 RT-Thread虛擬化部署DeepSeek大模型實踐
RT-Thread虛擬化部署DeepSeek大模型實踐

背景介紹
隨著邊緣計算與實時智能需求的快速增長,如何在資源受限的嵌入式設備上同時滿足實時控制與AI推理能力成為技術熱點。本文以ROCK 5B開發板為開發平臺(搭載4核Cortex-A76 + 4核Cortex-A55,8GB LPDDR4),通過虛擬化技術實現虛擬化Linux+RTOS混合部署,并在Linux環境中部署輕量化大語言模型DeepSeek-1.5B+語音轉文字模型,實現實時語音對話大模型功能,探索實時控制與AI推理的融合方案。
vmRT-Thread
vmRT-Thread是一個基于虛擬化技術的嵌入式軟件集成開發平臺,使得在高性能嵌入式設備上開發同時具備高實時性、高安全性和高復雜度的應用更簡單和高效。整體系統架構如下:
1、實時/安全虛擬機(RVM/SVM,Realtime/Safety Virtual Machine) – 運行要求高實時性、或符合功能安全要求的應用,可以使用RT-Thread API或POSIX(PSE51)API,底層操作系統使用標準版ASIL-D認證版的RT-Thread或RT-Thread Smart;
2、管理虛擬機(MVM,Management Virtual Machine) - 運行高級管理服務(比如:復雜的監控、升級和日志等功能)和虛擬外設服務(比如:網絡、存儲、圖形和圖像等外設的虛擬化共享),如果沒有這些功能則不需此虛擬機,可使用Linux、RT-Thread或RT-Thread Smart操作系統;普通虛擬機(NVM,Normal Virtual Machine) – 運行多媒體和人工智能等復雜應用,可以使用Android API或POSIX(PSE54) API,底層操作系統可以使用Linux或Android;
3、虛擬機間通信 – 支持虛擬機間的高性能共享內存,以及易用的套接字通信;vmRT-Thread虛擬機管理器(Hypervisor/VMM) - 利用硬件虛擬化功能運行在虛擬化層,是針對嵌入式設備設計實現的輕量級、高安全性、高性能的Type1虛擬機管理器。
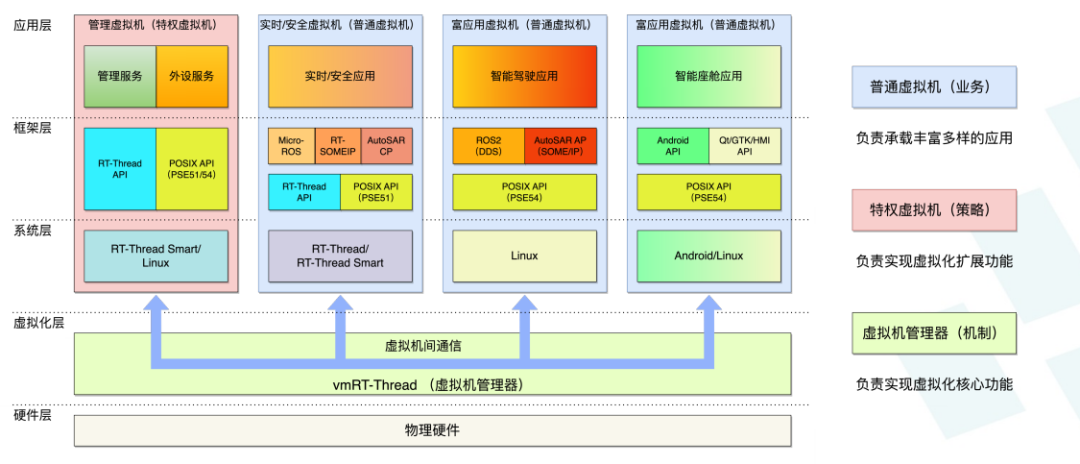
