") BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解
BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解

BEVFusion 技術詳解總結
原始論文:*附件:bevfusion.pdf
介紹(Introduction)
背景:自動駕駛系統(tǒng)配備了多種傳感器,提供互補的信號。但是不同傳感器的數據表現形式不同。
自動駕駛系統(tǒng)配備了多樣的傳感器。 例如,Waymo的自動駕駛車輛有29個攝像頭、6個雷達和5個激光雷達。 **不同的傳感器提供互補的信號:**例如,攝像機捕捉豐富的語義信息,激光雷達提供精確的空間信息,而雷達提供即時的速度估計。 因此,多傳感器融合對于準確可靠的感知具有重要意義。**來自不同傳感器的數據以根本不同的方式表示:**例如,攝像機在透視圖中捕獲數據,激光雷達在3D視圖中捕獲數據。

1. 核心目標與創(chuàng)新?
- 目標? 解決多模態(tài)傳感器(攝像頭、激光雷達等)在3D感知任務中的異構數據融合難題,實現高效、通用的多任務學習(如3D檢測、BEV分割)
- 核心創(chuàng)新?
- ?統(tǒng)一BEV表示 將多模態(tài)特征映射到共享的鳥瞰圖(BEV)空間,保留幾何結構(激光雷達優(yōu)勢)和語義密度(攝像頭優(yōu)勢)
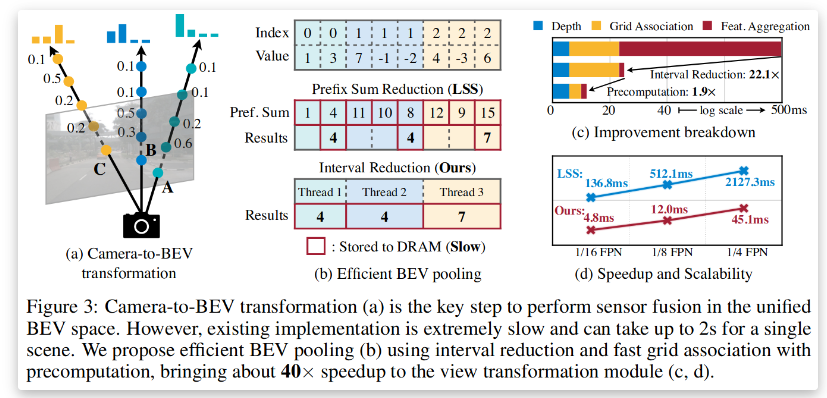
- ?優(yōu)化BEV池化 通過預計算和間隔縮減技術,將BEV池化速度提升40%以上
- ?全卷積融合 解決激光雷達與攝像頭BEV特征的空間錯位問題,提升融合魯棒性
2. 技術框架與關鍵模塊?
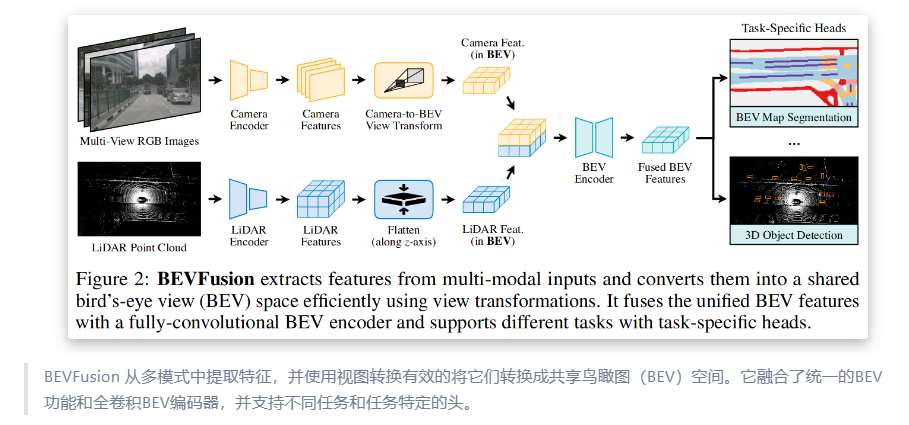
?2.1 多模態(tài)特征提取
- ?傳感器輸入
- ?攝像頭 多視角圖像(透視視圖)
- ?激光雷達 點云數據(3D視圖)
- ?模態(tài)專用編碼器
- ?攝像頭 2D卷積神經網絡(如ResNet)提取圖像特征
- ?激光雷達 3D稀疏卷積網絡(如VoxelNet)提取點云特征
?2.2 統(tǒng)一BEV表示構建
- ?攝像頭到BEV的轉換
- ?深度分布預測 顯式預測每個像素的離散深度分布(避免幾何失真)
- ?特征投影 沿相機射線將像素特征分散到離散3D點,通過BEV池化聚合特征(見圖1)
- ?優(yōu)化加速 預計算相機內外參矩陣,減少實時計算開銷
- ?激光雷達到BEV的轉換 直接通過體素化將點云映射到BEV網格
?2.3 全卷積特征融合
- ?融合策略
- ?通道級聯(lián) 將攝像頭和激光雷達的BEV特征拼接,輸入全卷積網絡(FCN)
- ?空間對齊補償 通過可變形卷積或注意力機制緩解特征錯位問題
?2.4 多任務頭設計
- ?3D物體檢測 基于融合后的BEV特征,采用Anchor-free或CenterPoint范式預測邊界框
- ?BEV地圖分割 全卷積解碼器輸出語義分割結果(如車道線、可行駛區(qū)域)
?3. 性能優(yōu)勢與實驗驗證
? 3.1 基準測試結果(NuScenes數據集)
| ?任務 | ?模型類型 | ?性能指標 | ?BEVFusion優(yōu)勢 |
