 利用eBPF程序繞過內核以加速存儲訪問
利用eBPF程序繞過內核以加速存儲訪問

【摘要】
隨著微秒級NVMe存儲的蓬勃發展,Linux內核存儲棧的開銷幾乎是存儲訪問時間的兩倍,已經成為性能瓶頸。作者提出XRP——一個允許應用通過在NVMe驅動的eBPF hook運行用戶定義的存儲函數(如索引查找)的框架,它可以安全地繞過內核大部分存儲棧。為了保持文件系統的語義,當用戶注冊的eBPF函數被調用時,XRP向它的NVMe驅動hook傳遞了一小部分內核的狀態。作者測試了兩個KV存儲——BPF-KV,一個簡單的B+樹KV存儲,和WiredTiger,一個流行的LSM樹的存儲引擎,并證明了它們從XRP中可以獲得極大的帶寬和延遲收益。
【背景和動機】
1、動機實驗配置
| CPU | 6-core i5-8500 3GHz |
| DRAM | 16GB |
| Ubuntu | 20.04 |
| Linux | 5.8.0 |
| Processor C-states | no |
| turbo boost | no |
| governor | maximum performance |
| KPTI | no |
2、軟件開銷成為存儲性能瓶頸
如下圖,像3D-Xpoint這樣的新介質和低延遲NAND可以讓新的NVMe設備表現出個位數微秒級延遲和1e6(十萬)級別的IOPS。從訪問一代快速NVMe設備開始,軟件開銷占比就達到15%,到現在訪問最新的NVMe設備時,軟件開銷占比達到50%。
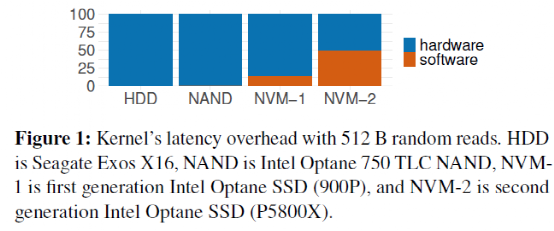
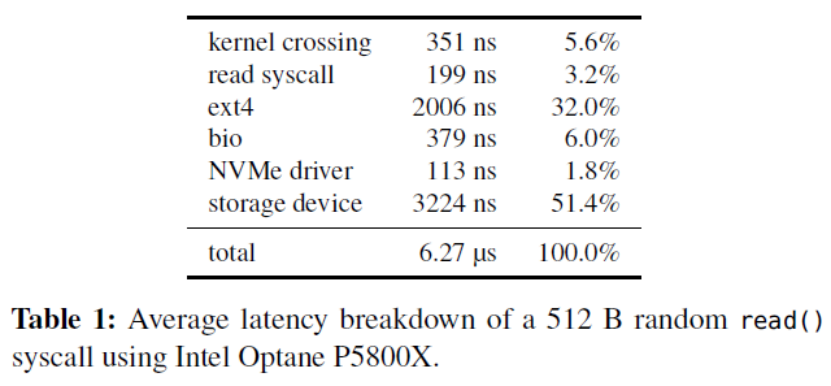
作者進一步對內核軟件開銷進行分解,其中使用了O_DIRECT繞過了page cache。如下表,開銷最大的層是文件系統層(ext4),其次是塊設備層(bio)和kernel crossing(上下文切換),整體軟件開銷占比達到48.6%。
那么,為什么不直接繞過內核呢?
這種辦法并非靈丹妙藥:這意味著把存儲設備的訪問完全暴露給應用,同時應用必須實現自己的文件系統——這意味著沒有保證數據孤立的機制,不同應用無法共享同一個設備的空間。此外,用戶態應用也無法接受中斷——這意味著當I/O并非性能瓶頸時,CPU資源會被浪費,利用率低下。而且當多個polling的線程共享一個CPU時,CPU競爭+缺乏同步機制會導致所有polling的線程的尾端延遲巨大,帶寬巨低。
