") 讓大模型訓練更高效,奇異摩爾用互聯(lián)創(chuàng)新方案定義下一代AI計算
讓大模型訓練更高效,奇異摩爾用互聯(lián)創(chuàng)新方案定義下一代AI計算
電子發(fā)燒友網(wǎng)報道(文/吳子鵬)近一段時間以來,DeepSeek現(xiàn)象級爆火引發(fā)產(chǎn)業(yè)對大規(guī)模數(shù)據(jù)中心建設(shè)的思考和爭議。在訓練端,DeepSeek以開源模型通過算法優(yōu)化(如稀疏計算、動態(tài)架構(gòu))降低了訓練成本,使得企業(yè)能夠以低成本實現(xiàn)高性能AI大模型的訓練;在推理端,DeepSeek加速了AI應用從訓練向推理階段的遷移。因此,有觀點稱,DeepSeek之后算力需求將放緩。不過,更多的國內(nèi)外機構(gòu)和研報認為,DeepSeek降低了AI應用的門檻,將加速AI大模型應用落地,吸引更多的企業(yè)進入這個賽道,算力需求仍將繼續(xù)增長,不過需求重心從“單卡峰值性能”轉(zhuǎn)向“集群能效優(yōu)化”。比如,SemiAnalysis預測,全球數(shù)據(jù)中心容量將從2023年的49GW增長至2026年的96GW,其中新建智算中心容量將占增量的85%。近日,全球四大巨頭(Meta、亞馬遜、微軟及)公布的2025 AI基礎(chǔ)設(shè)施支出總計超3000億美元,相比2024年增長30%。
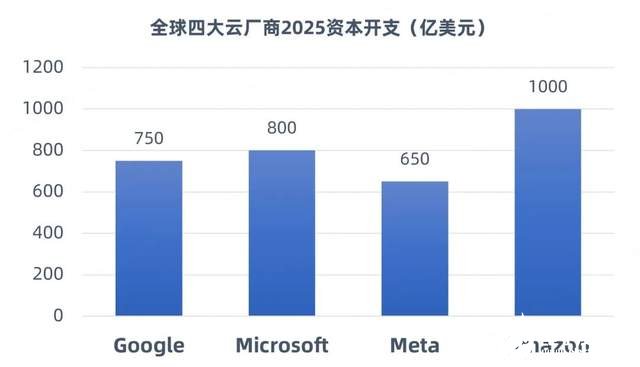
(數(shù)據(jù)來源:科技巨頭公開披露報告)
奇異摩爾創(chuàng)始人兼CEO田陌晨表示:“‘Scaling Law’依然在延續(xù)。從Transformer的獨領(lǐng)風騷到MoE專家模型的創(chuàng)新突圍,AI領(lǐng)域正邁向萬億、甚至十萬億參數(shù)規(guī)模的AI大模型訓練時代。DeepSeek-R1推理模型的問世離不開基礎(chǔ)模型Deepseek-V3的龐大訓練積累。在這一背景下,強大的算力集群依然是支撐AI的基石。而如何提高集群的線性加速比,一直是產(chǎn)業(yè)的核心話題。與此同時,AI算力網(wǎng)絡(luò)的重要性日益凸顯,它讓數(shù)據(jù)在集群中各個層面、各個維度上都能夠快速傳輸,實現(xiàn)各節(jié)點資源的高效調(diào)動。”

(圖:奇異摩爾創(chuàng)始人兼CEO田陌晨)
為此,作為行業(yè)領(lǐng)先的AI網(wǎng)絡(luò)全棧式互聯(lián)產(chǎn)品及解決方案提供商,奇異摩爾給出了一套極具競爭力的解決方案——基于高性能RDMA和Chiplet技術(shù),利用“Scale Out”“Scale Up”“Scale Inside”三大理念,提升算力基礎(chǔ)設(shè)施在網(wǎng)間、片間和片內(nèi)的傳輸效率,為智能算力發(fā)展賦能。
Scale Out——打破系統(tǒng)傳輸瓶頸
