") 多智能體仿真中的統(tǒng)一混合模型框架研究
多智能體仿真中的統(tǒng)一混合模型框架研究

隨著GPT大語(yǔ)言模型的成功,越來(lái)越多的工作嘗試使用類GPT架構(gòu)的離散模型來(lái)表征駕駛場(chǎng)景中的交通參與者行為,從而生成多智能體仿真。這些方法展現(xiàn)出明顯的性能優(yōu)勢(shì),成為Waymo OpenSim Agents Challenge(WOSAC)中主流的領(lǐng)先方法。
在本文中,我們將GPT-Like離散模型視為采取了特定配置的混合模型(MixtureModel),嘗試探究目前主流的GPT-Like方法性能優(yōu)勢(shì)的來(lái)源。在統(tǒng)一的混合模型框架(Unified Mixture Model,UniMM)下,我們從模型和數(shù)據(jù)兩個(gè)方面的配置展開(kāi)研究發(fā)現(xiàn):GPT-Like離散模型實(shí)際上采用了由Tokenization自然引l入的閉環(huán)樣本,這是其性能優(yōu)勢(shì)的關(guān)鍵。
基于上述發(fā)現(xiàn),我們嘗試將閉環(huán)樣本應(yīng)用于更廣泛的混合模型,進(jìn)一步觀察到并解決了相關(guān)的ShortcutLearning和Of-PolicyLearning問(wèn)題。最終,UniMM框架下的各種變體均在WaymoOpenSim AgentsChallenge(WOSAC)展現(xiàn)了SOTA性能。
? 原文鏈接:
https://arxiv.org/abs/2501.17015
? 項(xiàng)目主頁(yè):
https://longzhong-lin.github.io/unimm-webpage
?代碼倉(cāng)庫(kù):
https://github.com/Longzhong-Lin/UniMM
多智能體仿真
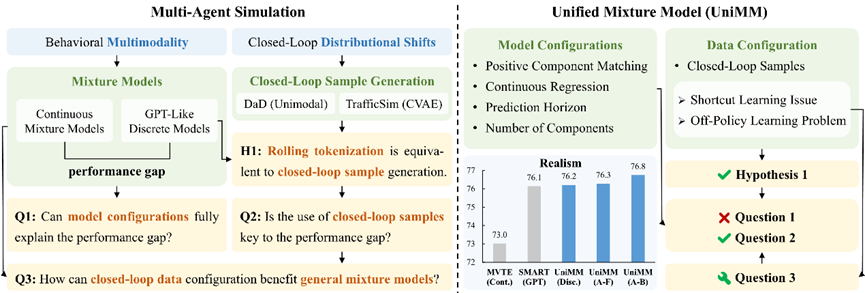
仿真 (Simulation)是評(píng)估自動(dòng)駕駛系統(tǒng)的重要途徑,生成真實(shí)的多智能體 (Multi-Agent) 行為是其中的關(guān)鍵。近年來(lái),許多工作采用數(shù)據(jù)驅(qū)動(dòng)的方法,從真實(shí)世界駕駛數(shù)據(jù)集中學(xué)習(xí)行為模型 (Behavior Model) 來(lái)模仿人類交通參與者。要實(shí)現(xiàn)真實(shí)的多智能體仿真,主要挑戰(zhàn)在于捕捉智能體行為的多模態(tài)性 (Multimodality)和解決模型閉環(huán)運(yùn)行的分布偏移 (Distributional Shifts)問(wèn)題。
