") 規(guī)模化混沌工程體系建設(shè)及AI融合探索
規(guī)模化混沌工程體系建設(shè)及AI融合探索
1、何謂混沌工程?
混沌工程由 Netflix 率先提出并應(yīng)用,其業(yè)務(wù)高度依賴(lài)分布式系統(tǒng),為確保系統(tǒng)在面對(duì)各種故障時(shí)仍能穩(wěn)定運(yùn)行,其組織開(kāi)發(fā)了混沌工程工具集 ——Chaos Monkey 等,通過(guò)隨機(jī)地關(guān)閉生產(chǎn)環(huán)境中的服務(wù)器來(lái)驗(yàn)證系統(tǒng)彈性。
混沌工程是一種在分布式系統(tǒng)上進(jìn)行實(shí)驗(yàn)的方法,目的是提升系統(tǒng)的彈性和穩(wěn)定性。它通過(guò)主動(dòng)向系統(tǒng)注入故障,觀(guān)察系統(tǒng)在各種壓力情況下的行為,以發(fā)現(xiàn)系統(tǒng)中的潛在問(wèn)題并加以改進(jìn)。
2、混沌工程實(shí)驗(yàn)的核心原則
a、建立穩(wěn)定性指標(biāo)
建立系統(tǒng)穩(wěn)定性指標(biāo),是觀(guān)測(cè)混沌工程實(shí)驗(yàn)效果的關(guān)鍵手段。在混沌工程啟動(dòng)前,必須明確系統(tǒng)穩(wěn)定性狀態(tài)的定義,穩(wěn)定性狀態(tài)可以是系統(tǒng)的技術(shù)指標(biāo)、業(yè)務(wù)指標(biāo)或用戶(hù)體驗(yàn)指標(biāo)等。例如,系統(tǒng)TP99指標(biāo)范圍、可用率指標(biāo)范圍、頁(yè)面響應(yīng)時(shí)間范圍、訂單處理成功率范圍等。
b、多樣化故障注入
多樣化的故障注入,是驗(yàn)證系統(tǒng)故障應(yīng)急能力的前提。混沌工程應(yīng)盡可能模擬真實(shí)世界中可能發(fā)生的各種故障或異常情況。包括不限于,硬件故障、軟件故障、網(wǎng)絡(luò)故障、人為錯(cuò)誤等。例如,服務(wù)器宕機(jī)、網(wǎng)絡(luò)延遲、數(shù)據(jù)庫(kù)故障、配置錯(cuò)誤等。
c、生產(chǎn)環(huán)境接納度
生產(chǎn)環(huán)境對(duì)演練實(shí)驗(yàn)的接納度,是確保故障演練實(shí)驗(yàn)精度和有效性的基礎(chǔ)要素。混沌工程實(shí)驗(yàn)最好在生產(chǎn)環(huán)境中進(jìn)行,因?yàn)樯a(chǎn)環(huán)境是最真實(shí)的系統(tǒng)運(yùn)行環(huán)境,能夠反映出系統(tǒng)在實(shí)際使用中的各種情況。當(dāng)然,在生產(chǎn)環(huán)境中進(jìn)行實(shí)驗(yàn)務(wù)必謹(jǐn)慎操作,確保實(shí)驗(yàn)不會(huì)對(duì)生產(chǎn)運(yùn)營(yíng)及用戶(hù)造成不良影響。
d、常態(tài)化運(yùn)轉(zhuǎn)
混沌工程實(shí)驗(yàn)的常態(tài)化運(yùn)轉(zhuǎn),是確保系統(tǒng)健壯性得以持續(xù)鞏固的基礎(chǔ)。混沌工程實(shí)驗(yàn)應(yīng)該持續(xù)自動(dòng)化運(yùn)行,以便及時(shí)發(fā)現(xiàn)系統(tǒng)中的潛在問(wèn)題。自動(dòng)化實(shí)驗(yàn)可以定期進(jìn)行,也可以在系統(tǒng)發(fā)生變化時(shí)進(jìn)行。通過(guò)持續(xù)自動(dòng)化運(yùn)行實(shí)驗(yàn),可以不斷提高系統(tǒng)的彈性和穩(wěn)定性。
3、混沌工程實(shí)驗(yàn)的關(guān)鍵步驟及落地
快遞快運(yùn)技術(shù)部,自2024年11月起,針對(duì)分揀揀攬派及C端、B端核心業(yè)務(wù)線(xiàn),0-1落地研測(cè)聯(lián)動(dòng)紅藍(lán)攻防機(jī)制,完成共兩輪,87個(gè)核心接口架構(gòu)分析,覆蓋31個(gè)核心應(yīng)用(79個(gè)場(chǎng)景),識(shí)別攔截5類(lèi)36處風(fēng)險(xiǎn)(監(jiān)控、流程、代碼、預(yù)案、依賴(lài)),持續(xù)鞏固快快應(yīng)急預(yù)案體系,在此基礎(chǔ)上,25年持續(xù)推動(dòng)演練線(xiàn)上化實(shí)踐、成熟度評(píng)估體系建設(shè)、落地及能力升維。
a、實(shí)驗(yàn)范圍圈定
通過(guò)對(duì)核心系統(tǒng)的架構(gòu)分析,梳理系統(tǒng)鏈路的關(guān)鍵指標(biāo)(系統(tǒng)規(guī)模、SLA及限流指數(shù)等)和關(guān)鍵依賴(lài)(應(yīng)用、存儲(chǔ)及其他中間件),明確要進(jìn)行實(shí)驗(yàn)的系統(tǒng)或服務(wù)范圍,標(biāo)記故障注入點(diǎn)。
實(shí)驗(yàn)范圍可以是一個(gè)或多個(gè)單體應(yīng)用、某個(gè)業(yè)務(wù)場(chǎng)景下的應(yīng)用鏈路、某個(gè)數(shù)據(jù)中心或整個(gè)分布式系統(tǒng)。
b、穩(wěn)定性指標(biāo)定義
定義明確的穩(wěn)定性指標(biāo),用以衡量系統(tǒng)在實(shí)驗(yàn)過(guò)程中的狀態(tài),穩(wěn)定性指標(biāo)可以是技術(shù)監(jiān)控指標(biāo)、業(yè)務(wù)監(jiān)控指標(biāo)或用戶(hù)體驗(yàn)指標(biāo)等。
1)技術(shù)監(jiān)控指標(biāo)
技術(shù)監(jiān)控指標(biāo),一般從技術(shù)視角監(jiān)控系統(tǒng)穩(wěn)定性,通常分為幾個(gè)維度監(jiān)控。
| 指標(biāo)名稱(chēng) | 指標(biāo)描述 |
| UMP(JD術(shù)語(yǔ)) | 監(jiān)控方法調(diào)用的TP99,響應(yīng)時(shí)間等 |
| 日志異常關(guān)鍵字 | 監(jiān)控日志中的,有無(wú)異常關(guān)鍵字,報(bào)錯(cuò)信息等 |
| 容器指標(biāo)監(jiān)控 | 監(jiān)控CPU,數(shù)據(jù)庫(kù)等使用情況是否有異常 |
| 調(diào)用鏈監(jiān)控 | 監(jiān)控整個(gè)上下游調(diào)用鏈路,是否有可用率下降等問(wèn)題 |
| JVM監(jiān)控 | 監(jiān)控內(nèi)存,線(xiàn)程等使用情況 |
2)業(yè)務(wù)監(jiān)控指標(biāo)
業(yè)務(wù)監(jiān)控指標(biāo),是整個(gè)監(jiān)控體系的“頂層”,能夠直接反映用戶(hù)使用業(yè)務(wù)的真實(shí)情況。在快遞快運(yùn)分揀業(yè)務(wù)域,體現(xiàn)如下(例如,發(fā)貨環(huán)節(jié),設(shè)置【發(fā)貨環(huán)節(jié)成功率】作為監(jiān)控指標(biāo),通過(guò)配置規(guī)則:當(dāng)前時(shí)間的發(fā)貨成功數(shù)據(jù)與上周同比下降超過(guò)30%,如果5分鐘內(nèi)連續(xù)出現(xiàn)3次告警,則觸發(fā)嚴(yán)重級(jí)別的告警)。
?
c、實(shí)驗(yàn)場(chǎng)景構(gòu)建
根據(jù)系統(tǒng)的架構(gòu)及技術(shù)特點(diǎn),以及可能出現(xiàn)的故障情況,參考設(shè)計(jì)各種實(shí)驗(yàn)場(chǎng)景。實(shí)驗(yàn)場(chǎng)景應(yīng)該盡可能地模擬真實(shí)世界中可能發(fā)生的各種故障和異常情況(可參考 歷史存量線(xiàn)上故障)。
| 故障分類(lèi) | 描述 |
| 服務(wù)器硬件故障 | 模擬服務(wù)器 CPU、內(nèi)存、硬盤(pán)等硬件組件故障。例如,通過(guò)設(shè)置硬件監(jiān)控軟件模擬 CPU 使用率瞬間達(dá)到 100%,或模擬內(nèi)存出現(xiàn)壞塊導(dǎo)致部分內(nèi)存無(wú)法正常讀寫(xiě),又或者模擬硬盤(pán)空間滿(mǎn)溢,影響應(yīng)用數(shù)據(jù)存儲(chǔ)和讀取 |
| 網(wǎng)絡(luò)設(shè)備故障 | 包括網(wǎng)絡(luò)交換機(jī)、路由器故障。如設(shè)置網(wǎng)絡(luò)交換機(jī)某個(gè)端口故障,造成部分服務(wù)器網(wǎng)絡(luò)連接中斷;模擬路由器丟包,導(dǎo)致應(yīng)用網(wǎng)絡(luò)通信延遲或數(shù)據(jù)傳輸錯(cuò)誤 |
| 操作系統(tǒng)故障 | 如操作系統(tǒng)內(nèi)核崩潰、系統(tǒng)資源耗盡(如文件描述符用盡)。可通過(guò)編寫(xiě)腳本消耗系統(tǒng)資源,觸發(fā)文件描述符不足的情況,觀(guān)察應(yīng)用在這種操作系統(tǒng)故障下的表現(xiàn) |
| 應(yīng)用程序自身故障 | 例如代碼邏輯錯(cuò)誤導(dǎo)致空指針異常、內(nèi)存泄漏、死鎖等。可以在應(yīng)用代碼中特定位置人為插入引發(fā)空指針異常的代碼片段,進(jìn)行局部模擬;對(duì)于內(nèi)存泄漏,可通過(guò)工具模擬對(duì)象未正確釋放內(nèi)存的情況;通過(guò)編寫(xiě)存在競(jìng)爭(zhēng)條件的代碼模擬死鎖場(chǎng)景 |
| 中間件故障 | 若應(yīng)用使用數(shù)據(jù)庫(kù)中間件、消息隊(duì)列中間件等,可模擬中間件故障。比如數(shù)據(jù)庫(kù)中間件連接池耗盡,導(dǎo)致應(yīng)用無(wú)法獲取數(shù)據(jù)庫(kù)連接;消息隊(duì)列中間件消息堆積、消息丟失等。以數(shù)據(jù)庫(kù)中間件為例,可通過(guò)修改配置參數(shù),限制連接池大小,快速創(chuàng)建大量數(shù)據(jù)庫(kù)連接請(qǐng)求,使連接池耗盡 |
| 高并發(fā)壓力 | 利用性能測(cè)試工具模擬大量用戶(hù)同時(shí)訪(fǎng)問(wèn)應(yīng)用,造成系統(tǒng)負(fù)載過(guò)高。例如,使用 JMeter 模擬每秒數(shù)千個(gè)并發(fā)請(qǐng)求,測(cè)試應(yīng)用在高并發(fā)場(chǎng)景下的穩(wěn)定性和故障應(yīng)對(duì)能力 |
| 環(huán)境變量錯(cuò)誤 | 修改應(yīng)用運(yùn)行所需的環(huán)境變量,如配置錯(cuò)誤的數(shù)據(jù)庫(kù)連接字符串、錯(cuò)誤的系統(tǒng)路徑等,觀(guān)察應(yīng)用能否正確識(shí)別并處理這些錯(cuò)誤 |
1)一般場(chǎng)景構(gòu)建
①CPU使用率(單個(gè)故障場(chǎng)景樣例及核心參數(shù)解釋?zhuān)?/p>
?演練目的:CPU混沌實(shí)驗(yàn)用于在主機(jī)模擬CPU負(fù)載情況,通過(guò)搶占CPU資源,模擬CPU在特定負(fù)載情況下,驗(yàn)證其對(duì)服務(wù)質(zhì)量、監(jiān)控告警、流量調(diào)度、彈性伸縮等應(yīng)用能力的影響。
?核心參數(shù)解釋
?使用率:根據(jù)研發(fā)配置的MDC告警閾值決定(例:研發(fā)配置60%。80%-90%)
?搶占模式:故意運(yùn)行占用大量 CPU 資源的進(jìn)程,使得系統(tǒng)的 CPU 使用率飆升,從而觀(guān)察其他服務(wù)和進(jìn)程在資源競(jìng)爭(zhēng)下的表現(xiàn)。(勾選代表打開(kāi)該模式)
?滿(mǎn)載核數(shù):核心滿(mǎn)載個(gè)數(shù)(如果一個(gè)系統(tǒng)在正常運(yùn)行時(shí)很少有核心達(dá)到滿(mǎn)載,但在混沌工程測(cè)試中有多個(gè)核心持續(xù)滿(mǎn)載,那么可能表明系統(tǒng)在極端情況下的資源分配存在問(wèn)題,或者系統(tǒng)并沒(méi)有正確地平衡負(fù)載。)
?滿(mǎn)載核索引:每個(gè) CPU 核心在操作系統(tǒng)中都有一個(gè)唯一的索引號(hào),這些索引號(hào)通常從 0 開(kāi)始計(jì)數(shù)。(例:0,1 / 0-2) 參數(shù)優(yōu)先級(jí):使用率 > 滿(mǎn)載核數(shù) > 滿(mǎn)載核索引 建議:第一次演練優(yōu)先使用【使用率】
②更多場(chǎng)景及選型原則:混沌工程-故障演練場(chǎng)景選型及實(shí)施說(shuō)明?
2)復(fù)雜場(chǎng)景構(gòu)建
①單應(yīng)用單故障場(chǎng)景“多參數(shù)”組合構(gòu)建
場(chǎng)景構(gòu)建說(shuō)明
| 構(gòu)建參數(shù) | 故障類(lèi)型 |
| 接口參數(shù):請(qǐng)求類(lèi)型(GET/POST)、數(shù)據(jù)格式(JSON/XML)、請(qǐng)求體大小(1KB/10KB) | 資源耗盡(CPU / 內(nèi)存) |
| 配置參數(shù):線(xiàn)程池大小(5/10)、超時(shí)閾值(1s/5s)、緩存 TTL(30s/60s) | 網(wǎng)絡(luò)異常(延遲 / 丟包) |
| 環(huán)境參數(shù):CPU 利用率(50%/80%)、內(nèi)存占用(60%/90%)、網(wǎng)絡(luò)延遲(100ms/500ms) | 數(shù)據(jù)異常(錯(cuò)誤碼 / 空值) |
(場(chǎng)景樣例)連接庫(kù)請(qǐng)求延遲&業(yè)務(wù)的異常流量注入
?場(chǎng)景描述:依據(jù)場(chǎng)景構(gòu)建的基本原則,我們?cè)跇?gòu)建數(shù)據(jù)庫(kù)請(qǐng)求延遲的情況前提下,向系統(tǒng)注入帶有異常業(yè)務(wù)數(shù)據(jù)的流量,以檢查應(yīng)急預(yù)案對(duì)應(yīng)的處理能力。
| 攻擊接口 | http://xxxxx.forcebot.jdl.com/services/xxxxx/getWaybillChute | ||
| 攻擊步驟 | 預(yù)期結(jié)果 | 結(jié)論 | |
| 10*10個(gè)QPS將壓測(cè)流量灌入(正常流量) | 事務(wù)成功率100% | pass | |
| 植入故障,觀(guān)察(故障占比:80%,A分組5臺(tái)打掛,B分組3臺(tái)打掛) | 5分鐘內(nèi)觸發(fā)數(shù)據(jù)庫(kù)請(qǐng)求告警,守方報(bào)備到備戰(zhàn)群 | pass | |
| 調(diào)節(jié)壓測(cè)流量,QPS增加到60*10(值逐步增加) | 服務(wù)可用率降低,TP99上升 | pass | |
| 調(diào)節(jié)壓測(cè)流量,QPS增加到80*10(值逐步增加) | 服務(wù)可用率降低,TP99上升 | pass | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 較長(zhǎng)時(shí)間內(nèi)服務(wù)沒(méi)起來(lái) | 事務(wù)成功率100%,連接數(shù)據(jù)庫(kù)請(qǐng)求正常,TP99恢復(fù)正常(TCP重傳、數(shù)據(jù)庫(kù)連接、下線(xiàn)機(jī)器、擴(kuò)容) | pass | |
| 停止故障任務(wù) | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常,連接數(shù)據(jù)庫(kù)請(qǐng)求正常 | pass | |
| 停止壓測(cè)腳本 | 流量停止灌入 | pass | |
②單應(yīng)用多故障場(chǎng)景組合構(gòu)建
?場(chǎng)景構(gòu)建說(shuō)明:可參考如下組合方式,構(gòu)建單應(yīng)用多故障場(chǎng)景。
| 組合方式 | 組合描述 |
| 基于故障影響范圍組合 | 局部與全局故障組合:先設(shè)置一個(gè)局部故障,如某個(gè)模塊的代碼邏輯錯(cuò)誤導(dǎo)致該模塊功能不可用,同時(shí)再設(shè)置一個(gè)影響全局的故障,如服務(wù)器內(nèi)存耗盡,使整個(gè)應(yīng)用運(yùn)行緩慢甚至崩潰。這樣可以測(cè)試應(yīng)用在局部問(wèn)題和整體資源危機(jī)同時(shí)出現(xiàn)時(shí)的應(yīng)對(duì)策略 |
| 上下游故障組合:如果應(yīng)用存在上下游依賴(lài)關(guān)系,模擬上游服務(wù)故障(如數(shù)據(jù)提供方接口異常)與下游服務(wù)故障(如數(shù)據(jù)存儲(chǔ)服務(wù)不可用)同時(shí)發(fā)生 | |
| 基于故障發(fā)生時(shí)間順序組合 | 先后發(fā)生故障組合:設(shè)定故障按特定順序出現(xiàn)。比如,先模擬網(wǎng)絡(luò)短暫中斷,導(dǎo)致部分?jǐn)?shù)據(jù)傳輸失敗,緊接著由于數(shù)據(jù)處理異常,引發(fā)應(yīng)用內(nèi)部的緩存雪崩問(wèn)題。通過(guò)這種順序組合,測(cè)試應(yīng)用在連鎖故障場(chǎng)景下的恢復(fù)能力和數(shù)據(jù)一致性 |
| 周期性故障組合:設(shè)置周期性出現(xiàn)的故障,如每隔一段時(shí)間(如 10 分鐘)網(wǎng)絡(luò)出現(xiàn)一次短暫擁塞,在擁塞期間,同時(shí)出現(xiàn)應(yīng)用程序的內(nèi)存泄漏問(wèn)題逐漸加重。這種組合可以觀(guān)察應(yīng)用在長(zhǎng)期面對(duì)周期性故障和持續(xù)惡化的內(nèi)部故障時(shí)的表現(xiàn) | |
| 基于業(yè)務(wù)流程關(guān)鍵節(jié)點(diǎn)組合 | 核心業(yè)務(wù)流程故障組合:針對(duì)應(yīng)用的核心業(yè)務(wù)流程設(shè)置故障。以在線(xiàn)支付流程為例,在用戶(hù)輸入支付信息階段,模擬輸入校驗(yàn)?zāi)K出現(xiàn)故障,接受錯(cuò)誤格式的支付信息;同時(shí)在支付確認(rèn)階段,模擬與支付網(wǎng)關(guān)通信故障,測(cè)試支付流程在多個(gè)關(guān)鍵節(jié)點(diǎn)故障下的健壯性 |
| 業(yè)務(wù)高峰與故障組合:結(jié)合業(yè)務(wù)使用高峰時(shí)段,疊加多種故障。例如,一個(gè)視頻播放應(yīng)用在晚上用戶(hù)觀(guān)看高峰期,同時(shí)出現(xiàn)服務(wù)器 CPU 負(fù)載過(guò)高、視頻源文件損壞、CDN 節(jié)點(diǎn)故障等多種故障,測(cè)試應(yīng)用在高業(yè)務(wù)壓力和復(fù)雜故障環(huán)境下能否保障用戶(hù)基本體驗(yàn) |
(場(chǎng)景樣例)核心依賴(lài)中間件MySQL請(qǐng)求延遲&CPU使用率增加場(chǎng)景
?場(chǎng)景描述:該場(chǎng)景主要在單應(yīng)用模式下,在數(shù)據(jù)庫(kù)和CPU維度,參考故障的一般發(fā)生順序,進(jìn)行組合注入,并同步觀(guān)察系統(tǒng)恢復(fù)能力。
?實(shí)際執(zhí)行層面,在植入CPU使用率和數(shù)據(jù)庫(kù)延遲故障時(shí),預(yù)期觸發(fā)CPU和接口可用利率告警,但實(shí)際情況中,CPU告警按預(yù)期觸發(fā),但接口可用率報(bào)警并未觸發(fā)。
| 攻擊接口 | com.jdl.xxxxx.xxxxx.api.gather.xxxxx#queryWayGather | ||
| 攻擊步驟 | 預(yù)期結(jié)果 | 結(jié)論 | |
| 20個(gè)QPS將流量灌入對(duì)應(yīng)機(jī)器(接口單機(jī)線(xiàn)上最大QPS 66) | 事務(wù)成功率100% | pass | |
| 植入故障1【cpu 使用率70%+MYSQL延遲2000ms】 | 期望:觸發(fā)cpu告警,觸發(fā)接口可用率告警 | fail | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 | 事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 植入故障2【針對(duì)擴(kuò)容新增機(jī)器 植入cpu 使用率70%】 | 新機(jī)器持續(xù)cpu告警,持續(xù)擴(kuò)容,保證分組下集群數(shù)量 | pass | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 調(diào)節(jié)壓測(cè)流量,QPS增加到1980(線(xiàn)上峰值3倍) | 服務(wù)可用率降低,CPU使用率持續(xù)增加,TP99上升 觸發(fā)方法調(diào)用次數(shù)告警 | pass | |
| 停止壓測(cè)腳本 | 流量停止灌入 | pass | |
③多應(yīng)用多故障場(chǎng)景組合構(gòu)建
場(chǎng)景構(gòu)建說(shuō)明:多應(yīng)用多故障場(chǎng)景的構(gòu)建,可基于單應(yīng)用單故障的場(chǎng)景進(jìn)行組合,可參考如下組合方式。目前針對(duì)該類(lèi)型場(chǎng)景還未進(jìn)行覆蓋,后續(xù)基于上下游系統(tǒng)的架構(gòu)分析和調(diào)用關(guān)系,進(jìn)行組合。如應(yīng)用A調(diào)用應(yīng)用B,在給應(yīng)用A植入故障的同時(shí),B應(yīng)用也進(jìn)行故障植入。
| 組合方式 | 組合描述 |
| 基于業(yè)務(wù)流程的組合 | 串聯(lián)業(yè)務(wù)流程故障組合:業(yè)務(wù)場(chǎng)景 A發(fā)生一個(gè)故障,同時(shí)業(yè)務(wù)場(chǎng)景B也發(fā)生也一個(gè)故障,同時(shí) A和B 是不同應(yīng)用,業(yè)務(wù)流程串聯(lián) |
| 并發(fā)業(yè)務(wù)流程故障組合:業(yè)務(wù)場(chǎng)景 A發(fā)生一個(gè)故障,同時(shí)業(yè)務(wù)場(chǎng)景B也發(fā)生也一個(gè)故障,同時(shí) A和B 是不同應(yīng)用,業(yè)務(wù)流程并發(fā) | |
| 基于故障影響范圍的組合 | 局部與全局故障組合:局部故障可以是某個(gè)內(nèi)部使用的特定應(yīng)用出現(xiàn)功能故障,全局故障則可以是影響整個(gè)企業(yè)的網(wǎng)絡(luò)故障或核心數(shù)據(jù)庫(kù)故障 |
| 關(guān)鍵與非關(guān)鍵應(yīng)用故障組合:設(shè)置故障場(chǎng)景為核心業(yè)務(wù)系統(tǒng)出現(xiàn)數(shù)據(jù)庫(kù)連接池耗盡的故障,非核心應(yīng)用發(fā)生另一個(gè)故障 | |
| 基于故障發(fā)生時(shí)間順序的組合 | 先后發(fā)生故障組合:先設(shè)置一個(gè)應(yīng)用的故障,待其產(chǎn)生一定影響后,再觸發(fā)另一個(gè)應(yīng)用的故障 |
| 周期性故障組合:設(shè)置某些故障周期性出現(xiàn),如每隔一段時(shí)間(如每天凌晨)出現(xiàn)故障A,同時(shí),在每周的特定時(shí)間段(如周五下午業(yè)務(wù)高峰時(shí)段)出現(xiàn)故障B,組合參考 |
?