3、BPF簡介
BPF(Berkeley Packet Filter)是一個允許用戶把一個簡單的函數注入內核執行的接口。Linux中實現的BPF框架叫eBPF。函數在注入前,需要經過幾秒鐘的檢驗(verification),隨后這個eBPF函數就可以被正常調用了。
BPF的潛在優勢
當一個請求需要進行多次I/O查找(resubmission)時,BPF可以避免內核態和用戶態之間的數據遷移。例如,查找B樹的索引時,需要先從根節點查起,直到找到葉子節點。而這一過程若使用多個系統調用,則每一次系統調用都要遍歷整個內核存儲棧。而若使用BPF函數,可以把剛剛的查找函數注入NVMe驅動層,這樣只有第一次查找需要遍歷整個內核存儲棧,之后的查詢結果只需要返回驅動層即可。二者的對比如下圖:
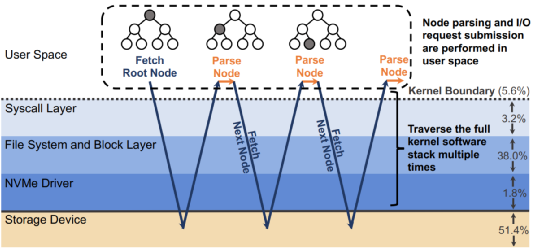
B-Tree Lookup from User Space
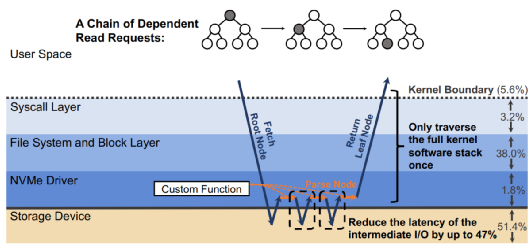
B-Tree Lookup With an In-Kernel Function
其他數據結構(LSM樹)、其他操作(范圍查詢、迭代、計算統計數據)也可以從這種機制中獲益。這些操作的特點是有大量“中間“(或者說”備用“)的I/O操作,而對用戶而言只需要最后的單個結果或者I/O返回的一小部分對象。
除了在NVMe驅動層,BPF函數也可以放在其他層,如系統調用。下圖是普通的系統調用和兩個使用BPF函數分發(或者重發)I/O操作時的不同路徑。
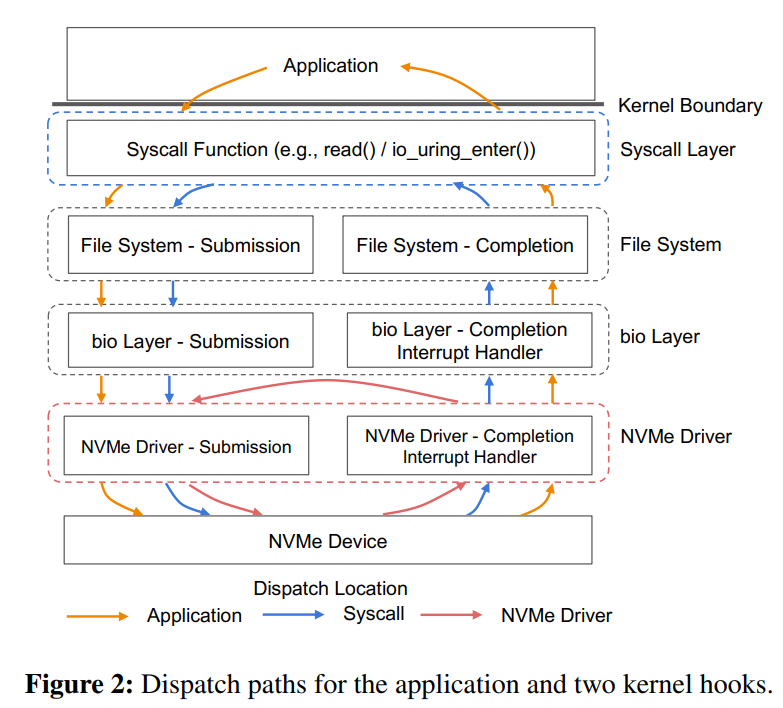
作者在21年HotOS上的文章中比較了BPF函數在這兩個不同地方時獲得的性能收益,如下表,比較的基準是read()系統調用。

當CPU達到飽和態后,在NVMe驅動層重發I/O請求帶來的提升最終轉化為1.8x-2.5x的帶寬增大。(具體增大多少取決于工作集中線程的數目)
擴展:線程的數目如何影響帶寬的提升呢?
當CPU未飽和時,線程越多,提升越小。而CPU飽和后,提升更加明顯。下圖6個線程后CPU飽和。
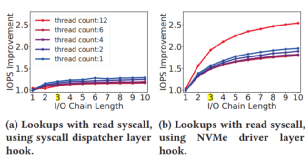
BPF函數越靠近底層,性能提升越大。所以,XRP的重發hook放在NVMe驅動層。
前文提到的都是同步I/O,那么異步I/O的表現如何呢?
