") OpenAI公布MADDPG代碼,讓智能體學(xué)習(xí)合作、競(jìng)爭(zhēng)和交流
OpenAI公布MADDPG代碼,讓智能體學(xué)習(xí)合作、競(jìng)爭(zhēng)和交流
智能體(agent)互相爭(zhēng)奪資源的多智能體環(huán)境是通向強(qiáng)人工智能(AGI)的必經(jīng)之路。多智能體環(huán)境具有兩種優(yōu)越的特質(zhì):首先,它具備自然的考驗(yàn)——環(huán)境的難易程度取決于競(jìng)爭(zhēng)對(duì)手的技能(如果你正與自己的克隆體對(duì)抗,環(huán)境則完全符合你的技術(shù)水平)。其次,多智能體環(huán)境沒(méi)有穩(wěn)定的平衡,即無(wú)論一個(gè)智能體多么聰明,想變得更聰明總是有困難的。這種環(huán)境與傳統(tǒng)模式有很大的不同,在達(dá)到目標(biāo)之前需要進(jìn)行更多研究。
OpenAI開(kāi)發(fā)了一種名為MADDPG(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments)的新算法,用于實(shí)現(xiàn)多智能體環(huán)境中的集中式學(xué)習(xí)和分散式執(zhí)行,讓智能體學(xué)習(xí)互相合作、互相競(jìng)爭(zhēng)。
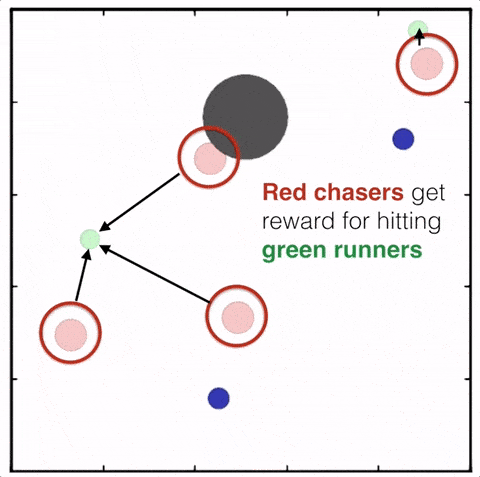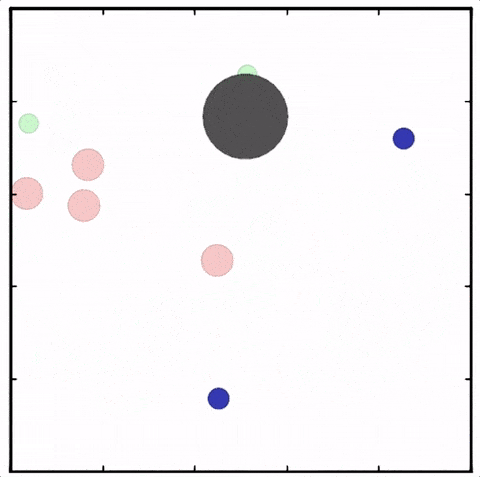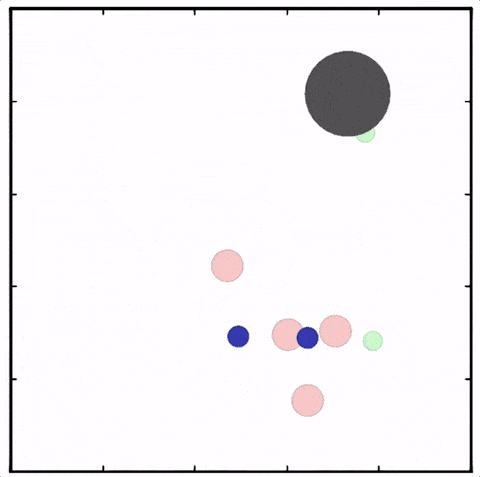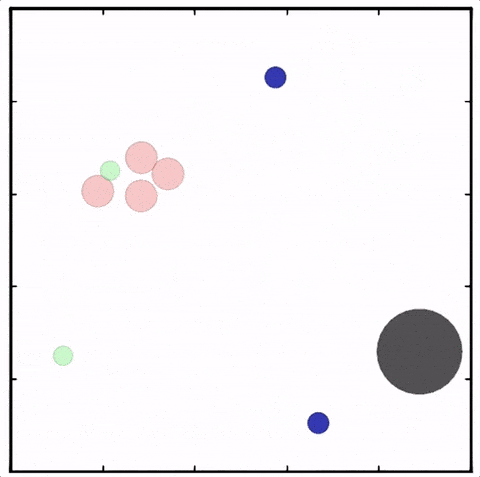
用MADDPG算法訓(xùn)練四個(gè)紅色圓點(diǎn)追逐兩個(gè)綠色圓點(diǎn),紅色圓點(diǎn)已經(jīng)學(xué)會(huì)彼此合作追逐同一個(gè)綠色圓點(diǎn),以獲得更高的獎(jiǎng)勵(lì)。與此同時(shí),綠色圓點(diǎn)學(xué)會(huì)了“分頭行動(dòng)”,其中一個(gè)被紅點(diǎn)追逐,其他的則試圖接近藍(lán)色圓點(diǎn)獲得獎(jiǎng)勵(lì),同時(shí)避開(kāi)紅色圓點(diǎn)