DeepSeek的成功證明了開源模型相較于閉源模型具有一定的優(yōu)越性,隨著模型的智能化趨勢演進,模型體量的增加仍然會是行業(yè)發(fā)展的主要趨勢之一。為了完成千億、萬億參數(shù)規(guī)模AI大模型的訓練任務,通用的做法一般會采用Tensor并行(TP)、Pipeline并行(PP)、和Data并行(DP)策略來拆分訓練任務。隨著MoE(Mixture of Experts,混合專家)模型的出現(xiàn),除了涉及上述并行策略外,還引入了專家并行(EP)。其中,EP和TP通信數(shù)據(jù)開銷較大,主要通過Scale Up互聯(lián)方式應對。DP和PP并行計算的通信開銷相對較小,主要通過Scale Out互聯(lián)方式應對。
因而,如下圖所示,當下主流的萬卡集群里存在兩種互聯(lián)域——GPU南向Scale Up互聯(lián)域(Scale Up Domain,SUD)和GPU北向Scale Out互聯(lián)域(Scale Out Domain,SOD)。田陌晨強調(diào):“以Scale Up和Scale Out雙擎驅(qū)動方式構(gòu)建大規(guī)模、高效的智算集群,是應對算力需求爆發(fā)的有效手段。”
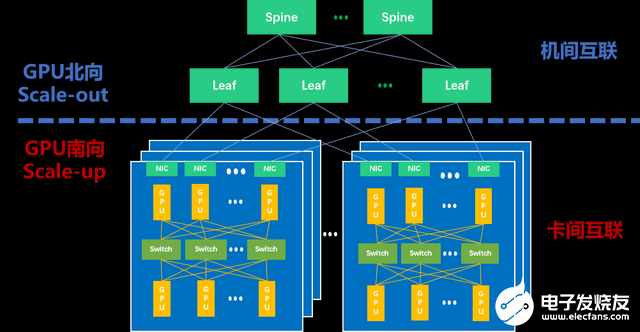
智算集群里的Scale Up和Scale Out
在這個集群網(wǎng)絡(luò)中,Scale Out專注于橫向/水平的擴展,強調(diào)通過增加更多計算節(jié)點實現(xiàn)集群規(guī)模的擴展。當前,遠程直接內(nèi)存訪問(RDMA)已經(jīng)成為構(gòu)建Scale Out網(wǎng)絡(luò)的主流選擇。作為一種host-offload/host-bypass技術(shù),RDMA提供了從一臺計算機內(nèi)存到另一臺計算機內(nèi)存的直接訪問,具有低延遲、高帶寬的特性,在大規(guī)模集群中扮演著重要的角色。如下圖所示,RDMA主要包含InfiniBand(IB)、基于以太網(wǎng)的RoCE和基于TCP/IP的iWARP。其中,IB和以太網(wǎng)RDMA是算力集群里應用最廣泛的技術(shù)。
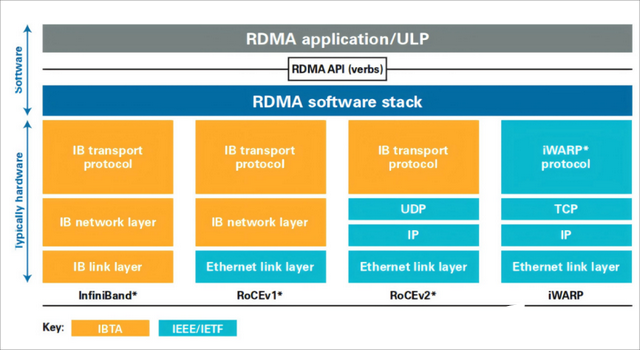
RDMA應用和實現(xiàn)方式(來源:知乎 @Savir)
IB是專門為RDMA開發(fā)的一種網(wǎng)絡(luò)通信技術(shù),具有高帶寬、低延遲等優(yōu)勢,且IB默認是無損網(wǎng)絡(luò),無需特殊設(shè)置。得益于這些優(yōu)勢,過往IB在Scale Out網(wǎng)絡(luò)構(gòu)建中占據(jù)主導地位。然而,IB需要專門支持該技術(shù)的網(wǎng)卡和交換機,價格是傳統(tǒng)網(wǎng)絡(luò)的5-10倍,成本相對較高,且IB交換機交期較長。同時,IB兼容性差,難以和大多數(shù)以太網(wǎng)設(shè)備兼容,例如網(wǎng)卡、線纜、交換機和路由器等,無法成為行業(yè)統(tǒng)一的發(fā)展路線。