3)計(jì)劃外場(chǎng)景構(gòu)建
故障演練計(jì)劃外場(chǎng)景通常是指在沒(méi)有預(yù)先計(jì)劃或通知的情況下,模擬系統(tǒng)或服務(wù)出現(xiàn)故障的情境,以測(cè)試和提高系統(tǒng)的可靠性和團(tuán)隊(duì)的應(yīng)急響應(yīng)能力。其主要特點(diǎn)包括:突發(fā)性、真實(shí)感、壓力測(cè)試、團(tuán)隊(duì)協(xié)作。以下是在研發(fā)毫無(wú)防備的情況,進(jìn)行的一次突襲式的故障演練例子:
混沌工程與傳統(tǒng)的故障引入測(cè)試,在注入場(chǎng)景和工具使用方面存在重疊。故障注入測(cè)試,是混沌工程實(shí)驗(yàn)的一種驗(yàn)證策略。 其本質(zhì)區(qū)別,是思維方式的差異 ,故障注人測(cè)試是通過(guò)已知故障和應(yīng)急預(yù)案,確認(rèn)系統(tǒng)對(duì)已知風(fēng)險(xiǎn)的承載能力。而混沌工程,是通過(guò)構(gòu)造諸如應(yīng)急預(yù)案范圍外的故障場(chǎng)景,確認(rèn)系統(tǒng)對(duì)未知風(fēng)險(xiǎn)的承載能力。
(場(chǎng)景樣例)JAVA進(jìn)程線(xiàn)程池滿(mǎn)(未在演練劇本內(nèi)的故障,觀(guān)察系統(tǒng)應(yīng)急能力)
通常在劇本評(píng)審階段,測(cè)試團(tuán)隊(duì)會(huì)與架構(gòu)團(tuán)隊(duì)完成全量場(chǎng)景評(píng)估,同時(shí)會(huì)提取部分場(chǎng)景,在約定演練時(shí)間計(jì)劃外執(zhí)行,研發(fā)團(tuán)隊(duì)對(duì)此類(lèi)故障的執(zhí)行計(jì)劃不知情,以此強(qiáng)化驗(yàn)證其應(yīng)急處理能力。
例如:在某計(jì)劃外場(chǎng)景演練過(guò)程中,發(fā)現(xiàn)2個(gè)問(wèn)題,①當(dāng)植入JAVA進(jìn)程線(xiàn)程池滿(mǎn)的故障時(shí),預(yù)期觸發(fā)CPU告警,研發(fā)團(tuán)隊(duì)并未第一時(shí)間同步報(bào)備。②在故障停止時(shí),預(yù)期所有機(jī)器及事務(wù)恢復(fù)正常,并由研發(fā)接口人報(bào)備同步恢復(fù)信息,但研發(fā)團(tuán)隊(duì)并未第一時(shí)間同步報(bào)備。
由此可見(jiàn),計(jì)劃外的場(chǎng)景,在識(shí)別系統(tǒng)應(yīng)急能力之外,可更多反映研發(fā)團(tuán)隊(duì),在故障處理過(guò)程中的組織協(xié)同能力。
| 演練執(zhí)行 | |||
| 攻擊接口 | com.jdl.xxxxx.resource.api.message.xxxxx#isNeedVerificationCode | ||
| 攻擊步驟 | 預(yù)期結(jié)果 | 結(jié)論 | |
| 1個(gè)QPS將流量灌入對(duì)應(yīng)機(jī)器 | 事務(wù)成功率100% | pass | |
| 植入JAVA進(jìn)程線(xiàn)程池滿(mǎn)故障,觀(guān)察 | 10分鐘內(nèi)觸發(fā)CPU使用率告警,守方報(bào)備到備戰(zhàn)群,業(yè)務(wù)全部失敗 | fail | |
| 故障生效后立即調(diào)節(jié)壓測(cè)流量,QPS增加到10筆/s(日常量) | 服務(wù)可用率降低,CPU使用率持續(xù)增加,TP99上升 | pass | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 停止故障任務(wù) | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | fail | |
| 停止壓測(cè)腳本 | 流量停止灌入 | pass | |
?
4)流量沖擊融合場(chǎng)景構(gòu)建
?系統(tǒng)在故障發(fā)生時(shí),例如,C端用戶(hù)在響應(yīng)卡滯情況下,如系統(tǒng)未給予明確的故障提示、降級(jí)方案或恢復(fù)預(yù)期,往往會(huì)通過(guò)重復(fù)操作,確認(rèn)系統(tǒng)恢復(fù)進(jìn)展,請(qǐng)求量存在倍增可能。
?后端平臺(tái)類(lèi)系統(tǒng)對(duì)接,請(qǐng)求方往往會(huì)通過(guò)自動(dòng)重試,嘗試重建成功請(qǐng)求,同時(shí)在長(zhǎng)鏈路業(yè)務(wù)場(chǎng)景下,如鏈路各應(yīng)用重試策略未統(tǒng)一,請(qǐng)求量存在倍增可能。以上,在故障恢復(fù)過(guò)程中,已部分恢復(fù)的服務(wù),大概率會(huì)被倍增流量快速擊潰,造成系統(tǒng)可用性雪崩。有必要通過(guò)融合流量沖擊場(chǎng)景的混沌實(shí)驗(yàn),確認(rèn)系統(tǒng)的極端風(fēng)險(xiǎn)承載能力。
(場(chǎng)景樣例)應(yīng)用CPU滿(mǎn)載混合單機(jī)流量激增
?場(chǎng)景描述:在CPU滿(mǎn)載的情況下,模擬接口流量激增。首先植入CPU滿(mǎn)載,再調(diào)節(jié)注入流量,觀(guān)察整個(gè)處理過(guò)程。
| 演練執(zhí)行 | |||
| 攻擊接口 | 整個(gè)應(yīng)用 | ||
| 攻擊步驟 | 預(yù)期結(jié)果 | 結(jié)論 | |
| 小流量注入 | 事務(wù)成功率100% | pass | |
| 植入故障CPU占用率80%,植入比例:70%,觀(guān)察 | CPU滿(mǎn)載,5分鐘內(nèi)觸發(fā)CPU使用率告警,守方報(bào)備到備戰(zhàn)群 | pass | |
| 調(diào)節(jié)壓測(cè)流量,單機(jī)QPS增加到1倍壓測(cè)流量(梯度),單機(jī)CPU占有率>60% | CPU使用率持續(xù)增加,TP99上升 | pass | |
| 調(diào)節(jié)壓測(cè)流量,單機(jī)QPS增加到2倍壓測(cè)流量(梯度),單機(jī)CPU占有率>80% | CPU使用率持續(xù)增加,TP99上升 | pass | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 | 事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 觀(guān)察到守方通過(guò)防守動(dòng)作止損 | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 停止故障任務(wù) | 集群下所有機(jī)器事務(wù)成功率100%,CPU使用率60%以下,TP99恢復(fù)正常 | pass | |
| 停止壓測(cè)腳本 | 流量停止注入 | pass | |
d、實(shí)驗(yàn)劇本構(gòu)建
1)劇本設(shè)計(jì)詳解
故障注入過(guò)程,尤其是在生產(chǎn)或準(zhǔn)生產(chǎn)環(huán)境實(shí)驗(yàn),未經(jīng)評(píng)估的故障場(chǎng)景,極易造成線(xiàn)上生產(chǎn)異動(dòng),對(duì)實(shí)驗(yàn)方案的嚴(yán)謹(jǐn)性以及人員的專(zhuān)業(yè)性,提出了更高的要求。實(shí)驗(yàn)劇本構(gòu)建主要包括以下幾個(gè)要素。
| 劇本構(gòu)建核心要素 | 關(guān)鍵事項(xiàng) | 準(zhǔn)入標(biāo)準(zhǔn) | 準(zhǔn)出標(biāo)準(zhǔn) |
| 明確實(shí)驗(yàn)?zāi)繕?biāo) | ·定義實(shí)驗(yàn)?zāi)康模鹤R(shí)別實(shí)驗(yàn)的核心目的,例如提高系統(tǒng)的彈性、驗(yàn)證故障處理機(jī)制、評(píng)估服務(wù)降級(jí)策略等。 ·選擇關(guān)鍵性能指標(biāo)(KPIs):確定用于評(píng)估實(shí)驗(yàn)結(jié)果的關(guān)鍵性能指標(biāo),如系統(tǒng)的響應(yīng)時(shí)間、可用性、吞吐量、錯(cuò)誤率等。 ·設(shè)定具體目標(biāo):制定具體的、可衡量的目標(biāo)。例如,“在網(wǎng)絡(luò)延遲增加的情況下,系統(tǒng)響應(yīng)時(shí)間不超過(guò)2秒”。 ·業(yè)務(wù)影響考量:確保實(shí)驗(yàn)?zāi)繕?biāo)與業(yè)務(wù)目標(biāo)相一致,評(píng)估實(shí)驗(yàn)對(duì)業(yè)務(wù)連續(xù)性和用戶(hù)體驗(yàn)的潛在影響。 | ·團(tuán)隊(duì)準(zhǔn)備:確保參與實(shí)驗(yàn)的團(tuán)隊(duì)成員了解實(shí)驗(yàn)?zāi)康摹⒘鞒毯蛻?yīng)急響應(yīng)計(jì)劃。 ·確保業(yè)務(wù)影響最小化:制定策略,確保實(shí)驗(yàn)不會(huì)對(duì)關(guān)鍵業(yè)務(wù)功能造成重大影響。可以通過(guò)選擇非高峰時(shí)段進(jìn)行實(shí)驗(yàn)或在實(shí)驗(yàn)前進(jìn)行業(yè)務(wù)影響評(píng)估。 ·風(fēng)險(xiǎn)識(shí)別:系統(tǒng)地識(shí)別實(shí)驗(yàn)可能帶來(lái)的所有潛在風(fēng)險(xiǎn),包括對(duì)系統(tǒng)穩(wěn)定性、數(shù)據(jù)完整性和業(yè)務(wù)連續(xù)性的影響。 | ·設(shè)定實(shí)驗(yàn)范圍和條件:明確實(shí)驗(yàn)的范圍(例如哪些服務(wù)或組件會(huì)受到影響)和條件(例如故障的持續(xù)時(shí)間、強(qiáng)度等)。 |
| 選擇故障場(chǎng)景 | ·識(shí)別潛在故障:通過(guò)對(duì)系統(tǒng)架構(gòu)、依賴(lài)關(guān)系和歷史故障記錄的分析,識(shí)別潛在的故障類(lèi)型。包括網(wǎng)絡(luò)延遲、服務(wù)宕機(jī)、資源耗盡、數(shù)據(jù)庫(kù)故障、磁盤(pán)故障,超時(shí)、服務(wù)不存活等。 ·優(yōu)先級(jí)排序:根據(jù)故障對(duì)業(yè)務(wù)的影響程度進(jìn)行排序。優(yōu)先選擇那些對(duì)關(guān)鍵業(yè)務(wù)流程影響較大的故障;考慮故障發(fā)生的可能性,優(yōu)先演練那些較高概率發(fā)生的故障。 ·場(chǎng)景細(xì)化:將故障場(chǎng)景具體化,包括故障的觸發(fā)條件、影響范圍和預(yù)期結(jié)果;考慮組合多個(gè)故障場(chǎng)景,模擬復(fù)雜環(huán)境下的系統(tǒng)行為。 | ·場(chǎng)景驗(yàn)證:確保所選故障場(chǎng)景經(jīng)過(guò)驗(yàn)證,可以在實(shí)驗(yàn)環(huán)境中安全地注入和控制。 ·團(tuán)隊(duì)準(zhǔn)備:團(tuán)隊(duì)成員應(yīng)了解故障場(chǎng)景的細(xì)節(jié)、實(shí)驗(yàn)步驟和應(yīng)急響應(yīng)計(jì)劃。 ·審批流程:實(shí)驗(yàn)需要獲得相關(guān)方的批準(zhǔn),特別是涉及到關(guān)鍵業(yè)務(wù)系統(tǒng)時(shí)。 | ·可行性完成:評(píng)估故障場(chǎng)景的實(shí)施難度,包括技術(shù)可行性和資源需求,確保實(shí)驗(yàn)?zāi)軌蛟诂F(xiàn)有條件下順利進(jìn)行。 ·影響評(píng)估完成:預(yù)估故障場(chǎng)景可能對(duì)系統(tǒng)和用戶(hù)造成的影響,并確保其在可控范圍內(nèi),避免對(duì)生產(chǎn)環(huán)境造成嚴(yán)重影響。 |
| 設(shè)計(jì)實(shí)驗(yàn)方案 | ·場(chǎng)景描述:詳細(xì)描述每個(gè)故障場(chǎng)景,包括故障類(lèi)型、注入方式和預(yù)期影響。 ·步驟規(guī)劃:制定實(shí)驗(yàn)的具體步驟,包括故障注入的時(shí)間、地點(diǎn)和方式。 ·成功標(biāo)準(zhǔn):定義實(shí)驗(yàn)的成功標(biāo)準(zhǔn),即在故障條件下系統(tǒng)應(yīng)達(dá)到的性能水平。 | ·風(fēng)險(xiǎn)評(píng)估:完成對(duì)實(shí)驗(yàn)的風(fēng)險(xiǎn)評(píng)估,識(shí)別可能的風(fēng)險(xiǎn)和影響,并制定相應(yīng)的緩解措施。 ·團(tuán)隊(duì)準(zhǔn)備:團(tuán)隊(duì)成員已接受必要的培訓(xùn),了解實(shí)驗(yàn)步驟、應(yīng)急響應(yīng)計(jì)劃和溝通渠道。 ·溝通計(jì)劃:確保所有相關(guān)方已被告知實(shí)驗(yàn)的時(shí)間、范圍和可能的影響,并制定溝通計(jì)劃以便在實(shí)驗(yàn)過(guò)程中及時(shí)更新信息。 | ·方案風(fēng)險(xiǎn)評(píng)估完成:評(píng)估實(shí)驗(yàn)對(duì)系統(tǒng)和用戶(hù)的實(shí)際影響,確保實(shí)驗(yàn)沒(méi)有導(dǎo)致不可接受的中斷或損害。 |
| 風(fēng)險(xiǎn)評(píng)估與應(yīng)急預(yù)案 | ·風(fēng)險(xiǎn)識(shí)別:識(shí)別實(shí)驗(yàn)可能帶來(lái)的風(fēng)險(xiǎn),包括對(duì)系統(tǒng)穩(wěn)定性和業(yè)務(wù)運(yùn)營(yíng)的影響。 ·應(yīng)急預(yù)案:制定緩解措施,如快速回滾計(jì)劃和應(yīng)急響應(yīng)方案。 | ·風(fēng)險(xiǎn)識(shí)別:系統(tǒng)地識(shí)別實(shí)驗(yàn)可能帶來(lái)的所有潛在風(fēng)險(xiǎn),包括對(duì)系統(tǒng)穩(wěn)定性、數(shù)據(jù)完整性和業(yè)務(wù)連續(xù)性的影響。 ·應(yīng)急響應(yīng)計(jì)劃:制定詳細(xì)的應(yīng)急響應(yīng)計(jì)劃,明確角色和責(zé)任,以便在實(shí)驗(yàn)過(guò)程中快速響應(yīng)任何突發(fā)問(wèn)題。 ·審批和溝通:風(fēng)險(xiǎn)評(píng)估報(bào)告和緩解計(jì)劃需要獲得相關(guān)方的審核和批準(zhǔn)。確保所有相關(guān)方都了解可能的風(fēng)險(xiǎn)和緩解措施。 | ·風(fēng)險(xiǎn)評(píng)估完成:完成對(duì)實(shí)驗(yàn)風(fēng)險(xiǎn)的評(píng)估,并制定相應(yīng)的應(yīng)急預(yù)案。 |
| 實(shí)驗(yàn)環(huán)境準(zhǔn)備 | ·環(huán)境搭建:準(zhǔn)備實(shí)驗(yàn)環(huán)境,確保其與生產(chǎn)環(huán)境盡可能相似,以提高實(shí)驗(yàn)結(jié)果的可靠性。 ·工具配置:配置必要的故障注入和監(jiān)控工具,確保能夠?qū)崟r(shí)收集和分析數(shù)據(jù)。 | ·環(huán)境驗(yàn)證:驗(yàn)證實(shí)驗(yàn)環(huán)境的準(zhǔn)備情況,包括配置、數(shù)據(jù)和工具的可用性。 ·溝通確認(rèn):確認(rèn)所有相關(guān)方(如開(kāi)發(fā)、運(yùn)維、業(yè)務(wù)團(tuán)隊(duì))已收到實(shí)驗(yàn)通知并同意進(jìn)行實(shí)驗(yàn)。 | ·環(huán)境隔離:確保實(shí)驗(yàn)環(huán)境與生產(chǎn)環(huán)境適當(dāng)隔離(成熟度高的可以不隔離),以避免實(shí)驗(yàn)對(duì)生產(chǎn)系統(tǒng)造成不必要的影響。 ·環(huán)境一致性:驗(yàn)證實(shí)驗(yàn)環(huán)境的配置與生產(chǎn)環(huán)境盡可能一致,包括硬件、軟件版本、網(wǎng)絡(luò)配置等,以確保實(shí)驗(yàn)結(jié)果的可用性和相關(guān)性。 ·資源可用性:確保實(shí)驗(yàn)所需的所有資源(如計(jì)算資源、存儲(chǔ)、網(wǎng)絡(luò)帶寬)已準(zhǔn)備就緒,并能夠支持實(shí)驗(yàn)的順利進(jìn)行。 |
| 實(shí)驗(yàn)執(zhí)行與數(shù)據(jù)分析 | ·實(shí)時(shí)監(jiān)控:在實(shí)驗(yàn)過(guò)程中,實(shí)時(shí)監(jiān)控系統(tǒng)狀態(tài)和關(guān)鍵指標(biāo),確保能夠快速識(shí)別和響應(yīng)異常情況。 ·故障注入:按照實(shí)驗(yàn)方案注入故障,觀(guān)察系統(tǒng)的反應(yīng)。 ·數(shù)據(jù)收集:收集實(shí)驗(yàn)期間的所有相關(guān)數(shù)據(jù),包括日志、監(jiān)控指標(biāo)和用戶(hù)反饋。 ·結(jié)果分析:分析實(shí)驗(yàn)結(jié)果,評(píng)估系統(tǒng)在故障條件下的表現(xiàn),并識(shí)別改進(jìn)機(jī)會(huì)。 | ·風(fēng)險(xiǎn)評(píng)估完成:確保已進(jìn)行全面的風(fēng)險(xiǎn)評(píng)估,識(shí)別潛在風(fēng)險(xiǎn),并制定相應(yīng)的緩解措施。 ·團(tuán)隊(duì)準(zhǔn)備就緒:所有相關(guān)團(tuán)隊(duì)(如開(kāi)發(fā)、運(yùn)維、安全)已準(zhǔn)備好,并了解各自的職責(zé)和應(yīng)對(duì)措施。 ·應(yīng)急計(jì)劃確認(rèn):確保應(yīng)急計(jì)劃已制定并經(jīng)過(guò)驗(yàn)證,所有團(tuán)隊(duì)成員都清楚如何在緊急情況下快速恢復(fù)系統(tǒng)。 ·環(huán)境驗(yàn)證:實(shí)驗(yàn)環(huán)境已被驗(yàn)證為與生產(chǎn)環(huán)境相似,并且所有必要的工具和配置已準(zhǔn)備就緒。 ·溝通與批準(zhǔn):獲得所有相關(guān)方(包括管理層和業(yè)務(wù)團(tuán)隊(duì))的批準(zhǔn),確保他們了解實(shí)驗(yàn)計(jì)劃和可能的影響。 ·監(jiān)控和日志系統(tǒng)在線(xiàn):確保監(jiān)控和日志系統(tǒng)正常運(yùn)行,以便實(shí)時(shí)追蹤實(shí)驗(yàn)過(guò)程中系統(tǒng)的狀態(tài)和行為。 | ·實(shí)驗(yàn)結(jié)果評(píng)估:對(duì)照預(yù)定的成功標(biāo)準(zhǔn)評(píng)估實(shí)驗(yàn)結(jié)果,確保實(shí)驗(yàn)?zāi)繕?biāo)已實(shí)現(xiàn)。 ·系統(tǒng)恢復(fù)確認(rèn):確保系統(tǒng)已恢復(fù)到正常運(yùn)行狀態(tài),所有故障注入的影響已完全消除。 ·數(shù)據(jù)完整性驗(yàn)證:檢查實(shí)驗(yàn)期間的數(shù)據(jù)完整性,確保沒(méi)有數(shù)據(jù)丟失或損壞。 ·報(bào)告生成:生成詳細(xì)的實(shí)驗(yàn)報(bào)告,包括實(shí)驗(yàn)過(guò)程、結(jié)果、發(fā)現(xiàn)的問(wèn)題和改進(jìn)建議。 ·經(jīng)驗(yàn)總結(jié)與分享:召開(kāi)經(jīng)驗(yàn)總結(jié)會(huì)議,分享實(shí)驗(yàn)中的經(jīng)驗(yàn)教訓(xùn),并更新相關(guān)的操作文檔和策略。 ·后續(xù)行動(dòng)計(jì)劃:確定并記錄需要改進(jìn)的領(lǐng)域和后續(xù)行動(dòng)計(jì)劃,以提升系統(tǒng)的彈性和可靠性。 |
| 復(fù)盤(pán)與成熟度評(píng)估 | ·報(bào)告撰寫(xiě):撰寫(xiě)詳細(xì)的實(shí)驗(yàn)報(bào)告,記錄實(shí)驗(yàn)過(guò)程、結(jié)果和發(fā)現(xiàn)的問(wèn)題。 ·改進(jìn)計(jì)劃:根據(jù)實(shí)驗(yàn)結(jié)果制定系統(tǒng)改進(jìn)計(jì)劃,并計(jì)劃后續(xù)步驟。 ·知識(shí)共享:將實(shí)驗(yàn)結(jié)果和經(jīng)驗(yàn)教訓(xùn)分享給相關(guān)團(tuán)隊(duì),促進(jìn)組織內(nèi)部的知識(shí)積累。 ·復(fù)盤(pán)會(huì)議:召開(kāi)復(fù)盤(pán)會(huì)議,討論實(shí)驗(yàn)中的亮點(diǎn)和不足,優(yōu)化未來(lái)的實(shí)驗(yàn)流程。 ·成熟度改進(jìn):評(píng)估被演練系統(tǒng)服務(wù)成熟度。 | ·數(shù)據(jù)完整性:確保所有相關(guān)數(shù)據(jù)和日志已收集完畢,并且數(shù)據(jù)質(zhì)量足以支持有效分析。 ·參與者準(zhǔn)備:確保所有關(guān)鍵參與者(如開(kāi)發(fā)、運(yùn)維、安全團(tuán)隊(duì)成員)已準(zhǔn)備好參與復(fù)盤(pán)會(huì)議,并了解實(shí)驗(yàn)的背景和結(jié)果。 ·目標(biāo)明確:復(fù)盤(pán)的目標(biāo)和預(yù)期成果已明確,并傳達(dá)給所有參與者 ·成熟度評(píng)估:已完成對(duì)當(dāng)前混沌工程實(shí)踐的成熟度評(píng)估,識(shí)別出需要改進(jìn)的領(lǐng)域。 | ·問(wèn)題識(shí)別與分析:已識(shí)別并分析實(shí)驗(yàn)中的所有關(guān)鍵問(wèn)題和挑戰(zhàn)。 ·成功與不足記錄:記錄實(shí)驗(yàn)中的成功經(jīng)驗(yàn)和不足之處,并分析其原因。 ·改進(jìn)措施制定:制定具體的改進(jìn)措施和后續(xù)行動(dòng)計(jì)劃,并獲得相關(guān)方的認(rèn)可。 ·文檔更新:更新相關(guān)文檔,包括操作手冊(cè)、實(shí)驗(yàn)報(bào)告和改進(jìn)計(jì)劃。 ·經(jīng)驗(yàn)分享:將復(fù)盤(pán)結(jié)果和經(jīng)驗(yàn)分享給更廣泛的團(tuán)隊(duì)或組織,以促進(jìn)知識(shí)共享。 |
2)劇本構(gòu)建樣例
?故障演練方案-快遞快運(yùn)-分揀條線(xiàn)-2024年12月?