|---|---|---|---|
| 3D物體檢測 | 純攝像頭模型 | mAP: 35.1% | ?mAP: 68.5%(+33.4%) |
| 3D物體檢測 | 純激光雷達模型 | mAP: 65.2% | ?mAP: 68.5%(+3.3%) |
| BEV地圖分割 | 純攝像頭模型 | mIoU: 44.7% | ?mIoU: 50.7%(+6.0%) |
| BEV地圖分割 | 純激光雷達模型 | mIoU: 37.1% | ?mIoU: 50.7%(+13.6%) |
?3.2 效率對比
- ?計算成本 BEVFusion的計算量僅為同類多模態(tài)模型的50%(1.9倍低于純激光雷達模型)
- ?推理速度 優(yōu)化后的BEV池化使端到端延遲降低40%
?4. 與傳統(tǒng)方法的對比分析
?4.1 早期融合 vs. 晚期融合
| ?方法 | ?優(yōu)勢 | ?劣勢 |
|---|---|---|
| 早期融合(特征級) | 保留原始數據信息 | 異構特征難以對齊(如幾何失真) |
| 晚期融合(決策級) | 模態(tài)獨立性高 | 語義信息丟失,任務性能受限 |
| ?BEVFusion | ?統(tǒng)一BEV空間平衡幾何與語義 | 需優(yōu)化特征對齊與計算效率 |
?4.2 其他多模態(tài)模型對比
- ?PointPainting 將攝像頭語義注入點云,但依賴激光雷達主導,無法充分發(fā)揮攝像頭優(yōu)勢
- ?TransFusion 基于Transformer的融合,計算復雜度高,實時性差
?5. 局限性與未來方向
- ?局限性
- ?動態(tài)場景適應性 BEV靜態(tài)假設可能影響運動物體感知
- ?傳感器依賴性 仍需激光雷達提供幾何先驗
- ?未來方向
- ?純視覺BEV泛化 探索無激光雷達的BEV感知(如4D標注數據增強)
- ?時序融合 引入多幀BEV特征提升動態(tài)場景理解
?總結
BEVFusion通過統(tǒng)一的BEV表示空間和高效融合機制,解決了多模態(tài)傳感器在幾何與語義任務中的權衡問題,成為自動駕駛多任務感知的標桿框架其設計范式為后續(xù)研究提供了重要啟發(fā) ?**“統(tǒng)一表示+輕量優(yōu)化”是多模態(tài)融合的核心方向**
項目鏈接
- 官方網頁:https://hanlab.mit.edu/projects/bevfusion
- 原始論文:https://arxiv.org/abs/2205.13542
- 項目地址:https://github.com/mit-han-lab/bevfusion
參考資料
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
自動駕駛
+關注
關注
790文章
14321瀏覽量
170696
發(fā)布評論請先 登錄
相關推薦
熱點推薦
康謀分享 | 基于多傳感器數據的自動駕駛仿真確定性驗證
自動駕駛仿真測試中,游戲引擎的底層架構可能會帶來非確定性的問題,侵蝕測試可信度。如何通過專業(yè)仿真平臺,在多傳感器配置與極端天氣場景中實現測試數據零差異?確定性驗證方案已成為自動駕駛研發(fā)

自動駕駛汽車是如何準確定位的?