隨著集群規(guī)模增大,以太網(wǎng)RDMA獲得了主流廠商的廣泛支持。以太網(wǎng)RDMA同樣具有高速率、高帶寬、CPU負載低等優(yōu)勢,在低時延和無損網(wǎng)絡(luò)特性方面也已經(jīng)和IB性能持平。同時,以太網(wǎng)RDMA具有更好的開放性、兼容性和統(tǒng)一性,更利于做大規(guī)模的組網(wǎng)集群。從一些行業(yè)代表性案例來看,如字節(jié)跳動的萬卡集群,Meta公司的數(shù)萬卡集群,以及特斯拉希望打造的十萬卡集群,都一致選擇了以太網(wǎng)方案。此外,因為硬件通用和運維簡單,以太網(wǎng)RDMA方案更具性價比。
雖然以太網(wǎng)RDMA已經(jīng)被公認是未來Scale Out的大趨勢,不過田陌晨指出:“如果是基于RoCEv2構(gòu)建方案仍存在一些問題,比如亂序需要重傳,負載分擔不完美,存在Go-back-N問題,以及DCQCN 部署調(diào)優(yōu)復雜等。在萬卡和十萬卡集群中,業(yè)界需要增強型以太網(wǎng)RDMA以應對上述這些挑戰(zhàn),超以太網(wǎng)傳輸(Ultra Ethernet Transport,UET)便是下一代AI計算和HPC里的關(guān)鍵技術(shù)。”
為了能夠進一步發(fā)揮以太網(wǎng)和RDMA技術(shù)的潛能,博通、思科、Arista、微軟、Meta等公司牽頭成立了超以太網(wǎng)聯(lián)盟(UEC)。如下圖所示,在UEC規(guī)范1.0的預覽版本中,UEC從軟件API、運輸層、鏈路層、網(wǎng)絡(luò)安全和擁塞控制等方面對Transport Layer傳輸層做了全面的優(yōu)化,關(guān)鍵功能包括FEC(前向糾錯)統(tǒng)計、鏈路層重傳(LLR)、多路徑報文噴發(fā)、新一代擁塞控制、靈活排序、端到端遙測、交換機卸載等。根據(jù)AMD方面的數(shù)據(jù),UEC就緒(UEC-ready)系統(tǒng)能夠提供比傳統(tǒng)RoCEv2系統(tǒng)高出5-6倍的性能。
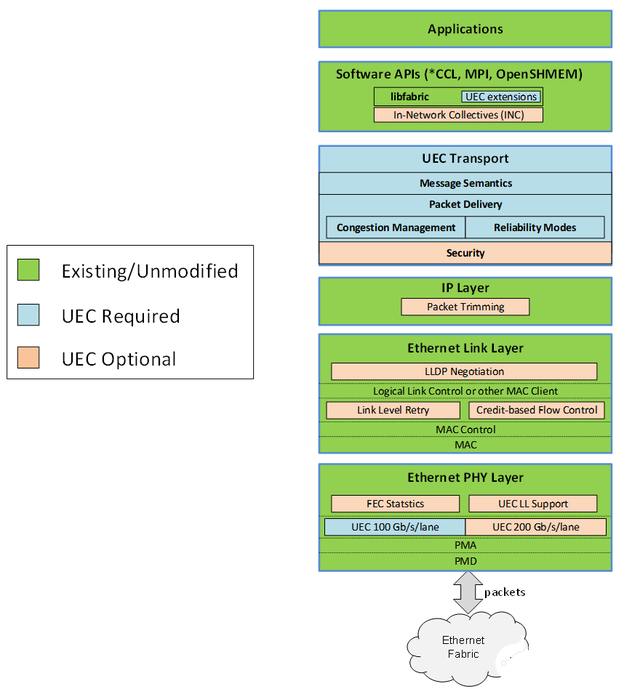
UEC規(guī)范1.0示意圖(來源:UEC)
田陌晨表示:“UEC是專門為AI網(wǎng)絡(luò)Scale Out互聯(lián)成立的國際聯(lián)盟,致力于通過Modernized RDMA優(yōu)化AI和HPC工作負載。借助UEC的關(guān)鍵性能,Scale Out網(wǎng)絡(luò)能夠充分利用系統(tǒng)內(nèi)所有可用的傳輸路徑,并最小化網(wǎng)絡(luò)擁塞。當前基于RDMA RoCE的解決方案未來也可以通過踐行UEC聯(lián)盟的標準升級各自的以太網(wǎng)產(chǎn)品方案,打造更大規(guī)模的無損集群通信。”