e、工具選型
1)工具選型原則
①功能特性
?復(fù)雜場(chǎng)景構(gòu)建:對(duì)于復(fù)雜的分布式系統(tǒng),尤其是包含多種技術(shù)棧(如同時(shí)有微服務(wù)、數(shù)據(jù)庫(kù)、消息隊(duì)列等)的系統(tǒng),需要選擇能夠模擬多種故障類(lèi)型的工具,以更全面地測(cè)試系統(tǒng)的彈性。
?實(shí)驗(yàn)場(chǎng)景定制化:混沌工程工具應(yīng)該允許用戶(hù)根據(jù)自己的系統(tǒng)特點(diǎn)和需求定制實(shí)驗(yàn)場(chǎng)景,提供豐富的實(shí)驗(yàn)?zāi)0澹⒖赏ㄟ^(guò)修改這些模板或編寫(xiě)自己的實(shí)驗(yàn)?zāi)_本來(lái)定制實(shí)驗(yàn)。這種靈活性使得用戶(hù)能夠模擬特定的業(yè)務(wù)場(chǎng)景下可能出現(xiàn)的故障,如模擬電商系統(tǒng)在購(gòu)物高峰期時(shí)數(shù)據(jù)庫(kù)查詢(xún)緩慢的情況。
?系統(tǒng)集成能力:實(shí)驗(yàn)工具需要能夠與企業(yè)現(xiàn)有的系統(tǒng)和工具集成,如監(jiān)控系統(tǒng)、日志系統(tǒng)等。通過(guò)插件或者 API 的方式實(shí)現(xiàn)與其他系統(tǒng)的集成,增強(qiáng)工具的實(shí)用性。
②環(huán)境適配
?容器化基礎(chǔ)設(shè)施兼容性:隨著容器技術(shù)和 Kubernetes 的廣泛應(yīng)用,混沌工程工具需要加強(qiáng)對(duì)以上基礎(chǔ)環(huán)境的支持,更充分地兼容 Kubernetes(Pod、Deployment、Service 等),并進(jìn)行有效的故障注入。
?云平臺(tái)兼容性:對(duì)于部署在云平臺(tái)(如 京東云、阿里云、騰訊云、華為云、百度云、GCP、IBM Cloud、Oracle Cloud、AWS、Azure、Ali 等)上的系統(tǒng),需要考慮工具是否與這些云平臺(tái)兼容,是否能夠提供針對(duì)特定云平臺(tái)的故障模擬功能,。例如,AWS S3 存儲(chǔ)桶故障、Azure 虛擬機(jī)故障等特定故障情況,以適應(yīng)云環(huán)境下的實(shí)驗(yàn)需求。
?跨平臺(tái)支持:對(duì)于同時(shí)在多種操作系統(tǒng)(如 Linux、Windows、Android、IOS、MacOS 等)和硬件架構(gòu)(如 x86、ARM)上運(yùn)行的系統(tǒng),確保所選工具能夠在所有相關(guān)平臺(tái)上正常工作,避免出現(xiàn)因平臺(tái)差異導(dǎo)致實(shí)驗(yàn)無(wú)法進(jìn)行的情況。
③易用性和學(xué)習(xí)成本
?用戶(hù)界面友好程度
?直觀(guān)、易于操作的用戶(hù)界面可以降低用戶(hù)的學(xué)習(xí)成本和操作難度。例如,Gremlin 有一個(gè)相對(duì)直觀(guān)的 Web 界面,用戶(hù)可以通過(guò)簡(jiǎn)單的操作(如選擇故障類(lèi)型、目標(biāo)系統(tǒng)等)來(lái)設(shè)置和啟動(dòng)實(shí)驗(yàn)。對(duì)于非技術(shù)人員或者剛接觸混沌工程的團(tuán)隊(duì)成員來(lái)說(shuō),這樣的界面更容易上手。
?文檔和社區(qū)支持
?完善的文檔和活躍的社區(qū)可以幫助用戶(hù)更快地學(xué)習(xí)和使用工具。工具的官方文檔應(yīng)該包括詳細(xì)的安裝指南、實(shí)驗(yàn)設(shè)置說(shuō)明、故障模擬類(lèi)型介紹等內(nèi)容。同時(shí),一個(gè)活躍的社區(qū)可以讓用戶(hù)分享經(jīng)驗(yàn)、解決問(wèn)題,例如在開(kāi)源的混沌工程工具社區(qū)中,用戶(hù)可以找到其他使用者分享的自定義實(shí)驗(yàn)場(chǎng)景案例,幫助自己更好地開(kāi)展實(shí)驗(yàn)。
④安全性和可靠性
?實(shí)驗(yàn)風(fēng)險(xiǎn)控制
?混沌工程工具在進(jìn)行故障注入時(shí)可能會(huì)對(duì)生產(chǎn)系統(tǒng)造成一定的風(fēng)險(xiǎn),因此需要選擇能夠有效控制實(shí)驗(yàn)風(fēng)險(xiǎn)的工具。一些工具提供了諸如 “安全模式” 或 “沙箱模式” 的功能,在這些模式下,故障注入的強(qiáng)度和范圍可以得到限制,并且可以提前設(shè)置好終止實(shí)驗(yàn)的條件,以確保在系統(tǒng)出現(xiàn)異常時(shí)能夠及時(shí)停止實(shí)驗(yàn),避免對(duì)生產(chǎn)系統(tǒng)造成嚴(yán)重破壞。
?工具自身的可靠性
?工具本身應(yīng)該是可靠的,不會(huì)因?yàn)樽陨淼墓收隙鴮?dǎo)致實(shí)驗(yàn)結(jié)果不準(zhǔn)確或者對(duì)系統(tǒng)造成額外的干擾。可以查看工具的版本更新記錄、用戶(hù)評(píng)價(jià)等信息來(lái)了解工具的可靠性情況。例如,經(jīng)過(guò)多個(gè)企業(yè)長(zhǎng)時(shí)間使用且更新頻繁的工具,通常在可靠性方面有更好的保障。
2)業(yè)界混沌工程解決方案
在混沌工程實(shí)踐里,通過(guò)模擬各類(lèi)故障場(chǎng)景,像是模擬服務(wù)器崩潰、制造網(wǎng)絡(luò)延遲,或是觸發(fā)數(shù)據(jù)丟失狀況等方式,能夠極為精準(zhǔn)地挖掘出系統(tǒng)中潛藏的薄弱環(huán)節(jié)。目前,市面上既有開(kāi)源性質(zhì)的解決方案,也不乏商業(yè)化的專(zhuān)業(yè)工具。接下來(lái),我們將著重對(duì)京東(JD)的混沌解決方案,以及其他具有代表性的開(kāi)源方案展開(kāi)詳細(xì)介紹。
①JD泰山混沌工程平臺(tái)(快快技術(shù)-首選解決方案平臺(tái))
?簡(jiǎn)介:是一款遵循混沌工程原理和混沌實(shí)驗(yàn)?zāi)P偷膶?shí)驗(yàn)注入工具,幫助用戶(hù)檢驗(yàn)系統(tǒng)高可用、提升分布式系統(tǒng)的容錯(cuò)能力,平臺(tái)使用簡(jiǎn)單、調(diào)度安全。是基于 ChaosBlade 底座進(jìn)行打造,并增加了JIMDB、JSF、JED等中間件類(lèi)故障場(chǎng)景,讓大家可以精細(xì)地控制演練影響范圍(爆炸半徑)。
?特點(diǎn):支持多種類(lèi)型的故障,如基礎(chǔ)資源故障:CPU、 內(nèi)存、網(wǎng)絡(luò)、磁盤(pán)、進(jìn)程;Java進(jìn)程故障:進(jìn)程內(nèi)CPU滿(mǎn)載、內(nèi)存溢出、類(lèi)方法延遲/拋異常/篡改返回值、MYSQL請(qǐng)求故障、JIMDB請(qǐng)求故障、JSF請(qǐng)求故障;JED集群故障:集群分片主從切換、集群分片節(jié)點(diǎn)重啟
?適用場(chǎng)景:適用于復(fù)雜分布式系統(tǒng)和微服務(wù)架構(gòu)中的故障模擬,另外針對(duì)JD特有的服務(wù)可支持故障植入。
②業(yè)界工具平臺(tái)及能力對(duì)標(biāo)
| 平臺(tái)/能力 | 特點(diǎn) | 適用場(chǎng)景 |
| 云原生計(jì)算基金會(huì)托管項(xiàng)目,專(zhuān)注于 Kubernetes 環(huán)境中進(jìn)行混沌工程實(shí)踐,可編排多種混沌實(shí)驗(yàn) | ·支持多種類(lèi)型的故障注入,如 Pod 故障、網(wǎng)絡(luò)故障、文件系統(tǒng)故障、時(shí)間故障、壓力故障等 ·提供了直觀(guān)的 Web 界面 ChaosDashboard,方便用戶(hù)管理、設(shè)計(jì)和監(jiān)控混沌實(shí)驗(yàn) | 適用于云原生架構(gòu)下的系統(tǒng),幫助開(kāi)發(fā)人員、運(yùn)維人員在 Kubernetes 環(huán)境中測(cè)試應(yīng)用程序和基礎(chǔ)設(shè)施的可靠性與穩(wěn)定性,如基礎(chǔ)資源故障,Java應(yīng)用故障等 |
| Kubernetes 原生的混沌工程開(kāi)源平臺(tái),以其強(qiáng)大的故障創(chuàng)建與編排能力著稱(chēng) | ·擁有故障注入實(shí)驗(yàn)市場(chǎng) ChaosHub,提供大量可定制的實(shí)驗(yàn)?zāi)0澹С侄喾N故障注入類(lèi)型,涵蓋通用、各大云平臺(tái)及 Spring Boot 等多種場(chǎng)景 ·可與 Prometheus 等可觀(guān)測(cè)性工具原生集成,方便監(jiān)控故障注入實(shí)驗(yàn)的影響 | 適用于不同技術(shù)背景的團(tuán)隊(duì),在 Kubernetes 環(huán)境中進(jìn)行混沌工程實(shí)踐,幫助識(shí)別系統(tǒng)中的弱點(diǎn)和潛在停機(jī)隱患。如可模擬存儲(chǔ)故障,CICD管道層面故障等 |
| 阿里巴巴開(kāi)源的混沌工程工具,可針對(duì)主機(jī)基礎(chǔ)資源、容器、Kubernetes 平臺(tái)、Java 應(yīng)用、C++ 應(yīng)用、阿里云平臺(tái)及其他服務(wù)等多達(dá) 7 個(gè)場(chǎng)景開(kāi)展故障注入實(shí)驗(yàn) | ·支持在多種環(huán)境中進(jìn)行故障注入,能夠模擬各種復(fù)雜的故障場(chǎng)景,如 CPU 滿(mǎn)載、內(nèi)存泄漏、網(wǎng)絡(luò)延遲等資源層面的故障,還能深入到應(yīng)用層對(duì)特定方法進(jìn)行故障注入 ·具有易用性和靈活性,通過(guò)簡(jiǎn)單的 CLI 命令行工具進(jìn)行故障注入 ·支持動(dòng)態(tài)加載和無(wú)侵入式的實(shí)驗(yàn)設(shè)計(jì) | 適用于復(fù)雜分布式系統(tǒng)和微服務(wù)架構(gòu)中的故障模擬,幫助團(tuán)隊(duì)提前發(fā)現(xiàn)系統(tǒng)中的薄弱環(huán)節(jié)。能夠模擬一些中間件的故障,如云原生故障等 |
| 輕量級(jí)、靈活且易于集成的混沌工程工具,允許用戶(hù)以聲明式的方式定義各種故障注入場(chǎng)景 | ·支持使用 YAML 文件定義混沌實(shí)驗(yàn),內(nèi)置多種故障模型,如 Pod Kill、Network Latency、Disk IO Stress 等 ·深度集成 Kubernetes,提供友好的 Web 界面和 RESTful API,方便操作與集成 | 適用于開(kāi)發(fā)者和運(yùn)維人員在 Kubernetes 環(huán)境中進(jìn)行混沌工程實(shí)驗(yàn),可作為新功能上線(xiàn)前的測(cè)試、持續(xù)集成 / 持續(xù)交付流程的一部分,以及故障恢復(fù)訓(xùn)練等 |
| 功能全面的混沌工程工具,提供了直觀(guān)的 Web 界面,可模擬多種故障場(chǎng)景,包括服務(wù)器故障、網(wǎng)絡(luò)延遲、丟包、數(shù)據(jù)庫(kù)故障、容器故障等 | ·具備強(qiáng)大的故障模擬能力和靈活的實(shí)驗(yàn)配置選項(xiàng),可與多種監(jiān)控和日志工具集成,方便用戶(hù)在實(shí)驗(yàn)過(guò)程中觀(guān)察系統(tǒng)的狀態(tài)變化 ·提供了 “安全模式” 或 “沙箱模式” 等風(fēng)險(xiǎn)控制功能,確保實(shí)驗(yàn)的安全性 | 適用于各種規(guī)模和架構(gòu)的分布式系統(tǒng),幫助企業(yè)提升系統(tǒng)的彈性和穩(wěn)定性,尤其適合對(duì)安全性和風(fēng)險(xiǎn)控制要求較高的生產(chǎn)環(huán)境 |
| 亞馬遜推出的混沌工程工具,專(zhuān)門(mén)用于在 AWS 云平臺(tái)上進(jìn)行故障注入實(shí)驗(yàn) | ·可模擬 AWS 云服務(wù)的各種故障情況,如 EC2 實(shí)例故障、S3 存儲(chǔ)桶故障、RDS 數(shù)據(jù)庫(kù)故障等 ·與 AWS 的其他服務(wù)和工具集成緊密,方便用戶(hù)在云環(huán)境中進(jìn)行全面的系統(tǒng)測(cè)試 | 適用于使用 AWS 云平臺(tái)的企業(yè)和開(kāi)發(fā)者,幫助他們?cè)谠骗h(huán)境中評(píng)估系統(tǒng)的可靠性和彈性,確保應(yīng)用程序能夠在 AWS 云服務(wù)出現(xiàn)故障時(shí)正常運(yùn)行 |
?
f、執(zhí)行實(shí)驗(yàn)
1)系統(tǒng)架構(gòu)分析
①架構(gòu)分析的必要性
系統(tǒng)級(jí)架構(gòu)分析,是所有穩(wěn)定性保障工作開(kāi)展的首要條件。通過(guò)對(duì)系統(tǒng)機(jī)構(gòu)的充分理解和分析,才能準(zhǔn)確識(shí)別故障演練的切入點(diǎn)(可能的弱點(diǎn)),以下,是系統(tǒng)架構(gòu)分析的必要環(huán)節(jié)和目的。
②識(shí)別關(guān)鍵組件和依賴(lài)關(guān)系
系統(tǒng)架構(gòu)分析幫助識(shí)別系統(tǒng)中關(guān)鍵的組件和服務(wù),以及它們之間的依賴(lài)關(guān)系。這有助于確定哪些部分對(duì)系統(tǒng)的整體功能至關(guān)重要,并需要優(yōu)先進(jìn)行故障演練。
③理解數(shù)據(jù)流和通信路徑
分析架構(gòu)可以揭示數(shù)據(jù)在系統(tǒng)內(nèi)的流動(dòng)路徑和通信模式。這有助于設(shè)計(jì)針對(duì)網(wǎng)絡(luò)延遲、帶寬限制或通信中斷的故障演練。
④識(shí)別單點(diǎn)故障
系統(tǒng)架構(gòu)分析可以幫助識(shí)別系統(tǒng)中的單點(diǎn)故障,這些是可能導(dǎo)致整個(gè)系統(tǒng)崩潰的薄弱環(huán)節(jié)。通過(guò)故障演練,可以測(cè)試這些點(diǎn)的冗余性和故障恢復(fù)能力。
⑤優(yōu)化故障演練設(shè)計(jì)
了解系統(tǒng)架構(gòu)可以幫助設(shè)計(jì)更加真實(shí)和有針對(duì)性的故障場(chǎng)景,從而提高故障演練的有效性和相關(guān)性。
⑥評(píng)估故障影響范圍
系統(tǒng)架構(gòu)分析可以幫助預(yù)測(cè)故障可能影響的范圍和程度,從而為故障演練設(shè)定合理的范圍和目標(biāo)。
⑦加強(qiáng)團(tuán)隊(duì)的協(xié)作與溝通
通過(guò)架構(gòu)分析,團(tuán)隊(duì)成員可以更好地理解系統(tǒng)的整體設(shè)計(jì)和各自的角色。這有助于在故障演練中提高團(tuán)隊(duì)的響應(yīng)能力和協(xié)作效率。
⑧支持持續(xù)改進(jìn):
架構(gòu)分析提供了一個(gè)基準(zhǔn),用于在故障演練后評(píng)估系統(tǒng)的改進(jìn)效果。通過(guò)反復(fù)的分析和演練,可以不斷優(yōu)化系統(tǒng)架構(gòu),提高系統(tǒng)的彈性。
?
總之,系統(tǒng)架構(gòu)分析是故障演練的基礎(chǔ),它確保演練的設(shè)計(jì)和實(shí)施是有針對(duì)性的,并能有效地提高系統(tǒng)的可靠性和穩(wěn)定性。
?