圖表1 多智能體仿真
智能體行為的多模態(tài)性在運(yùn)動(dòng)預(yù)測(cè) (Motion Prediction) 領(lǐng)域得到廣泛研究,其中主流方法采用的是混合模型 (Mixture Model)。由于任務(wù)的相似性,不少仿真領(lǐng)域的工作也采用類似的連續(xù)混合模型 (Continuous Mixture Model) 來(lái)表征智能體行為。最近,受大語(yǔ)言模型的啟發(fā),越來(lái)越多的研究開(kāi)始嘗試GPT架構(gòu)的離散模型 (GPT-Like Discrete Model) ,將智能體的軌跡離散化為運(yùn)動(dòng)Token并進(jìn)行NTP (Next-Token Prediction) 訓(xùn)練,在仿真領(lǐng)域展現(xiàn)出了超越連續(xù)混合模型的性能優(yōu)勢(shì)。
為了緩解模型閉環(huán)運(yùn)行的分布偏移,時(shí)間序列建模領(lǐng)域的DaD方法繼承在線學(xué)習(xí)算法DAgger的理論保證,將訓(xùn)練樣本中的真值輸入替換為自回歸模型預(yù)測(cè),不過(guò)該方法只討論了單模態(tài) (Unimodal) 模型。TrafficSim將類似方法應(yīng)用在CVAE行為模型,迭代地將真值軌跡替換為后驗(yàn) (Posterior) 預(yù)測(cè),從而生成閉環(huán)樣本 (Closed-Loop Sample)。
圖表2 UniMM研究概述
統(tǒng)一混合模型框架
我們注意到,GPT-Like離散模型本質(zhì)上是一種混合模型,其中每個(gè)混合組分 (Mixture Component) 代表一個(gè)離散類別,而運(yùn)動(dòng)Token則是各組分對(duì)應(yīng)的錨點(diǎn) (Anchor) 。因此,本文建立統(tǒng)一的混合模型框架 (Unified Mixture Model, UniMM),并從模型和數(shù)據(jù)兩個(gè)方面展開(kāi)研究,探索GPT-Like方法優(yōu)勢(shì)的根源,并嘗試推廣到更一般的混合模型中。