奇異摩爾打造的Kiwi NDSA-SNIC AI原生智能網(wǎng)卡便是一款UEC就緒方案,性能比肩全球標桿ASIC產(chǎn)品。Kiwi NDSA SmartNIC提供領(lǐng)先行業(yè)的高性能,支持高達800Gbps的傳輸帶寬,提供低至μs級的數(shù)據(jù)傳輸延時,滿足當前數(shù)據(jù)中心行業(yè)400Gbps-800Gbps升級需求,可實現(xiàn)Tb級別萬卡集群間無損數(shù)據(jù)傳輸。

奇異摩爾Kiwi NDSA-SNIC AI原生智能網(wǎng)卡方案(來源:奇異摩爾)
借助UEC就緒RDMA中的路徑感知擁塞控制、有序消息傳遞、選擇性確認重傳、自適應路由及數(shù)據(jù)包噴灑等關(guān)鍵功能,Kiwi NDSA-SNIC能夠充分保障AI網(wǎng)絡(luò)間數(shù)據(jù)的穩(wěn)定傳輸。比如,Kiwi NDSA-SNIC提供的自適應路由及數(shù)據(jù)包噴灑功能可以充分發(fā)揮高速網(wǎng)絡(luò)的性能,支持高級分組噴灑,提供多路徑數(shù)據(jù)包傳送和細粒度負載平衡,有效應對傳輸擁塞。相同用例還有:通過有序消息傳遞(In-Order Message Delivery)來降低系統(tǒng)延遲,通過路徑感知擁塞控制(Path Aware Congestion Control)來優(yōu)化多個路徑的數(shù)據(jù)包流,等等。
此外,Kiwi NDSA-SNIC還擁有很多其他的關(guān)鍵特性。比如,Kiwi NDSA-SNIC具有出色的高并發(fā)特性,支持多達數(shù)百萬個隊列對,可擴展內(nèi)存空間達到GB;Kiwi NDSA-SNIC具有可編程性,可應對各種網(wǎng)絡(luò)任務加速,為Scale Out網(wǎng)絡(luò)帶來持續(xù)創(chuàng)新的功能,并保證與未來的行業(yè)標準無縫兼容。
綜合而言,奇異摩爾的Kiwi NDSA-SNIC AI原生智能網(wǎng)卡是一個擁有高性能、可編程的Scale Out網(wǎng)絡(luò)引擎,將開啟AI網(wǎng)絡(luò) Scale Out發(fā)展的新篇章。田陌晨稱:“當前,奇異摩爾已經(jīng)成為UEC聯(lián)盟成員。隨著以太網(wǎng)逐漸過渡到超以太網(wǎng),奇異摩爾愿攜手聯(lián)盟伙伴共同探討并踐行Scale Out相關(guān)標準的制定和完善,并第一時間為行業(yè)帶來性能領(lǐng)先的UEC方案,推動AI網(wǎng)絡(luò) Scale Out技術(shù)向前發(fā)展。”

奇異摩爾UEC會員(來源:UEC官網(wǎng))
Scale Up——讓計算芯片配合更高效