2)架構(gòu)分析案例
①架構(gòu)分析要求
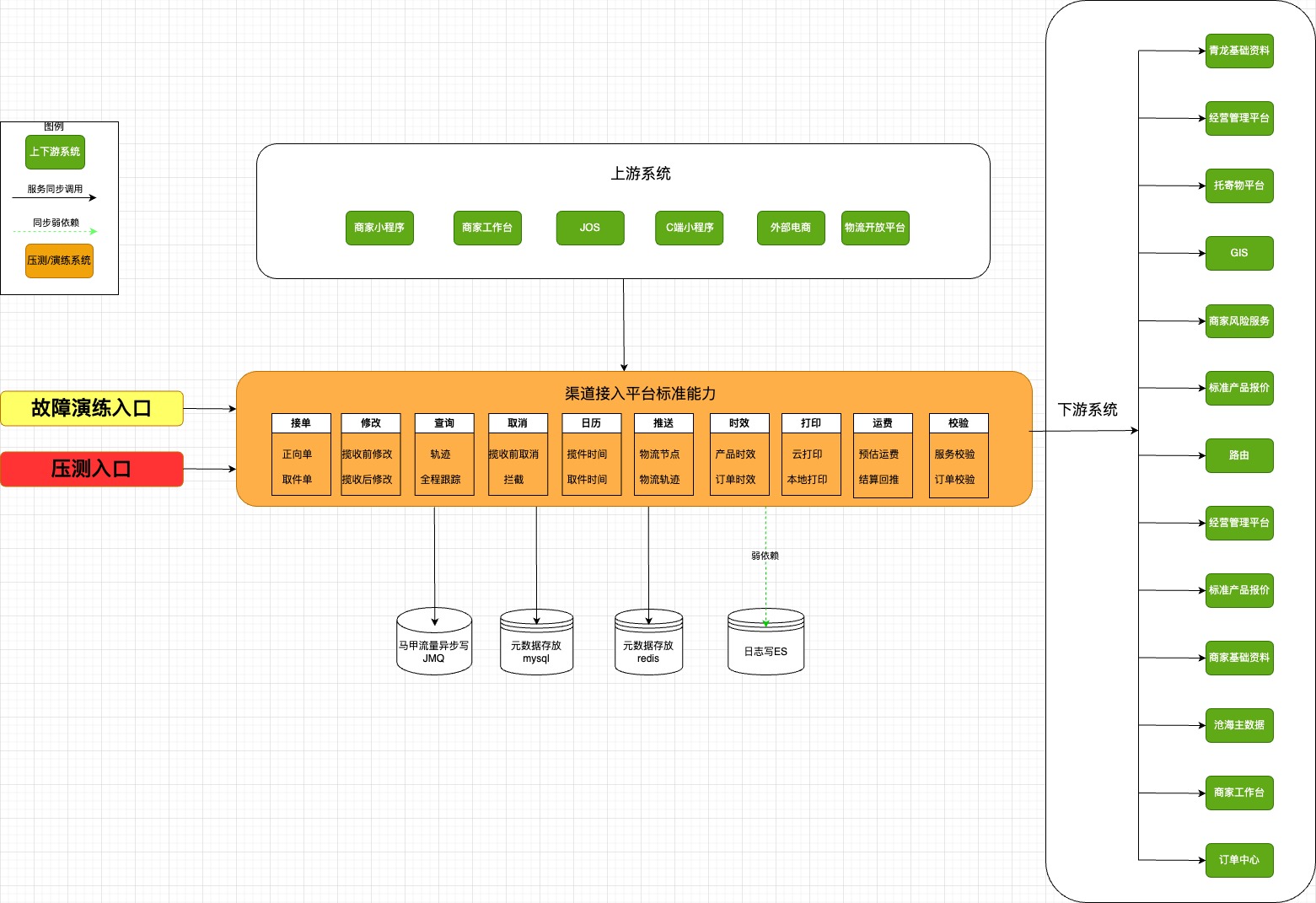
?梳理系統(tǒng)全局架構(gòu)圖,標(biāo)注演練(壓測(cè)同理)入口。
?梳理演練(壓測(cè)同理)接口調(diào)用架構(gòu)圖,標(biāo)識(shí)調(diào)用鏈路強(qiáng)弱依賴(lài)、調(diào)用層級(jí)關(guān)系以及演練(壓測(cè)同理)切入點(diǎn)。
?沉淀調(diào)用鏈路信息文檔。
(圖例)系統(tǒng)總架構(gòu)圖
(圖例)單接口調(diào)用架構(gòu)圖
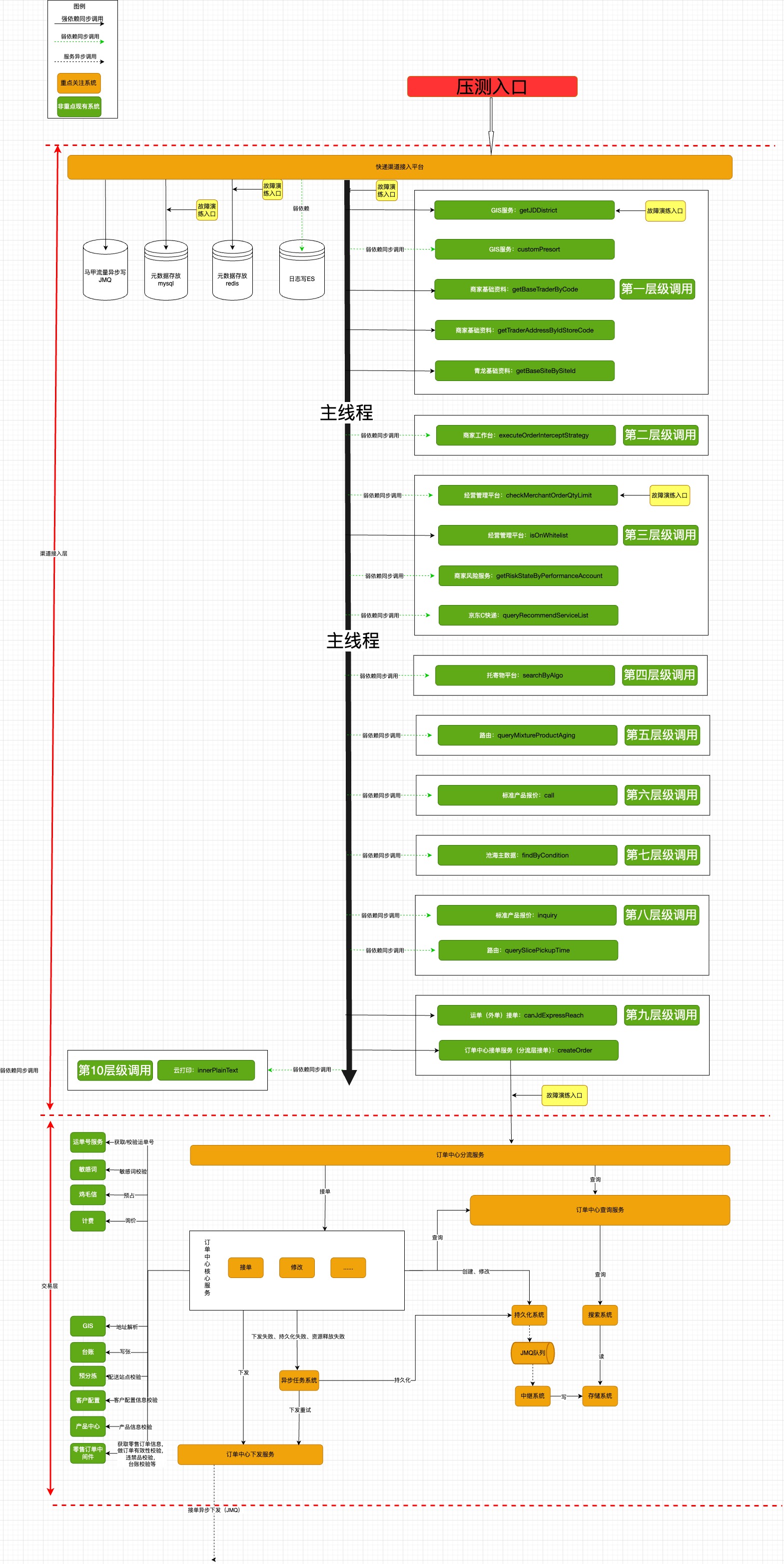
②調(diào)用鏈?zhǔn)崂砦臋n(樣例):快快接口梳理(常態(tài)化演練)?
3)實(shí)驗(yàn)方案
在生產(chǎn)環(huán)境或測(cè)試環(huán)境中執(zhí)行實(shí)驗(yàn),觀(guān)察系統(tǒng)在各種故障情況下的行為。在執(zhí)行實(shí)驗(yàn)過(guò)程中,應(yīng)嚴(yán)格遵照劇本要求明確分工及實(shí)驗(yàn)步驟,密切關(guān)注系統(tǒng)的穩(wěn)定狀態(tài)指標(biāo),確保實(shí)驗(yàn)不會(huì)對(duì)用戶(hù)造成不良影響。故障演練劇本?
①方案樣例
實(shí)驗(yàn)方案實(shí)施過(guò)程中,應(yīng)嚴(yán)格按照分工和劇本執(zhí)行,第一時(shí)間留存關(guān)鍵證據(jù),記錄關(guān)鍵步驟結(jié)論。
| 演練過(guò)程記錄 | |||
| 環(huán)節(jié) | 時(shí)間線(xiàn) | 舉證 | |
| 故障開(kāi)始注入時(shí)間 (攻方填寫(xiě)) | 2024-12-26 17:54:55 |
 |
|
| 故障停止注入時(shí)間(攻方填寫(xiě)) | 2024-12-26 18:16:15 |
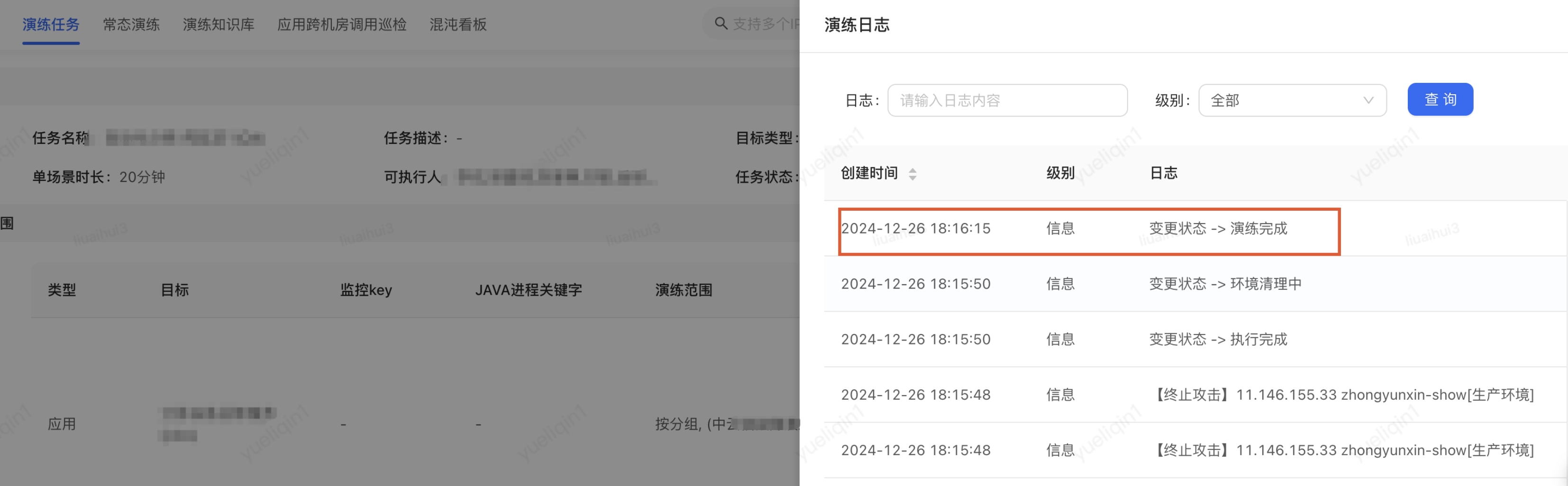 |
|
| 告警觸發(fā)及識(shí)別時(shí)間(守方填寫(xiě)) | 2024-12-26 17:58:00 |
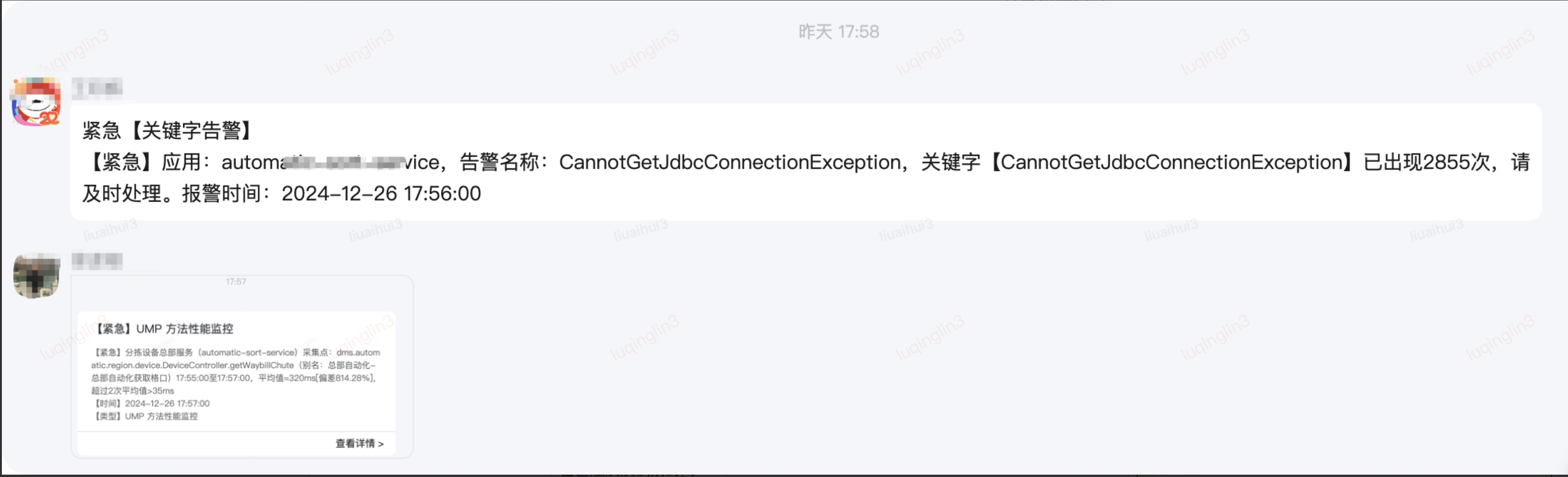 |
|
| 定位時(shí)間(守方填寫(xiě)) | 2024-12-26 18:05:00 |
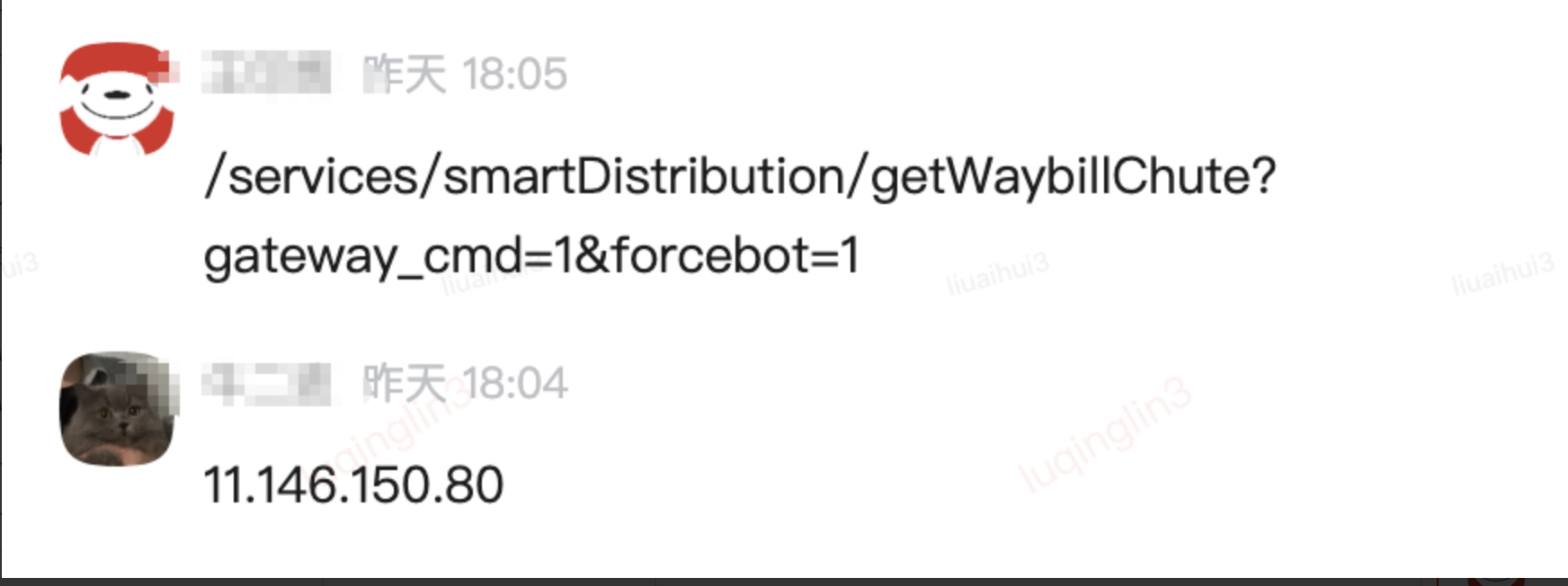 |
|
| 止損時(shí)間(守方填寫(xiě)) | 2024-12-26 18:09:00 |
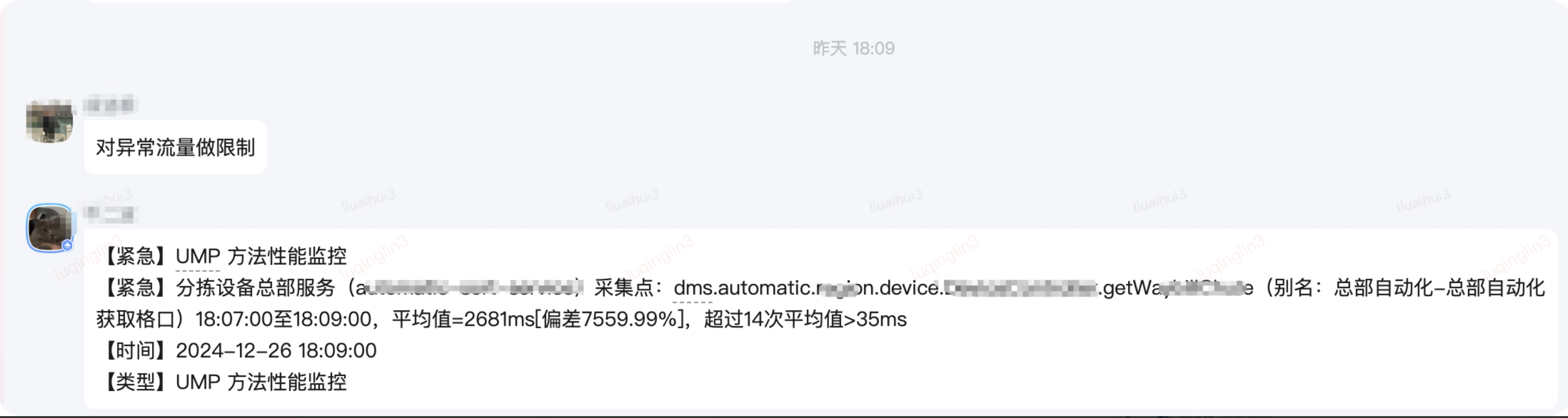 |
|
| 故障恢復(fù)時(shí)間(守方填寫(xiě)) | 2024-12-26 18:10:00 |
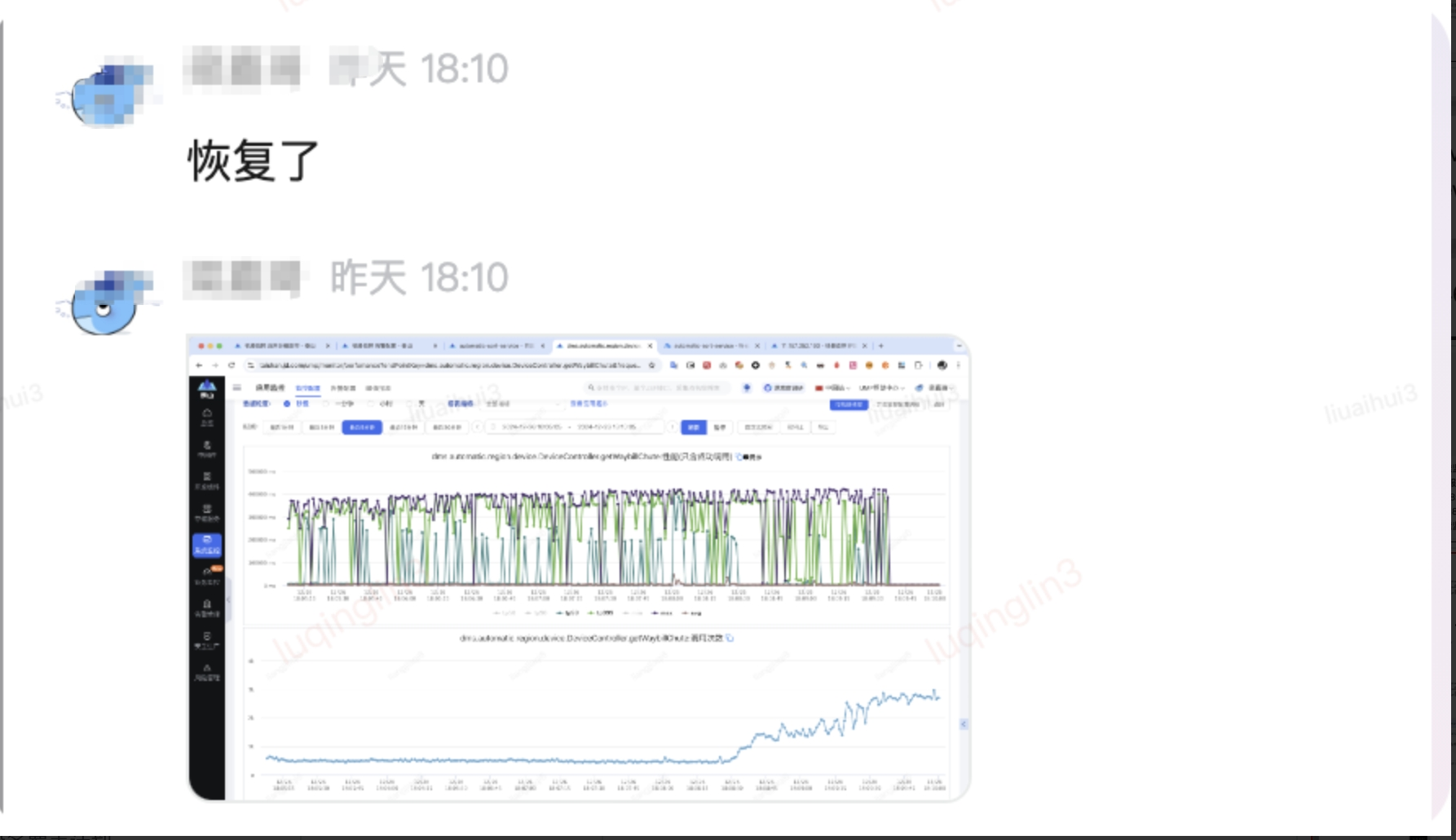 |
|
| MTTR(攻方填寫(xiě)) | 22min | ||
?