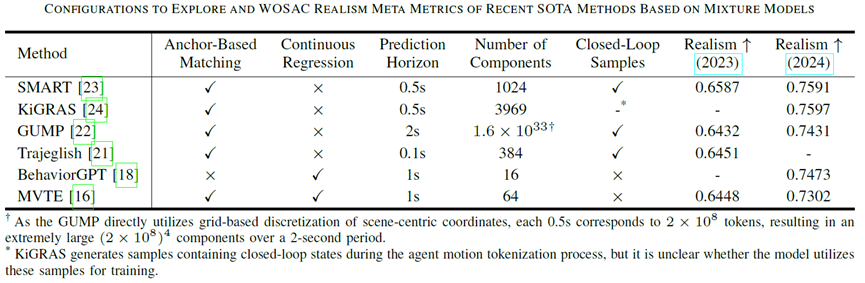
圖表3 WOSAC領(lǐng)先方法(可視為混合模型)的配置和指標(biāo)
模型配置
模型方面,我們關(guān)注的配置包括:
正組分匹配 (Positive Component Matching) :主流范式為無(wú)錨點(diǎn) (Anchor-Free) 和基于錨點(diǎn) (Anchor-Based) 匹配。
連續(xù)回歸 (Continuous Regression) :若Anchor-Based模型將錨點(diǎn)直接作為對(duì)應(yīng)混合組分的預(yù)測(cè)軌跡,則無(wú)需連續(xù)回歸。
預(yù)測(cè)時(shí)長(zhǎng) (Prediction Horizon) :模型預(yù)測(cè)軌跡的長(zhǎng)度。
混合組分?jǐn)?shù)量 (Number of Components) :混合模型中混合組分的數(shù)量。
其中,GPT-Like離散模型采用Anchor-Based正組分匹配且不具備連續(xù)回歸,通常使用大量混合組分且預(yù)測(cè)時(shí)長(zhǎng)較短。后面的實(shí)驗(yàn)表明:模型配置的差別并不能完全解釋連續(xù)混合模型和GPT-Like離散模型之間的性能差距。采用與GPT-Like方法完全不同的模型配置,也可以達(dá)到同樣優(yōu)秀的仿真性能。
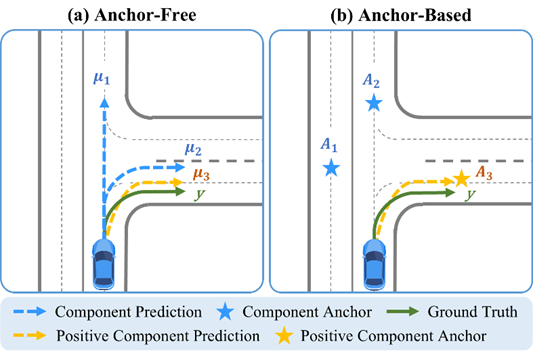
圖表4 主流的正組分匹配范式
數(shù)據(jù)配置
數(shù)據(jù)方面,我們借鑒DaD和TrafficSim的設(shè)計(jì)理念,提出了適用于一般混合模型的閉環(huán)樣本生成方法。具體地,我們基于原始開(kāi)環(huán)樣本自回歸地運(yùn)行模型,將樣本中的真值輸入狀態(tài)替換為與之匹配的后驗(yàn)?zāi)P皖A(yù)測(cè)(我們稱之為后驗(yàn)規(guī)劃)。生成的閉環(huán)樣本在盡量接近真值的同時(shí),將模型預(yù)測(cè)引入到樣本輸入中,使訓(xùn)練期間模型見(jiàn)到的狀態(tài)更接近在閉環(huán)仿真中遇到的狀態(tài),從而緩解分布偏移。
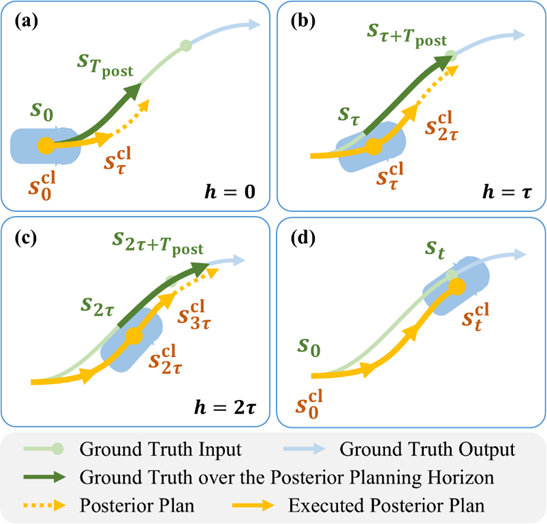
圖表5 閉環(huán)樣本生成