和橫向/水平擴展的Scale Out不同,Scale Up是垂直/向上擴展,目標是打造機內(nèi)高帶寬互聯(lián)的超節(jié)點。上述提到,TP張量并行以及EP專家并行需要更高的帶寬和更低的時延來進行全局同步。通過Scale Up的方式,將更多的算力芯片GPU集中到一個節(jié)點上,是非常有效的應對方式。如今的Scale Up實際上就是一個以超高帶寬為核心的機內(nèi)GPU-GPU組網(wǎng)方式,還有一個名稱是超帶寬域(HBD,High Bandwidth Domain)。
英偉達GB200 NVL72的推出引領(lǐng)著國內(nèi)外AI網(wǎng)絡(luò)生態(tài)對HBD技術(shù)的廣泛探討。英偉達GB200NVL72服務器是一個典型的超大HBD,實現(xiàn)了36組GB200(36個Grace CPU,72個B200 GPU)之間的超高帶寬互聯(lián)。在這個HBD系統(tǒng)里,第五代 NVLink是最關(guān)鍵的,它能夠提供GPU-GPU之間雙向1.8TB的傳輸速率,使得這個HBD系統(tǒng)可以作為一個大型GPU去使用,訓練效率相較于H100系統(tǒng)提升了4倍,能效提升了25倍。
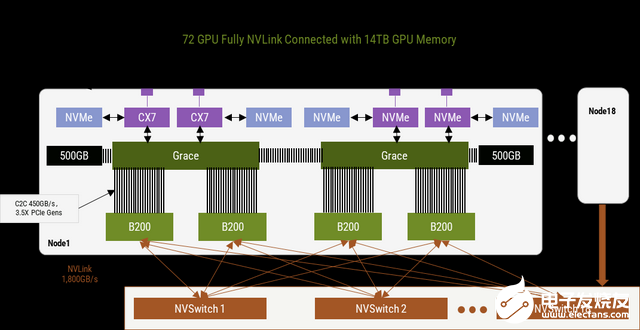
NVL72互聯(lián)架構(gòu)(來源:英偉達)
和IB一樣,NVLink也是由英偉達主導,雖然性能強勁但是生態(tài)封閉,只服務于英偉達的高端GPU。由于沒有NVLink和NVSwitch這樣的技術(shù),此前其他廠商主要采用full mesh或者cube-mesh結(jié)構(gòu),以8卡互聯(lián)為主,而16-32卡互聯(lián)是下一代方案。
DeepSeek事件引發(fā)了業(yè)界對于上述NVLink和HBD需求的不同預期。但中長期發(fā)展來看,相比軟件迭代速度以小時來計算,硬件的迭代則是以年為計算的循序漸進過程,不會一蹴而就。據(jù)SemiAnalysis預計大型模型的標準只會隨著未來的模型發(fā)布而繼續(xù)升高,但從經(jīng)濟效用上來說,其所對應的硬件必須堅持使用并有效 4-6 年,而不僅僅是直到下一個模型發(fā)布。
對此,田陌晨認為:“未來MoE模型的進階路線在一定程度上存在不確定性,創(chuàng)新隨時可能發(fā)生。但國產(chǎn)AI網(wǎng)絡(luò)的生態(tài)閉環(huán)勢在必行。英偉達NVLink和Cuda的護城河仍然存在,首先要解決Scale Up互聯(lián)國產(chǎn)替代方案有沒有的問題,再來看做到哪種程度。未來隨著國產(chǎn)大模型、芯片架構(gòu)等軟硬件生態(tài)的協(xié)同發(fā)展,有望逐步實現(xiàn)國產(chǎn)算力閉環(huán)。”
