") TeleAI提出COPO對(duì)齊方法:8B模型超越Llama3-70B的表現(xiàn)
TeleAI提出COPO對(duì)齊方法:8B模型超越Llama3-70B的表現(xiàn)
在自然界中,好奇心驅(qū)使著生物探索未知,是生存和進(jìn)化的關(guān)鍵。人類,作為地球上最具智能的物種,其探索精神引領(lǐng)了科技、文化和社會(huì)的進(jìn)步。1492 年,哥倫布懷揣探索未知的理想,勇敢地向西航行,最終發(fā)現(xiàn)了新大陸。
正如人類在面對(duì)未知時(shí)展現(xiàn)出的探索行為,在人工智能領(lǐng)域,尤其在大型語(yǔ)言模型(LLMs)理解語(yǔ)言和知識(shí)中,研究人員正嘗試賦予 LLM 類似的探索能力,從而突破其在給定數(shù)據(jù)集中學(xué)習(xí)的能力邊界,進(jìn)一步提升性能和安全性。
近期,中國(guó)電信集團(tuán) CTO、首席科學(xué)家、中國(guó)電信人工智能研究院(TeleAI)院長(zhǎng)李學(xué)龍教授帶領(lǐng)團(tuán)隊(duì)在全模態(tài)星辰大模型體系深耕的基礎(chǔ)之上,聯(lián)合清華大學(xué)、香港城市大學(xué)、上海人工智能實(shí)驗(yàn)室等單位提出了一種新的探索驅(qū)動(dòng)的大模型對(duì)齊方法 Count-based Online Preference Optimization(COPO)。
該工作將人類探索的本能融入到大語(yǔ)言模型的后訓(xùn)練(Post-Training)中,引導(dǎo)模型在人類反饋強(qiáng)化學(xué)習(xí)(RLHF)框架下主動(dòng)探索尚未充分理解的知識(shí),解決了現(xiàn)有對(duì)齊框架受限于偏好數(shù)據(jù)集覆蓋范圍的問(wèn)題。
這一創(chuàng)新成果為智傳網(wǎng)(AI Flow)中 “基于連接與交互的智能涌現(xiàn)” 提供了重要技術(shù)支撐,使得模型在動(dòng)態(tài)交互中不斷學(xué)習(xí)和進(jìn)步,在探索的過(guò)程中實(shí)現(xiàn)智能的持續(xù)涌現(xiàn)。論文被國(guó)際表征學(xué)習(xí)大會(huì) ICLR 2025 錄用,實(shí)現(xiàn)了大模型多輪交互探索中的能力持續(xù)提升。TeleAI 研究科學(xué)家白辰甲為論文的第一作者。

論文標(biāo)題:
Online Preference Alignment for Language Models via Count-based Exploration
論文地址:
https://arxiv.org/abs/2501.12735
代碼地址:
https://github.com/Baichenjia/COPO
研究動(dòng)機(jī)
雖然大型語(yǔ)言模型(LLM)在進(jìn)行多種語(yǔ)言任務(wù)中已經(jīng)有出色的表現(xiàn),但它們?cè)谂c人類價(jià)值觀和意圖對(duì)齊方面仍面臨著很多挑戰(zhàn)。現(xiàn)有的大模型 RLHF 框架主要依賴于預(yù)先收集的偏好數(shù)據(jù)集進(jìn)行對(duì)齊,其性能受限于離線偏好數(shù)據(jù)集對(duì)提示 - 回復(fù)(Prompt-Response)的覆蓋范圍,對(duì)數(shù)據(jù)集覆蓋之外的語(yǔ)言難以進(jìn)行有效泛化。
然而,人類偏好數(shù)據(jù)集的收集是較為昂貴的,且現(xiàn)有的偏好數(shù)據(jù)難以覆蓋所有可能的提示和回復(fù)。這就引出了一個(gè)關(guān)鍵問(wèn)題:是否可以使 LLM 在對(duì)齊過(guò)程中對(duì)語(yǔ)言空間進(jìn)行自主探索,從而突破離線數(shù)據(jù)集的約束,不斷提升泛化能力?