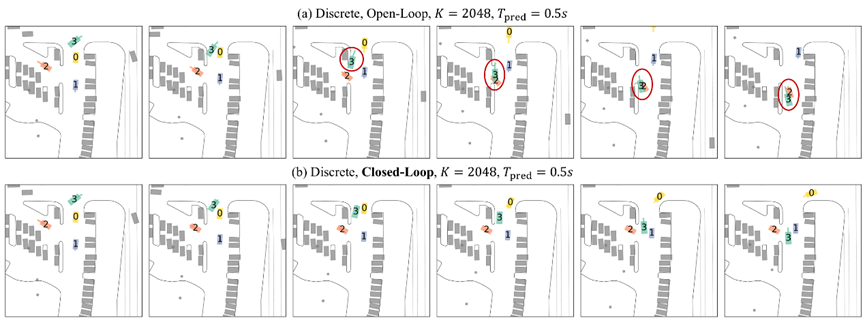
對(duì)于GPT-Like離散模型,我們證明:上述閉環(huán)樣本生成方法等價(jià)于采用滾動(dòng)匹配 (Rolling Matching) 的智能體運(yùn)動(dòng)Tokenization。后面的實(shí)驗(yàn)表明:使用閉環(huán)樣本進(jìn)行訓(xùn)練是生成逼真多智能體行為的關(guān)鍵。進(jìn)一步地,為了讓閉環(huán)樣本能夠惠及更廣泛的混合模型,我們識(shí)別并解決了Shortcut Learning和Off-Policy Learning問(wèn)題。
實(shí)驗(yàn)
網(wǎng)絡(luò)架構(gòu)
實(shí)驗(yàn)中使用的網(wǎng)絡(luò)架構(gòu)包含場(chǎng)景編碼器 (Context Encoder) 和運(yùn)動(dòng)解碼器 (Motion Decoder) 。場(chǎng)景編碼器能夠并行處理多智能體在多個(gè)時(shí)間上的信息;運(yùn)動(dòng)解碼器生成特定智能體從指定時(shí)間開(kāi)始的多模態(tài)未來(lái)軌跡。特別地,對(duì)于帶連續(xù)回歸的Anchor-Based模型,我們的解碼器先對(duì)錨點(diǎn)打分、再生成所選取組分對(duì)應(yīng)的軌跡,使得其能夠像離散模型一樣高效地增加混合組分的數(shù)量。
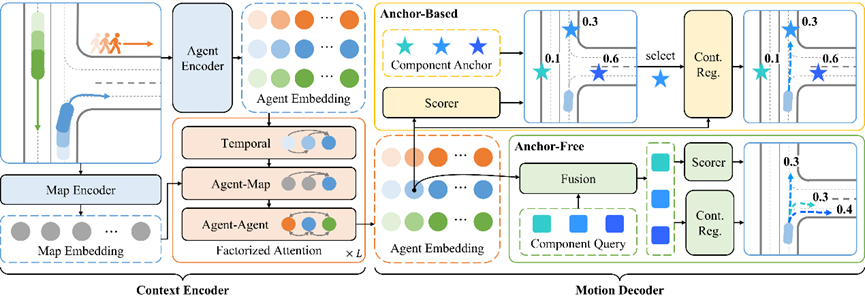
圖表6 混合模型網(wǎng)絡(luò)結(jié)構(gòu)
采用開(kāi)環(huán)樣本訓(xùn)練
我們首先探索不同預(yù)測(cè)時(shí)長(zhǎng)和混合組分?jǐn)?shù)量下的Anchor-Free和Anchor-Based模型。在這里,我們采用開(kāi)環(huán)樣本訓(xùn)練來(lái)保證數(shù)據(jù)的一致性,從而更好地體現(xiàn)上述模型配置的影響。
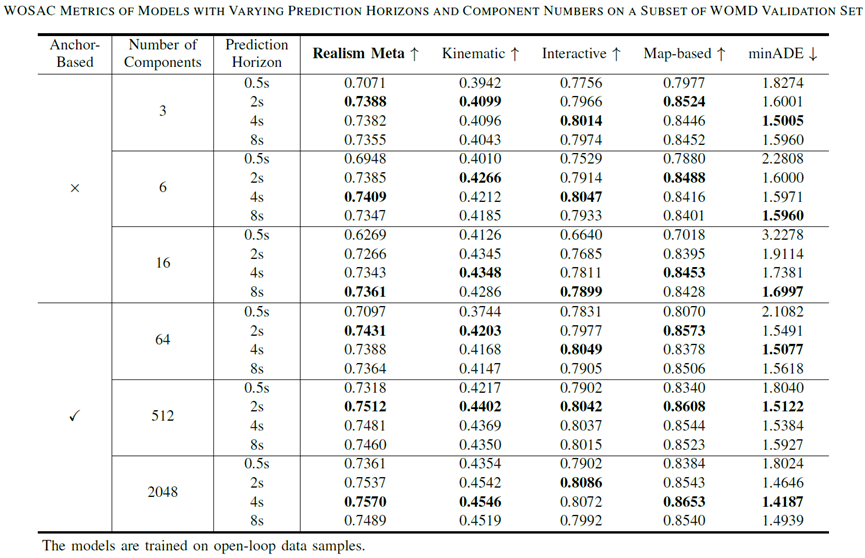
圖表7 采用開(kāi)環(huán)樣本訓(xùn)練
預(yù)測(cè)時(shí)長(zhǎng):
更大的預(yù)測(cè)時(shí)長(zhǎng) (Prediction Horizon) 帶來(lái)的額外監(jiān)督信號(hào)是有效的。