如今,科技巨頭正聯(lián)合生態(tài)上下游在GPU-GPU高效互聯(lián)方面主要分為兩個流派:內(nèi)存語義和消息語義。內(nèi)存語義Load/Store/Atomic是GPU內(nèi)部總線傳輸?shù)脑Z義,英偉達NVLink便是基于內(nèi)存語義,對標NVLink的UAlink等也是基于這種語義;消息語義則是采用類似Scale Out的DMA語義Send/Read/Write,將數(shù)據(jù)進行打包傳輸,亞馬遜和Tenstorrent等公司便是基于消息語義打造Scale Up互聯(lián)方案。
內(nèi)存語義和消息語義各有千秋。內(nèi)存語義是GPU內(nèi)部傳輸?shù)脑Z義,處理器負擔更小,在數(shù)據(jù)包體量小時效率更高;消息語義采用數(shù)據(jù)打包的方式,隨著數(shù)據(jù)包體量變大,性能逐漸追上了內(nèi)存語義,隨著AI大模型體量增大,這一點也非常重要。
不過,田陌晨指出:“無論是內(nèi)存語義還是消息語義,對于廠商而言,都面臨一些共性的挑戰(zhàn),比如傳統(tǒng)GPU直出將IO集成在GPU內(nèi)部,性能提升受到了光罩尺寸的嚴格限制,留給IO的空間非常有限,IO密度提升困難;Scale Up網(wǎng)絡(luò)和數(shù)據(jù)傳輸協(xié)議復雜,計算芯片廠商大都缺乏相關(guān)經(jīng)驗,尤其是開發(fā)交換機芯片的經(jīng)驗;除NVLink之外,其他Scale Up協(xié)議并不成熟且不統(tǒng)一,協(xié)議迭代對計算芯片迭代造成了巨大的困擾。”
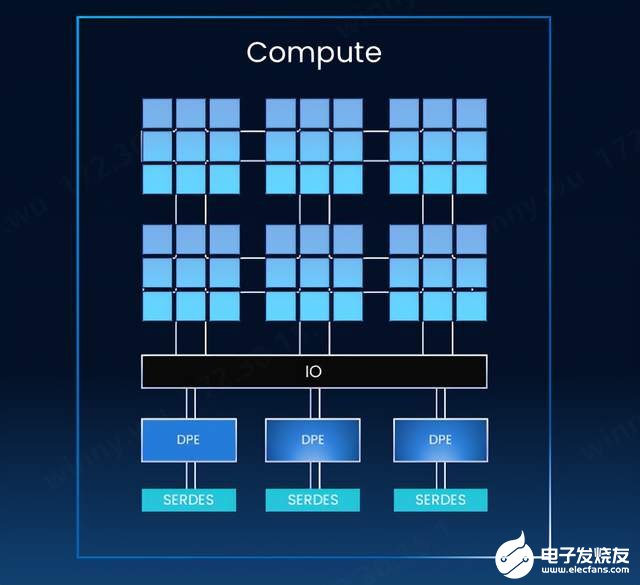
GPU IO集成在GPU內(nèi)部(來源:奇異摩爾)
為了能夠更好地應對上述挑戰(zhàn),產(chǎn)業(yè)界提出了一種創(chuàng)新的GPU直出方式——計算和IO分離。奇異摩爾NDSA-G2G互聯(lián)方案便是這條技術(shù)路徑里非常有競爭力的一款方案。
借助NDSA-G2G可以實現(xiàn)計算芯粒和IO芯粒解耦,通過通用芯粒互聯(lián)技術(shù)UCIe進行互聯(lián)。這樣做的好處是,只需要犧牲一點點的芯片面積(小百分之幾),就可以將寶貴的中介層資源近乎100%用于計算,并按照客戶的需求靈活地增加IO芯粒的數(shù)量,且計算芯粒和IO芯粒可以基于不同的工藝技術(shù)。再加上IO芯粒的復用特性,能夠顯著提升高性能計算芯片的性能和性價比。
NDSA-G2G的第二大優(yōu)勢是提升IO密度和性能,具有高帶寬、低延時和高并發(fā)的特性。在高帶寬方面,基于NDSA-G2G芯粒,可以實現(xiàn)1TB級別的網(wǎng)絡(luò)層吞吐量,TB級的GPU側(cè)吞吐量;在低延時方面,NDSA-G2G芯粒提供百ns級的數(shù)據(jù)傳輸延時和ns級D2D數(shù)據(jù)傳輸延時;在高并發(fā)方面,該產(chǎn)品支持多達數(shù)百萬個隊列對,可擴展系統(tǒng)中的內(nèi)存資源。也就是說,借助奇異摩爾NDSA-G2G芯粒能夠賦能國產(chǎn)AI芯片實現(xiàn)自主突圍,構(gòu)建性能媲美英偉達NVSwitch+NVLink的Scale Up方案。