為了解決這一問(wèn)題,近期的大模型相關(guān)研究開(kāi)始由人類反饋強(qiáng)化學(xué)習(xí)驅(qū)動(dòng)的離線對(duì)齊(Offline RLHF)轉(zhuǎn)向在線對(duì)齊(Online RLHF),通過(guò)迭代式地收集提示和回復(fù),允許大模型在與語(yǔ)言環(huán)境的互動(dòng)中不斷學(xué)習(xí)和進(jìn)步,從而在偏好數(shù)據(jù)集的覆蓋之外進(jìn)行探索。
本研究旨在解決在線 RLHF 過(guò)程中的核心問(wèn)題:如何使 LLM 高效在語(yǔ)言空間(類比于強(qiáng)化學(xué)習(xí)動(dòng)作空間)中進(jìn)行探索。
具體地,強(qiáng)化學(xué)習(xí)算法在進(jìn)行大規(guī)模的狀態(tài)動(dòng)作空間(類比于 LLM 中的語(yǔ)言生成空間)中的最優(yōu)策略求解時(shí),系統(tǒng)性探索(Systematic Exploration)對(duì)于收集有益的經(jīng)驗(yàn)至關(guān)重要,會(huì)直接關(guān)系到策略學(xué)習(xí)的效果。在 LLM 對(duì)齊中,如果缺乏有效的探索機(jī)制,可能會(huì)導(dǎo)致模型對(duì)齊陷入局部最優(yōu)策略。
同時(shí),有效的探索可以幫助大模型更好地理解語(yǔ)言環(huán)境的知識(shí),從而在廣闊的語(yǔ)言空間中找到最優(yōu)回復(fù)策略。
本研究的目標(biāo)在于解決在線 RLHF 中的探索問(wèn)題,即如何在每次迭代中有效地探索提示 - 回復(fù)空間,以擴(kuò)大偏好數(shù)據(jù)覆蓋范圍,提高模型對(duì)人類偏好的學(xué)習(xí)和適應(yīng)能力。具體地,COPO 算法通過(guò)結(jié)合基于計(jì)數(shù)的探索(Count-based Exploration)和直接偏好優(yōu)化(DPO)框架,利用一個(gè)輕量級(jí)的偽計(jì)數(shù)模塊來(lái)平衡探索和偏好優(yōu)化,并在線性獎(jiǎng)勵(lì)函數(shù)近似和離散狀態(tài)空間中提供了理論框架。
實(shí)驗(yàn)中,在 Zephyr 和 Llama-3 模型上進(jìn)行的 RLHF 實(shí)驗(yàn)結(jié)果表明,COPO 在指令遵循和學(xué)術(shù)基準(zhǔn)測(cè)試中的性能優(yōu)于其他 RLHF 基線。
理論框架、
研究的理論框架基于大模型獎(jiǎng)勵(lì)的線性假設(shè),將獎(jiǎng)勵(lì)函數(shù)簡(jiǎn)化為參數(shù)向量和特征向量的內(nèi)積形式。在此假設(shè)下,可以將復(fù)雜大模型對(duì)語(yǔ)言提取的特征作為一個(gè)低維的向量,將 RLHF 過(guò)程中構(gòu)建的顯式或隱式的大模型獎(jiǎng)勵(lì)視為向量的線性函數(shù),具體地:

在此基礎(chǔ)上,給定大模型偏好數(shù)據(jù)集 ,在現(xiàn)有 Bradley-Terry (BT) 獎(jiǎng)勵(lì)模型的基礎(chǔ)上可以通過(guò)極大似然估計(jì)來(lái)估計(jì)獎(jiǎng)勵(lì)模型的參數(shù),即:
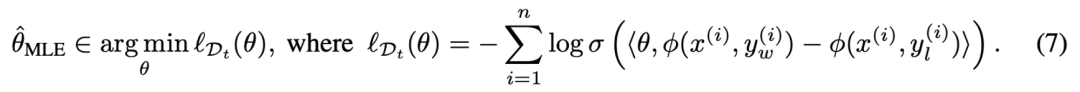
隨后,根據(jù)統(tǒng)計(jì)學(xué)中的相關(guān)理論,可以定量地為獎(jiǎng)勵(lì)模型提供了一個(gè)明確的誤差界限,并得到關(guān)于獎(jiǎng)勵(lì)模型參數(shù)的置信集合(confidence set),從而使估計(jì)的參數(shù)以較大概率落在置信集合中。具體地:
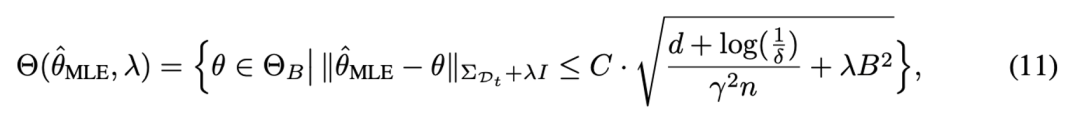
隨后,在參數(shù)集合中可以使用樂(lè)觀的期望值函數(shù)來(lái)獲得值函數(shù)估計(jì)的置信上界,從而實(shí)現(xiàn)了強(qiáng)化學(xué)習(xí)探中的樂(lè)觀原則(Optimism), 使大模型策略向樂(lè)觀方向進(jìn)行策略優(yōu)化。
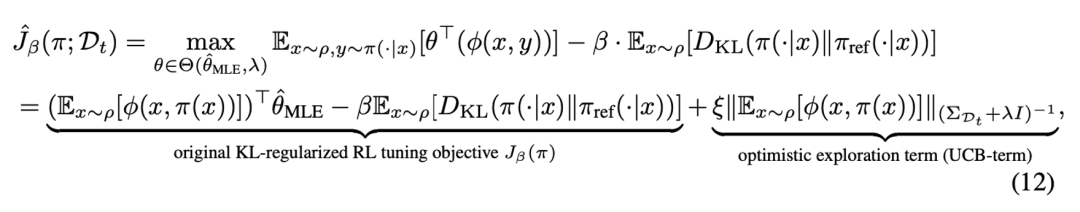
在上述目標(biāo)中,最終的優(yōu)化項(xiàng)包含兩個(gè)部分:第一部分對(duì)應(yīng)于經(jīng)典的兩階段 RLHF 方法,在 BT 模型的基礎(chǔ)上估計(jì)獎(jiǎng)勵(lì),通過(guò)最大化獎(jiǎng)勵(lì)來(lái)學(xué)習(xí)策略,同時(shí)保持和原始大模型策略的接近性約束。第二部分為新引入的置信區(qū)間上界(UCB)項(xiàng),用于測(cè)量當(dāng)前數(shù)據(jù)集對(duì)目標(biāo)策略生成的狀態(tài)分布的覆蓋程度,鼓勵(lì)模型探索那些尚未充分探索的語(yǔ)言空間。
具體來(lái)說(shuō),UCB 項(xiàng)通過(guò)增加對(duì)較少產(chǎn)生的提問(wèn) - 回答的組合的對(duì)數(shù)似然,從而鼓勵(lì)大模型生成新的、可能更優(yōu)的回答。這將有助于大模型在最大化獎(jiǎng)勵(lì)和探索新響應(yīng)之間的權(quán)衡,即著名的強(qiáng)化學(xué)習(xí)探索 - 利用權(quán)衡(exploration-exploitation trade-off)。
最終,研究證明了采用 COPO 算法的在線學(xué)習(xí)范式能夠在 T 次迭代后,將總后悔值限制在 O (√T) 的量級(jí)內(nèi),顯示了算法在處理大規(guī)模狀態(tài)空間時(shí)的效率和穩(wěn)定性。

算法設(shè)計(jì)