g、結(jié)果分析
?對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行分析,找出系統(tǒng)中的潛在問(wèn)題和薄弱環(huán)節(jié)。分析實(shí)驗(yàn)結(jié)果可以使用數(shù)據(jù)分析工具、監(jiān)控工具或日志分析工具等。針對(duì)實(shí)驗(yàn)結(jié)果總結(jié)經(jīng)驗(yàn)并后續(xù)做針對(duì)性改進(jìn)。
?樣例:如針對(duì)某一個(gè)應(yīng)用,演練完成之后,會(huì)從以下維度評(píng)估,并總結(jié)經(jīng)驗(yàn)。
?應(yīng)用:workbench-xxxxx-backend-xxxxx
?故障場(chǎng)景:強(qiáng)依賴(lài)JSF超時(shí)不可用+弱依賴(lài)JSF超時(shí)不可用
?故障時(shí)間:2025-01-02 21:14:38 ~ 2025-01-02 21:35:00
?問(wèn)題現(xiàn)象
?下游強(qiáng)依賴(lài)接口(計(jì)費(fèi)系統(tǒng))持續(xù)響應(yīng)3S,TP99飚高,可用率未下降,仍100%
?從植入故障到引起監(jiān)控報(bào)警,間隔13min,該接口性能告警配置建議調(diào)整時(shí)間(現(xiàn)狀:5次/分鐘超過(guò)配置的閾值則報(bào)警,并在10分鐘內(nèi)不重復(fù)報(bào)警)
?問(wèn)題原因
?針對(duì)強(qiáng)依賴(lài)接口,下游超時(shí)未上報(bào)可用率下降
?告警時(shí)間配置10min,告警配置不敏感
?改進(jìn)措施
?針對(duì)強(qiáng)依賴(lài)接口,下游超時(shí)上報(bào)可用率下降
?更改UMP告警配置,更改為5min告警1次
?
h、問(wèn)題修復(fù)及重復(fù)實(shí)驗(yàn)
?根據(jù)實(shí)驗(yàn)結(jié)果,修復(fù)系統(tǒng)中的潛在問(wèn)題和薄弱環(huán)節(jié)。之后重復(fù)進(jìn)行實(shí)驗(yàn),以驗(yàn)證修復(fù)效果并進(jìn)一步提高系統(tǒng)的彈性和穩(wěn)定性。
?目前快快技術(shù)團(tuán)隊(duì),在演練過(guò)程中,關(guān)鍵問(wèn)題修復(fù)之后,會(huì)針對(duì)性進(jìn)行二次驗(yàn)證。
?
i、成熟度評(píng)估
1)什么是混沌工程成熟度模型
混沌工程成熟度模型是一種框架,用于評(píng)估和指導(dǎo)組織在實(shí)施混沌工程實(shí)踐中的發(fā)展階段和成熟度。這個(gè)模型幫助組織理解它們?cè)诨煦绻こ虒?shí)踐中的位置,并為進(jìn)一步改進(jìn)提供路線(xiàn)圖。
通常,混沌工程成熟度模型會(huì)分為幾個(gè)階段,每個(gè)階段代表不同的能力和實(shí)踐水平,通常包括初始階段、基礎(chǔ)階段(初級(jí))、標(biāo)準(zhǔn)化階段(發(fā)展中)、優(yōu)化階段(成熟)、創(chuàng)新階段(卓越)。
混沌工程成熟度模型的演變可以幫助組織系統(tǒng)化地實(shí)施混沌實(shí)驗(yàn),并逐步提高其混沌工程實(shí)踐的成熟度。通過(guò)系統(tǒng)化的成熟度評(píng)估,組織可以更有效地實(shí)施混沌工程實(shí)踐,提升其整體系統(tǒng)的穩(wěn)健性和響應(yīng)能力。
混沌工程成熟度模型的演變反映了組織在復(fù)雜系統(tǒng)環(huán)境中不斷追求更高彈性和可靠性的努力,結(jié)合業(yè)內(nèi)對(duì)成熟度模型理解和京東實(shí)際情況,對(duì)成熟度框架進(jìn)行剪裁(去掉接納度維度和初始階段),剪裁后的成熟度框架如下。
| 成熟度等級(jí) | 1級(jí)(初級(jí)) | 2級(jí)(發(fā)展中) | 3級(jí)(成熟) | 4級(jí)(卓越) |
| 架構(gòu)抵御故障的能力(系統(tǒng)維度) | 一定冗余 統(tǒng)中存在備份或多個(gè)實(shí)例,以防單點(diǎn)故障。在硬件層面,可以有多個(gè)服務(wù)器或數(shù)據(jù)中心;在軟件層面,可以有多個(gè)服務(wù)實(shí)例或數(shù)據(jù)庫(kù)副本。(多機(jī)房無(wú)單點(diǎn)) | 冗余且可擴(kuò)展 除了具備一定的冗余之外,系統(tǒng)還應(yīng)該能夠根據(jù)需求進(jìn)行水平或垂直擴(kuò)展。水平擴(kuò)展是指增加更多的服務(wù)器或?qū)嵗怪睌U(kuò)展是指升級(jí)現(xiàn)有服務(wù)器的硬件配置。可擴(kuò)展性允許系統(tǒng)在面臨高負(fù)載或增長(zhǎng)時(shí)繼續(xù)提供服務(wù)。 | 已使用可避免級(jí)聯(lián)故障技術(shù) 級(jí)聯(lián)故障是指一個(gè)故障導(dǎo)致一系列其他故障的連鎖反應(yīng)。為了避免這種情況,可以使用技術(shù)如熔斷(Circuit Breaker)、隔離(Bulkhead)和限流(Rate Limiting)。(垂直部署) | 已實(shí)現(xiàn)韌性架構(gòu) 韌性架構(gòu)是指系統(tǒng)在面臨異常情況(如高負(fù)載、網(wǎng)絡(luò)中斷或硬件故障)時(shí)仍能保持一定的功能和性能。實(shí)現(xiàn)韌性架構(gòu)通常需要設(shè)計(jì)和實(shí)施多種策略,包括上述的冗余、可擴(kuò)展性和避免級(jí)聯(lián)故障技術(shù),以及其他技術(shù)如自動(dòng)恢復(fù)(自動(dòng)重啟、自動(dòng)回滾等)、自適應(yīng)負(fù)載平衡和實(shí)時(shí)監(jiān)控等。 |
| 指標(biāo)監(jiān)控能力(系統(tǒng)維度) | 實(shí)驗(yàn)結(jié)果只反映系統(tǒng)狀態(tài)指標(biāo) 實(shí)驗(yàn)結(jié)果主要關(guān)注系統(tǒng)的基礎(chǔ)健康狀態(tài)指標(biāo),例如CPU使用率、內(nèi)存使用率、磁盤(pán)空間等。這些指標(biāo)可以幫助你了解系統(tǒng)在故障情況下的表現(xiàn)(具備MDC監(jiān)控) | 實(shí)驗(yàn)結(jié)果反應(yīng)健康狀態(tài)指標(biāo) 除了基礎(chǔ)系統(tǒng)狀態(tài)指標(biāo)外,實(shí)驗(yàn)結(jié)果還會(huì)考慮更高級(jí)別的健康狀態(tài)指標(biāo),例如服務(wù)可用性、響應(yīng)時(shí)間、錯(cuò)誤率等。這些指標(biāo)可以提供關(guān)于系統(tǒng)整體健康狀況的更深入的見(jiàn)解。(具備UMP和Pfinder監(jiān)控,應(yīng)用健康度評(píng)分90分以上) | 實(shí)驗(yàn)結(jié)果反應(yīng)聚合的業(yè)務(wù)指標(biāo) 實(shí)驗(yàn)結(jié)果會(huì)聚焦于與業(yè)務(wù)相關(guān)的指標(biāo),例如訂單處理速度、用戶(hù)會(huì)話(huà)數(shù)、轉(zhuǎn)化率等。這些指標(biāo)可以幫助你了解故障對(duì)業(yè)務(wù)流程和用戶(hù)體驗(yàn)的影響。(具備業(yè)務(wù)監(jiān)控能力) | 有對(duì)照組比較業(yè)務(wù)指標(biāo)差異 除了上述指標(biāo)外,還會(huì)設(shè)置一個(gè)對(duì)照組(即沒(méi)有故障的基線(xiàn)組)來(lái)與實(shí)驗(yàn)組進(jìn)行比較。通過(guò)比較兩組的業(yè)務(wù)指標(biāo)差異,可以更準(zhǔn)確地評(píng)估故障對(duì)業(yè)務(wù)的實(shí)際影響。 |
| 實(shí)驗(yàn)環(huán)境選擇(系統(tǒng)維度) | 可在預(yù)生產(chǎn)環(huán)境運(yùn)行試驗(yàn) 在接近生產(chǎn)環(huán)境的設(shè)置中進(jìn)行試驗(yàn),預(yù)生產(chǎn)環(huán)境通常與生產(chǎn)環(huán)境具有相似的配置和數(shù)據(jù),可以幫助你在不影響實(shí)際用戶(hù)的情況下評(píng)估系統(tǒng)的彈性。 | 復(fù)制生產(chǎn)流量在灰度環(huán)境運(yùn)行 在一個(gè)專(zhuān)門(mén)設(shè)計(jì)的灰度環(huán)境中模擬生產(chǎn)環(huán)境的流量和負(fù)載。通過(guò)這種方式,你可以在真實(shí)的生產(chǎn)條件下測(cè)試系統(tǒng)的彈性,而不直接影響到實(shí)際用戶(hù)。 | 在生產(chǎn)環(huán)境中運(yùn)行實(shí)驗(yàn) 需要非常小心和謹(jǐn)慎,只有當(dāng)你有足夠的信心和準(zhǔn)備工作時(shí),才應(yīng)該考慮在生產(chǎn)環(huán)境中進(jìn)行混沌工程實(shí)驗(yàn)。這種方法可以提供最真實(shí)的結(jié)果,但也存在最大的風(fēng)險(xiǎn)。 | 包含生產(chǎn)在內(nèi)的任意環(huán)境都可進(jìn)行實(shí)驗(yàn) 這種說(shuō)法并不完全正確。雖然理論上可以在任何環(huán)境中進(jìn)行混沌工程實(shí)驗(yàn),但在實(shí)踐中,需要根據(jù)具體的系統(tǒng)和業(yè)務(wù)需求來(lái)選擇合適的環(huán)境。例如,對(duì)于關(guān)鍵系統(tǒng)或高風(fēng)險(xiǎn)應(yīng)用,可能不適合直接在生產(chǎn)環(huán)境中進(jìn)行實(shí)驗(yàn)。 |
| 故障注入場(chǎng)景和爆炸半徑范圍(系統(tǒng)維度) | 進(jìn)行一些基礎(chǔ)的演練場(chǎng)景注入 選擇注入一些基本的故障場(chǎng)景,例如突然終止一個(gè)進(jìn)程、關(guān)閉一個(gè)服務(wù)或者模擬機(jī)器崩潰等。這些場(chǎng)景可以幫助你了解系統(tǒng)在面對(duì)單一故障時(shí)的反應(yīng)。 | 注入較高級(jí)的故障場(chǎng)景 注入更復(fù)雜的故障場(chǎng)景,例如網(wǎng)絡(luò)延遲、數(shù)據(jù)庫(kù)延遲或者是第三方服務(wù)不可用等。這些場(chǎng)景可以模擬更真實(shí)的生產(chǎn)環(huán)境中的問(wèn)題。 | 引入服務(wù)級(jí)別的影響和組合式演練場(chǎng)景 注入涉及多個(gè)服務(wù)的復(fù)雜故障場(chǎng)景,例如同時(shí)模擬多個(gè)微服務(wù)的故障、網(wǎng)絡(luò)分區(qū)或者是負(fù)載均衡器失效等。這些場(chǎng)景可以幫助你了解系統(tǒng)在面對(duì)多個(gè)故障同時(shí)發(fā)生時(shí)的行為。 | 基于業(yè)務(wù)注入故障 注入更高級(jí)別的故障,例如模擬用戶(hù)的不同使用模式、返回結(jié)果的變化或者是異常結(jié)果的出現(xiàn)等。這些場(chǎng)景可以幫助你理解系統(tǒng)在面對(duì)非標(biāo)準(zhǔn)輸入或輸出時(shí)的彈性。 |
| 試驗(yàn)自動(dòng)化(基礎(chǔ)設(shè)施維度) | 利用工具進(jìn)行半自動(dòng)化試驗(yàn) 使用工具來(lái)輔助試驗(yàn)的某些步驟,但仍需要人工干預(yù)。例如,使用腳本來(lái)模擬故障或生成負(fù)載,而人工負(fù)責(zé)啟動(dòng)和監(jiān)控試驗(yàn)。 | 自動(dòng)創(chuàng)建、運(yùn)行實(shí)驗(yàn),但需要手動(dòng)監(jiān)控和停止 試驗(yàn)的創(chuàng)建和運(yùn)行可以被自動(dòng)化,例如使用CI/CD流程來(lái)部署和執(zhí)行試驗(yàn)。然而,仍然需要人工監(jiān)控試驗(yàn)的進(jìn)展和結(jié)果,并在必要時(shí)手動(dòng)停止試驗(yàn)。 | 自動(dòng)結(jié)果分析,自動(dòng)終止試驗(yàn) 系統(tǒng)可以自動(dòng)檢測(cè)到試驗(yàn)的結(jié)果,并根據(jù)預(yù)設(shè)的規(guī)則自動(dòng)終止試驗(yàn)。例如,如果系統(tǒng)的性能下降超過(guò)某個(gè)閾值,試驗(yàn)將被自動(dòng)停止。 | 自動(dòng)設(shè)計(jì)、實(shí)現(xiàn)、執(zhí)行、終止實(shí)驗(yàn) 整個(gè)混沌工程流程都被自動(dòng)化。系統(tǒng)可以自主設(shè)計(jì)試驗(yàn)、選擇適當(dāng)?shù)沫h(huán)境、執(zhí)行試驗(yàn)、分析結(jié)果,并根據(jù)結(jié)果自動(dòng)調(diào)整或終止試驗(yàn)。這種級(jí)別的自動(dòng)化需要高度復(fù)雜的系統(tǒng)和算法支持。 |
| 工具使用(基礎(chǔ)設(shè)施維度) | 采用試驗(yàn)工具 選擇一款專(zhuān)門(mén)設(shè)計(jì)用于混沌工程的試驗(yàn)工具,例如Chaos Monkey、Gremlin、Pumba等。這些工具可以幫助你模擬各種故障和壓力測(cè)試,評(píng)估系統(tǒng)的彈性。(泰山—風(fēng)險(xiǎn)管理—混沌工程) | 使用試驗(yàn)框架 選擇使用一個(gè)更全面的試驗(yàn)框架,例如Chaos Toolkit或Litmus。這些框架提供了更豐富的功能,包括試驗(yàn)設(shè)計(jì)、執(zhí)行、監(jiān)控和結(jié)果分析等。(泰山—風(fēng)險(xiǎn)管理—混沌工程) | 實(shí)驗(yàn)框架和持續(xù)發(fā)布工具集成 將混沌工程工具與持續(xù)發(fā)布(CI/CD)工具集成,例如Jenkins、GitLab CI/CD或CircleCI。這樣可以實(shí)現(xiàn)自動(dòng)化的混沌工程流程,例如在每次代碼部署后自動(dòng)運(yùn)行一系列混沌工程試驗(yàn)。 | 工具支持交互式的比對(duì)實(shí)驗(yàn) 工具不僅可以執(zhí)行混沌工程試驗(yàn),還可以提供交互式的比對(duì)實(shí)驗(yàn)功能。例如,你可以使用工具來(lái)比較兩種不同的系統(tǒng)配置或版本在面對(duì)相同的故障情況下的表現(xiàn)差異。這種功能可以幫助你更深入地理解系統(tǒng)的彈性和性能。 |
| 環(huán)境恢復(fù)能力(基礎(chǔ)設(shè)施維度) | 可手動(dòng)恢復(fù)環(huán)境 需要手動(dòng)介入來(lái)恢復(fù)環(huán)境。這可能涉及到重新啟動(dòng)服務(wù)、清理日志文件、調(diào)整配置等步驟。雖然這種方法可以解決問(wèn)題,但它通常需要更多的時(shí)間和人力資源。 | 可半自動(dòng)恢復(fù)環(huán)境 系統(tǒng)具備一些自動(dòng)化的恢復(fù)功能,例如自動(dòng)重啟服務(wù)或者自動(dòng)清理日志文件。然而,仍然需要系統(tǒng)管理員的介入來(lái)執(zhí)行其他恢復(fù)步驟(比如手動(dòng)恢復(fù)數(shù)據(jù)、手動(dòng)回滾代碼等)。這種方法可以加快恢復(fù)過(guò)程,但仍然依賴(lài)于人工干預(yù) | 部分可自動(dòng)化恢復(fù)環(huán)境 系統(tǒng)的恢復(fù)過(guò)程可以被大部分自動(dòng)化。例如,系統(tǒng)可以自動(dòng)檢測(cè)故障并嘗試恢復(fù),或者在出現(xiàn)問(wèn)題時(shí)自動(dòng)切換到備用系統(tǒng)。雖然仍然可能需要人工干預(yù)來(lái)解決某些問(wèn)題(比如未知類(lèi)型故障、數(shù)據(jù)一致性問(wèn)題、安全問(wèn)題等),但自動(dòng)化程度已經(jīng)大大提高。 | 韌性架構(gòu)自動(dòng)恢復(fù) 系統(tǒng)可以自動(dòng)檢測(cè)和響應(yīng)任何類(lèi)型的故障,包括那些在設(shè)計(jì)時(shí)未被預(yù)見(jiàn)的故障。這種能力通常需要一個(gè)高度彈性和自適應(yīng)的架構(gòu),例如微服務(wù)架構(gòu)、容器化環(huán)境或者云原生應(yīng)用。系統(tǒng)可以自動(dòng)擴(kuò)展、縮小、重啟服務(wù)或者重新路由流量,以確保服務(wù)的連續(xù)性。 |