MADDPG對(duì)強(qiáng)化學(xué)習(xí)算法DDPG進(jìn)行擴(kuò)展,從actor-critic(玩家-評(píng)委)強(qiáng)化學(xué)習(xí)技術(shù)中獲得靈感;其他團(tuán)隊(duì)也正探索這些想法的變體和并行實(shí)現(xiàn)。
研究人員將模擬中的每個(gè)智能體看作“actor”(玩家),每個(gè)玩家從評(píng)委那里獲得建議,讓它們?cè)谟?xùn)練過(guò)程中選擇應(yīng)該加強(qiáng)哪些動(dòng)作的訓(xùn)練。在傳統(tǒng)環(huán)境中,評(píng)委嘗試預(yù)測(cè)在某一特定情況下一種動(dòng)作的價(jià)值(即我們期待未來(lái)獲得的獎(jiǎng)勵(lì)),從而讓玩家更新策略。這種方法比直接使用獎(jiǎng)勵(lì)更穩(wěn)定,獎(jiǎng)勵(lì)會(huì)導(dǎo)致較大的差異。為了能讓智能體進(jìn)行全局合作,研究者改進(jìn)了評(píng)委,使它們能夠訪(fǎng)問(wèn)智能體的觀察和行動(dòng),如下圖所示。
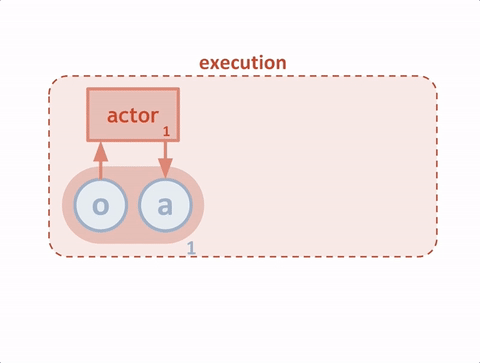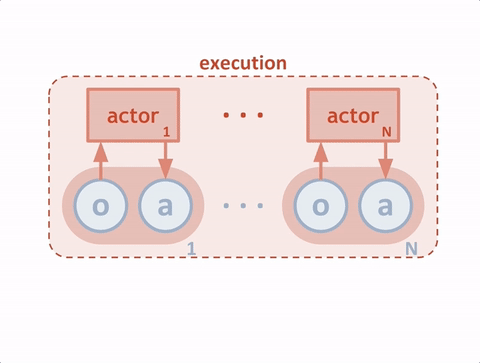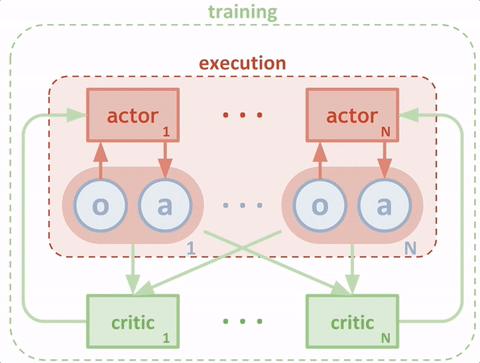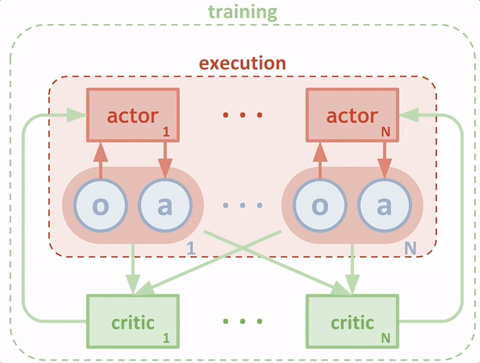
測(cè)試時(shí),智能體無(wú)需具備中間的評(píng)委;它們根據(jù)觀察以及對(duì)其他智能體行為的預(yù)測(cè),做出動(dòng)作。由于一個(gè)中心化的評(píng)委是為每個(gè)智能體獨(dú)立學(xué)習(xí)的,這種方法也可以用來(lái)模擬多智能體之間的任意獎(jiǎng)勵(lì)結(jié)構(gòu),包括擁有相反獎(jiǎng)勵(lì)的對(duì)抗案例。