厘米級的定位精度,并能夠實時響應環(huán)境變化。為此,自動駕駛系統(tǒng)通常采用多傳感器融合的方式,將全球導航衛(wèi)星系統(tǒng)(GNSS)、慣性測量單元(IMU)、激光雷達(LiDAR)、攝像頭、超寬帶(
AI將如何改變自動駕駛?
自動駕駛帶來哪些變化?其實AI可以改變自動駕駛技術的各個環(huán)節(jié),從感知能力的提升到決策框架的優(yōu)化,從安全性能的增強到測試驗證的加速,AI可以讓自動駕駛
技術分享 |多模態(tài)自動駕駛混合渲染HRMAD:將NeRF和3DGS進行感知驗證和端到端AD測試
多模態(tài)自動駕駛混合渲染HRMAD,融合NeRF與3DGS技術,實現超10萬㎡場景重建,多傳感器實

多傳感器融合在自動駕駛中的應用趨勢探究
自動駕駛技術的快速發(fā)展加速交通行業(yè)變革,為實現車輛自動駕駛,需要車輛對復雜動態(tài)環(huán)境做出準確、高效的響應,而多
一文聊聊自動駕駛測試技術的挑戰(zhàn)與創(chuàng)新
,包括場景生成的多樣性與準確性、多傳感器數據融合的精度驗證、高效的時間同步機制,以及仿真平臺與實際場景的匹配等問題。 自動駕駛測試的必要性與

MEMS技術在自動駕駛汽車中的應用
MEMS技術在自動駕駛汽車中的應用主要體現在傳感器方面,這些傳感器為自動駕駛汽車提供了關鍵的環(huán)境感知和數據采集能力。以下是對MEMS
人工智能的應用領域有自動駕駛嗎
的核心技術 自動駕駛汽車的核心依賴于人工智能,尤其是機器學習和深度學習技術。這些技術使得汽車能夠通過傳感器收集大量數據,并實時進行分析。以下
自動駕駛技術的典型應用 自動駕駛技術涉及到哪些技術
自動駕駛技術的典型應用 自動駕駛技術是一種依賴計算機、無人駕駛設備以及各種傳感器,實現汽車自主行
FPGA在自動駕駛領域有哪些優(yōu)勢?
領域的主要優(yōu)勢:
高性能與并行處理能力:
FPGA內部包含大量的邏輯門和可配置的連接,能夠同時處理多個數據流和計算任務。這種并行處理能力使得FPGA在處理自動駕駛中復雜的圖像識別、傳感器數據處理等
發(fā)表于 07-29 17:11
FPGA在自動駕駛領域有哪些應用?