Linux內核新提出的io_uring可以實現批量下發異步I/O,一定程度上攤銷了用戶態陷入內核態的開銷。然而每一個I/O請求依然要穿過整個內核存儲棧。事實上,io_uring和BPF I/O重發可以相互補充:
io_uring可以高效地批量下發I/O請求,而每個I/O請求觸發不同的I/O鏈,eBPF函數處理這樣的I/O鏈。下圖是和只使用io_uring相比,使用io_uring+BPF hook時的帶寬提升。
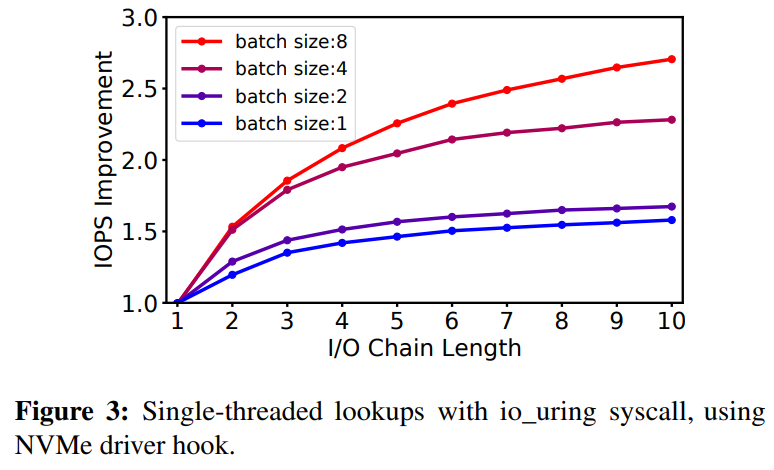
注:I/O Chain Length指初始I/O和重發的I/O總數(如,B-樹的深度);batch size指在每個io_uring調用中打包的系統調用數。
【設計挑戰與原則】
1、挑戰1:地址轉化和安全
以索引查詢為例,XRP會處理一個讀I/O請求,然后調用BPF函數解析下一個塊的偏移量。然而,對NVMe層而言,這個偏移量沒有任何意義——因為它缺乏文件元數據,所以不知道這個偏移量對應的塊號。開發者確實可以把塊的物理地址也編進去,但是這樣一來,BPF函數可以訪問設備上的任何塊——而有些塊用戶沒有訪問權限。
2、挑戰2:并發訪問
在NVMe驅動層的XRP無法看到page cache層的寫。若有的寫操作修改了數據結構的layout(如指針指向的下一塊),而與此同時,若有一個讀請求在訪問這一部分,XRP可能會訪問到錯誤的數據。這些可以通過鎖解決,但是在NVMe驅動層訪問鎖開銷過高。
觀察:大多數盤上的數據結構是穩定的。
許多存儲引擎(B樹、LSM樹)的文件相對穩定。有些數據結構不會就地更新盤上數據,如當LSM樹寫它的索引文件(SSTable)時,在它們被刪除前,這些文件都是不可修改的。這樣同步就不用那么費勁了。有些B樹的實現雖然實現了就地更新,他們的文件的extent基本上穩定。作者使用YCSB在MariaDB上運行TokuDB 24小時,使用B樹,發現文件的extent平均每159秒改變一次,所以可以在NVMe驅動層緩存文件系統元數據。
3、設計原則
一次只處理一個文件的鏈式重發
不支持遍歷需要鎖的數據結構
用戶定義的cache(不支持page cache)
慢路徑回調:若XRP的遍歷失敗了,應用要試著重新試一次,或者使用系統調用來分發I/O請求。
【XRP的設計與實現】
本論文中,XRP基于Linux的eBPF和ext4文件系統。
1、修改NVMe驅動中的中斷控制器:實現重發I/O
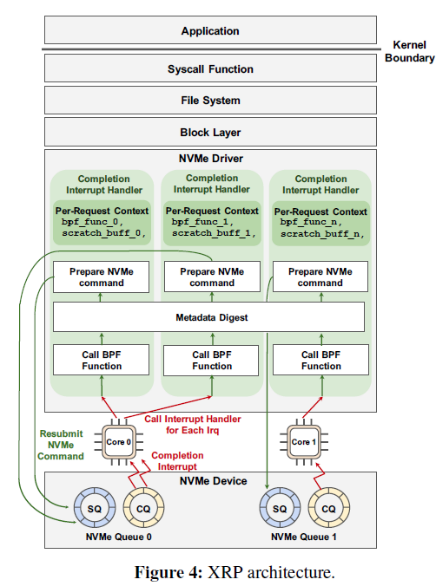
當NVMe請求完成時,設備向主機發送中斷,進入中斷處理器,此時XRP通過bio調用BPF函數,訪問元數據摘要,進行地址轉化,最后準備下一個NVMe請求,并重發,把請求放入NVMe提交隊列(SQ)中。
具體重發的次數是由NVMe請求注冊的特定BPF函數決定的。例如查找一個數狀的結構,那么遇到中間節點時BPF函數會重發,直到遇到葉子節點時終止。目前的XRP實現中,對重發次數沒有硬限制。如果需要實現,可以在I/O請求描述器中增加一個重發計數器。這個計數器既不能被用戶訪問,也不能被XRP的BPF函數訪問,所以即使多個BPF函數執行重發,計數器也不會超量。
BPF函數的上下文以請求為單位的,而元數據摘要則所有核和中斷控制器共享,它的同步訪問由RCU(read-copy-update)控制。
1.1 BPF hook
BPF的每個類型對應對應一種程序,XRP引入了新的BPF類型——BPF_PROG_TYPE_XRP。它的簽名如下:

任何符合這個簽名的BPF程序都可以被這個hook調用。下一部分會展示一個具體的符合該簽名的BPF程序。
BPF_PROG_TYPE_XRP程序的上下文有五個域:
| data | 緩存從磁盤讀上來的數據(如一個B-樹頁) |
