(shù)是指在GPU中運(yùn)行的程序,也被稱為kernel函數(shù)?
3?將算法的最終運(yùn)行結(jié)果從設(shè)備端內(nèi)存卸載到主機(jī)端,最后釋放設(shè)備端和主機(jī)端的所有內(nèi)存?
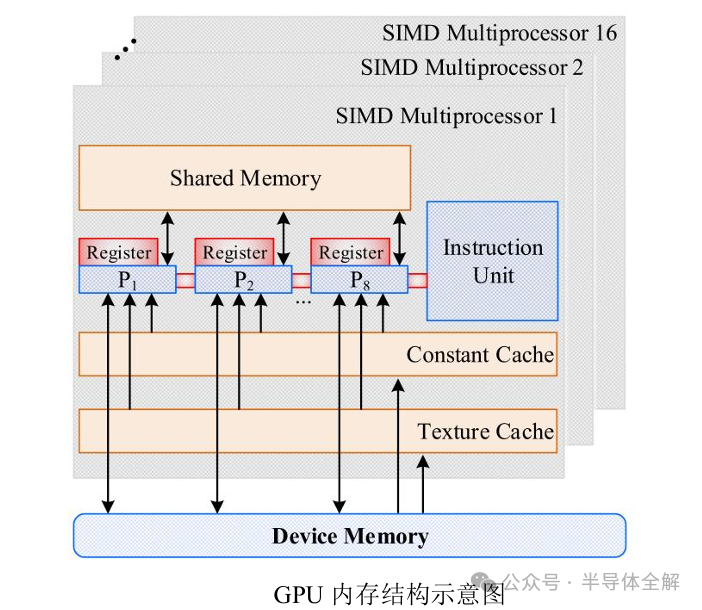
GPU的核心組件是流式多處理器(Streaming Multiprocessor,簡(jiǎn)稱SM),也被稱為GPU大核,一個(gè)GPU設(shè)備含有多個(gè)SM硬件,SM的組件包括CUDA核心,共享內(nèi)存和寄存器等?
其中,CUDA核心(CUDA core)是GPU最基本的處理單元,具體的指令和任務(wù)都是在這個(gè)核心上處理的,本質(zhì)上GPU在執(zhí)行并行程序的時(shí)候,是在使用多個(gè)SM同時(shí)處理不同的線程?而共享內(nèi)存和寄存器是SM內(nèi)部最重要的資源,在很大程度上GPU的并行能力就取決于SM中的資源分配能力?
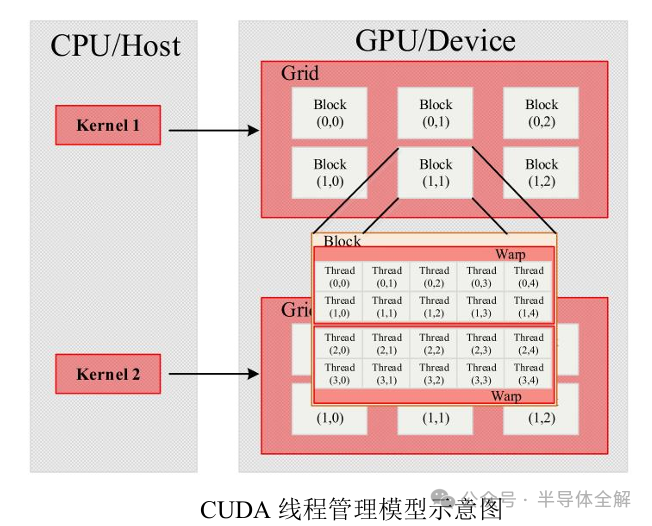
在CUDA架構(gòu)中,網(wǎng)格(Grid),塊(Block)和線程(Thread)是三個(gè)十分重要的軟件概念,其中線程負(fù)責(zé)執(zhí)行具體指令的運(yùn)行任務(wù),線程塊由多個(gè)線程組成,網(wǎng)格由多個(gè)線程塊組成,線程和線程塊的數(shù)量都可以通過程序的具體實(shí)現(xiàn)設(shè)定?
GPU在執(zhí)行核函數(shù)時(shí)會(huì)以一個(gè)網(wǎng)格作為執(zhí)行整體,將其劃分成多個(gè)線程塊,再將線程塊分配給SM執(zhí)行計(jì)算任務(wù)?
GPU內(nèi)存結(jié)構(gòu)如下圖所示,主要包括位于SP內(nèi)部的寄存器(Register)?位于SM上的共享內(nèi)存(Shared memory)和GPU板載的全局內(nèi)存(Global memory)?