在理論框架下,具體的算法設(shè)計(jì)中結(jié)合了直接偏好優(yōu)化(DPO)的算法框架。其中第一項(xiàng)對(duì)獎(jiǎng)勵(lì)的構(gòu)建和獎(jiǎng)勵(lì)最大化的學(xué)習(xí)具象化為 DPO 的學(xué)習(xí)目標(biāo),而將樂(lè)觀探索的 UCB 項(xiàng)轉(zhuǎn)化為更容易求解的目標(biāo)。具體地,在有限狀態(tài)動(dòng)作空間的假設(shè)下,樂(lè)觀探索項(xiàng)可以表示為基于狀態(tài) - 動(dòng)作計(jì)數(shù)(Count)的學(xué)習(xí)目標(biāo),即:
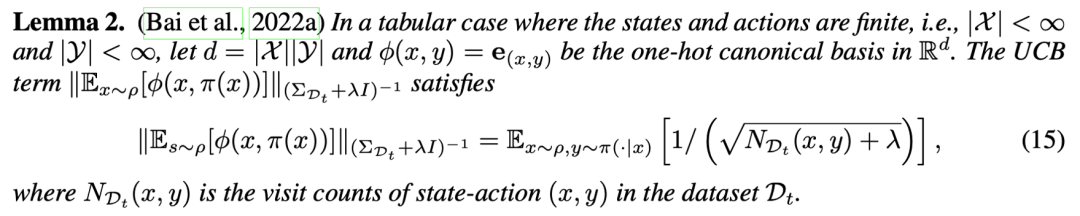
從而,最終的學(xué)習(xí)目標(biāo)表示為 DPO 獎(jiǎng)勵(lì)和基于提示 - 回答計(jì)數(shù)的探索目標(biāo)。具體地:
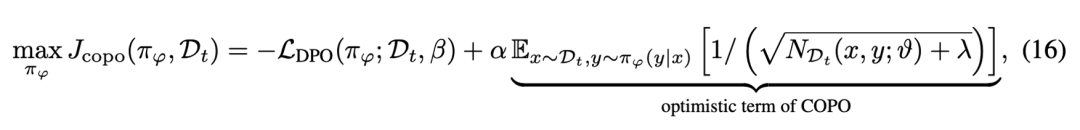
上式中第二項(xiàng)通過(guò)在偏好數(shù)據(jù)中對(duì)模型產(chǎn)生的提示 - 回答進(jìn)行計(jì)數(shù),可以鼓勵(lì)增加對(duì)之前出現(xiàn)次數(shù)較少的提示 - 回答的探索來(lái)鼓勵(lì)大模型突破離線數(shù)據(jù)集的覆蓋,使模型主動(dòng)探索新的、可能更優(yōu)的回復(fù),從而在迭代過(guò)程中擴(kuò)大數(shù)據(jù)覆蓋范圍并提高策略的性能。
進(jìn)而可以通過(guò)求解梯度的方式進(jìn)一步的解析 COPO 優(yōu)化目標(biāo)的意義:
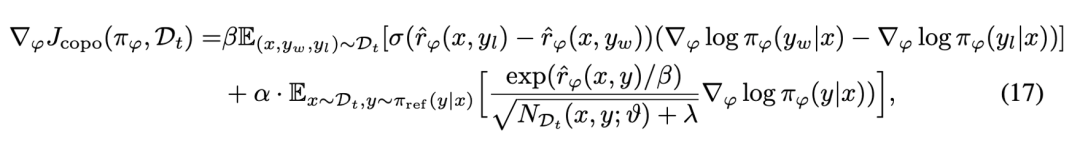
由兩部分組成:第一部分負(fù)責(zé)優(yōu)化模型以最大化偏好數(shù)據(jù)上的預(yù)期獎(jiǎng)勵(lì);第二部分對(duì)應(yīng)于探索項(xiàng)的梯度,它根據(jù)提示 - 回復(fù)對(duì)的歷史訪問(wèn)次數(shù)來(lái)調(diào)整模型的優(yōu)化方向。
當(dāng)某個(gè)回復(fù)的歷史訪問(wèn)次數(shù)較少時(shí),該項(xiàng)會(huì)推動(dòng)模型增加生成該回復(fù)的對(duì)數(shù)似然,從而鼓勵(lì)模型探索那些較少被訪問(wèn)但可能帶來(lái)更高獎(jiǎng)勵(lì)的區(qū)域,使算法能夠在最大化獎(jiǎng)勵(lì)的同時(shí)有效地平衡探索與利用,實(shí)現(xiàn)更優(yōu)的策略學(xué)習(xí)。
然而,在對(duì)大模型進(jìn)行上述目標(biāo)優(yōu)化中,往往無(wú)法在大規(guī)模語(yǔ)言空間中實(shí)現(xiàn)對(duì) “提示 - 回復(fù)” 的準(zhǔn)確 “計(jì)數(shù)”。語(yǔ)言空間的狀態(tài)通常是無(wú)限的,且完全相同的回復(fù)很少被多次產(chǎn)生,因此需要一種方法來(lái)估計(jì)或模擬這些提示 - 回復(fù)對(duì)的 “偽計(jì)數(shù)”,以便算法能夠在探索較少訪問(wèn)的區(qū)域時(shí)獲得激勵(lì)。