Kiwi NDSA-G2G 產(chǎn)品示意圖(來源:奇異摩爾)
NDSA-G2G的第三大優(yōu)勢是具有出色的靈活性。如上所述,目前Scale Up技術(shù)路線并不統(tǒng)一,且智算中心廠商在協(xié)議方面大都采用自有協(xié)議,或者自己主導的聯(lián)盟協(xié)議。這就導致高性能計算芯片需要在設(shè)計時考慮未來2~3年,甚至是3~5年的協(xié)議發(fā)展,具有非常大的挑戰(zhàn)。NDSA-G2G以計算芯粒和IO芯粒分離的方式讓IO芯粒可以靈活升級,同時NASG-G2G基于具有可編程性,可以支持目前市面上各種IO協(xié)議。這種靈活性讓高性能計算芯片廠商可以從容應對當前Scale Up技術(shù)路線不統(tǒng)一且協(xié)議混亂的挑戰(zhàn)。
同時,田陌晨也呼吁:“希望科技行業(yè)在Scale Up方向上能夠擁抱一種開放而統(tǒng)一的物理接口,實現(xiàn)更好的協(xié)同發(fā)展,這也是打造國產(chǎn)自主可控算力底座的關(guān)鍵一步。”
Scale Inside——全面提升計算芯片傳輸效率
在Scale Out和Scale Up 高速發(fā)展的過程中,作為算力基礎(chǔ)單元,Scale Inside的進度也沒有落下,并致力于通過先進封裝技術(shù)彌補摩爾定律速度放緩的影響。在整個智算系統(tǒng)里,更高算力的計算芯片能夠進一步提升Scale Up和Scale Out的性能水平,使得AI大模型的訓練更加高效。
當前,單顆高性能計算芯片的成本已經(jīng)非常恐怖,隨著制程工藝進一步精進,這一數(shù)字還將繼續(xù)飆升,因而Chiplet技術(shù)得到了廣泛的重視。Chiplet技術(shù)允許通過混合封裝的方式打造高性能計算芯片,也就是說計算單元和IO、存儲等其他功能單元可以選擇不同的工藝實現(xiàn),具有極高的靈活性,允許廠商根據(jù)自己的需求進行定制芯粒,不僅能夠顯著降低芯片設(shè)計和制造的成本,良率也能夠得到很大的改善。
在Scale Inside方向上,奇異摩爾能夠提供豐富的Chiplet技術(shù)方案,包括Kiwi Link UCIe Die2Die接口IP、Central IO Die,3D Base Die系列等。其中,Kiwi Link全系列支持UCIe標準,具有業(yè)界領(lǐng)先的高帶寬、低功耗、低延時特性,并支持多種封裝類型。Kiwi Link支持高達16~32 GT/s的傳輸速率和低至ns級的傳輸延遲,支持Multi-Protocol多協(xié)議,包括PCIe、CXL和Streaming。
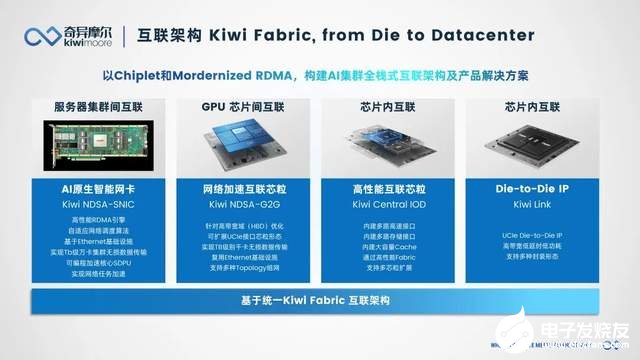
Kiwi Fabric互聯(lián)架構(gòu)(來源:奇異摩爾)