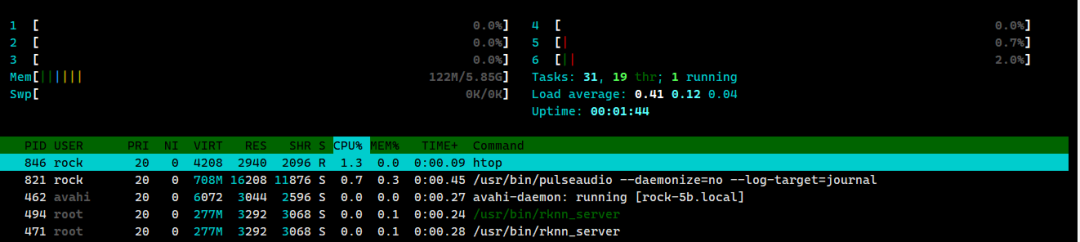
通過vmRT-Thread我們可以在ROCK 5B上同時部署RT-Thread系統和Linux系統,實現在Linux上部署大模型,在RT-Thread系統中可以控制小車等硬件設備。在本文中,我使用vmRT-Thread將ROCK 5B的8個CPU分為2部分,Linux系統占6核,RT-Thread系統占2核以下是htop查看的Linux系統的CPU信息
部署DeepSeek-R1-Distill-Qwen-1.5B大模型
DeepSeek-R1 是由杭州深度求索公司開發的大模型,DeepSeek系列模型完全開源且deepseek 通過 DeepSeek-R1蒸餾了 6 個小模型。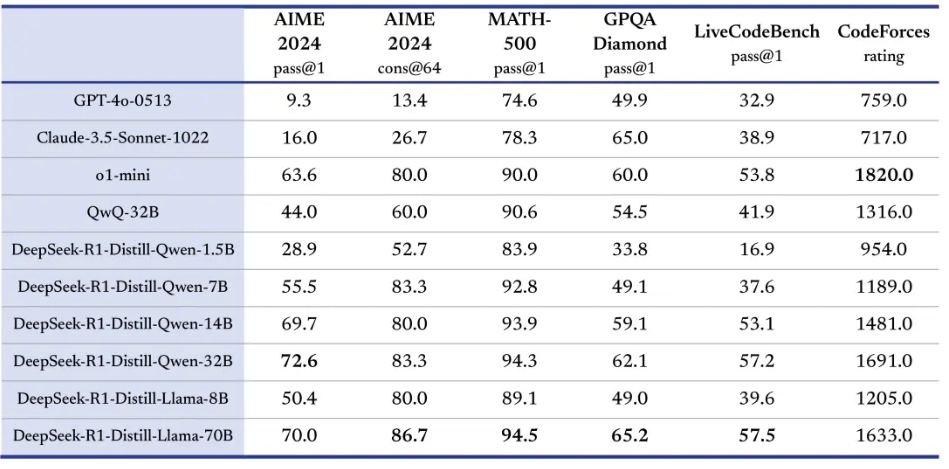 rock 5B官方提供了編譯好的 DeepSeek-R1-Distill-Qwen-1.5B 模型和執行文件,我們可以直接下載,下載鏈接:模型文件下載:https://docs.radxa.com/rock5/rock5b/app-development/rkllm_deepseek_r1下載文件如下
rock 5B官方提供了編譯好的 DeepSeek-R1-Distill-Qwen-1.5B 模型和執行文件,我們可以直接下載,下載鏈接:模型文件下載:https://docs.radxa.com/rock5/rock5b/app-development/rkllm_deepseek_r1下載文件如下 下載好的模型文件上傳到開發板上,導入必需的環境變量
下載好的模型文件上傳到開發板上,導入必需的環境變量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/librkllmrt.so所在文件夾路徑
export RKLLM_LOG_LEVEL=1
測試模型推理, 128分別是模型輸入的最大token數量和生成的最大token數量
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B.rkllm 128 128