| done | 標識重發是否完成的布爾變量 |
| next_adr | 下一個塊的邏輯地址的數組 |
| size | 下一個塊的大小的數組(0表示沒有I/O) |
| scratch | 一個緩沖區,用于用戶向BPF函數傳遞參數、或者BPF函數存儲I/O重發過程中的中間數據、或者向用戶返回數據。 這個buffer的大小為4KB,若需要存儲更多的中間數據,BPF函數可以使用BPF map。 |
每個BPF上下文都為一個NVMe 請求所私有,因此使用BPF上下文時不需要鎖。而且,由用戶提供一個scratch緩沖區,而非使用BPF map,避免了進程和函數不得不調用bpf_map_lookup_elem來訪問scratch buffer。
1.2 BPF Verifier
BPF的寄存器分為scalar和pointer兩種,其中pointer有不同的類型,如PTR-TO-MEM,指向一塊固定大小的內存區域。在XRP上下文中,data和scratch的類型是PTR TO MEM,而剩下的是scalar。BPF Verifier會根據數據類型檢測寄存器的數據,防止訪問區域外的數據。
此外,作者還實現了XRP類型對應的is_valid_acces()函數,可以檢測對上下文的訪問是否正確以及返回上下文域的值的類型。1.3 元數據摘要
中斷控制器并沒有文件以及邏輯地址到物理地址的轉換的概念。作者在此實現了“元數據摘要“,即一個中斷控制器與文件系統之間的接口,這樣,文件系統就可以和中斷控制器共享地址映射了從而支持基于eBPF的盤上重發。
元數據摘要包括兩個部分,如下圖:

更新函數:當地址映射被更新時,由文件系統調用
查詢函數:由中斷控制器調用,返回給定偏移和長度的地址映射。同時也實現了訪問控制。
這兩類函數的實現方式多種多樣,例如在本文中,作者實現了ext4的extent狀態樹的緩存,因此元數據摘要中包括了這個狀態樹的版本號。同時使用RCU進行并發控制——查詢函數可以很快而且無鎖。當extent更新的同時還有查找在進行,extent的版本號會更新。查找到的數據在返回BPF函數前會進行二次查詢,若發現版本號不一致,則放棄本次操作。
不過,一般應用不會允許查找與更新同一塊區域同時進行,所以若發生這種情況要么是應用代碼出錯,要么是惡意應用。
當然,也可以不實現extent狀態樹緩存——這樣update函數什么也不用做。但是,此時查詢需要先獲得自旋鎖,會變慢很多。
目前的XRP只支持ext4文件系統。但如f2fs等的元數據摘要也可以輕易實現。
1.4 重發NVMe請求
為了避免調用kmalloc的開銷,XRP重用舊的NVMe請求結構,在重發時僅僅修改physical sector和block address。
不過,重發的I/O請求只能抓取和舊I/O請求一樣多的物理段。如果BPF函數返回了多個指針(next_addr),而NVMe請求不支持這多物理段的抓取,那么XRP會拋棄這個請求。
2、同步控制
BPF目前僅支持自旋鎖,而且同時只能獲得一個鎖,且在結束前必須釋放這個鎖。用戶應用也無法直接訪問這個鎖,必須經過系統調用bpf()來讀寫鎖保護的區域。因此,需要在多個讀和寫之間同步的復雜的修改無法在用戶態實現。
用戶也可以使用BPF的原子操作自己實現自旋鎖,這樣用戶和BPF程序都可以直接獲得這個鎖。但是,BPF函數不能一直等待鎖被釋放——無法通過verifier。
另一種實現同步的方式是用RCU,XRP BPF程序在NVMe中斷控制器中實現,這本身就是不可搶占的,所以它們已經在RCU的讀關鍵區了。
3、和Linux調度器的交互
進程調度器:
作者觀察到,超低延遲存儲和Linux的CFS調度器存在沖突,例如當I/O密集進程和計算密集進程共享一個核時,I/O密集進程產生的中斷可能打斷計算密集進程的運行,導致計算密集進程被餓死。最壞的情況下,計算密集進程只能獲得34%的CPU時間。而當使用較慢的設備時,則不存在這個問題。XRP進一步加劇了這個問題——產生多個鏈式中斷。作者把這一問題留給未來的工作解決。
I/O調度器:
XRP bypass了Linux的I/O調度器。不過,noop調度器目前已經是NVMe設備的默認I/O調度器。而若需要保證公平,它們在硬件隊列中有仲裁機制。
【案例分析】
如下圖,應用可以通過調用這些函數來使用XRP。

bpf_prog_load:一個已有的函數。用于加載BPF_PROG_TYPE_XRP類型的BPF函數到驅動中。
read_xrp:用戶可以用它把一個特定的BPF函數應用到一個具體的請求上。
在這一部分中將介紹兩個案例,以表明應用應該做什么樣的修改來使用XRP。
1、BPF-KV
BPF-KV是作者構造的一個簡單的KV存儲,它用來存儲小對象并且提供優秀的讀性能。其中,BPF-KV的索引結構是B+樹,而對象存儲在一個無序的日志(log)中。簡單起見,BPF-KV使用固定大小的key(8B)和value(64B)。索引和日志一起被放在一個大文件里。索引節點(index node)使用簡單的頁結構(每個index node就是一個頁):頭+key+value;葉子節點包含一個指向下一個葉子節點的文件偏移量。對象的大小固定(64B),所以對象可以在log中被就地更新,新插入的項會被附加在log后面,它們的索引一開始存儲在內存的哈希表中,而當哈希表滿后,BPF-KV會將其和盤上的B+樹文件混合。
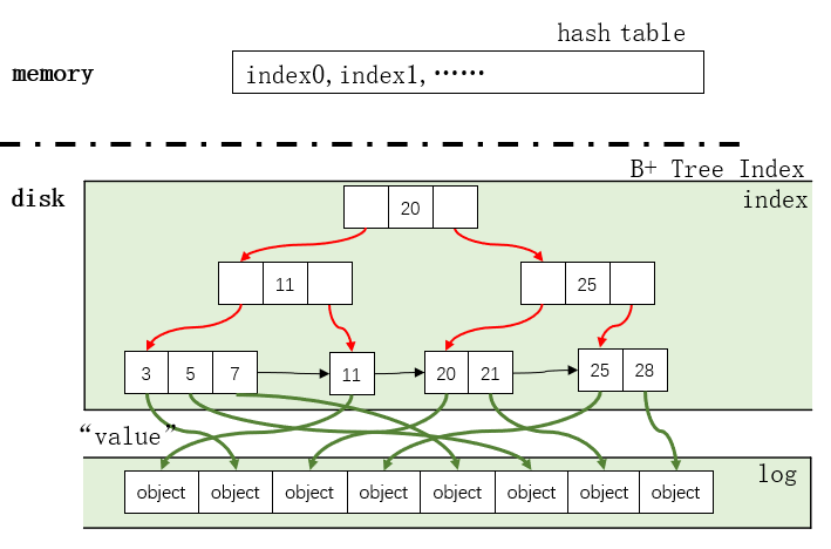
1.1 緩存
為了減少查找時的I/O數量,BPF-KV把頭k層B+樹索引緩存到內存中。當object足夠多時,不可能在內存中緩存全部的索引。若BPF-KV用于存儲10 billiion 64B對象,index node的大小是512B(和Optane SSD的訪問粒度匹配),因此,每個中間節點可以存儲31的指向孩子的指針。因此,10 billion的object需要8層index。
注:
設B+樹有n層,則葉子節點層有
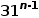 個指向object的指針,而object有
個指向object的指針,而object有 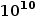 個,解得n=8.
個,解得n=8.
把6層放到DRAM里面已經很貴了(14GB),更別說7層(436GB)或更多了。所以,為了支持更多的key,在每次查詢中,BPF-KV會需要至少3~4個I/O(包括最終的I/O)。
除此之外,BPF-KV還有一個LRU對象緩存,里面存儲了最近最常使用的key-value對。
當查詢一個object時,先查找LRU對象緩存,若沒找到,則在hash表中查找index,若沒找到,則在前k層緩存的index中查找。若遇到了不在內存中index,則在磁盤中查詢。
1.2 BPF函數
下圖是在BPF-KV中使用的BPF函數,此處忽略了最終步(查詢log)的部分。struct node地能夠以了B+樹的index node的layout(大小為512B)。BPF函數bpfkv_bpf首先從scratch中提取目標key,然后搜索當前節點找到要讀的下一個節點。
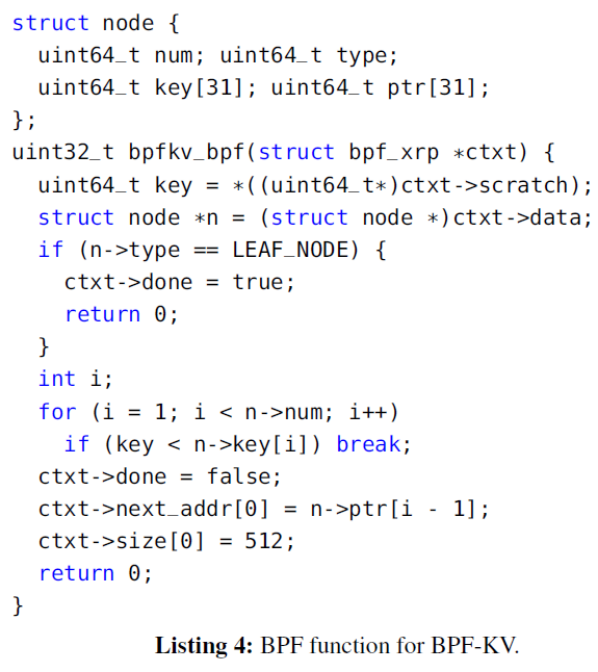
1.3 接口修改
作者把read()系統調用換成了read_xrp(),在調用read_xrp之前,BPF-KV會先分配scratch空間,計算開始查詢的offset。
1.4 范圍查詢