在此基礎(chǔ)上,COPO 提出使用 Coin Flipping Network(CFN)來(lái)高效的實(shí)現(xiàn)偽計(jì)數(shù)。CFN 不依賴于復(fù)雜的密度估計(jì)或?qū)δP图軜?gòu)和訓(xùn)練過(guò)程的限制,而是通過(guò)一個(gè)簡(jiǎn)單的回歸問(wèn)題來(lái)預(yù)測(cè)基于計(jì)數(shù)的探索獎(jiǎng)勵(lì)。
具體地,CFN 基于的基本假設(shè)是,計(jì)數(shù)可以通過(guò)從 Rademacher 分布的采樣來(lái)估計(jì)來(lái)得到,考慮從 {-1,1} 的集合中近似隨機(jī)采樣得到的分布,如果進(jìn)行 n 次采樣并對(duì)采樣結(jié)果取平均,則該變量的二階矩和計(jì)數(shù)的倒數(shù)呈現(xiàn)出等價(jià)的關(guān)系,即:
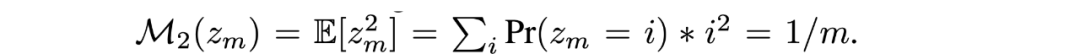
進(jìn)而,CFN 通過(guò)在每次遇到狀態(tài)時(shí)進(jìn)行 Rademacher 試驗(yàn)(即硬幣翻轉(zhuǎn)),并利用這些試驗(yàn)的平均值來(lái)推斷狀態(tài)的訪問(wèn)頻率。在實(shí)現(xiàn)中,CFN 表示為一個(gè)輕量化的網(wǎng)絡(luò),它通過(guò)最小化預(yù)測(cè)值和實(shí)際 Rademacher 標(biāo)簽之間的均方誤差來(lái)進(jìn)行訓(xùn)練。
在實(shí)現(xiàn)中,CFN 接受由主語(yǔ)言模型提取的提示 - 回復(fù)對(duì)的最后隱藏狀態(tài)作為輸入,并輸出一個(gè)預(yù)測(cè)值,該值與狀態(tài)的 “偽計(jì)數(shù)” 成反比。通過(guò)這種方式,CFN 能夠?yàn)槊總€(gè)提示 - 響應(yīng)提供一個(gè)探索激勵(lì),鼓勵(lì)模型在探索迭代中擴(kuò)大數(shù)據(jù)覆蓋范圍,提高模型對(duì)齊的性能。
實(shí)驗(yàn)結(jié)果
在實(shí)驗(yàn)中使用 UltraFeedback 60K 偏好數(shù)據(jù)集來(lái)對(duì) Zephyr-7B 和 Llama3-8B 模型進(jìn)行微調(diào),數(shù)據(jù)集中包含豐富的單輪對(duì)話偏好對(duì)的數(shù)據(jù)。
實(shí)驗(yàn)中使用了一個(gè)小型的獎(jiǎng)勵(lì)模型 PairRM 0.4B 來(lái)對(duì)多輪迭代過(guò)程中模型模型生成的回復(fù)進(jìn)行偏好排序,從而在探索中利用不斷更新后的大模型來(lái)產(chǎn)生不斷擴(kuò)充的偏好數(shù)據(jù),提升了數(shù)據(jù)集的質(zhì)量和覆蓋率。
