 一種基于基礎模型對齊的自監督三維空間理解方法
一種基于基礎模型對齊的自監督三維空間理解方法

? 論文鏈接:
https://arxiv.org/pdf/2412.13193
?項目主頁:
https://hustvl.github.io/GaussTR/
概述
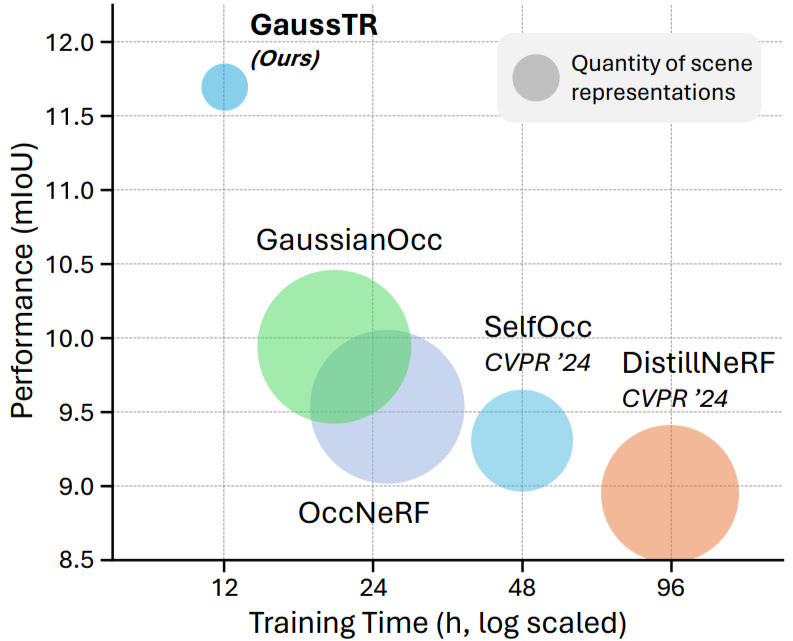
三維空間理解是推動自動駕駛、具身智能等領域中智能系統實現環境感知、交互的核心任務,其中3D語義占據預測 (Semantic Occupancy Prediction) 對三維場景進行精準的體素級建模。然而,當前主流方法嚴重依賴大規模標注數據,制約了模型的可擴展性和泛化能力。為此,我們提出GaussTR,一種基于基礎模型對齊的自監督三維空間理解方法。GaussTR通過Transformer架構前饋地預測一組稀疏高斯分布來高效表示3D場景,并利用Gaussian Splatting可微分渲染特征圖與預訓練基礎模型的知識對齊,從而使模型學習到通用的3D表征,在無需顯式標注數據的情況下即可實現零樣本開放詞匯占據預測。在Occ3D-nuScene數據集上的實驗結果表明,GaussTR取得了11.70mIoU的最先進性能,相比現有方法提升18%,同時訓練時間減少50%,顯著提升計算效率。我們希望GaussTR能夠為三維空間智能領域的研究進展提供新的視角,推動更可擴展、泛化性更強的3D表征學習。
基于基礎模型對齊的3D表征學習
近年來,2D視覺基礎模型,如CLIP、DINO等,已取得突破性進展,而自監督3D空間理解仍受限于大規模3D數據集的獲取困難與3D表征的復雜性。在3D語義占據預測任務中,現有的有監督方法依賴大規模體素級標注,不僅標注成本高昂,也難以擴大到更大規模的模型量級。受RenderOcc的啟發,一些自監督方案嘗試通過基于SAM生成的語義掩碼偽標簽來間接監督3D表征。然而,該類方法仍限于學習SAM生成的預定義的類別概率,限制了通用3D表征的學習,難以適應自動駕駛等現實應用中不可忽視的分布外 (Out-of-Distribution) 場景。同時,基于密集體素的建模方式也帶來了冗余計算開銷大、難以捕捉高級語義信息等問題。