低,適合用于實現高效的圖像算法,如車道線檢測、交通標志識別等。
雷達和LiDAR處理:自動駕駛汽車通常會使用雷達和LiDAR(激光雷達)等多種傳感器來獲取環(huán)境信息。FPGA能夠協(xié)助完成這些傳感
發(fā)表于 07-29 17:09
自動駕駛識別技術有哪些
自動駕駛的識別技術是自動駕駛系統(tǒng)中的重要組成部分,它使車輛能夠感知并理解周圍環(huán)境,從而做出智能決策。自動駕駛識別技術主要包括多種
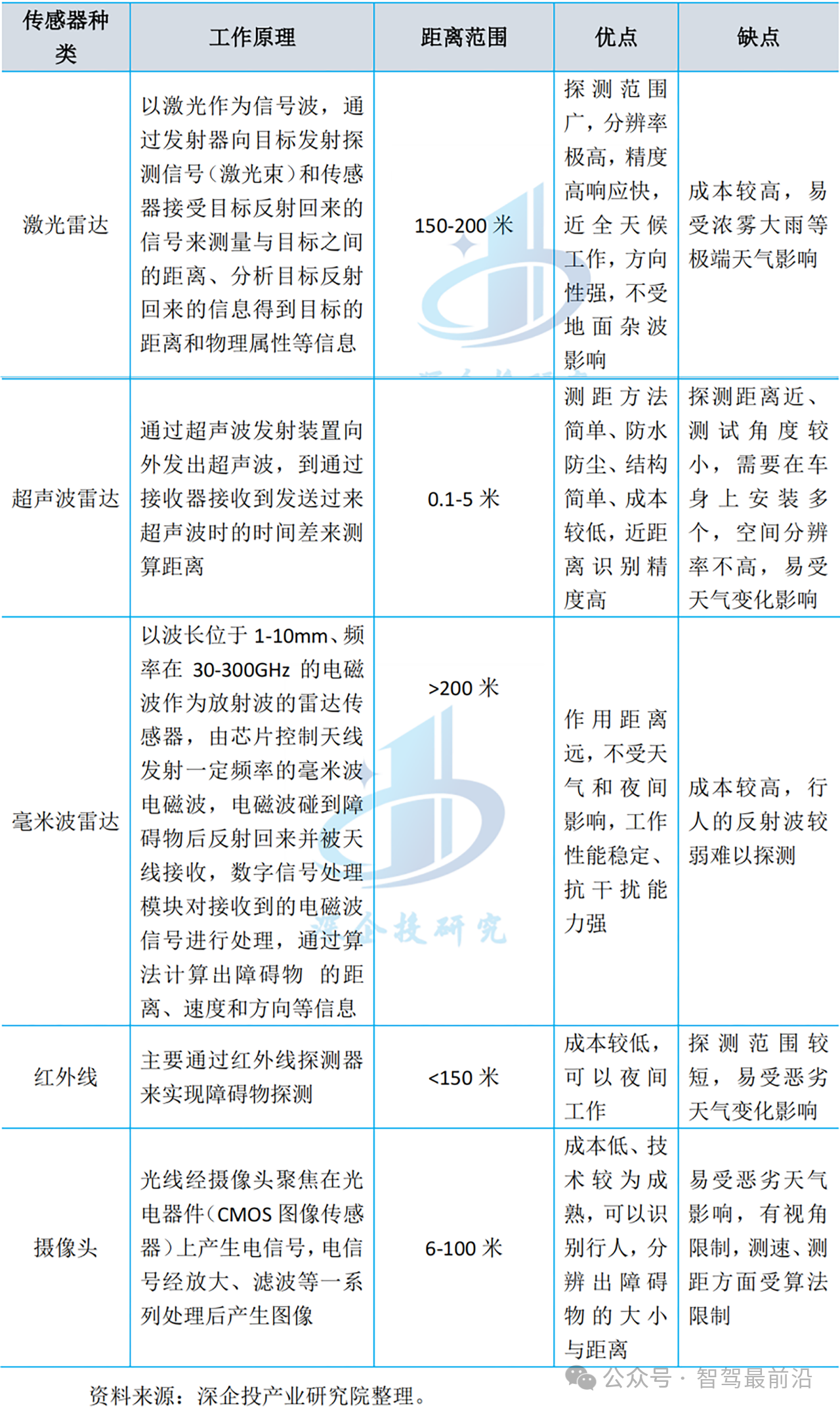
自動駕駛的傳感器技術介紹
自動駕駛的傳感器技術是自動駕駛系統(tǒng)的核心組成部分,它使車輛能夠感知并理解周圍環(huán)境,從而做出智能決策。以下是對自動駕駛
自動駕駛汽車傳感器有哪些
自動駕駛汽車傳感器是實現自動駕駛功能的關鍵組件,它們通過采集和處理車輛周圍環(huán)境的信息,為自動駕駛系統(tǒng)提供必要的感知和決策依據。以下是對自動駕駛





 工商網監(jiān)
工商網監(jiān)
評論