BPF-KV支持返回一些object的范圍查詢。在scratch中,存儲了BPF函數的狀態(查詢的范圍)和已接受的object。scratch最多頓出32個72 byte的key-value對。第一次調用時,函數找到具有開始key的葉子節點,隨后把葉子節點存在scratch中,隨后在緩存中葉子節點中查找,當葉子節點讀完后,函數提交下一個葉子節點的查找,依次類推。當找到范圍末端/查完整個index集/scratch空間滿了之后,函數返回。
1.5 統計計算(Aggregation)
BPF-KV支持如SUM、MAX和MIN的統計計算。這個計算是基于返回查詢的,在范圍查詢的上層設置了一個bit標識是否要統計計算。計算后的值存在scratch中。
2 WiredTiger
WiredTiger是MongoDB默認的KV存儲。其使用LSM樹組織數據:數據被分到不同的層,每一層都有一個單獨的文件,每個文件中使用B-樹索引(頁大小為512B),而KV對存在樹的葉子節點中。這些文件是只讀的,更新和插入都會先寫入內存的buffer中,buffer滿之后,數據會寫入一個新的文件。作者修改了大約500行代碼,包括buffer分配、擴展函數簽名和封裝XRP系統調用。XRP加速磁盤讀,不會影響更新和插入。
2.1 BPF函數
WiredTiger安裝了和BPF-KV中類似的BPF函數,不同點在于查找下一個node的指針時,WiredTiger的BPF函數把原有的for循環換成解析WiredTiger的B樹節點頁的端口。
2.2 緩存
WiredTiger使用LRU鏈表把一部分內部節點和葉子節點緩存在cache中。當查詢一個新的KV對時,WiredTiger把整個查詢路徑(包括葉子節點)緩存下來。為了遵從WiredTiger的語義,上文中提到的BPF函數額外返回了所有查詢的節點,這樣WiredTiger就可以緩存它們了。這些查詢到的節點會放在scratch里,當scratch滿了后,BPF函數直接返回。WiredTiger把這些節點加入cache后,它再次調用read_xrp,繼續查詢。
scratch的大小是4KB,所以它一共可以存6個查到的512B大小的節點(預留了1KB存必要的元數據)。
2.3 接口修改
作者把普通的read系統調用全部換成了read_xrp。WiredTiger的緩存策略保證了未緩存的節點沒有已緩存的兒子,所以可以放心調用read_xrp返回剩余的讀路徑上的節點。如果read_xrp失敗了,WiredTiger會調用舊的查詢辦法。data和scratch會事先分好以避免分配和釋放緩沖區的開銷。WiredTiger同時只處理一個請求,以避免并發。
【評估測試】
| CPU | 6-core i5-8500 3GHz server |
| DRAM | 16GB |
| Ubuntu | 20.04 |
| Linux | 5.12.0 |
| SSD | Intel Optane 5800X |
| page cache | no(繞過了page cache) |
| hyper-threading | no |
| processor C-states | no(不支持進入低功耗模式) |
| turbo boost(睿頻加速) | no(以保證CPU頻率穩定) |
| governor | maximum performance(讓CPU性能最高) |
| KPTI | yes(保證BPF程序無法竊取內核信息) |
| WiredTiger | 4.4.0(目前最新版本11.1.0) |
Baselines:
(a) XRP
(b) SPDK
(c) read()
(d) io_uring syscalls
1、在存儲場景下使用BPF的開銷有多大?
1.1 延遲
在本實驗中,作者執行了