受到3D Gaussian Splatting (GS) 技術在場景重建領域的成功應用啟發,GaussTR采用稀疏高斯作為3D建模方式,利用GS在2D與3D域間的跨模態表征一致性,實現2D視覺基礎模型的知識遷移到前饋預測的稀疏、非結構化的通用3D高斯表征中。借助2D視覺基礎模型獲得可擴展性和泛化性,實現自監督3D空間理解與零樣本開放詞匯推理。
算法架構
GaussTR作為基于自監督學習的3D場景理解框架,整體架構可分為前饋高斯建模、基礎模型對齊監督、開放詞匯占據預測三個階段。
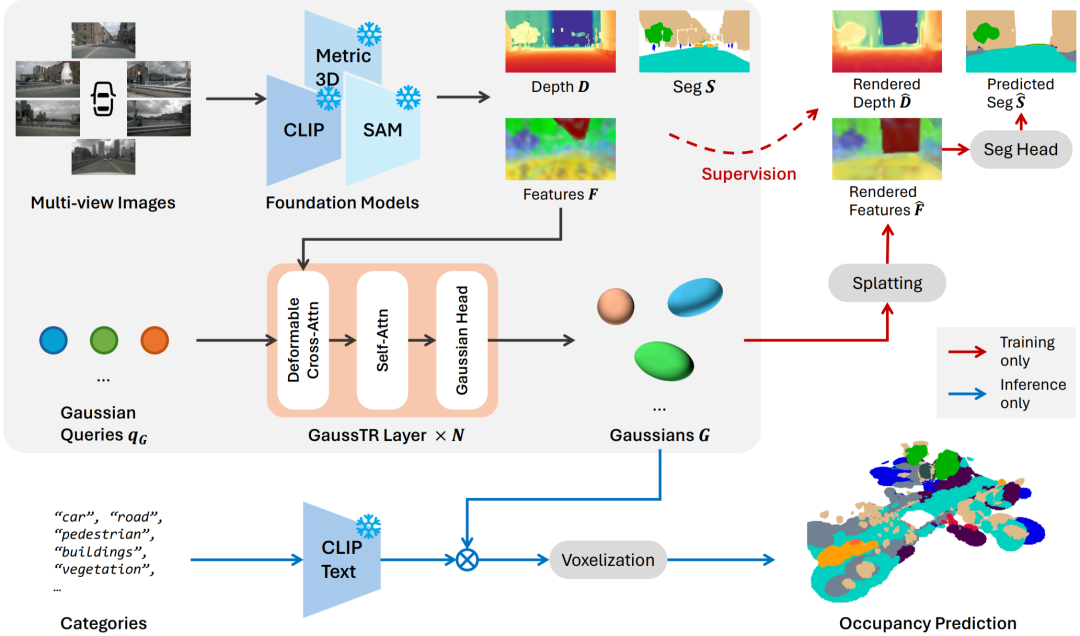
前饋高斯建模
GaussTR以多視角圖像作為輸入,首先通過CLIP和Metric3D V2提取全局語義特征和深度信息構建幾何先驗。由于CLIP的視覺局部特征較弱,GaussTR引入FeatUp模塊以增強CLIP特征的細節表征。隨后,GaussTR采用Transformer架構,從一組可學習的高斯查詢初始化,通過可變形注意力聚合基礎模型的局部特征,隨后通過自注意力機制建模3D場景的全局關系。最終通過MLP預測頭預測每個查詢對應的高斯參數,包括位置μ、尺度S、旋轉R、密度α、特征f,作為3D場景的表征。
基礎模型對齊監督
在訓練階段,GaussTR采用可微分Gaussian Splatting將3D表征投影回2D視角得到渲染特征與深度,與2D視覺基礎模型進行對齊監督,優化2D-3D表征的幾何位置和跨模態一致性。此外,為了提升CLIP特征的語義特征的邊界準確性,GaussTR可選地引入Grounded SAM生成的分割掩碼,通過輔助語義頭預測約束高斯特征渲染的類別概率。
開放詞匯占據預測
在推理階段,GaussTR利用CLIP共享的視覺-語言對齊的嵌入空間,計算預測的高斯特征與目標類別的CLIP文本向量之間的相似度得到每個高斯查詢對應的類別概率,隨后將高斯查詢體素化生成最終的占據預測。由此,GaussTR可以在無需額外標注的情況下,實現零樣本開放詞匯預測。