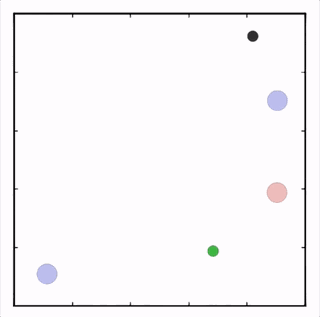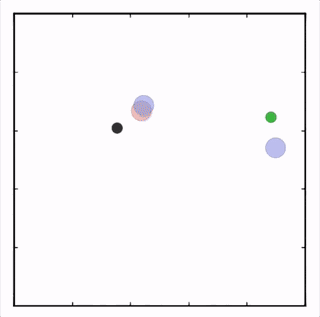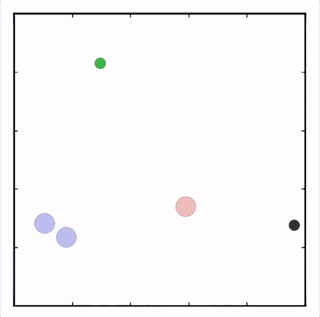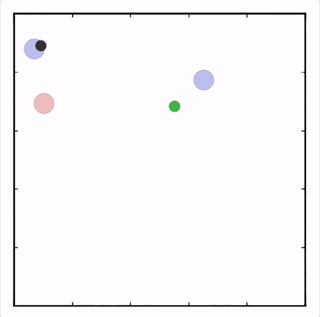
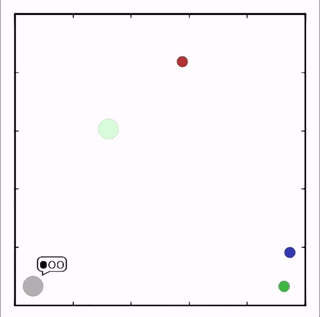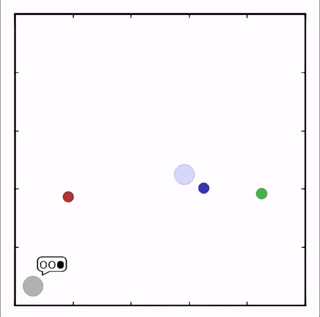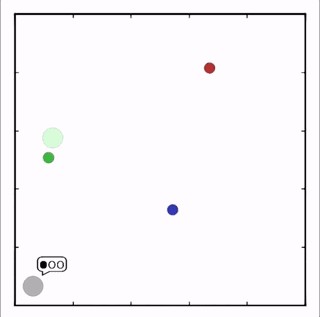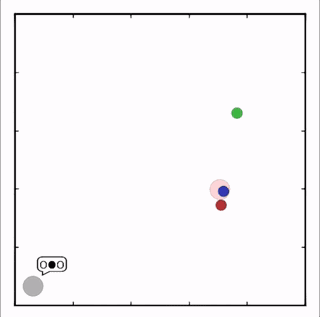
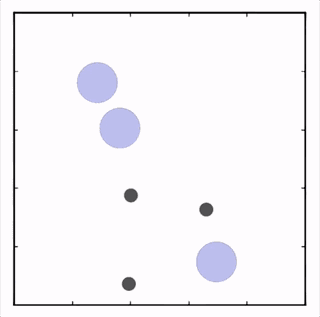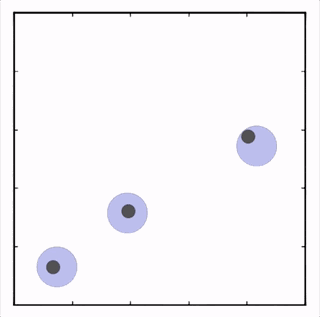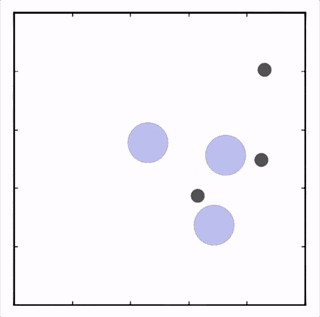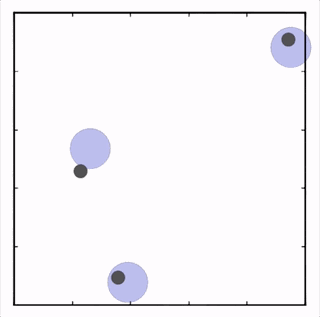
OpenAI研究者在多個(gè)任務(wù)上測(cè)試了他們的方法,結(jié)果均優(yōu)于DDPG上的表現(xiàn)。在上圖的動(dòng)畫(huà)中,從上至下可以看到:兩個(gè)智能體試圖前往特定位置,并且學(xué)習(xí)分散,向?qū)κ蛛[藏真實(shí)的目的地;一個(gè)智能體將位置信息傳遞給另一個(gè)智能體,其他三個(gè)智能體協(xié)調(diào)前往此處,并且不會(huì)碰撞。
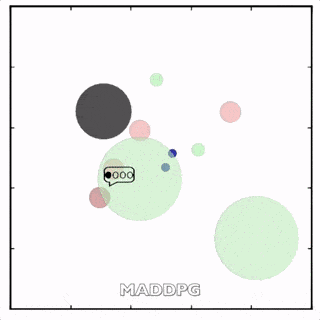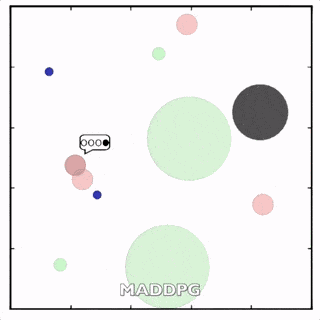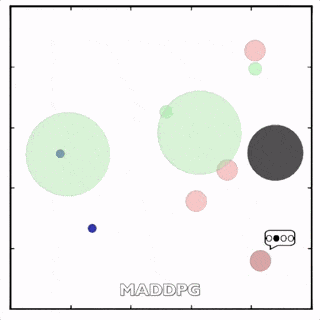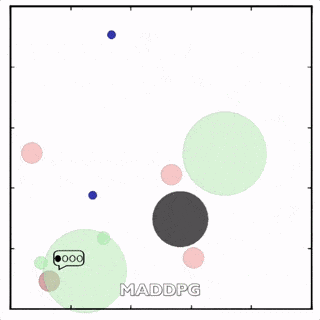
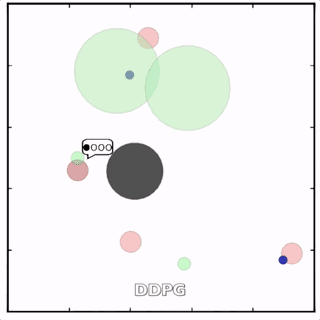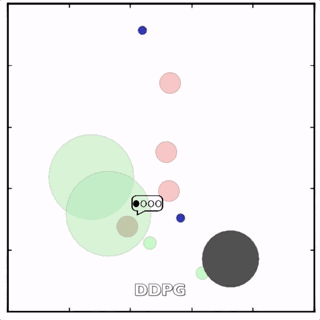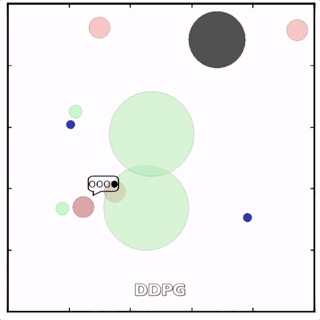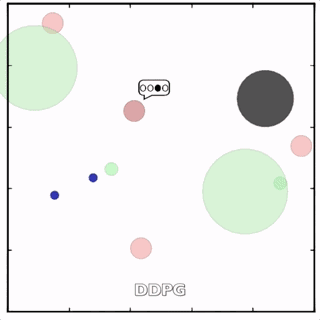
