 新品發布|啟英泰倫聯合啟明云端推出離在線語音大模型方案
新品發布|啟英泰倫聯合啟明云端推出離在線語音大模型方案

當前,生成式大模型正以顛覆性姿態重塑人機交互的邊界,并逐漸向終端場景滲透。然而,云端大模型在落地終端場景時面臨兩大挑戰:1. 在真實噪聲場景下容易聽不清、誤識別,影響交互準確性;2. 云端處理冗余數據及大規模計算任務帶來的響應延遲。其根本原因在于缺乏一顆強計算性能的端側語音處理芯片。

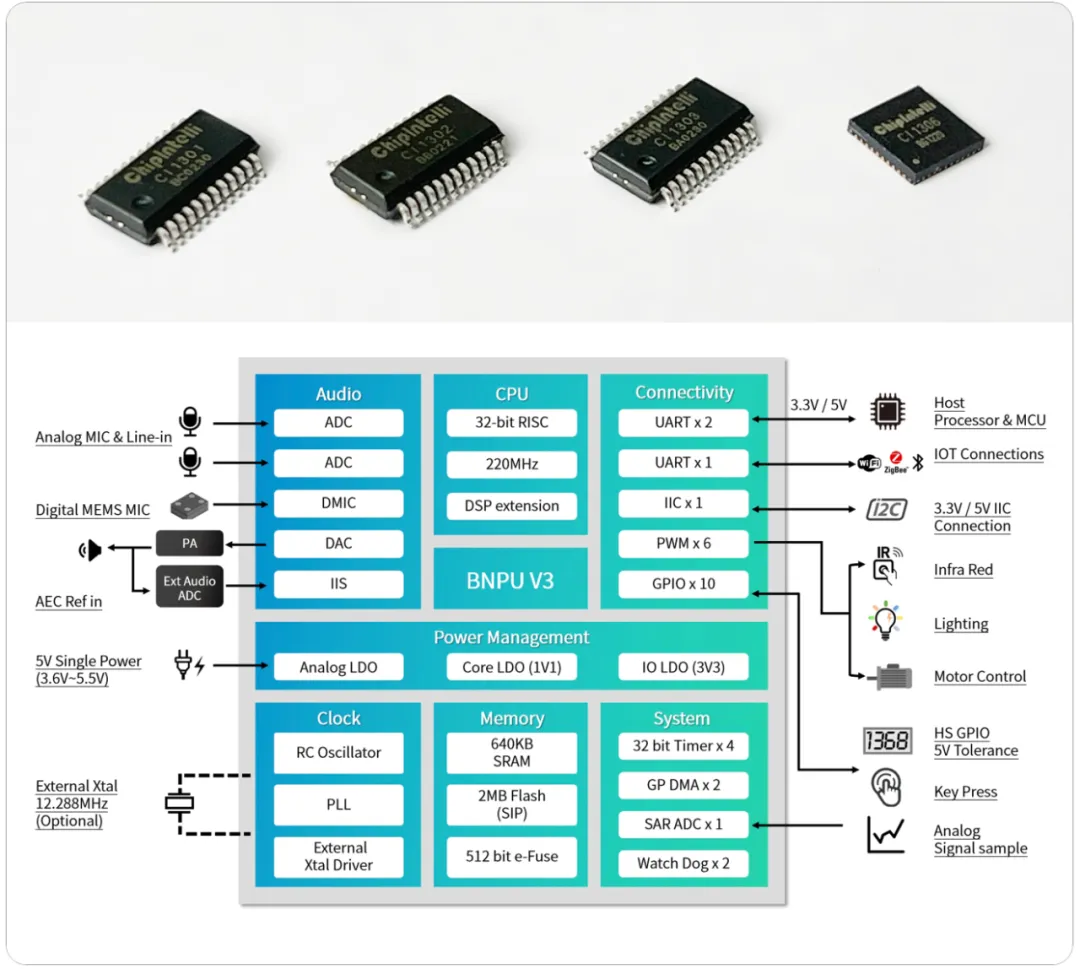
近日,啟英泰倫聯合啟明云端正式推出WT01C202-AI-S1高性能離在線語音大模型方案。該方案基于啟英泰倫CI130X系列神經網絡語音芯片,可實現語音識別、語音端點檢測、深度學習降噪、回聲消除、聲源定位、音頻壓縮、流媒體播放等功能,同時可對接豆包、文心一言、ChatGPT、Deepseek等大模型,充分發揮大模型在語義理解與內容生成方面的優勢。通過端-云協同設計,將簡單任務(如喚醒、降噪)在本地完成,復雜任務(如自然語言理解)交由云端處理,實現低延遲、高準確率的交互體驗。
具體優勢如下:
01
支持基于DNN的本地語音喚醒及識別
針對設備的各項功能控制,無需按鍵,無需聯網,通過該方案可直接進行本地離線語音喚醒和識別。數據無需上傳云端進行分析和決策,大大提升了響應速度。
02
支持基于DNN的端點檢測
采用先進的端點檢測(VAD)技術,通過深度學習與硬件加速的融合設計,在穩態噪聲和非穩態噪聲環境下均能精準識別人聲起始點和終點。僅在檢測到人聲時進行喚醒,其余時間保持低功耗休眠狀態,避免了云端一直監聽環境聲音,將全部音頻上傳云端分析帶來的高帶寬和流量消耗。其響應速度達到毫秒級,作為云端大模型的“智能哨兵”,為后續的語音處理流程提供了高效、精準的支持。
03
支持基于DNN的語音降噪
采用基于DNN的深度學習語音降噪技術,使得該方案具備更強的自適應性和泛化能力,能夠在不同的噪音環境中保持優異的降噪效果,為云端大模型提供了更干凈的語音,極大提升了云端大模型的語音識別準確率。
04
支持基于DNN的回聲消除打斷
基于自適應線性濾波聯合基于深度學習的非線性濾波的回聲消除方案可有效抑制回聲,且能做到實時打斷,讓用戶無需漫長等待即可繼續進行語音指令輸入,保障了用戶體驗的流暢性與即時性。