過(guò)大的預(yù)測(cè)時(shí)長(zhǎng)使模型更關(guān)注于遠(yuǎn)期預(yù)測(cè)的優(yōu)化,由于仿真僅會(huì)利用模型預(yù)測(cè)的前面一小段,所以這并不利于提升仿真的效果。
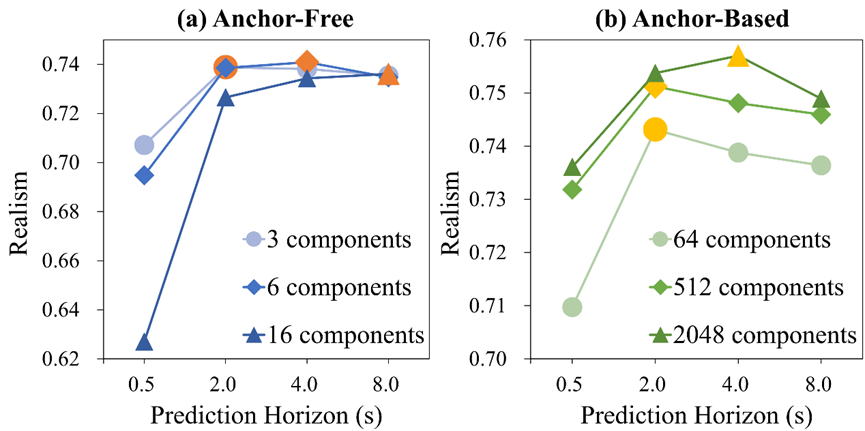
圖表8 不同預(yù)測(cè)時(shí)長(zhǎng)的WOSAC指標(biāo)
混合組分?jǐn)?shù)量:
增加混合組分的數(shù)量確實(shí)能夠提升模型對(duì)復(fù)雜分布的表征能力。
較多數(shù)量的混合組分可能會(huì)阻礙Anchor-Free模型挑選出合理軌跡,從而影響其在仿真中的表現(xiàn)。
Anchor-Based模型持續(xù)受益于混合組分?jǐn)?shù)量的增長(zhǎng)。
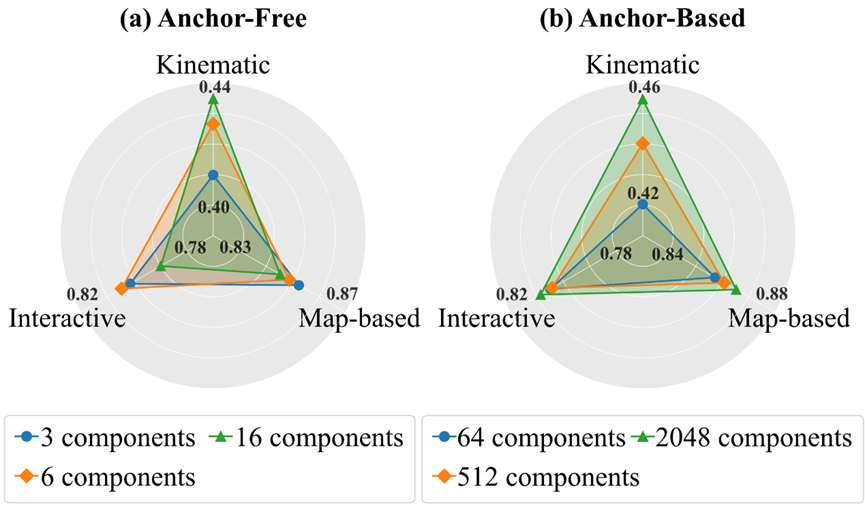
圖表9 不同混合組分?jǐn)?shù)量下的最優(yōu)WOSAC指標(biāo)
采用閉環(huán)樣本訓(xùn)練
接下來(lái)展開(kāi)對(duì)數(shù)據(jù)配置的研究,我們從開(kāi)環(huán)樣本實(shí)驗(yàn)中表現(xiàn)最佳的模型配置出發(fā),從而凸顯閉環(huán)樣本的作用。
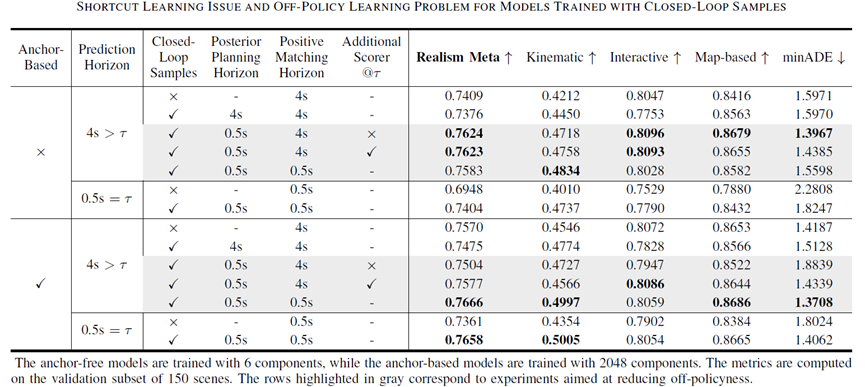
圖表10 采用閉環(huán)樣本訓(xùn)練
Shortcut Learning問(wèn)題:
生成閉環(huán)樣本時(shí),若后驗(yàn)策略的規(guī)劃時(shí)長(zhǎng) (Posterior Planning Horizon) 超過(guò)其重規(guī)劃間隔,模型會(huì)學(xué)習(xí)到捷徑,損害時(shí)空交互推理能力。
Off-Policy Learning問(wèn)題:
若訓(xùn)練策略的正組分匹配時(shí)長(zhǎng) (Positive Matching Horizon) 和樣本生成策略的后驗(yàn)規(guī)劃時(shí)長(zhǎng) (Posterior Planning Horizon) 不一致,則其導(dǎo)致的Off-Policy Learning問(wèn)題會(huì)阻礙閉環(huán)樣本發(fā)揮作用。