| 實(shí)驗(yàn)結(jié)果整理(基礎(chǔ)設(shè)施維度) | 可以通過(guò)實(shí)驗(yàn)工具得到實(shí)驗(yàn)結(jié)果,需要人工整理、分析和解讀 實(shí)驗(yàn)工具會(huì)生成大量的數(shù)據(jù),包括系統(tǒng)指標(biāo)、錯(cuò)誤日志、用戶(hù)行為等。這些數(shù)據(jù)需要人工進(jìn)行整理、分析和解讀,以便從中提取有用的信息和洞察。 | 可以通過(guò)實(shí)驗(yàn)工具持續(xù)收集實(shí)驗(yàn)結(jié)果,但需人工分析和解讀 實(shí)驗(yàn)工具不僅可以在實(shí)驗(yàn)期間收集數(shù)據(jù),還可以在日常運(yùn)營(yíng)中持續(xù)監(jiān)控系統(tǒng)的狀態(tài)。這樣可以幫助團(tuán)隊(duì)更早地發(fā)現(xiàn)問(wèn)題并進(jìn)行修復(fù)。然而,仍然需要人工分析和解讀這些數(shù)據(jù),以便理解系統(tǒng)的行為和性能。 | 可以通過(guò)實(shí)驗(yàn)持續(xù)收集實(shí)驗(yàn)結(jié)果和報(bào)告,并完成簡(jiǎn)單的故障分析 實(shí)驗(yàn)結(jié)果處理已經(jīng)具備了一定的自動(dòng)化能力。實(shí)驗(yàn)工具可以自動(dòng)收集數(shù)據(jù)、生成報(bào)告,并進(jìn)行初步的故障分析。這樣可以大大減輕人工的工作量。但是,對(duì)于復(fù)雜的故障或深入的分析,仍然需要人工的介入。 | 實(shí)驗(yàn)結(jié)果可預(yù)測(cè)收入損失、并完成容量規(guī)劃、區(qū)分出不容服務(wù)實(shí)際的關(guān)鍵程度 通過(guò)對(duì)實(shí)驗(yàn)結(jié)果的深入分析和建模,可以預(yù)測(cè)系統(tǒng)故障可能帶來(lái)的收入損失,并據(jù)此進(jìn)行容量規(guī)劃和資源優(yōu)化。同時(shí),可以通過(guò)實(shí)驗(yàn)結(jié)果來(lái)區(qū)分哪些服務(wù)或功能是關(guān)鍵的,哪些是非關(guān)鍵的,從而有針對(duì)性地進(jìn)行改進(jìn)和優(yōu)化。 |
2)成熟度評(píng)估案例
基于成熟度模型的關(guān)鍵維度,我們對(duì)多個(gè)研發(fā)團(tuán)隊(duì),進(jìn)行了實(shí)際的落地評(píng)估工作,具體某個(gè)團(tuán)隊(duì)的評(píng)估過(guò)程,詳見(jiàn)下表。
| 成熟度等級(jí) | 最終評(píng)級(jí) | 舉證 | 待提升項(xiàng)(距離下一等級(jí)) |
| 架構(gòu)抵御故障的能力 | 二級(jí) |
擴(kuò)容,有水平擴(kuò)展的能力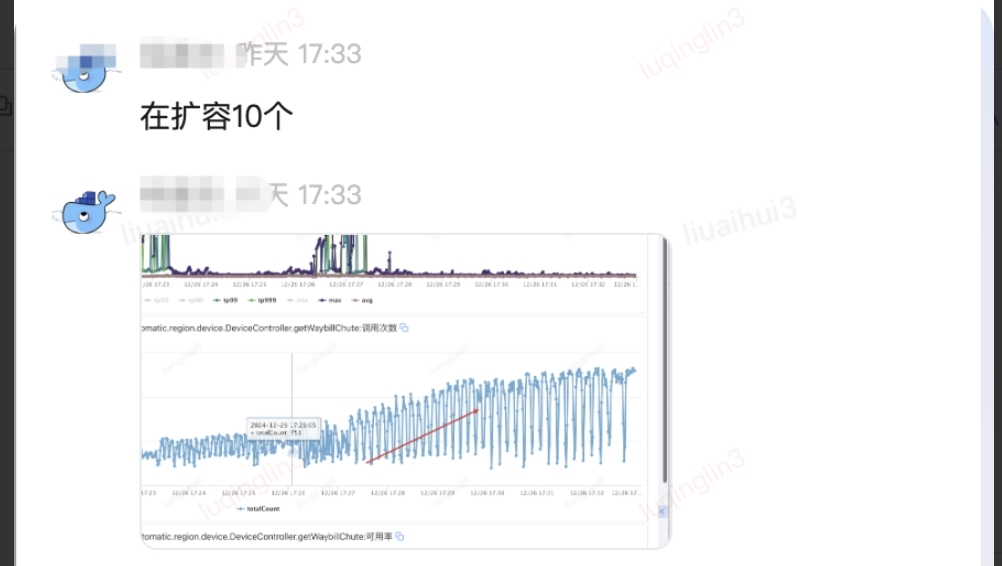 |
具備技術(shù)熔斷能力 |
| 指標(biāo)監(jiān)控能力 | 三級(jí) |
除了ump等基本監(jiān)控之外,具備業(yè)務(wù)監(jiān)控的能力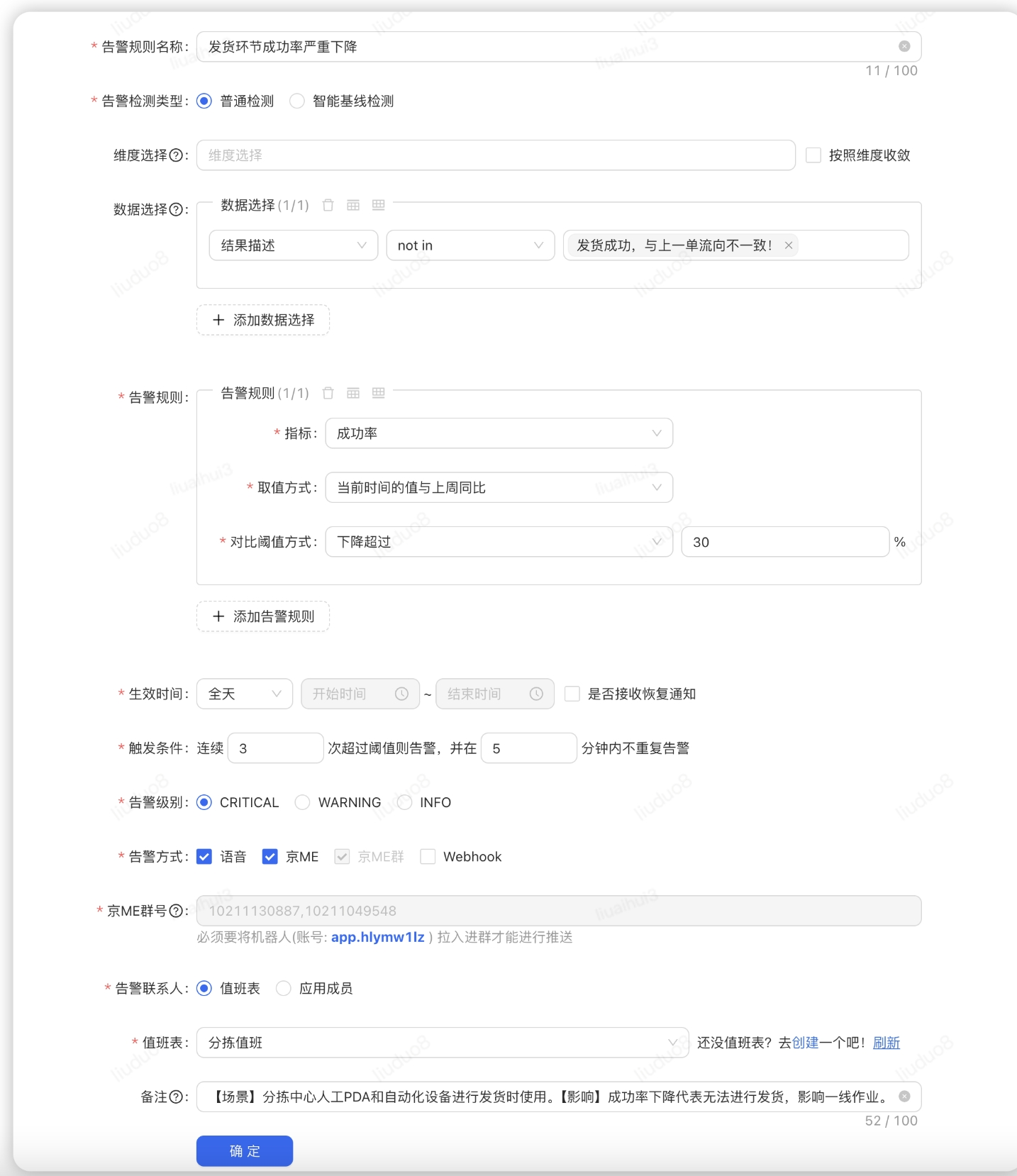 |
設(shè)置對(duì)照組,針對(duì)演練的分組和實(shí)際分組做業(yè)務(wù)監(jiān)控對(duì)比,找出差異 |
| 實(shí)驗(yàn)環(huán)境選擇 | 二級(jí) |
生產(chǎn)環(huán)境無(wú)生產(chǎn)流量演練 |
可在生產(chǎn)環(huán)境帶生產(chǎn)流量進(jìn)行演練 |
| 故障注入場(chǎng)景和爆炸半徑范圍 | 三級(jí) |
多個(gè)場(chǎng)景混合注入故障 |
基于業(yè)務(wù)場(chǎng)景構(gòu)造故障,在通用故障的基礎(chǔ)上,加入業(yè)務(wù)的場(chǎng)景 |
4、移動(dòng)端混沌實(shí)驗(yàn)
結(jié)合移動(dòng)端特性與現(xiàn)有穩(wěn)定性測(cè)試基礎(chǔ),以下為混沌工程在移動(dòng)端的系統(tǒng)性實(shí)施框架,涵蓋設(shè)計(jì)原則、核心要素、工具鏈及落地步驟。
a、核心原則
| 核心原則 | 描述 |
| 以業(yè)務(wù)場(chǎng)景為中心 | 故障注入圍繞核心業(yè)務(wù)流程,如物流中的攬收、派送子域,確保關(guān)鍵路徑的韌性 |
| 漸進(jìn)式風(fēng)險(xiǎn)暴露 | 從單點(diǎn)可控故障開(kāi)始,如模擬API超時(shí),逐步升級(jí)至復(fù)雜故障鏈,如網(wǎng)絡(luò)中斷、服務(wù)端熔斷 |
| 可觀(guān)測(cè)性驅(qū)動(dòng) | 故障注入需同步監(jiān)控業(yè)務(wù)指標(biāo),如成功率、耗時(shí),和系統(tǒng)指標(biāo),如崩潰率、資源占用率 |
| 安全邊界控制 | 通過(guò)環(huán)境隔離,如僅限測(cè)試環(huán)境、預(yù)發(fā)環(huán)境隔離,和熔斷機(jī)制,如自動(dòng)終止破壞性實(shí)驗(yàn)規(guī)避生產(chǎn)事故 |
b、核心要素
1)故障場(chǎng)景庫(kù)設(shè)計(jì)
| 故障類(lèi)型 | 典型場(chǎng)景 | 注入手段 |
| 網(wǎng)絡(luò)層 | 5G/弱網(wǎng)切換、DNS劫持、TCP丟包 | Charles弱網(wǎng)模擬、OkHttp MockWebServer |
| 設(shè)備層 | 強(qiáng)制殺進(jìn)程、模擬內(nèi)存泄漏、電池耗盡 | ADB命令(adb shell am force-stop)、Xcode工具鏈 |
| 應(yīng)用層 | 主線(xiàn)程阻塞、依賴(lài)服務(wù)(如地圖SDK)超時(shí) | 代碼插樁(AOP)、第三方SDK Mock工具 |
| 數(shù)據(jù)層 | 本地?cái)?shù)據(jù)庫(kù)損壞、緩存過(guò)期、時(shí)間篡改 | 文件系統(tǒng)操作、SQLite注入異常 |
| 安全層 | 中間人攻擊、證書(shū)校驗(yàn)繞過(guò)、敏感數(shù)據(jù)明文存儲(chǔ) | Wireshark抓包篡改、Frida動(dòng)態(tài)Hook |
2)實(shí)驗(yàn)優(yōu)先級(jí)矩陣
| 業(yè)務(wù)影響 | 發(fā)生概率 | 實(shí)驗(yàn)優(yōu)先級(jí) |
| 高 | 高 | P0(立即修復(fù)) |
| 高 | 低 | P1(灰度驗(yàn)證) |
| 低 | 高 | P2(監(jiān)控優(yōu)化) |
| 低 | 低 | P3(長(zhǎng)期規(guī)劃) |
c、工具鏈與自動(dòng)化集成
1)分層工具矩陣
| 層級(jí) | 推薦工具 | 適用場(chǎng)景 |
| 網(wǎng)絡(luò)模擬 | Charles、ATC、Facebook Augmented Traffic Control | 弱網(wǎng)、斷網(wǎng)、協(xié)議級(jí)攻擊測(cè)試 |
| 設(shè)備控制 | ADB、iOS Simulator CLI、Google Espresso | 進(jìn)程終止、傳感器模擬、自動(dòng)化操作注入 |
| 故障注入 | Chaos Mesh、Pumba、自研SDK | 容器級(jí)資源限制、服務(wù)端聯(lián)調(diào)故障 |
| 監(jiān)控分析 | Firebase Crashlytics、Prometheus+Grafana | 崩潰追蹤、性能指標(biāo)實(shí)時(shí)可視化 |
2)自動(dòng)化流水線(xiàn)設(shè)計(jì)

d、落地實(shí)施步驟
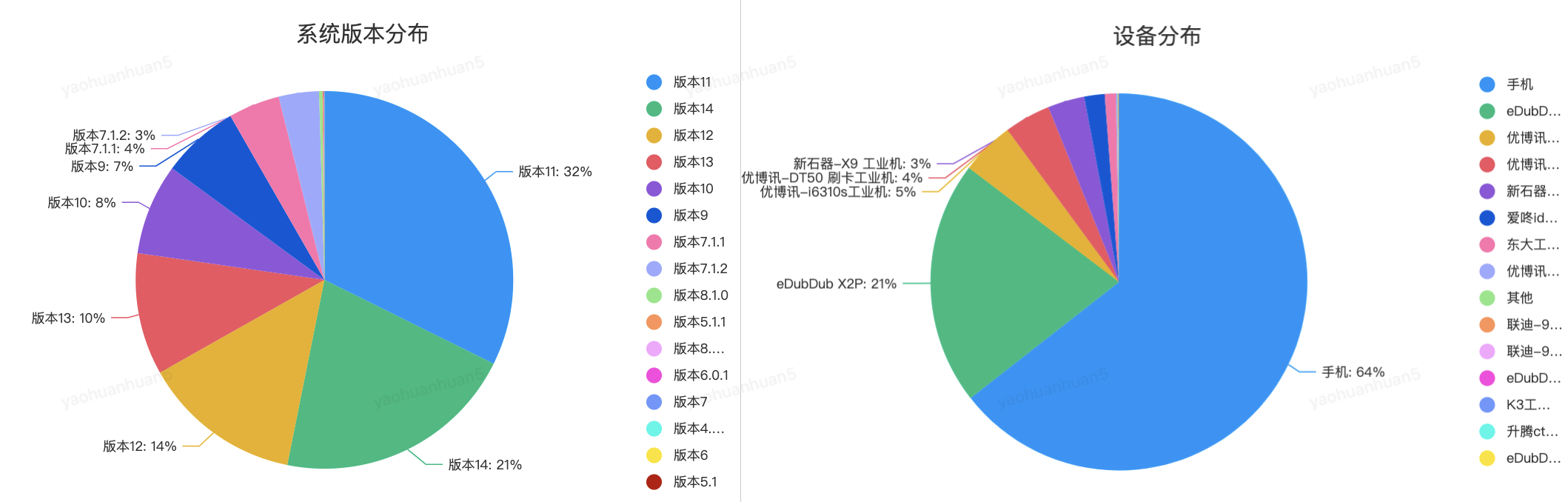
1)設(shè)備覆蓋計(jì)劃
測(cè)試設(shè)備根據(jù)一線(xiàn)使用頻率較高的系統(tǒng)版本和設(shè)備類(lèi)型的TOP3來(lái)選擇。
2)常態(tài)化落地機(jī)制(弱網(wǎng)與斷網(wǎng)故障注入深度實(shí)踐)
弱網(wǎng)與斷網(wǎng)測(cè)試,是驗(yàn)證應(yīng)用網(wǎng)絡(luò)韌性的核心環(huán)節(jié)。通過(guò)Charles工具鏈與深度業(yè)務(wù)場(chǎng)景結(jié)合,系統(tǒng)性驗(yàn)證了移動(dòng)端在極端網(wǎng)絡(luò)條件下的行為,為后續(xù)自動(dòng)化混沌工程流水線(xiàn)建設(shè)提供了實(shí)踐范本。未來(lái)可進(jìn)一步與mpaas監(jiān)控、灰度發(fā)布聯(lián)動(dòng),實(shí)現(xiàn)“故障注入-監(jiān)控告警-自動(dòng)修復(fù)”閉環(huán)。以小哥工作臺(tái)APP為例,其測(cè)試實(shí)施過(guò)程如下:
| 測(cè)試方法與工具鏈 | 工具選型:基于Charles Proxy實(shí)現(xiàn)網(wǎng)絡(luò)故障注入,通過(guò)抓包攔截與網(wǎng)絡(luò)參數(shù)動(dòng)態(tài)配置,模擬2G/3G/4G等網(wǎng)絡(luò)類(lèi)型,支持自定義帶寬(如上行50kbps/下行100kbps)、延時(shí)(300ms~5s)、丟包率(10%~30%)及穩(wěn)定性(周期性斷網(wǎng)) |
| 前置條件:開(kāi)通測(cè)試設(shè)備與Charles的網(wǎng)絡(luò)互訪(fǎng)權(quán)限,確保流量可被代理捕獲;構(gòu)建Debug包以繞過(guò)證書(shū)校驗(yàn)限制,支持HTTPS請(qǐng)求解析。 | |
| 場(chǎng)景覆蓋與問(wèn)題挖掘 | 業(yè)務(wù)場(chǎng)景:圍繞攬收、派送等核心流程,覆蓋100+關(guān)鍵交互節(jié)點(diǎn),包括:訂單提交時(shí)的網(wǎng)絡(luò)閃斷重試;離線(xiàn)模式下地址信息本地緩存與同步;弱網(wǎng)環(huán)境下的圖片上傳降級(jí)策略 |
| 問(wèn)題發(fā)現(xiàn):累計(jì)識(shí)別20+韌性缺陷,如以下3類(lèi)。 ①網(wǎng)絡(luò)切換容錯(cuò)缺失:Wi-Fi與蜂窩網(wǎng)絡(luò)切換時(shí),偶現(xiàn)任務(wù)狀態(tài)丟失; ②重試風(fēng)暴:斷網(wǎng)恢復(fù)后,客戶(hù)端未采用指數(shù)退避策略,導(dǎo)致服務(wù)端瞬時(shí)流量激增; ③離線(xiàn)數(shù)據(jù)沖突:多設(shè)備離線(xiàn)操作后,數(shù)據(jù)合并邏輯異常引發(fā)業(yè)務(wù)臟數(shù)據(jù)。 | |
| 優(yōu)化方向 | 流程提效:推動(dòng)去Debug包依賴(lài),采用OkHttp MockWebServer或Charles Map Local功能,直接劫持線(xiàn)上包API響應(yīng),減少構(gòu)建成本; 構(gòu)建自動(dòng)化弱網(wǎng)場(chǎng)景庫(kù),將典型配置(如電梯、樓宇網(wǎng)絡(luò))預(yù)設(shè)為腳本,一鍵觸發(fā)測(cè)試。 |
?
5、AI大模型與混沌工程的雙向融合
a、AI場(chǎng)景下的混沌實(shí)驗(yàn)
1)AI大模型系統(tǒng)與傳統(tǒng)系統(tǒng)的差異
隨著AI大模型技術(shù)的快速發(fā)展,各行各業(yè)的傳統(tǒng)系統(tǒng)都在逐步融合AI大模型能力,那么由此給混沌實(shí)驗(yàn)帶來(lái)了新的挑戰(zhàn),與傳統(tǒng)系統(tǒng)的混沌實(shí)驗(yàn)相比,融合了AI大模型能力的系統(tǒng)則會(huì)有一定的差異性,如下:
| 維度 | 傳統(tǒng)系統(tǒng) | AI大模型融合系統(tǒng) |
| 實(shí)驗(yàn)原理 | 基于確定性規(guī)則(如手動(dòng)觸發(fā)服務(wù)宕機(jī)、模擬流量激增)。 | 結(jié)合AI生成對(duì)抗性故障(如動(dòng)態(tài)調(diào)整故障參數(shù)、模擬數(shù)據(jù)分布偏移)。 |
| 實(shí)驗(yàn)?zāi)繕?biāo) | 驗(yàn)證系統(tǒng)對(duì)已知故障(如網(wǎng)絡(luò)延遲、服務(wù)宕機(jī))的容錯(cuò)能力,確保預(yù)設(shè)的冗余、熔斷等機(jī)制有效。 | 包括傳統(tǒng)系統(tǒng)既有的實(shí)驗(yàn)?zāi)繕?biāo)以外,還需: 1、驗(yàn)證AI模型的動(dòng)態(tài)適應(yīng)能力(如故障預(yù)測(cè)、自愈決策),驗(yàn)證系統(tǒng)在復(fù)雜、動(dòng)態(tài)環(huán)境中的智能響應(yīng)能力。 2、評(píng)估AI模型的魯棒性(如對(duì)抗數(shù)據(jù)擾動(dòng)、模型漂移)、AI與人類(lèi)決策的協(xié)作效率 |
| 場(chǎng)景設(shè)計(jì) | 硬件/網(wǎng)絡(luò)故障、服務(wù)中斷 | 數(shù)據(jù)異常、模型推理瓶頸、算力動(dòng)態(tài)調(diào)度 |
| 監(jiān)控指標(biāo) | 基礎(chǔ)資源、接口調(diào)用、服務(wù)可用性(SLA)、平均恢復(fù)時(shí)間(MTTR)、錯(cuò)誤率。 | 保留傳統(tǒng)指標(biāo),并新增AI相關(guān)指標(biāo): - 模型推理延遲、決策準(zhǔn)確率; - 異常檢測(cè)召回率; - 動(dòng)態(tài)策略調(diào)整效率。 -數(shù)據(jù)質(zhì)量(如特征分布偏移)、模型置信度、AI與人類(lèi)決策一致性。 |
| 結(jié)果分析 | 單點(diǎn)故障定位、容錯(cuò)機(jī)制驗(yàn)證 | 模型魯棒性評(píng)估、數(shù)據(jù)鏈路風(fēng)險(xiǎn)、業(yè)務(wù)影響量化 |
因此,在對(duì)AI大模型融合系統(tǒng)實(shí)施混沌實(shí)驗(yàn)時(shí),在滿(mǎn)足傳統(tǒng)系統(tǒng)混沌實(shí)驗(yàn)關(guān)注點(diǎn)的同時(shí),還需要更加關(guān)注模型服務(wù)可靠性(如推理延遲、數(shù)據(jù)異常影響),覆蓋數(shù)據(jù)噪聲、GPU資源爭(zhēng)用及模型輸出漂移等復(fù)雜場(chǎng)景,指標(biāo)監(jiān)控上應(yīng)額外追蹤模型性能(如準(zhǔn)確率)、數(shù)據(jù)分布偏移及GPU利用率。在進(jìn)行結(jié)果分析時(shí)需量化模型魯棒性、數(shù)據(jù)鏈路風(fēng)險(xiǎn)及業(yè)務(wù)間接損失(如用戶(hù)信任)。
?