05
支持基于DNN的聲源定位
基于麥克風陣列與波束成形算法,實現多場景下的指向性交互,提升人機交互的自然性和人性化。例如,在機器人或智能玩具中,設備可根據聲源方向轉頭或移動,不僅增強了產品的可玩性與趣味性,還為用戶帶來更具沉浸感的交互體驗。
06
支持多語種
啟英泰倫自主開發多個小語種模型,支持漢語、英語、日語等多種語言輸入,能夠滿足不同地區、不同語言背景用戶的多樣化需求,為產品的國際化推廣奠定了堅實基礎。
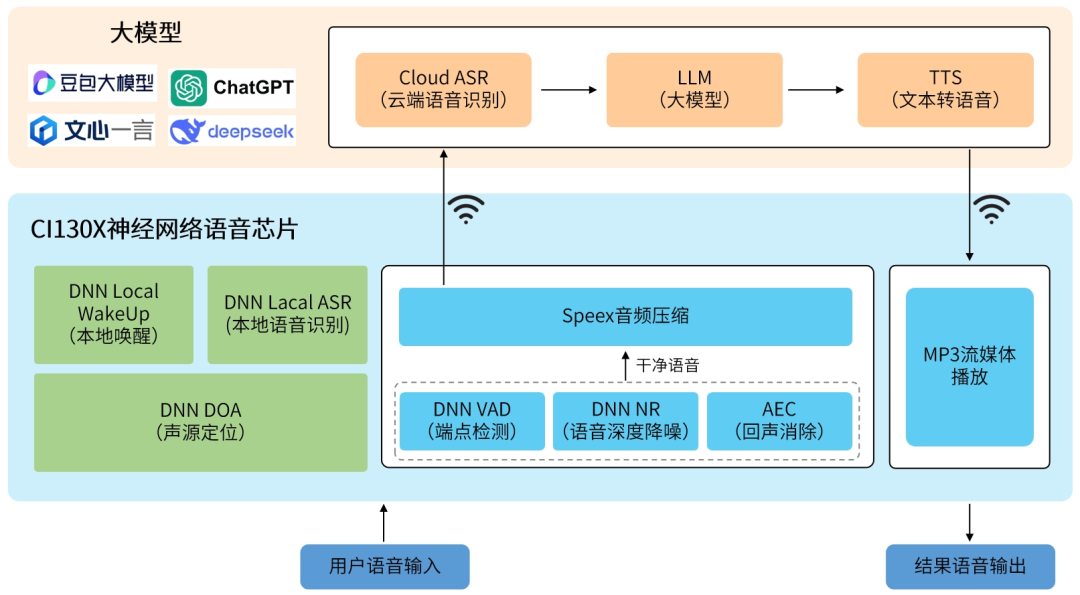
方案應用架構該方案支持國內外各大大模型平臺,包括豆包、文心一言、ChatGPT、Deepseek等,為企業或開發者提供高效便捷的多模型選擇。通過此方案,用戶能夠輕松實現一站式開發,無需繁雜切換,即可在不同大模型間無縫過渡與調用。
WT01C202-AI-S1模組方案憑借其卓越的性能和豐富多樣的功能,具備極為廣泛的應用前景,可應用于家電、玩具、文創、機器人等眾多產品領域,幫助企業在國際市場上實現語音交互等各類智能語音方案應用。
-
dnn
+關注
關注
0文章
61瀏覽量
9262 -
啟英泰倫
+關注
關注
1文章
54瀏覽量
1594 -
大模型
+關注
關注
2文章
3114瀏覽量
4020
發布評論請先 登錄
語音助手只能聊天?啟明云端AI語音交互方案偷偷修煉了音樂才藝!

開發案例 | 用CI1302 AI語音開發板4步打造智能語音床頭小夜燈,手殘黨也能玩轉開發!

啟英泰倫亮相成都人工智能專場路演,發布具身智能新戰略!

喜訊丨啟英泰倫入選2025成都硬科技企業撲克牌榜單
智能語音交互的突破與應用,啟明云端AI大模型方案應用
【新品】搭載ESP32-C2芯片,啟明云端WT99C202-AI語音開發板震撼來襲,離在線一體
喜訊丨啟英泰倫榮登2024德勤中國高科技高成長50強榜單
【新品發布】啟明云端WT01C202-AI-S1模組來襲,為智能語音產品開發帶來新可能!
啟英泰倫新推出多意圖自然說,重塑離線人機交互新標準!
成都市科技局局長丁小斌一行調研啟英泰倫
啟英泰倫獲評國家級專精特新“小巨人”企業!
佛山市市委常委、常務副市長劉杰一行到啟英泰倫考察





 工商網監
工商網監
評論