對(duì)于Anchor-Free模型,Off-Policy Learning問(wèn)題的影響沒(méi)那么嚴(yán)重,這可能是因?yàn)樗鼈兊男阅芨蕾囉诟骰旌辖M分的靈活預(yù)測(cè),而不是對(duì)混合組分的挑選。
對(duì)齊訓(xùn)練策略和樣本生成策略的組分選擇Horizon可以有效緩解Off-Policy Learning問(wèn)題,特別是對(duì)于十分依賴其混合組分選擇的Anchor-Based模型。
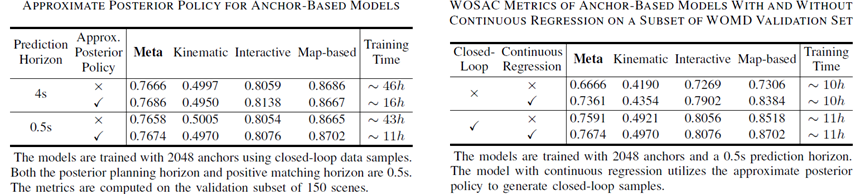
圖表11 近似后驗(yàn)策略(左)和連續(xù)回歸(右)
近似后驗(yàn)策略:
我們?yōu)锳nchor-Based模型設(shè)計(jì)了近似后驗(yàn)策略,將后驗(yàn)組分對(duì)應(yīng)的錨點(diǎn)直接作為執(zhí)行規(guī)劃,可以在顯著減少訓(xùn)練時(shí)間的同時(shí),達(dá)到相當(dāng)?shù)姆抡嫘阅堋?/p>
連續(xù)回歸:
主流離散模型成功的關(guān)鍵在于閉環(huán)樣本的使用。
連續(xù)回歸 (Continuous Regression) 帶來(lái)的靈活性對(duì)于模型性能是有增益的,同時(shí)其并不需要顯著增加計(jì)算開(kāi)銷。
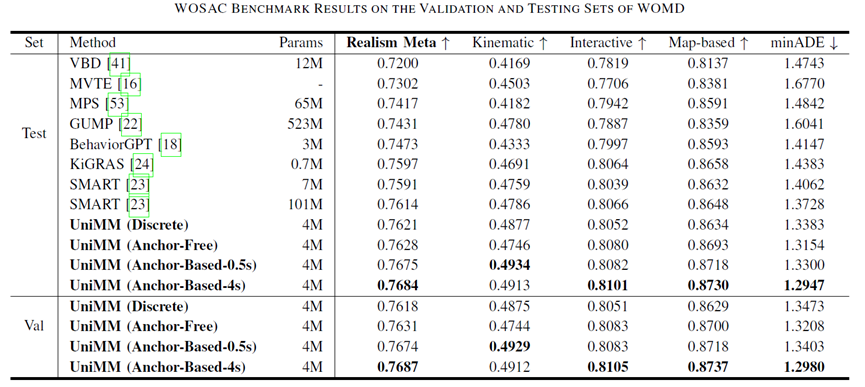
Benchmark結(jié)果
基于上述探索,我們提交了UniMM框架下的各種變體(包括離散和連續(xù)、Anchor-Free和Anchor-Based),均在Waymo Open Sim Agents Challenge (WOSAC)中展現(xiàn)了SOTA性能。由此證明了:
模型配置的差別并不能完全解釋之前的連續(xù)混合模型和GPT-Like離散模型之間的性能差距。
仿真性能的關(guān)鍵在于閉環(huán)樣本的使用,采用與主流離散方法不同的模型配置也能生成逼真的行為。
通過(guò)解決Shortcut Learning和Off-Policy Learning問(wèn)題,閉環(huán)樣本能夠使廣泛的混合模型受益,尤其是具有更大預(yù)測(cè)時(shí)長(zhǎng)的模型。
總結(jié)與展望