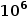 次隨機讀操作。為了關注查詢盤上數據的開銷,作者關閉了內存的緩存(緩存對象和緩存index)。平均延遲的對比如下表,最左一列的I/O數不包括獲得最終要的數據的最后一次I/O。
次隨機讀操作。為了關注查詢盤上數據的開銷,作者關閉了內存的緩存(緩存對象和緩存index)。平均延遲的對比如下表,最左一列的I/O數不包括獲得最終要的數據的最后一次I/O。
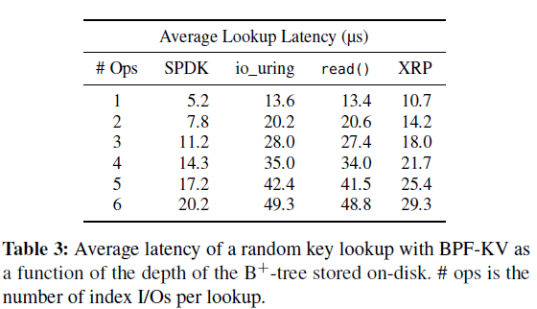
1)因為XRP省去了大部分軟件棧的開銷,相比read(),XRP的性能更好。而且,可以看到每增加一次index I/O,XRP的延遲增加3.5~3.9μs——約等于設備的延遲,側面證明XRP幾乎實現了重發請求的最優性能。
注意,重發request是同步的,所以io_uring和read的表現差不多。
2)SPDK的性能比XRP要好,因為在第一次I/O時,XRP依然要穿過整個I/O棧。但是XRP不需要使用polling,進程可以繼續利用CPU完成其他事情。下圖是99和99.9的尾端延遲隨著線程數的增加的變化。
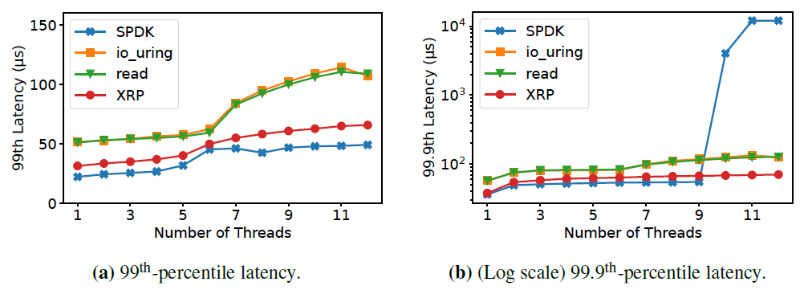
當線程數超過9之后,SPDK的99.99尾端延遲劇烈增加,因為它們的線程使用輪詢,無法高效共享CPU。作者還測試了請求延遲大于等于1ms的占比,如下圖:
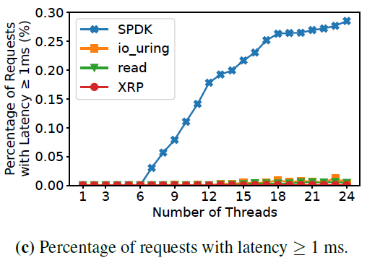
當線程數為7時,SPDK有0.03%的請求延遲大于1ms,而當線程數達到24時,這個比例達到0.28%。而其他幾個機制,這個比例一直低于0.01%。
1.2 帶寬(注意單位是KOPs)
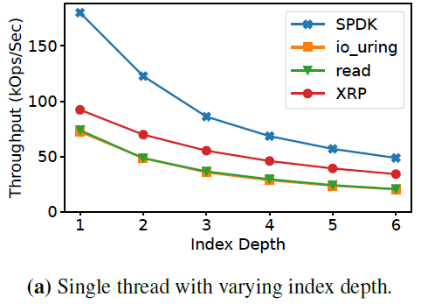
如下圖,當index深度增加時,XRP的帶寬提升和標準的系統調用相比更高了。
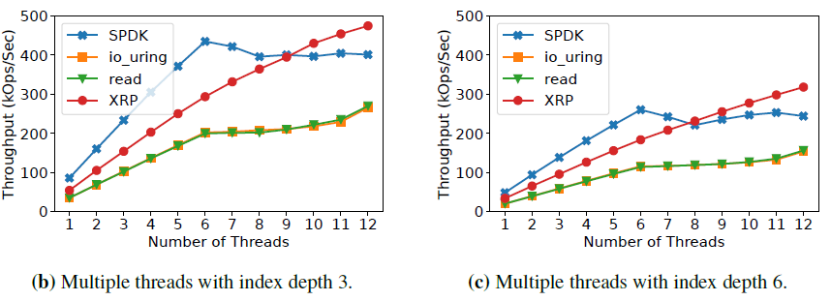
下圖是當index深度分別為3和6時,隨著線程數提升的帶寬變化。可見當I/O和XRP函數被擴展到多個核時,XRP的帶寬提升相比標準系統調用并沒有下降。此外,當線程數超過9后,XRP的帶寬和SPDK相等甚至更高。
2、XRP擴展到多線程場景下表現如何?
現在的存儲應用常常使用大量線程訪問存儲設備,因此XRP也需要在多線程下表現良好。在本實驗中,作者進行了一次open loop實驗,負載量和Intel設備的最大帶寬一致(5M IOPS),如下圖,index深度為6時,XRP(內部是io_uring)和SPDK在BPF-KV中的帶寬隨線程數的變化。
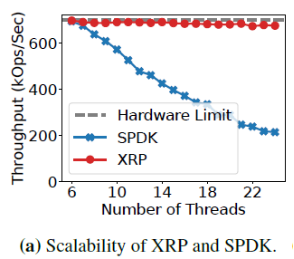
當使用6個線程時,SPDK和XRP都可以達到硬件允許的最大帶寬。而線程數增多后,SPDK的帶寬開始下滑。因為SPDK的輪詢線程必須等到Linux CFS調度(6ms)后才能被迫放棄CPU,而XRP的空閑線程可以主動放棄CPU,讓CPU做有意義的工作。
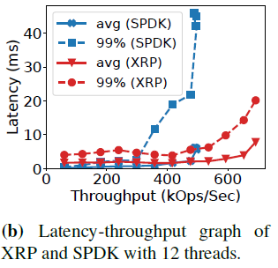
下圖是12個線程時,隨著負載的變化,帶寬和延遲之間的關系變化。可見SPDK中平均延遲和尾端延遲都比XRP增長更快。
3、XRP在范圍查詢的場景下表現如何?
每次范圍查詢時,都先執行一次index檢索找到第一個對象,之后遍歷葉子節點找到后面的對象。樹的深度為6,盡管XRP一次只能檢索32個對象,但由下圖可見和read相比,XRP提高的延遲很穩定。
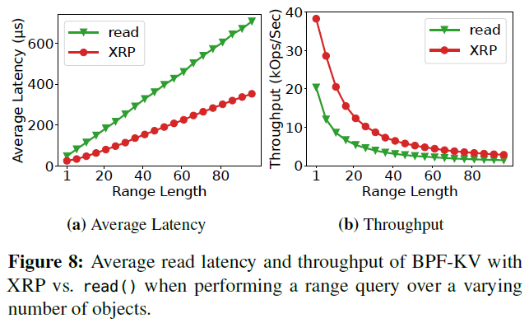
4、XRP可以加速真實世界的KV存儲嗎?