實驗結果
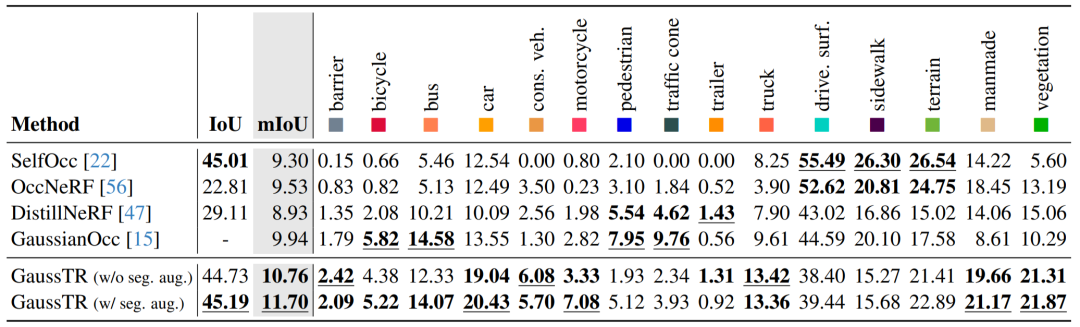
在Occ3D-nuScenes數據集上的實驗評估表明,GaussTR取得了11.70mIoU的最先進性能,在現有算法的基礎上提升了1.76mIoU。并且相較于依賴分割掩碼偽標簽的方法,GaussTR實現了零樣本的開放詞匯占據預測,進一步驗證了基礎模型對齊的通用3D表征學習能力。從逐類別的實驗結果來看,GaussTR在以物體為中心的的類別上標展卓越,如車輛、建筑物和植被,這些類別的提升與我們提出稀疏建模策略的核心理念相契合。然而,GaussTR在小物體類別(如行人)和平坦表面類別(如道路)上表現相對較弱。造成這一現象的主要原因包括:小物體的視覺特征不夠顯著,在基礎模型的預測特征中難以區分;駕駛場景中的大量遮擋,導致平坦表面的幾何信息難以捕獲。
從可視化結果來看,GaussTR預測的高斯分布展現了優異的整體場景結構,并且在物體局部細節的表現也更加精確,展現了出色的三維空間理解能力。
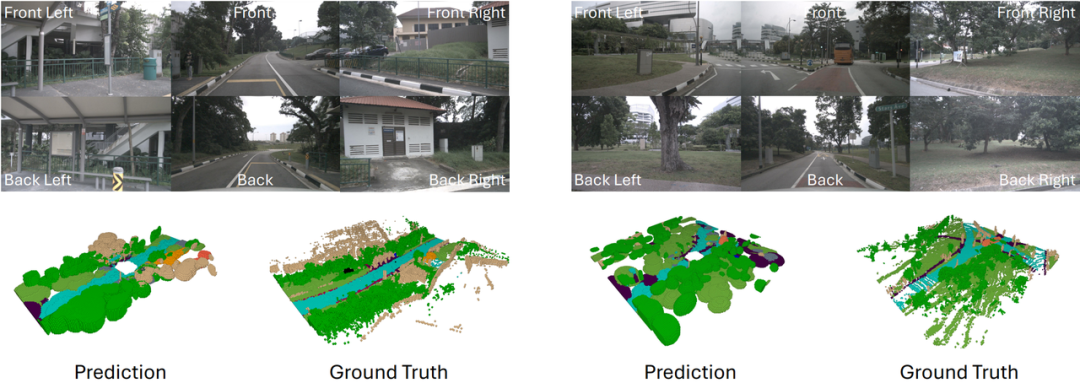
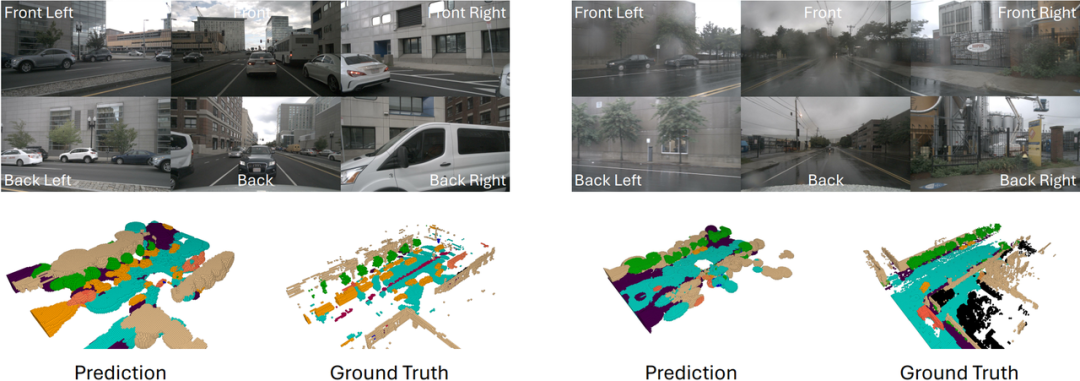
此外,我們對2D視角的渲染結果進行了可視化分析,尤其是數據集中未明確標注的罕見類別(如交通燈、街道標識)上的零樣本預測效果,GaussTR依然能夠在對應位置產生顯著的激活。這一點進一步證明了GaussTR在3D表征學習的泛化能力,即使面對現實應用的長尾分布場景,仍能依靠基礎模型的知識遷移實現準確的預測,為未來自動駕駛、具身智能等3D空間理解能力提供了新的方向。

總結與展望
本文介紹了一種基于基礎模型對齊的稀疏高斯表征學習框架GaussTR,通過將3D高斯預測與2D視覺基礎模型的知識對齊,實現了無需體素級標注的零樣本自監督三維語義占據預測,為3D空間理解提供了一種高效且可擴展的新方案。