使用MADDPG訓(xùn)練的紅色圓點(diǎn)比用DDPG訓(xùn)練的智能體行為更復(fù)雜。在上面的動(dòng)畫(huà)中可以看到,用MADDPG技術(shù)訓(xùn)練的智能體和用DDPG訓(xùn)練的智能體都試圖穿過(guò)綠色的圓圈追逐綠色的小圓點(diǎn),同時(shí)不撞到黑色障礙物。新方法訓(xùn)練出來(lái)的智能體抓到的綠色圓點(diǎn)更多,也比用DDPG方法訓(xùn)練出的動(dòng)作更協(xié)調(diào)。
傳統(tǒng)強(qiáng)化學(xué)習(xí)的困境
傳統(tǒng)的分散式強(qiáng)化學(xué)習(xí)方法,如DDPG、actor-critic學(xué)習(xí)、深度Q學(xué)習(xí)等,都難以在多智能體環(huán)境中學(xué)習(xí),因?yàn)樵诿總€(gè)時(shí)間段,每個(gè)智能體都要嘗試學(xué)習(xí)預(yù)測(cè)其他智能體的行為,同時(shí)還要分析自己的行為。在競(jìng)爭(zhēng)的情況下尤其如此。MADDPG采用集中的critic為智能體提供有關(guān)同類(lèi)的觀察和潛在行為的信息,將不可預(yù)測(cè)的環(huán)境轉(zhuǎn)化為可預(yù)測(cè)環(huán)境。
使用梯度策略的方法會(huì)帶來(lái)更多挑戰(zhàn):因?yàn)楫?dāng)獎(jiǎng)勵(lì)不一致時(shí),這種方法所得到的結(jié)果差別很大。另外,在提高穩(wěn)定性的同時(shí),增加critic仍然不能解決一些環(huán)境問(wèn)題,例如合作交流。這樣看來(lái)在培訓(xùn)期間考慮其他智能體的行為對(duì)于學(xué)習(xí)協(xié)作策略是很重要的。
最初的研究