在NVIDIA提出的CUDA統(tǒng)一編程模型中采用Grid的方式管理GPU上的全部線程,每個(gè)Grid中又包含多個(gè)線程塊(Block),每個(gè)Block中又可以劃分成若干個(gè)線程組(Warp)?Warp是GPU線程管理的最小單位,Warp內(nèi)的線程采用單指令多線程(Single Instruction MultipleThreads, SIMT)的執(zhí)行模式?
CUDA線程管理的基本結(jié)構(gòu)如下圖所示:
GPU獨(dú)特的體系架構(gòu)和強(qiáng)大的并行編程模型,使得GPU在并行計(jì)算和內(nèi)存訪問帶寬方面具有獨(dú)特的性能優(yōu)勢(shì)?
相對(duì)于傳統(tǒng)的CPU體系結(jié)構(gòu),GPU具有一些獨(dú)特的優(yōu)勢(shì):
1)并行度高?計(jì)算能力強(qiáng)?相對(duì)于CPU體系結(jié)構(gòu),GPU內(nèi)部集成了更多的并行計(jì)算單元,使得GPU在并行計(jì)算能力方面的表現(xiàn)更加出色?同時(shí),其理論計(jì)算峰值也遠(yuǎn)高于同時(shí)期CPU,當(dāng)前NVIDIA A100 GPU在執(zhí)行Bert推理任務(wù),其推理速度可達(dá)2個(gè)Intel至強(qiáng)金牌6240CPU的249倍6?
2)訪存帶寬高?為了匹配GPU超強(qiáng)的并行能力,GPU內(nèi)部設(shè)置了大量訪存控制器和性能更強(qiáng)的內(nèi)部互聯(lián)網(wǎng)絡(luò),導(dǎo)致GPU具有更高的內(nèi)存訪問帶寬?當(dāng)前NVIDIAA100 GPU的內(nèi)存帶寬可達(dá)1.94TB/s,而同期Intel至強(qiáng)金牌6248 CPU僅為137GB/s?圖處理由于其計(jì)算訪存比高,算法執(zhí)行過程中計(jì)算次數(shù)多?單次計(jì)算量小的特點(diǎn)天然地與GPU的硬件特征相匹配?
四、總結(jié)
隨著深度學(xué)習(xí)(DeepLearning,DL)的持續(xù)進(jìn)步,各類深度神經(jīng)網(wǎng)絡(luò)(DeepNeural Network ,DNN)模型層出不窮?DNN不僅在精確度上大幅超越傳統(tǒng)模型,其良好的泛化性也為眾多領(lǐng)域帶來了新的突破?
因此,人工智能(Artificial Intelligence, AI)技術(shù)得以迅速應(yīng)用于各個(gè)行業(yè)?如今,無論是在物聯(lián)網(wǎng)(Intemet of Things, IoT)的邊緣設(shè)備,還是數(shù)據(jù)中心的高性能服務(wù)器,DNN的身影隨處可見,人工智能的發(fā)展離不開計(jì)算能力的提升,因此高性能GPU的需求也將不斷提升!
參考文獻(xiàn):
(1)楊翔 深度學(xué)習(xí)模型的并行推理加速技術(shù)研究[D]。
(2)鄭志高 GPU上圖處理算法優(yōu)化關(guān)鍵技術(shù)研究[D]。
(3)關(guān)磊 機(jī)器學(xué)習(xí)模型并行訓(xùn)練關(guān)鍵技術(shù)研究[D]。
(4)薛圣瓏 機(jī)載預(yù)警雷達(dá)雜波快速生成及GPU實(shí)現(xiàn)研究[D]。
(5)韓吉昌 基于CUDA的國(guó)密算法SM3和SM4的設(shè)計(jì)與實(shí)現(xiàn)[D].
-
gpu
+關(guān)注
關(guān)注
28文章
4921瀏覽量
130812 -
AI
+關(guān)注
關(guān)注
88文章
34588瀏覽量
276164 -
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247405
原文標(biāo)題:一文了解人工智能(AI)算法及GPU運(yùn)行原理
文章出處:【微信號(hào):bdtdsj,微信公眾號(hào):中科院半導(dǎo)體所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
開售RK3576 高性能人工智能主板
AI人工智能隱私保護(hù)怎么樣

一文速覽 30KPA48A:快速響應(yīng),為電路安全保駕護(hù)航

人工智能和機(jī)器學(xué)習(xí)以及Edge AI的概念與應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論