此外,實(shí)驗(yàn)中使用輕量化的 CFN 網(wǎng)絡(luò)實(shí)現(xiàn)對(duì)提示 - 響應(yīng)對(duì)的偽計(jì)數(shù),大幅提升了在線 RLHF 算法的探索能力。
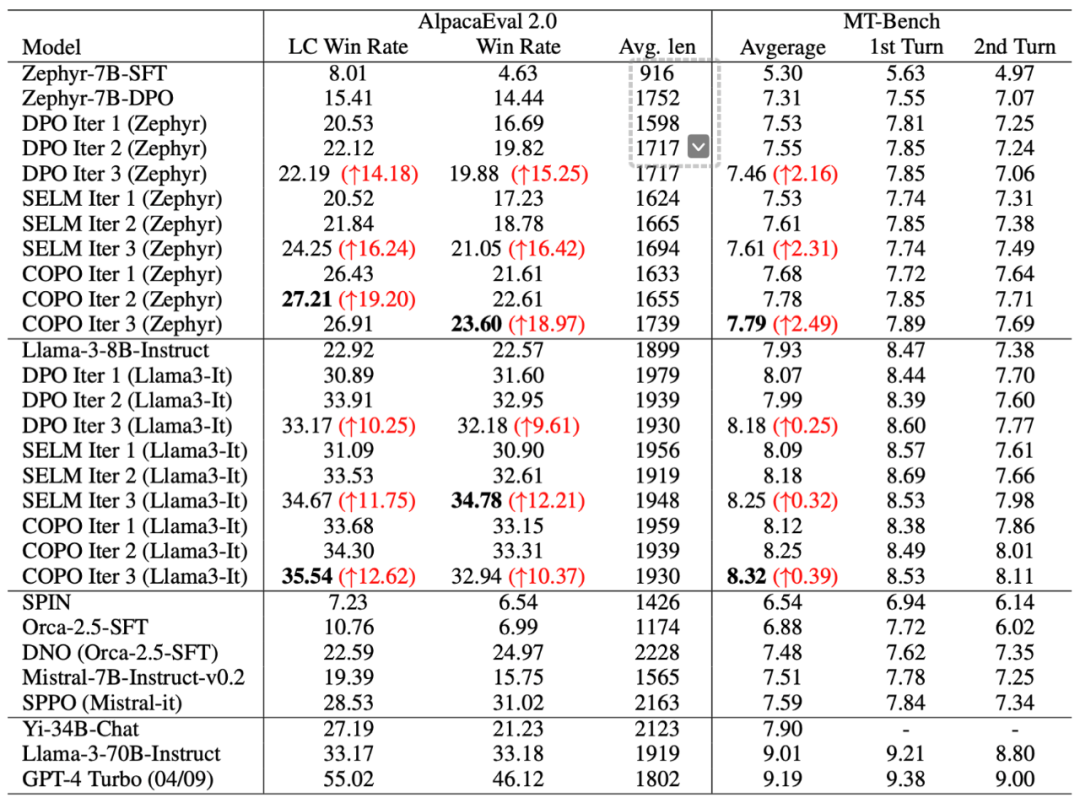
實(shí)驗(yàn)結(jié)果表明,COPO 算法在 AlpacaEval 2.0 和 MT-Bench 基準(zhǔn)測(cè)試可以通過(guò)多輪探索和對(duì)齊來(lái)不斷進(jìn)行性能提升。具體地,相比于離線 DPO 算法,COPO 顯著提升了 Zephyr-7B 和 Llama3-8B 模型的 LC 勝率,分別達(dá)到了 18.8% 和 7.1% 的提升,驗(yàn)證了 LLM 探索能力提升對(duì)獲取更大數(shù)據(jù)覆蓋和最優(yōu)策略方面的優(yōu)勢(shì)。
此外,COPO 超越了在線 DPO、SELM 等當(dāng)前最好的在線對(duì)齊方法,以 8B 的模型容量超越了許多大體量模型(如 Yi-34B,Llama3-70B)的性能,提升了大模型在語(yǔ)言任務(wù)中的指令跟隨能力和泛化能力。
-
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247391 -
LLM
+關(guān)注
關(guān)注
1文章
322瀏覽量
717
原文標(biāo)題:ICLR 2025 | 8B模型反超Llama3-70B!TeleAI提出探索驅(qū)動(dòng)的對(duì)齊方法COPO
文章出處:【微信號(hào):tyutcsplab,微信公眾號(hào):智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
太強(qiáng)了!AI PC搭載70B大模型,算力狂飆,內(nèi)存開(kāi)掛

IBM在watsonx.ai平臺(tái)推出DeepSeek R1蒸餾模型
IBM企業(yè)級(jí)AI開(kāi)發(fā)平臺(tái)watsonx.ai上線DeepSeek R1蒸餾模型
在算力魔方上本地部署Phi-4模型
Meta重磅發(fā)布Llama 3.3 70B:開(kāi)源AI模型的新里程碑
Meta推出Llama 3.3 70B,AI大模型競(jìng)爭(zhēng)白熱化
光纜8d與8b區(qū)別
Meta發(fā)布Llama 3.2量化版模型
Llama 3 語(yǔ)言模型應(yīng)用
TAS5805的I2C地址配置的是7b:2D,8b:5A怎么出來(lái)是7b:2F,8b:5E?這個(gè)是什么原因?
英偉達(dá)發(fā)布AI模型 Llama-3.1-Nemotron-51B AI模型
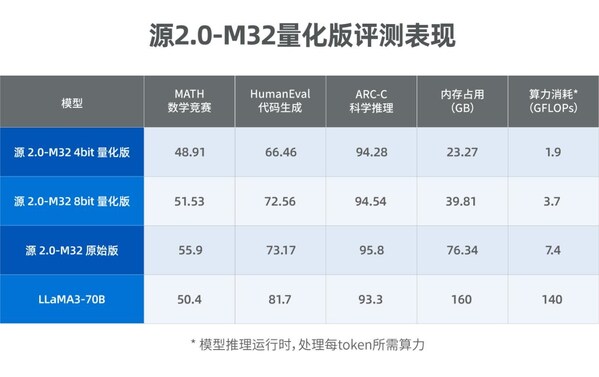
源2.0-M32大模型發(fā)布量化版 運(yùn)行顯存僅需23GB 性能可媲美LLaMA3
PerfXCloud平臺(tái)成功接入Meta Llama3.1
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論