部署語音喚醒和語音識別
語音喚醒使用pyaudio和webrtcvad實現,代碼參考自ASR-LLM-TTS(https://github.com/ABexit/ASR-LLM-TTS/tree/master)。語音識別為SenseVoiceSmall模型,模型下載鏈接。
語音喚醒
我們主要通過pyaudio實時采集音頻數據,然后將一段時間內采集的音頻數據用webrtcvad進行VAD檢測,將檢測到的有語音活動的數據拼接保存為wav格式的音頻,用于語音識別。代碼流程圖如下
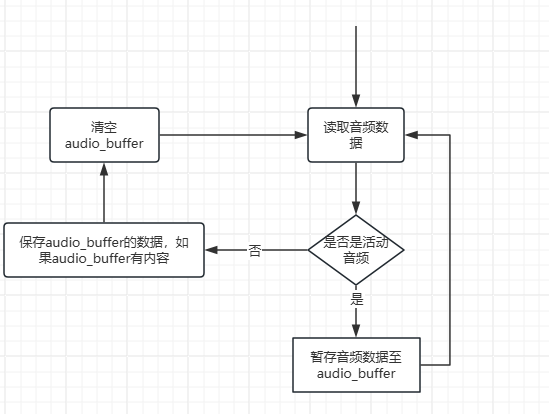
語音識別
語音識別使用的是SenseVoiceSmall模型,比官方提供的語音識別模型快6倍。他的部署方式與DeepSeek-R1-Distill-Qwen-1.5B一致,下載編譯好的模型文件并上傳到開發板中即可通過命令行或者代碼部署模型。部署語音識別模型還需要安裝rknn-toolkit2-lite2和以下依賴
pip install kaldi_native_fbank onnxruntime sentencepiece soundfile pyyaml numpy
運行sensevoice_rknn.py測試識別效果
python ./sensevoice_rknn.py --audio_file output.wav
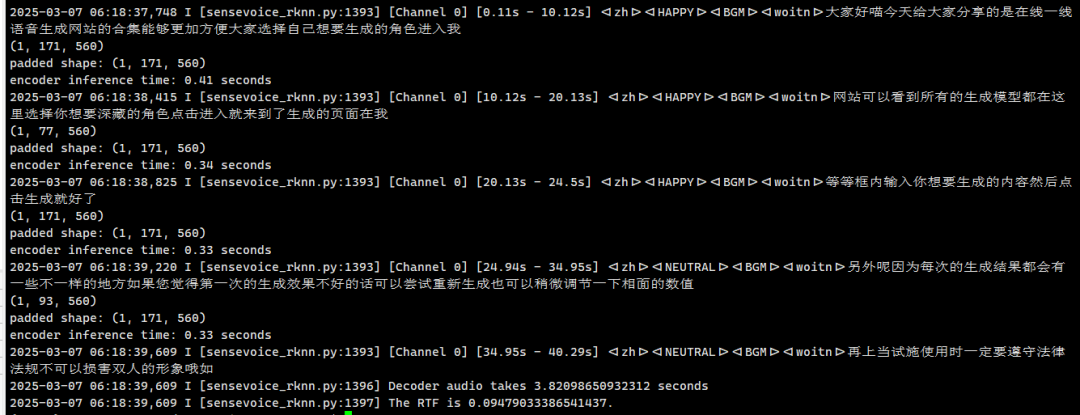
實現實時語音與大模型對話
有了上面的基礎,我們已經可以實現實時語音與大模型對話了。只要在語音喚醒和識別的基礎上,與大模型溝通即可。這里rknn-llm(https://github.com/airockchip/rknn-llm/tree/29a9fb97d14c773b6efa07415dce6ec91c7d8461/examples/rkllm_server_demo)中有example代碼,用Flask實現大模型服務。在開發板上下載rknn-llm代碼。修改flask_server.py中的PROMPT_TEXT_PREFIX和PROMPT_TEXT_POSTFIX為
PROMPT_TEXT_PREFIX = "<|im_start|>system\nYou are a helpful assistant.\n<|im_end|>\n<|im_start|>user\n"
PROMPT_TEXT_POSTFIX = "\n<|im_end|>\n<|im_start|>assistant\n"
然后運行以下代碼啟動大模型服務
python flask_server.py --rkllm_model_path ../ds_r1/DeepSeek-R1-Distill-Qwen-1.5B.rkllm --target_platform rk3588
以下是實時語音對話的運行效果
總結
在傳統的嵌入式方案中,往往只能選擇Linux或者RT-Thread一個系統,這種方式使得系統只能用于一般的非實時交互環境。而在當前眾多的生產生活環境中,往往需要滿足交互的情況下,盡可能的提高控制系統的響應和實時性能。因此,本文從這一出發點,詳細的介紹了基于vmRT-Thread的虛擬化方案,通過提供虛擬化層,既滿足了人機交互的可能,同時,又滿足了RT-Thread OS的實時性性能,該方案可以廣泛的應用在當前各種工業、生產環境中,為原有嵌入式設備提供高實時性、高穩定性的智能化交互解決方案,該方案有潛力運用在智能家居、智慧制造等諸多領域。下一期,我們將介紹基于該方案的智能小車解決方案,在該方案中,我們可以更加直觀的理解基于這種基于虛擬化的嵌入式AI方案給設備智能化開發帶來的便利。體驗了解虛擬化
-
虛擬化
+關注
關注
1文章
400瀏覽量
30251 -
RT-Thread
+關注
關注
32文章
1412瀏覽量
41994 -
大模型
+關注
關注
2文章
3148瀏覽量
4090 -
DeepSeek
+關注
關注
2文章
798瀏覽量
1773
發布評論請先 登錄
關于RT-AK開源輕松實現一鍵部署AI模型至RT-Thread解析
記錄——基于 RT-Thread 實現 USB 虛擬串口

RT-Thread AI kit開源:輕松實現一鍵部署AI模型至 RT-Thread
2022 RT-Thread全球技術大會:螢石EZIOT SDK對RT-Thread的支持
4月10日深圳場RT-Thread線下workshop,探索RT-Thread混合部署新模式!

4月10日深圳場RT-Thread線下workshop,探索RT-Thread混合部署新模式!

【4月10日-深圳-workshop】RT-Thread帶你探索混合部署新模式
4月25日北京站RT-Thread線下workshop,探索RT-Thread混合部署新模式
RT-Thread混合部署Workshop北京站來啦!
5月16日南京站RT-Thread線下workshop,探索RT-Thread混合部署新模式!
6月6日杭州站RT-Thread線下workshop,探索RT-Thread混合部署新模式!





 工商網監
工商網監
評論