作者使用YCSB產生負載,在WiredTiger中評估了XRP的性能。作者使用了YCSB A、YCSB B、YCSB C、YCSB D、YCSB E、YCSB F六種不同的負載,每種負載運行的時間接近。A、B、C、F中有10M個操作,D中有50M個,E中有3M個。
baseline:
pread()
read_xrp()
configure:
key-value中key和value都16B,總大小為46GB。KV對一共有10^9對。當cahce塊滿時,WiredTiger會把頁剔除。使用2個剔除線程。
4.1 帶寬
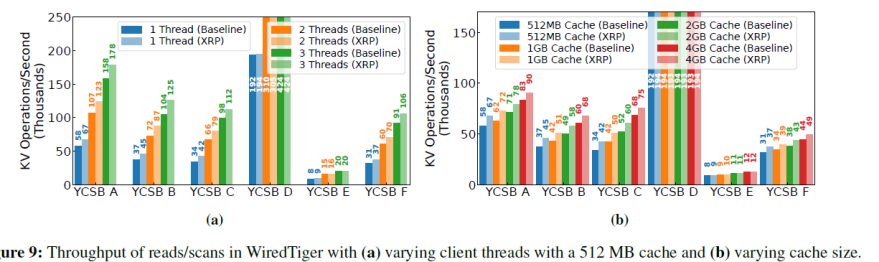
大部分工作集中,XRP有穩定的帶寬提升,其中最大提升1.25倍。緩存越大,XRP的提升越小。因為WiredTiger僅花費63%的時間在I/O操作上,所以相比BPF-KV,XRP對WiredTiger的提升更小。此外,在YCSB D和YCSB E中,XRP的提升不明顯。YCSB D中,最新插入的對象總是最常被訪問,所以大部分訪問都在cache中完成了。而YCSB E的大多數操作是遍歷和插入,在遍歷場景下,XRP只能在獲取遍歷的初始KV對時有收益,因為剩下的KV對一般在同一個葉子節點里或者只需要一次額外的I/O就可以獲得下一個葉子節點。
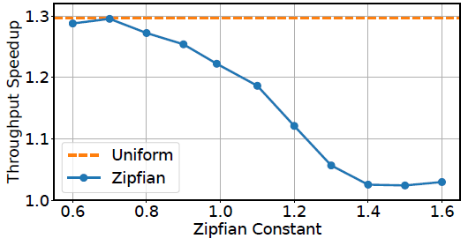
作者進一步探究了負載的偏移對XRP性能的影響。如下圖是調整TCSB C中Zipfian分布的不同常數和均勻分布的性能提升對比,可見負載偏移越大,XRP的提升越小(注,正常這個常數>0.99后說明負載偏移程度非常大了)。
4.2 尾端延遲
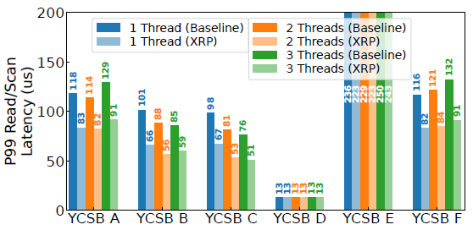
作者讓每個YCSB ABCDF的每個線程以20kop/s的速率下發負載,而YCSB E以5kop/s的速率下發負載。如下圖,XRP最多可以減少40%的尾端讀延遲(YCSB E是scan延遲)。和帶寬類似,隨著cache size大小增大,XRP的尾端延遲減少下降了。
致謝
感謝本次論文解讀者,來自華東師范大學的碩士生俞丁翠,主要研究方向為高性能存儲優化。
-
內核
+關注
關注
3文章
1416瀏覽量
41451 -
存儲
+關注
關注
13文章
4533瀏覽量
87486 -
程序
+關注
關注
117文章
3826瀏覽量
83018
原文標題:談談利用eBPF程序繞過內核以加速存儲訪問
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
解構內核源碼eBPF樣例編譯過程
關于 eBPF 安全可觀測性,你需要知道的那些事兒
如何利用C/C++編寫應用程序加速內核運行

一文手把手教你Android中的 eBPF 流量監控
教你們如何使用eBPF追蹤LINUX內核
openEuler倡議建立eBPF軟件發布標準
Linux 內核:eBPF優勢和eBPF潛力總結
Linux內核觀測技術eBPF中文入門指南
什么是eBPF,eBPF為何備受追捧?
eBPF,何以稱得上是革命性的內核技術?

基于ebpf的性能工具-bpftrace

ebpf的快速開發工具--libbpf-bootstrap
eBPF動手實踐系列三:基于原生libbpf庫的eBPF編程改進方案簡析






 工商網監
工商網監
評論