2)AI大模型混沌工程實(shí)驗(yàn)
①實(shí)驗(yàn)?zāi)繕?biāo)
?驗(yàn)證大模型服務(wù)降級(jí)/熔斷策略的有效性
?測(cè)試模型服務(wù)與業(yè)務(wù)系統(tǒng)的異常協(xié)同能力
?檢測(cè)數(shù)據(jù)流-模型-業(yè)務(wù)鏈路的健壯性
?驗(yàn)證模型性能監(jiān)控與自動(dòng)恢復(fù)機(jī)制。
②實(shí)驗(yàn)原則
?最小化爆炸半徑:從非核心業(yè)務(wù)開(kāi)始,逐步擴(kuò)大范圍
?可觀(guān)測(cè)性:確保所有操作可監(jiān)控、可記錄、可回滾
?穩(wěn)態(tài)假設(shè):明確定義系統(tǒng)正常運(yùn)行的指標(biāo)(如成功率、延遲、QPS等)
?生產(chǎn)環(huán)境優(yōu)先:優(yōu)先在生產(chǎn)環(huán)境進(jìn)行(需嚴(yán)格規(guī)劃)
③實(shí)驗(yàn)標(biāo)準(zhǔn)
| 實(shí)驗(yàn)準(zhǔn)入 | 實(shí)驗(yàn)準(zhǔn)出 |
| 演練前,研測(cè)雙方,未完成演練分組確認(rèn)、數(shù)據(jù)隔離確認(rèn),禁止啟動(dòng)演練 | 故障識(shí)別效率:守方在5分鐘內(nèi)識(shí)別故障,同時(shí)在“常態(tài)化備戰(zhàn)群”報(bào)備故障 |
| 演練場(chǎng)景,未通過(guò)研測(cè)聯(lián)合評(píng)審,并發(fā)出評(píng)審紀(jì)要,禁止啟動(dòng)演練 | 故障定位效率:守方在10分鐘內(nèi)定位故障,同時(shí)在“常態(tài)化備戰(zhàn)群”同步故障原因 |
| 演練周期內(nèi),指定攻守人員未在指定場(chǎng)所準(zhǔn)備就緒,禁止啟動(dòng)演練 | 止損效率:守方在15分鐘內(nèi)通過(guò)自動(dòng)或手動(dòng)方式,降級(jí)止損 |
| 演練平臺(tái)任務(wù),未與演練劇本及觀(guān)察員,二次對(duì)齊確認(rèn),禁止啟動(dòng)演練 | 弱依賴(lài)有效性:弱依賴(lài)類(lèi)故障,不影響核心業(yè)務(wù)流轉(zhuǎn) |
| 演練集群申請(qǐng)列表檢查完畢 | 故障修復(fù)效率:如演練場(chǎng)景為有損故障、或故障注入過(guò)程對(duì)線(xiàn)上業(yè)務(wù)產(chǎn)生影響,需要在20分鐘內(nèi)修復(fù) |
| 演練退出標(biāo)準(zhǔn):故障注入超過(guò)5分鐘未被識(shí)別、超過(guò)10分鐘未被定位、超過(guò)15分鐘未止損,對(duì)應(yīng)場(chǎng)景終止故障注入,并完成環(huán)境初始化,標(biāo)記演練未通過(guò) |
④場(chǎng)景設(shè)計(jì)原則
針對(duì)AI大模型工程系統(tǒng)的混沌實(shí)驗(yàn)設(shè)計(jì),需結(jié)合核心業(yè)務(wù)場(chǎng)景和底層依賴(lài)(算力、數(shù)據(jù)、模型、網(wǎng)絡(luò)),重點(diǎn)驗(yàn)證系統(tǒng)的容錯(cuò)性、自適應(yīng)能力和用戶(hù)體驗(yàn)魯棒性。
| 故障分類(lèi) | 具體場(chǎng)景 | 實(shí)驗(yàn)步驟 | 過(guò)程監(jiān)控 | 預(yù)期結(jié)果 |
| 基礎(chǔ)設(shè)施層 | GPU節(jié)點(diǎn)故障 | 1. 選擇1個(gè)GPU計(jì)算節(jié)點(diǎn) 2. 模擬硬件故障(如nvidia-smi注入故障代碼) 3. 持續(xù)10分鐘 | - GPU利用率/溫度實(shí)時(shí)監(jiān)控 - 節(jié)點(diǎn)存活狀態(tài)檢測(cè) - 服務(wù)自動(dòng)遷移日志追蹤 | - 服務(wù)自動(dòng)遷移至備用節(jié)點(diǎn) - 業(yè)務(wù)中斷時(shí)間<30秒 - GPU資源池利用率波動(dòng)<15% |
| 顯存溢出攻擊 | 1. 逐步增加推理請(qǐng)求的輸入尺寸 2. 監(jiān)控顯存使用率 3. 觸發(fā)OOM后記錄恢復(fù)流程 | - 顯存分配/釋放速率監(jiān)控 - OOM錯(cuò)誤日志捕獲 - 關(guān)聯(lián)服務(wù)健康狀態(tài)檢測(cè) | - 觸發(fā)熔斷機(jī)制自動(dòng)重啟服務(wù) - 錯(cuò)誤日志記錄完整率100% - 未影響其他模型服務(wù) | |
| 服務(wù)層 | 模型API高延遲 | 1. 在API網(wǎng)關(guān)注入10000ms延遲 2. 維持15分鐘 3. 監(jiān)控降級(jí)策略觸發(fā)情況 | - 請(qǐng)求響應(yīng)時(shí)間分布監(jiān)控 - 客戶(hù)端重試次數(shù)統(tǒng)計(jì) - 降級(jí)策略觸發(fā)狀態(tài) | - 客戶(hù)端超時(shí)重試機(jī)制生效 - 備用模型啟用率>90% - 整體錯(cuò)誤率上升≤5% |
| 模型熱切換失敗 | 1. 推送新模型版本 2. 強(qiáng)制中斷切換過(guò)程 3. 驗(yàn)證回滾機(jī)制 | - 模型版本哈希校驗(yàn) - 切換過(guò)程耗時(shí)監(jiān)控 - 請(qǐng)求成功率波動(dòng)檢測(cè) | - 10秒內(nèi)檢測(cè)到切換失敗 - 自動(dòng)回退至穩(wěn)定版本 - 業(yè)務(wù)請(qǐng)求成功率>99.5% | |
| 數(shù)據(jù)流層 | 特征存儲(chǔ)中斷 | 1. 切斷特征存儲(chǔ)服務(wù)網(wǎng)絡(luò) 2. 持續(xù)5分鐘 3. 恢復(fù)后驗(yàn)證數(shù)據(jù)一致性 | - 特征服務(wù)健康檢查 - 本地緩存命中率監(jiān)控 - 數(shù)據(jù)一致性校驗(yàn) | - 自動(dòng)切換本地特征緩存 - 數(shù)據(jù)恢復(fù)后差異率<0.1% - 業(yè)務(wù)決策準(zhǔn)確率下降≤3% |
| 實(shí)時(shí)數(shù)據(jù)亂序 | 1. 注入10%亂序數(shù)據(jù)流 2. 逐步提升至50%亂序率 3. 監(jiān)控處理延遲 | - 數(shù)據(jù)流處理延遲監(jiān)控 - 窗口計(jì)算偏差檢測(cè) - 亂序告警觸發(fā)統(tǒng)計(jì) | - 流處理引擎亂序容忍機(jī)制生效 - 最終計(jì)算結(jié)果偏差<1% - 告警系統(tǒng)在30秒內(nèi)觸發(fā) | |
| 模型層 | 模型精度下降 | 1. 修改在線(xiàn)模型權(quán)重參數(shù) 2. 注入5%對(duì)抗樣本 3. 監(jiān)控模型輸出穩(wěn)定性 | - 模型輸出分布偏移檢測(cè) - 對(duì)抗樣本識(shí)別率 - 業(yè)務(wù)決策錯(cuò)誤率波動(dòng) | - 模型監(jiān)控系統(tǒng)30秒內(nèi)告警 - 自動(dòng)切換備用模型 - 業(yè)務(wù)決策錯(cuò)誤率<警戒閾值(如2%) |
| 多模型投票失效 | 1. 關(guān)閉1個(gè)投票模型實(shí)例 2. 注入矛盾樣本 3. 驗(yàn)證決策一致性 | - 投票結(jié)果置信度監(jiān)控 - 模型間結(jié)果差異率 - 人工干預(yù)請(qǐng)求量統(tǒng)計(jì) | - 投票機(jī)制自動(dòng)降級(jí)為權(quán)重模式 - 最終決策置信度>85% - 人工復(fù)核請(qǐng)求觸發(fā)率<5% |
?
b、快遞快運(yùn)小哥AI智能助手-混沌工程探索
1)系統(tǒng)簡(jiǎn)介
快遞快運(yùn)終端系統(tǒng)是服務(wù)于一線(xiàn)快遞小哥及站點(diǎn)管理者的日常工作作業(yè)實(shí)操系統(tǒng),是京東物流作業(yè)人員最多、物流攬派作業(yè)最末端以及作業(yè)形態(tài)多元化的系統(tǒng)。
AI大模型具有超強(qiáng)自然語(yǔ)言處理、泛化能力、意圖理解、類(lèi)人推理以及多元化結(jié)果輸出的獨(dú)特能力,基于此,快遞快運(yùn)小哥AI智能助手通過(guò)結(jié)合AI大模型工程系統(tǒng)、大數(shù)據(jù)、GIS、語(yǔ)音SDK等分別在攬收、派送、站內(nèi)、輔助、問(wèn)答服務(wù)五大類(lèi)作業(yè)環(huán)節(jié)上實(shí)現(xiàn)了如小哥攬收信息錄入、打電話(huà)、發(fā)短信、查詢(xún)運(yùn)單信息、小哥攬派任務(wù)信息聚合查詢(xún)、知識(shí)問(wèn)答及攬派履約時(shí)效精準(zhǔn)化提示等場(chǎng)景。提升小哥作業(yè)效率和攬派實(shí)操體驗(yàn)。
2)系統(tǒng)架構(gòu)分析
快遞快運(yùn)小哥AI智能助手【產(chǎn)品架構(gòu)圖】快遞快運(yùn)小哥AI智能助手故障演練【系統(tǒng)架構(gòu)圖】
3)實(shí)驗(yàn)場(chǎng)景
針對(duì)AI大模型工程系統(tǒng)的混沌實(shí)驗(yàn)設(shè)計(jì),需結(jié)合核心功能(智能提示、智能問(wèn)答、智能操作)和底層依賴(lài)(算力、數(shù)據(jù)、模型、網(wǎng)絡(luò)),重點(diǎn)驗(yàn)證系統(tǒng)的容錯(cuò)性、自適應(yīng)能力和用戶(hù)體驗(yàn)魯棒性。
| 故障分類(lèi) | 具體場(chǎng)景 | 實(shí)驗(yàn)步驟 | 預(yù)期結(jié)果 |
| 服務(wù)層 | 模型API高延遲 (AI大模型工程系統(tǒng)提供給小哥后臺(tái)服務(wù)系統(tǒng)的API高延遲) | ·從泰山平臺(tái)注入10000ms延遲故障場(chǎng)景 ·故障維持15分鐘 ·停止故障場(chǎng)景注入,恢復(fù)大模型能力 | ·小哥工作臺(tái)APP客戶(hù)端檢測(cè)到大模型服務(wù)接口超時(shí)(如攬收數(shù)據(jù)錄入時(shí),無(wú)法得到響應(yīng)數(shù)據(jù)),啟動(dòng)降級(jí)策略機(jī)制,切斷大模型服務(wù),兜底回到五大模型服務(wù)模式,小哥可以正常繼續(xù)標(biāo)準(zhǔn)化作業(yè) ·小哥工作臺(tái)APP持續(xù)在無(wú)大模型服務(wù)下運(yùn)轉(zhuǎn) ·小哥工作臺(tái)APP客戶(hù)端檢測(cè)大模型能力恢復(fù),啟動(dòng)大模型能力服務(wù) |
| 模型層 | 模型精度下降 | ·修改在線(xiàn)模型權(quán)重參數(shù) ·注入5%對(duì)抗樣本數(shù)據(jù)(線(xiàn)上已錄制的大模型訪(fǎng)問(wèn)數(shù)據(jù)流量) ·恢復(fù)大模型參數(shù) | ·大模型監(jiān)控系統(tǒng)30秒內(nèi)告警,識(shí)別到模型參數(shù)異常變更,預(yù)警通知開(kāi)發(fā)人員,開(kāi)發(fā)人員發(fā)現(xiàn)模型參數(shù)異常 ·客戶(hù)端發(fā)現(xiàn)大模型使用能力下降,開(kāi)發(fā)啟動(dòng)自動(dòng)切換備用模型(參數(shù)已經(jīng)適配好的模型),開(kāi)發(fā)下線(xiàn)參數(shù)異常模型 ·開(kāi)發(fā)發(fā)現(xiàn)參數(shù)異常模型恢復(fù),重新啟動(dòng)上線(xiàn) |
?
c、混沌工程的AI智能化演進(jìn)展望
混沌實(shí)驗(yàn)的AI化演進(jìn)是系統(tǒng)穩(wěn)定性測(cè)試與人工智能技術(shù)深度融合的重要趨勢(shì)。這一演進(jìn)不僅體現(xiàn)在實(shí)驗(yàn)工具的智能化升級(jí)上,更體現(xiàn)在實(shí)驗(yàn)設(shè)計(jì)、執(zhí)行與分析的全鏈路優(yōu)化中。以下分別從技術(shù)融合、工具創(chuàng)新及場(chǎng)景擴(kuò)展三個(gè)維度展開(kāi)論述:
1)技術(shù)融合:AI賦能混沌實(shí)驗(yàn)的核心環(huán)節(jié)
混沌實(shí)驗(yàn)包含了實(shí)驗(yàn)設(shè)計(jì)、實(shí)驗(yàn)執(zhí)行及實(shí)驗(yàn)監(jiān)控與根因分析三大核心環(huán)節(jié),具體而言。
?
①實(shí)驗(yàn)設(shè)計(jì)智能化
傳統(tǒng)混沌實(shí)驗(yàn)依賴(lài)于人工假設(shè)(如“當(dāng)網(wǎng)絡(luò)延遲增加時(shí),系統(tǒng)可用性應(yīng)保持在99.99%以上”),而AI可通過(guò)歷史故障數(shù)據(jù)與系統(tǒng)日志,自動(dòng)識(shí)別潛在脆弱點(diǎn)并生成實(shí)驗(yàn)假設(shè)。
例如,基于強(qiáng)化學(xué)習(xí)的AI模型可模擬復(fù)雜故障場(chǎng)景的組合,優(yōu)化實(shí)驗(yàn)參數(shù)(如故障注入的強(qiáng)度、范圍),提升測(cè)試覆蓋率。AI可分析服務(wù)調(diào)用鏈,預(yù)測(cè)依賴(lài)服務(wù)失效后的級(jí)聯(lián)影響,并自動(dòng)設(shè)計(jì)針對(duì)性的網(wǎng)絡(luò)分區(qū)實(shí)驗(yàn)。在驗(yàn)證電商大促場(chǎng)景下的訂單支付鏈路韌性時(shí),通過(guò)AI驅(qū)動(dòng)的智能實(shí)驗(yàn)設(shè)計(jì),系統(tǒng)可自動(dòng)化發(fā)現(xiàn)潛在風(fēng)險(xiǎn)組合并生成針對(duì)性實(shí)驗(yàn)方案,具體而言
| 實(shí)驗(yàn)設(shè)計(jì)關(guān)鍵環(huán)節(jié) | 實(shí)驗(yàn)設(shè)計(jì)關(guān)鍵流程 |
| 歷史數(shù)據(jù)挖掘與脆弱點(diǎn)識(shí)別 | 數(shù)據(jù)輸入: ·歷史故障日志:比如過(guò)去3年大促期間記錄的168次服務(wù)降級(jí)事件(如庫(kù)存超賣(mài)、優(yōu)惠券死鎖)。 ·系統(tǒng)拓?fù)洌悍?wù)依賴(lài)關(guān)系(如支付網(wǎng)關(guān)調(diào)用訂單數(shù)據(jù)庫(kù)的頻率為5000次/秒)。 ·性能基線(xiàn):日常與大促期間的CPU/內(nèi)存/延遲指標(biāo)對(duì)比數(shù)據(jù) AI分析: ·使用圖神經(jīng)網(wǎng)絡(luò)(GNN)分析服務(wù)調(diào)用鏈,識(shí)別高頻依賴(lài)且資源消耗高的節(jié)點(diǎn)(如優(yōu)惠券服務(wù)在流量峰值時(shí)CPU利用率達(dá)90%)。 ·基于關(guān)聯(lián)規(guī)則挖掘(Apriori算法)發(fā)現(xiàn)故障組合模式(如“庫(kù)存服務(wù)響應(yīng)延遲>200ms”與“支付網(wǎng)關(guān)連接池耗盡”共同發(fā)生的概率為72%)。 |
| 強(qiáng)化學(xué)習(xí)生成實(shí)驗(yàn)參數(shù) | 強(qiáng)化學(xué)習(xí)模型(PPO算法)配置: ·狀態(tài)空間:優(yōu)惠券服務(wù)線(xiàn)程池使用率、支付網(wǎng)關(guān)活躍連接數(shù)、訂單數(shù)據(jù)庫(kù)寫(xiě)入延遲。 ·動(dòng)作空間: ·故障類(lèi)型:線(xiàn)程阻塞(阻塞比例10%~100%)、連接池限制(50%~20%容量)。 ·注入時(shí)機(jī):流量爬坡期(0%~100%峰值)。 ·獎(jiǎng)勵(lì)函數(shù): ·正向獎(jiǎng)勵(lì):實(shí)驗(yàn)觸發(fā)系統(tǒng)熔斷/降級(jí)(如訂單服務(wù)自動(dòng)切換為本地緩存)。 ·負(fù)向獎(jiǎng)勵(lì):訂單失敗率>0.1%或?qū)嶒?yàn)引發(fā)級(jí)聯(lián)故障。 ·訓(xùn)練過(guò)程: 在仿真環(huán)境中模擬10萬(wàn)次實(shí)驗(yàn),AI學(xué)習(xí)到最優(yōu)策略: “在流量達(dá)到峰值的70%時(shí),先注入優(yōu)惠券服務(wù)50%線(xiàn)程阻塞,待系統(tǒng)觸發(fā)自動(dòng)擴(kuò)容后,再限制支付網(wǎng)關(guān)連接池至30%容量” |
| 實(shí)驗(yàn)執(zhí)行與動(dòng)態(tài)調(diào)控 | 初始注入:AI按策略在流量爬坡期注入優(yōu)惠券服務(wù)50%線(xiàn)程阻塞。 動(dòng)態(tài)響應(yīng): ·系統(tǒng)檢測(cè)到線(xiàn)程池滿(mǎn)載,自動(dòng)擴(kuò)容優(yōu)惠券服務(wù)實(shí)例(從10個(gè)擴(kuò)展到15個(gè))。 ·AI監(jiān)控到擴(kuò)容完成,立即觸發(fā)支付網(wǎng)關(guān)連接池限制至30%。 異常檢測(cè): ·訂單數(shù)據(jù)庫(kù)寫(xiě)入延遲突增至800ms(超過(guò)基線(xiàn)300%),AI通過(guò)LSTM模型預(yù)測(cè)5秒內(nèi)可能觸發(fā)死鎖,立即停止實(shí)驗(yàn)并回滾故障。 |
通過(guò)借助AI智能實(shí)驗(yàn)方案設(shè)計(jì),獲得以下收益。
| 優(yōu)勢(shì)項(xiàng) | 描述 |
| 風(fēng)險(xiǎn)發(fā)現(xiàn)效率提升 | 提前識(shí)別出4個(gè)高危漏洞 |
| 驗(yàn)證成本降低 | 實(shí)驗(yàn)耗時(shí)從人工方案的48小時(shí)縮短至6小時(shí),資源消耗減少60% |
| 韌性增強(qiáng) | 優(yōu)化后系統(tǒng)在真實(shí)大促中訂單失敗率從0.15%降至0.02%,且故障平均恢復(fù)時(shí)間(MTTR)從8分鐘縮短至90秒 |
以上,AI不僅替代了人工設(shè)計(jì)中的重復(fù)勞動(dòng),更重要的是通過(guò)系統(tǒng)化挖掘隱性關(guān)聯(lián)與動(dòng)態(tài)博弈式測(cè)試,將混沌工程從“已知-已知”測(cè)試升級(jí)為“已知-未知”甚至“未知-未知”風(fēng)險(xiǎn)探索。
?
②執(zhí)行與調(diào)控動(dòng)態(tài)化
AI的動(dòng)態(tài)決策能力使得混沌實(shí)驗(yàn)從“預(yù)設(shè)故障”向“自適應(yīng)故障注入”演進(jìn)。例如,通過(guò)實(shí)時(shí)監(jiān)控系統(tǒng)指標(biāo)(如CPU負(fù)載、請(qǐng)求延遲),AI可動(dòng)態(tài)調(diào)整故障注入的強(qiáng)度或終止實(shí)驗(yàn),避免超出系統(tǒng)容災(zāi)閾值。通過(guò)AI驅(qū)動(dòng)的動(dòng)態(tài)實(shí)驗(yàn)調(diào)控,可以使混沌工程實(shí)現(xiàn)更多的突破,例如:實(shí)現(xiàn)動(dòng)態(tài)適應(yīng)性,從“固定劇本”升級(jí)為“實(shí)時(shí)博弈”,更貼近真實(shí)故障場(chǎng)景;實(shí)現(xiàn)精準(zhǔn)調(diào)控,避免因過(guò)度測(cè)試導(dǎo)致業(yè)務(wù)受損,平衡實(shí)驗(yàn)風(fēng)險(xiǎn)與價(jià)值;實(shí)現(xiàn)多目標(biāo)優(yōu)化,同時(shí)驗(yàn)證性能、穩(wěn)定性、安全性的綜合影響,例如:驗(yàn)證系統(tǒng)在流量激增時(shí)自動(dòng)擴(kuò)縮容的能力。
| 實(shí)驗(yàn)場(chǎng)景 | 在大促期間實(shí)施彈性伸縮混沌實(shí)驗(yàn) |
| 實(shí)驗(yàn)?zāi)繕?biāo) | 驗(yàn)證系統(tǒng)在流量激增時(shí)自動(dòng)擴(kuò)縮容的能力 |
| AI調(diào)控策略 | 初始故障:模擬流量突增50%,觸發(fā)自動(dòng)擴(kuò)容 動(dòng)態(tài)調(diào)整: ·若系統(tǒng)擴(kuò)容速度過(guò)慢(如新實(shí)例啟動(dòng)時(shí)間>3分鐘),AI自動(dòng)追加CPU負(fù)載故障(如占用80% CPU),資源爭(zhēng)用下的擴(kuò)容極限。 ·若擴(kuò)容成功但負(fù)載均衡異常(如某些實(shí)例請(qǐng)求量超標(biāo)),AI注入節(jié)點(diǎn)宕機(jī)故障,驗(yàn)證服務(wù)遷移能力。 終止條件:當(dāng)訂單失敗率超過(guò)1%時(shí),立即停止實(shí)驗(yàn)并觸發(fā)告警 |
| 預(yù)期結(jié)果 | AI發(fā)現(xiàn)擴(kuò)容策略在CPU高負(fù)載時(shí)延遲增加2倍,推薦優(yōu)化預(yù)熱腳本并增加冗余實(shí)例池 |
?