本研究首先建立了多智能體仿真的統(tǒng)一混合模型框架,并針對(duì)該框架下的模型配置(正組分匹配、連續(xù)回歸、預(yù)測(cè)時(shí)長(zhǎng)、混合組分?jǐn)?shù)量)和數(shù)據(jù)配置(閉環(huán)樣本生成方法)進(jìn)行深入的分析與實(shí)驗(yàn)。我們通過(guò)最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)、參數(shù)配置和訓(xùn)練方式得到的模型僅需4M參數(shù)量的情況下,在Waymo Open Sim Agents Challenge達(dá)到了SOTA的性能。基于以上多智能體仿真的模型優(yōu)化分析和實(shí)驗(yàn)結(jié)論,我們今后會(huì)進(jìn)一步去探索自動(dòng)駕駛的運(yùn)動(dòng)規(guī)劃問(wèn)題。
-
仿真
+關(guān)注
關(guān)注
52文章
4269瀏覽量
135747 -
模型
+關(guān)注
關(guān)注
1文章
3516瀏覽量
50368 -
混合模型
+關(guān)注
關(guān)注
0文章
6瀏覽量
6501 -
多智能體
+關(guān)注
關(guān)注
0文章
7瀏覽量
6279
原文標(biāo)題:開(kāi)發(fā)者說(shuō) | UniMM:重新審視多智能體仿真中的混合模型
文章出處:【微信號(hào):horizonrobotics,微信公眾號(hào):地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于多Agent系統(tǒng)的智能家庭網(wǎng)絡(luò)研究
智能跟蹤控制系統(tǒng)的動(dòng)畫(huà)仿真設(shè)計(jì)
一種基于聚類和競(jìng)爭(zhēng)克隆機(jī)制的多智能體免疫算法
Embedded SIG | 多 OS 混合部署框架
基于統(tǒng)一混沌系統(tǒng)的同步及其保密通信研究
一類參數(shù)不確定統(tǒng)一混沌系統(tǒng)的脈沖控制
形變體仿真中材質(zhì)本構(gòu)模型的應(yīng)用
和諧統(tǒng)一混合擇優(yōu)網(wǎng)絡(luò)的相繼故障行為
群智能算法在PID控制仿真中的應(yīng)用研究教程免費(fèi)下載
人群緊急狀況下的多智能體情緒感染仿真模型

多智能體路徑規(guī)劃研究綜述
SystemView在通信系統(tǒng)仿真中的應(yīng)用研究






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論