在開(kāi)發(fā)MADDPG之前,當(dāng)使用分散技術(shù)時(shí),研究人員注意到如果speaker所發(fā)出的關(guān)于去哪里不一致的消息,那么listener常常會(huì)忽略speaker,智能體將把有關(guān)speaker的所有權(quán)中設(shè)置為0。一旦發(fā)生這種情況,就很難恢復(fù)訓(xùn)練,因?yàn)闆](méi)有任何反饋,speaker永遠(yuǎn)不會(huì)知道自己所說(shuō)是否正確。為了解決這個(gè)問(wèn)題,他們研究了最近一個(gè)分層強(qiáng)化學(xué)習(xí)項(xiàng)目中所提到的技術(shù),該技術(shù)可以讓強(qiáng)制讓listener在決策過(guò)程中考慮speaker的消息。這種修復(fù)方法并不奏效,因?yàn)樗m然強(qiáng)制listener關(guān)注speaker,但并不能幫助listener決定說(shuō)出什么相關(guān)的內(nèi)容。通過(guò)幫助speaker學(xué)習(xí)哪些信息可能與其他智能體的位置信息有關(guān),集中式的critic方法有助于應(yīng)對(duì)這些挑戰(zhàn)。想了解更多結(jié)果,可點(diǎn)擊視頻觀看:
下一步
智能體建模在人工智能的研究中已經(jīng)有了豐富的成果,但之前的很多研究都只考慮了短時(shí)間內(nèi)簡(jiǎn)單的游戲。深度學(xué)習(xí)能讓我們處理復(fù)雜的視覺(jué)輸入,強(qiáng)化學(xué)習(xí)為我們提供了長(zhǎng)時(shí)間學(xué)習(xí)行為的工具。現(xiàn)在我們可以用這些功能一次性訓(xùn)練多個(gè)代理,而無(wú)需了解環(huán)境的變化(即環(huán)境在每個(gè)時(shí)間段發(fā)生的變化),我們可以解決更廣泛的包括交流和語(yǔ)言的高維度信息,同時(shí)從環(huán)境的高維信息中學(xué)習(xí)。
-
AI
+關(guān)注
關(guān)注
88文章
34560瀏覽量
276116
原文標(biāo)題:OpenAI公布MADDPG代碼,讓智能體學(xué)習(xí)合作、競(jìng)爭(zhēng)和交流
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論