通過引入Transformer架構前饋生成稀疏高斯分布,配合可微分渲染的跨模態對齊范式,GaussTR在降低計算復雜度的同時,突破了傳統方法對人工標注的依賴,在Occ3D-nuScenes數據集上取得11.70mIoU的自監督最先進性能,驗證了基于基礎模型知識遷移的3D表征學習有效性。實驗表明,稀疏高斯建模策略能有效捕捉場景的語義拓撲結構,尤其在物體級語義建模上展現出顯著優勢。
未來,我們希望進一步探索基于可微分渲染構建跨模態對齊的通用表征范式,突破3D標注數據瓶頸,這一技術路徑有望拓展至更廣泛的3D感知任務,如動態場景理解、多智能體協同感知等復雜任務。同時,隨著更強大的視覺-語言基礎模型的發展,我們也期待能夠構建更通用的3D語義表征,使得GaussTR能夠在更復雜的現實場景中發揮作用,為自動駕駛、具身智能、增強現實等領域提供更強大的3D感知能力。
-
模型
+關注
關注
1文章
3504瀏覽量
50184 -
三維空間
+關注
關注
0文章
19瀏覽量
7685 -
自動駕駛
+關注
關注
788文章
14261瀏覽量
170119 -
具身智能
+關注
關注
0文章
129瀏覽量
427
原文標題:CVPR 2025 | 通向自監督三維空間理解——基于高斯表示的語義占據預測算法GaussTR
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于多傳感器數據融合處理實現與城市三維空間和時間配準


labview 利用三維空間畫了一個球,然后想在球面上畫幾個點
請問ADXL345配合陀螺儀能精確測量短時三維空間運動路徑嗎?
基于麥克風陣列模擬人耳進行三維空間的聲源定位
三維空間中每一平面有四個點,能根據這四個點畫出一個圓來嗎 ?
基于交流伺服控制的三維空間磁場與磁力測試技術
一種用于三維空間雜波環境機動目標跟蹤的數據互聯方法
基于伺服控制的三維空間磁場與磁力測試系統
非正交三維坐標系下多電平空間矢量調制策略





 工商網監
工商網監
評論