綜合而言,奇異摩爾的解決方案能夠從“Scale Out”“Scale Up”“Scale Inside”三大角度,推動AI大模型訓練效率的提升。在Scale Out方面,奇異摩爾已經(jīng)是超以太網(wǎng)聯(lián)盟UEC的成員,能夠在第一時間響應UEC規(guī)范1.0以及后續(xù)規(guī)范;在Scale Up方面,奇異摩爾NDSA-G2G芯粒不僅能夠幫助科技公司打造媲美英偉達NVSwitch+NVLink性能的Scale Up方案,適配各種技術(shù)路線和協(xié)議,也正在引領(lǐng)計算芯片的設(shè)計革新;在Scale Inside方案,奇異摩爾的Kiwi Link UCIe Die2Die接口IP、Central IO Die、3D Base Die系列等方案能夠幫助廠商打造具有高效傳輸能力的高性能計算芯片。
這些方案很好地踐行了奇異摩爾公司的使命——以互聯(lián)為中心,依托Chiplet和RDMA技術(shù),構(gòu)筑AI高性能計算的基石。“對于國產(chǎn)AI大模型和國產(chǎn)AI芯片產(chǎn)業(yè)而言,奇異摩爾的方案是新質(zhì)生產(chǎn)力的代表,有著更大的潛能值得去挖掘。為實現(xiàn)國產(chǎn)AI芯片產(chǎn)業(yè)的‘中國夢’,奇異摩爾不僅提供支持最前沿協(xié)議的IO芯粒,以實現(xiàn)高速率、高帶寬、低時延的傳輸表現(xiàn),還在Chiplet路線上獨辟蹊徑,用創(chuàng)新的芯片架構(gòu)助力打造更高性能的AI芯片。奇異摩爾愿與國內(nèi)公司攜手,為國產(chǎn)AI芯片產(chǎn)業(yè)發(fā)展添磚加瓦,共同勾畫國產(chǎn)AI發(fā)展的廣闊藍圖。”田陌晨最后說。
發(fā)布評論請先 登錄
奇異摩爾邀您相約2025中國AI算力大會
英特爾與面壁智能宣布建立戰(zhàn)略合作伙伴關(guān)系,共同研發(fā)端側(cè)原生智能座艙,定義下一代車載AI

LPO 光模塊:下一代數(shù)據(jù)中心網(wǎng)絡(luò)的節(jié)能高效新選擇
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應手
適用于數(shù)據(jù)中心和AI時代的800G網(wǎng)絡(luò)
摩爾線程GPU原生FP8計算助力AI訓練

百度李彥宏談訓練下一代大模型
奇異摩爾分享計算芯片Scale Up片間互聯(lián)新途徑

中興通訊展示創(chuàng)新方案與實踐成果
國家大力部署 IPv6,打造下一代互聯(lián)網(wǎng)新生態(tài)

摩爾線程與羽人科技完成大語言模型訓練測試
奇異摩爾上海總部進駐上海浦東科海大樓

MWCS 2024 | 廣和通榮獲邊緣AI計算最佳創(chuàng)新方案

MWCS 2024 廣和通榮獲邊緣AI計算最佳創(chuàng)新方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論