③智能監(jiān)控與智能根因分析
傳統(tǒng)監(jiān)控工具(如Prometheus)依賴(lài)人工設(shè)置告警閾值,而AI可通過(guò)異常檢測(cè)算法(如LSTM、自編碼器)實(shí)時(shí)識(shí)別系統(tǒng)行為的偏離,并關(guān)聯(lián)故障注入事件,快速定位根因。例如,南京大學(xué)利用AI分析古生物大數(shù)據(jù)揭示復(fù)雜系統(tǒng)的演化模式,類(lèi)似方法可用于預(yù)測(cè)分布式系統(tǒng)中的故障傳播路徑。
智能監(jiān)控與根因分析通過(guò)AI技術(shù)實(shí)現(xiàn)從“被動(dòng)告警”到“主動(dòng)預(yù)測(cè)-定位”的跨越,其核心是通過(guò)多維度數(shù)據(jù)融合與因果推理,快速定位復(fù)雜系統(tǒng)中的故障根源。其技術(shù)原理可以從以下幾個(gè)方面深入展開(kāi):
| 異常檢測(cè):動(dòng)態(tài)閾值與模式識(shí)別 | 傳統(tǒng)監(jiān)控缺陷:人工設(shè)置靜態(tài)閾值(如“CPU使用率>90%觸發(fā)告警”),無(wú)法適應(yīng)業(yè)務(wù)波動(dòng)(如大促期間CPU正常使用率可能長(zhǎng)期維持在85%) |
| AI解決方案: 1)時(shí)序預(yù)測(cè)模型(LSTM/Prophet):基于歷史數(shù)據(jù)預(yù)測(cè)指標(biāo)正常范圍(如預(yù)測(cè)大促期間訂單服務(wù)的請(qǐng)求延遲基線(xiàn)為50ms±10ms),動(dòng)態(tài)調(diào)整告警閾值; 2)無(wú)監(jiān)督異常檢測(cè)(自編碼器/Isolation Forest):通過(guò)對(duì)比實(shí)時(shí)數(shù)據(jù)與正常模式的特征差異(如請(qǐng)求成功率的分布偏移),識(shí)別未知異常類(lèi)型(如特定API接口的偶發(fā)超時(shí)) | |
| 根因定位:因果圖與傳播路徑推理 | 傳統(tǒng)方法缺陷:人工排查需逐層檢查日志、指標(biāo)和鏈路追蹤,耗時(shí)長(zhǎng)且易遺漏隱性依賴(lài) |
| AI解決方案: 1)服務(wù)拓?fù)浣#▓D神經(jīng)網(wǎng)絡(luò)/GNN):將微服務(wù)調(diào)用關(guān)系建模為圖結(jié)構(gòu),分析節(jié)點(diǎn)(服務(wù))與邊(依賴(lài))的異常傳播權(quán)重。 2)因果推理(貝葉斯網(wǎng)絡(luò)/結(jié)構(gòu)方程模型):結(jié)合故障注入實(shí)驗(yàn)數(shù)據(jù)(如“當(dāng)Redis緩存失效時(shí),數(shù)據(jù)庫(kù)QPS增加300%”),構(gòu)建故障因果鏈,量化各因素對(duì)目標(biāo)異常(如訂單失敗率)的貢獻(xiàn)度。 | |
| 故障傳播預(yù)測(cè):復(fù)雜系統(tǒng)仿真 | 仿生學(xué)啟發(fā):借鑒南京大學(xué)分析古生物演化的方法(如模擬環(huán)境劇變對(duì)物種多樣性的影響),通過(guò)數(shù)字孿生技術(shù)構(gòu)建系統(tǒng)仿真模型,預(yù)測(cè)故障傳播路徑 |
| 關(guān)鍵技術(shù): 1)故障注入+強(qiáng)化學(xué)習(xí):模擬隨機(jī)或組合故障(如“數(shù)據(jù)庫(kù)主從延遲+緩存擊穿”),觀(guān)察系統(tǒng)響應(yīng)并生成故障傳播概率圖。 2)傳播路徑預(yù)測(cè):若檢測(cè)到A服務(wù)異常,AI基于歷史數(shù)據(jù)預(yù)測(cè)其下游影響(如A服務(wù)故障有70%概率在30秒內(nèi)導(dǎo)致B服務(wù)超時(shí)) |
AI驅(qū)動(dòng)的智能監(jiān)控與根因分析通過(guò)動(dòng)態(tài)異常檢測(cè)-因果推理-傳播預(yù)測(cè)的三層技術(shù)架構(gòu),將故障定位從“人工地毯式排查”升級(jí)為“秒級(jí)精準(zhǔn)定位”。此能力不僅大幅縮短了故障恢復(fù)時(shí)間,更重要的是通過(guò)預(yù)測(cè)潛在連鎖反應(yīng)(如“緩存失效→數(shù)據(jù)庫(kù)過(guò)載→服務(wù)雪崩”),推動(dòng)系統(tǒng)架構(gòu)從“容災(zāi)”向“抗災(zāi)”演進(jìn)。未來(lái),結(jié)合故障注入實(shí)驗(yàn)的閉環(huán)驗(yàn)證,AI監(jiān)控有望實(shí)現(xiàn)“自愈推薦”,即自動(dòng)生成修復(fù)策略并驗(yàn)證其有效性,真正實(shí)現(xiàn)系統(tǒng)的智能韌性。
?
2)AI驅(qū)動(dòng)的混沌工程平臺(tái)能力升級(jí)
①混沌工程工具AI能力建設(shè)焦點(diǎn)
以下針對(duì)目前的發(fā)展方向,混沌工程平臺(tái),可基于以下幾個(gè)方面拓展能力升級(jí)。
| 故障類(lèi)型 | 故障描述 | 參數(shù)說(shuō)明 |
| GPU節(jié)點(diǎn)故障 | 故障注入平臺(tái)的配置需要結(jié)合硬件特性、分布式訓(xùn)練框架的容錯(cuò)機(jī)制以及業(yè)務(wù)場(chǎng)景需求,包含:硬件級(jí)故障、軟件級(jí)故障以及環(huán)境級(jí)故障 | 參數(shù)類(lèi)別 示例參數(shù) 說(shuō)明 故障類(lèi)型 gpu_failure_type 顯存錯(cuò)誤/驅(qū)動(dòng)崩潰/NVLink中斷等 持續(xù)時(shí)間 duration 瞬時(shí)故障(毫秒級(jí))或持續(xù)故障(分鐘級(jí)) 影響范圍 gpu_index 指定GPU卡序號(hào)(如0-3) 錯(cuò)誤概率 error_rate 顯存訪(fǎng)問(wèn)錯(cuò)誤的發(fā)生頻率(如1e-6次/操作) |
| 顯存溢出攻擊 | 模擬惡意或異常顯存占用行為,驗(yàn)證系統(tǒng)對(duì)顯存資源耗盡場(chǎng)景的防御能力、容錯(cuò)機(jī)制及恢復(fù)效率,包含: 顯存暴力搶占:持續(xù)分配顯存直至耗盡(模擬惡意進(jìn)程)。 顯存泄漏攻擊:周期性分配顯存但不釋放(模擬代碼缺陷)。 梯度爆炸攻擊:注入異常梯度值導(dǎo)致反向傳播顯存需求激增。 多任務(wù)資源競(jìng)爭(zhēng):并行啟動(dòng)多個(gè)高顯存任務(wù)(測(cè)試調(diào)度策略的健壯性)。 | 參數(shù)項(xiàng) 可選值/示例 說(shuō)明 fault_type gpu_memory_overflow 故障類(lèi)型(顯存溢出攻擊) injection_method direct_allocation(直接分配) gradient_attack(梯度爆炸) multi_task(多任務(wù)競(jìng)爭(zhēng)) 顯存溢出的具體實(shí)現(xiàn)方式 target_gpu 0(GPU卡序號(hào)) 指定攻擊的目標(biāo)GPU設(shè)備 memory_fill_rate "90%" 或 "10GB" 顯存占用目標(biāo)閾值(百分比或絕對(duì)值) leak_speed "100MB/s" 顯存泄漏速率(僅對(duì)泄漏攻擊有效) attack_duration "5m"(5分鐘) 攻擊持續(xù)時(shí)間(瞬態(tài)攻擊或持續(xù)攻擊) |
| 模型熱切換失敗 | 在不停機(jī)的情況下切換模型版本時(shí),因資源競(jìng)爭(zhēng)、依賴(lài)沖突或狀態(tài)同步錯(cuò)誤導(dǎo)致新模型加載失敗或舊模型殘留,引發(fā)服務(wù)中斷或預(yù)測(cè)結(jié)果混亂。例如:新模型加載時(shí)顯存不足、舊模型卸載不徹底(如未釋放GPU資源)、版本元數(shù)據(jù)(如輸入輸出格式)不兼容 | 參數(shù)項(xiàng) 可選值/示例 說(shuō)明 fault_type model_hotswap_failure 故障類(lèi)型(模型熱切換失敗) injection_method resource_lock(資源鎖定) metadata_corruption(元數(shù)據(jù)損壞) 模擬資源競(jìng)爭(zhēng)或版本元數(shù)據(jù)錯(cuò)誤 failure_point pre_load(加載前) post_unload(卸載后) 指定故障注入階段(加載前/卸載后) rollback_strategy auto_rollback(自動(dòng)回滾) manual_intervention(人工介入) 切換失敗后的恢復(fù)策略 retry_threshold 3(最大重試次數(shù)) 加載失敗后的自動(dòng)重試次數(shù) |
| 實(shí)時(shí)數(shù)據(jù)亂序 | 數(shù)據(jù)流因網(wǎng)絡(luò)延遲、分片傳輸錯(cuò)誤或消息隊(duì)列故障導(dǎo)致時(shí)序數(shù)據(jù)亂序,影響時(shí)間敏感型模型(如LSTM、Transformer)的預(yù)測(cè)準(zhǔn)確性。例如:時(shí)間窗口內(nèi)數(shù)據(jù)順序錯(cuò)亂、數(shù)據(jù)延遲超過(guò)模型允許的時(shí)序容忍度、亂序數(shù)據(jù)觸發(fā)模型狀態(tài)異常(如狀態(tài)機(jī)崩潰) | 參數(shù)項(xiàng) 可選值/示例 說(shuō)明 fault_type data_out_of_order 故障類(lèi)型(實(shí)時(shí)數(shù)據(jù)亂序) disorder_rate "30%" 亂序數(shù)據(jù)比例(如30%的數(shù)據(jù)順序被打亂) max_latency "5s" 最大延遲時(shí)間(模擬數(shù)據(jù)遲到) window_size 1000 受影響的時(shí)間窗口大小(單位:數(shù)據(jù)條目數(shù)或時(shí)間范圍) distribution uniform(均勻分布) burst(突發(fā)亂序) 亂序分布模式 |
| 模型精度下降 | 因輸入數(shù)據(jù)漂移、模型參數(shù)篡改或計(jì)算單元異常(如GPU浮點(diǎn)運(yùn)算錯(cuò)誤),導(dǎo)致模型預(yù)測(cè)精度顯著下降且未被監(jiān)控系統(tǒng)及時(shí)捕獲。例如:輸入數(shù)據(jù)分布偏移(如傳感器數(shù)據(jù)偏差)、模型權(quán)重文件被部分覆蓋或損壞、浮點(diǎn)計(jì)算靜默錯(cuò)誤(如CUDA核函數(shù)異常) | 參數(shù)項(xiàng)` 可選值/示例 說(shuō)明 fault_type model_accuracy_drop 故障類(lèi)型(模型精度下降) noise_level "10%" 輸入數(shù)據(jù)噪聲強(qiáng)度(如添加10%高斯噪聲) weight_corruption random(隨機(jī)擾動(dòng)) targeted(定向攻擊) 模型參數(shù)篡改方式 error_type float_error(浮點(diǎn)錯(cuò)誤) quantization(量化異常) 計(jì)算單元錯(cuò)誤類(lèi)型 detection_threshold 0.95(置信度閾值) 觸發(fā)告警的精度下降閾值(如置信度低于0.95時(shí)告警) |
| 多模型投票失效 | 在多模型投票決策系統(tǒng)中,因部分模型故障、通信中斷或投票邏輯缺陷,導(dǎo)致最終決策結(jié)果與真實(shí)多數(shù)投票結(jié)果不一致。如:?jiǎn)蝹€(gè)模型輸出異常(如返回空值或極端值)、投票結(jié)果聚合邏輯錯(cuò)誤(如加權(quán)投票權(quán)重未生效)、模型間通信超時(shí)或數(shù)據(jù)丟失 | 參數(shù)項(xiàng)` 可選值/示例 說(shuō)明 fault_type ensemble_voting_failure 故障類(lèi)型(多模型投票失效) failure_mode silent(靜默失敗) noisy(輸出噪聲) 模型故障類(lèi)型 target_models ["model_a", "model_c"] 指定需要注入故障的模型列表 communication_delay "2s" 模擬模型間通信延遲 voting_algorithm majority(多數(shù)表決) weighted(加權(quán)投票) 投票算法類(lèi)型(驗(yàn)證算法容錯(cuò)性) |
②自動(dòng)化工具鏈的升級(jí)
當(dāng)前的各類(lèi)工具主要依賴(lài)手動(dòng)配置,通過(guò)AI的引入使得工具能夠從以下幾個(gè)維度升級(jí)
| 自動(dòng)化配置點(diǎn) | 配置描述 |
| 智能選擇靶點(diǎn) | 基于系統(tǒng)拓?fù)浜拓?fù)載情況,優(yōu)先測(cè)試高風(fēng)險(xiǎn)的組件 |
| 生成實(shí)驗(yàn)劇本 | 結(jié)合強(qiáng)化學(xué)習(xí)模擬多故障疊加場(chǎng)景,如“同時(shí)觸發(fā)數(shù)據(jù)庫(kù)延遲與容器資源耗盡 |
| 自動(dòng)修復(fù)建議 | 根據(jù)實(shí)驗(yàn)結(jié)果推薦冗余設(shè)計(jì)或負(fù)載均衡策略 |
③應(yīng)用層故障注入的精細(xì)化
應(yīng)用級(jí)故障注入工具通過(guò)“坐標(biāo)系統(tǒng)”,精確定位實(shí)驗(yàn)范圍(如特定用戶(hù)或服務(wù)版本),而AI可進(jìn)一步擴(kuò)展這一能力。例如,通過(guò)自然語(yǔ)言處理解析日志,自動(dòng)生成針對(duì)特定API接口的異常返回規(guī)則
④場(chǎng)景擴(kuò)展
?智能化場(chǎng)景推薦
包括不限于,基于系統(tǒng)架構(gòu)特性、基于既往線(xiàn)上故障、基于系統(tǒng)核心指標(biāo)異動(dòng)的智能化場(chǎng)景推薦,具體而言:
| 智能化場(chǎng)景推薦 | 技術(shù)原理 | 設(shè)計(jì)方案 |
| 基于系統(tǒng)架構(gòu)特性的場(chǎng)景推薦 | ·拓?fù)浣Y(jié)構(gòu)分析: ·通過(guò)服務(wù)注冊(cè)中心(如Nacos、Consul)獲取微服務(wù)依賴(lài)關(guān)系,構(gòu)建系統(tǒng)調(diào)用拓?fù)鋱D。 ·使用**圖神經(jīng)網(wǎng)絡(luò)(GNN)**計(jì)算節(jié)點(diǎn)中心性(如介數(shù)中心性),識(shí)別核心鏈路(如“訂單創(chuàng)建→支付→庫(kù)存扣減”路徑)。 ·資源依賴(lài)建模: ·分析服務(wù)與底層資源(數(shù)據(jù)庫(kù)、緩存、消息隊(duì)列)的綁定關(guān)系,定位資源競(jìng)爭(zhēng)熱點(diǎn)(如多個(gè)服務(wù)共享同一Redis集群)。 | ·輸入:系統(tǒng)拓?fù)鋱D、服務(wù)QPS、資源使用率(如數(shù)據(jù)庫(kù)連接數(shù))。 ·算法: ·關(guān)鍵路徑識(shí)別:基于PageRank算法標(biāo)記高權(quán)重節(jié)點(diǎn)(如支付網(wǎng)關(guān))。 ·瓶頸預(yù)測(cè):結(jié)合資源水位預(yù)測(cè)模型(如ARIMA),推斷未來(lái)壓力點(diǎn)。 ·輸出: ·推薦實(shí)驗(yàn)場(chǎng)景: ·針對(duì)核心鏈路:模擬支付網(wǎng)關(guān)高延遲。 ·針對(duì)共享資源:注入Redis主節(jié)點(diǎn)宕機(jī)。 |
| 基于既往線(xiàn)上故障的場(chǎng)景推薦 | ·故障模式挖掘: ·對(duì)歷史故障日志進(jìn)行NLP解析(如BERT模型),提取故障類(lèi)型、影響范圍、修復(fù)措施。 ·使用**關(guān)聯(lián)規(guī)則挖掘(Apriori算法)**發(fā)現(xiàn)高頻故障組合(如“緩存雪崩+數(shù)據(jù)庫(kù)連接池耗盡”)。 ·時(shí)序模式分析: ·基于LSTM構(gòu)建故障時(shí)序模型,預(yù)測(cè)周期性風(fēng)險(xiǎn)(如大促前1小時(shí)庫(kù)存服務(wù)易出現(xiàn)超賣(mài))。 | ·輸入:歷史故障數(shù)據(jù)庫(kù)、修復(fù)記錄、時(shí)間戳。 ·算法: ·故障關(guān)聯(lián)圖譜:構(gòu)建故障-服務(wù)-資源的關(guān)聯(lián)網(wǎng)絡(luò)。 ·相似度匹配:通過(guò)余弦相似度匹配當(dāng)前系統(tǒng)狀態(tài)與歷史故障特征。 ·輸出: ·推薦實(shí)驗(yàn)場(chǎng)景: ·復(fù)現(xiàn)歷史高頻故障:優(yōu)惠券服務(wù)線(xiàn)程池滿(mǎn)。 ·預(yù)測(cè)性場(chǎng)景:模擬大促開(kāi)始后30分鐘的緩存擊穿。 |
| 基于系統(tǒng)核心指標(biāo)異動(dòng)的場(chǎng)景推薦 | ·動(dòng)態(tài)基線(xiàn)計(jì)算: ·使用Prophet時(shí)序模型預(yù)測(cè)指標(biāo)正常范圍(如日常CPU使用率40%→大促期間允許80%)。 ·多維度異常檢測(cè): ·通過(guò)**多變量自編碼器(MAE)**分析指標(biāo)組合異常(如“CPU 85% + 數(shù)據(jù)庫(kù)鎖等待數(shù)激增”)。 | ·輸入:實(shí)時(shí)監(jiān)控指標(biāo)流(Prometheus)、業(yè)務(wù)日志(ELK)。 ·算法: ·異常模式聚類(lèi):對(duì)異常事件進(jìn)行K-means聚類(lèi),識(shí)別典型模式(如“突增流量型”“資源泄漏型”)。 ·根因映射:將異常模式映射至預(yù)設(shè)故障場(chǎng)景庫(kù)。 ·輸出: ·推薦實(shí)驗(yàn)場(chǎng)景: ·當(dāng)檢測(cè)到訂單服務(wù)延遲突增時(shí),推薦測(cè)試“庫(kù)存服務(wù)緩存失效”。 ·當(dāng)數(shù)據(jù)庫(kù)鎖等待數(shù)超標(biāo)時(shí),推薦測(cè)試“分布式鎖服務(wù)故障”。 |
?云原生與邊緣計(jì)算
在動(dòng)態(tài)的云原生環(huán)境中,AI可預(yù)測(cè)容器編排(如Kubernetes)的故障恢復(fù)效率,并驗(yàn)證自動(dòng)擴(kuò)縮容策略的有效性。
?跨學(xué)科復(fù)雜系統(tǒng)模擬
混沌實(shí)驗(yàn)的理念正被引入生物、氣候等復(fù)雜系統(tǒng)研究。例如,南京大學(xué)團(tuán)隊(duì)利用AI模擬元古宙生命演化中的“雪球地球”事件對(duì)生物多樣性的沖擊這種“環(huán)境混沌實(shí)驗(yàn)”為評(píng)估極端條件下的系統(tǒng)韌性提供了新范式。
隨著AI技術(shù)的不斷發(fā)展和應(yīng)用場(chǎng)景的落地實(shí)施,混沌實(shí)驗(yàn)正從“被動(dòng)容災(zāi)”轉(zhuǎn)向“主動(dòng)韌性構(gòu)建”,其核心是通過(guò)智能算法提升實(shí)驗(yàn)的精準(zhǔn)度與系統(tǒng)自愈能力。未來(lái),隨著AI與量子計(jì)算、生物模擬等領(lǐng)域的交叉,混沌實(shí)驗(yàn)或?qū)⑼黄乒こ谭懂牐蔀樘剿鲝?fù)雜系統(tǒng)普適規(guī)律的科學(xué)工具。
6、【積微成著】專(zhuān)業(yè)分享
??【積微成著】性能測(cè)試調(diào)優(yōu)實(shí)戰(zhàn)與探索(存儲(chǔ)模型優(yōu)化+調(diào)用鏈路分析):http://xingyun.jd.com/shendeng/article/detail/24444?forumId=174&jdme_router=jdme://web/202206081297?url%3Dhttp%3A%2F%2Fsd.jd.com%2Farticle%2F24444?
??【積微成著】規(guī)模化混沌工程體系建設(shè)及AI融合探索:http://xingyun.jd.com/shendeng/article/detail/44438?forumId=99&jdme_router=jdme://web/202206081297?url%3Dhttp%3A%2F%2Fsd.jd.com%2Farticle%2F44438?
??【積微成著】“泰山變更管控”在物流技術(shù)的深入實(shí)踐:http://xingyun.jd.com/shendeng/article/detail/45193?forumId=1414&jdme_router=jdme%3A%2F%2Fweb%2F202206081297%3Furl%3Dhttp%3A%2F%2Fsd.jd.com%2Farticle%2F45193
審核編輯 黃宇
-
監(jiān)控
+關(guān)注
關(guān)注
6文章
2311瀏覽量
56965 -
AI
+關(guān)注
關(guān)注
88文章
34588瀏覽量
276150 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3905瀏覽量
65876 -
分布式系統(tǒng)
+關(guān)注
關(guān)注
0文章
147瀏覽量
19577
發(fā)布評(píng)論請(qǐng)先 登錄
廣和通加速5G+AI規(guī)模化應(yīng)用
軟通動(dòng)力中標(biāo)艾比森AI創(chuàng)新中心平臺(tái)升級(jí)項(xiàng)目
IBM如何加速企業(yè)AI規(guī)模化應(yīng)用
NVIDIA助力安利生成式AI在效能和安全上破局
AI智能體規(guī)模化應(yīng)用前夜:英偉達(dá)NeMo Guardrails筑牢安全防線(xiàn)
易控智駕礦山無(wú)人駕駛規(guī)模化應(yīng)用兩項(xiàng)關(guān)鍵技術(shù)獲評(píng)國(guó)際領(lǐng)先
廣汽埃安攜手小馬智行打造Robotaxi規(guī)模化量產(chǎn)車(chē)型
東軟集團(tuán)助力藥品智慧監(jiān)管體系建設(shè)
蔚來(lái)能源武漢制造中心規(guī)模化量產(chǎn)
江波龍自研主控芯片實(shí)現(xiàn)規(guī)模化導(dǎo)入
高通中國(guó)區(qū)董事長(zhǎng)孟樸:5G與AI的融合正加速企業(yè)數(shù)字化轉(zhuǎn)型步伐
2024快應(yīng)用智慧服務(wù)生態(tài)白皮書(shū)發(fā)布,探索AI與快應(yīng)用融合之路
東土科技自主研發(fā)的人工智能交通服務(wù)器實(shí)現(xiàn)規(guī)模化應(yīng)用
IBM加速AI規(guī)模化應(yīng)用,解鎖企業(yè)新質(zhì)生產(chǎn)力

IBM陳旭東:攜手IBM加速 AI 規(guī)模化應(yīng)用,解鎖企業(yè)新質(zhì)生產(chǎn)力






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論