") SiFive Intelligence X280數(shù)據(jù)手冊(cè)和詳細(xì)解讀
SiFive Intelligence X280數(shù)據(jù)手冊(cè)和詳細(xì)解讀

作為RISC-V生態(tài)中首款面向高性能AI/ML場(chǎng)景的處理器IP,SiFive Intelligence X280通過(guò)開(kāi)放架構(gòu)、多引擎協(xié)同設(shè)計(jì)及靈活的擴(kuò)展能力,成為數(shù)據(jù)中心、邊緣計(jì)算和汽車電子等領(lǐng)域的創(chuàng)新解決方案。以下從技術(shù)架構(gòu)、核心特性、應(yīng)用場(chǎng)景及行業(yè)影響四個(gè)維度展開(kāi)分析:
*附件:x280-datasheet.pdf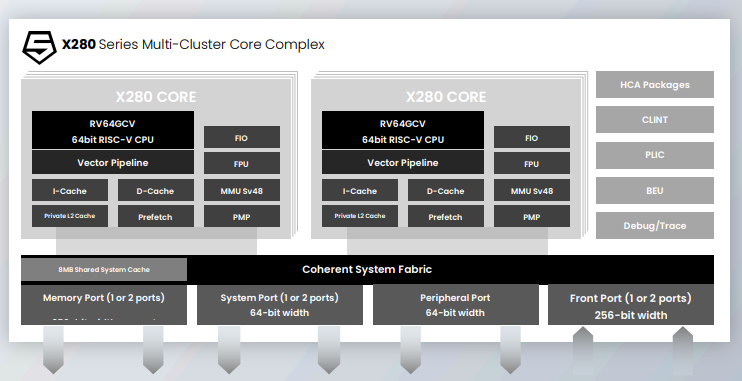
一、技術(shù)架構(gòu)與核心特性
- 多引擎協(xié)同計(jì)算架構(gòu)
X280采用 標(biāo)量(RV64GC)、矢量(RVV 1.0)、矩陣(MXU)三引擎融合設(shè)計(jì) ,支持混合精度運(yùn)算(INT8/BF16/FP16)。標(biāo)量引擎處理控制邏輯,矢量引擎執(zhí)行并行計(jì)算,矩陣引擎加速深度學(xué)習(xí)中的矩陣乘法。通過(guò) VCIX(矢量協(xié)處理器接口擴(kuò)展) ,外部加速器可直接訪問(wèn)X280的矢量寄存器文件,實(shí)現(xiàn)低延遲數(shù)據(jù)交互(僅需數(shù)十周期),避免傳統(tǒng)PCIe或內(nèi)存?zhèn)鬏數(shù)钠款i。 - 可擴(kuò)展性與內(nèi)存優(yōu)化
? 多集群架構(gòu) :支持16核緩存一致集群(Cache-Coherent Complex),單集群提供1TB/s持續(xù)內(nèi)存帶寬,并可通過(guò)CHI協(xié)議擴(kuò)展至多集群,滿足大模型推理需求。
? 高效緩存設(shè)計(jì) :私有L1/L2緩存與共享L3緩存結(jié)合,優(yōu)化數(shù)據(jù)流管理,減少冗余內(nèi)存訪問(wèn)。例如,在MobileNet推理任務(wù)中,X280的智能擴(kuò)展指令可實(shí)現(xiàn)標(biāo)量ISA的144倍加速。 - 安全與軟件生態(tài)
? WorldGuard可信執(zhí)行環(huán)境 :提供ASIL-D級(jí)功能安全支持,適用于汽車電子等高可靠性場(chǎng)景。
? 開(kāi)源軟件棧 :兼容PyTorch/TensorFlow框架,集成SiFive Kernel Library(SKL)和OpenXLA PJRT Runtime,簡(jiǎn)化異構(gòu)加速器編程。
二、性能表現(xiàn)與能效優(yōu)勢(shì)
? 算力密度 :?jiǎn)魏诵阅苓_(dá)4.5 SpecINT2k6/GHz(HiPerf配置),支持每GHz 16 TOPS(INT8)或8 TFLOPS(BF16),適用于高吞吐量邊緣推理。
? 能效比 :相較傳統(tǒng)GPU,X280在同等算力下功耗降低30%以上,尤其適合自動(dòng)駕駛和物聯(lián)網(wǎng)設(shè)備的低功耗需求。
? 靈活性 :支持動(dòng)態(tài)矢量長(zhǎng)度調(diào)整(512位寄存器可組合至4096位),優(yōu)化長(zhǎng)向量運(yùn)算效率,降低芯片面積與功耗。
SiFive Intelligence
X280 Key Features
- SiFive Intelligence Extensions for ML workloads
- Custom instructions to greatly accelerate Neural Network computation
- Optimized TensorFlow Lite implementation
- Hundreds of Neural Network models ported
- 4.6 TOPS performance
- 512-bit vector register length processor
- Performance benchmarks
- 5.75 CoreMarks/MHz
- 3.25 DMIPS/MHz
- 4.6 SpecINT2k6/GHz
- Built on silicon-proven U7-Series core
- High performance vector memory subsystem
- Memory parallelism provides cache miss tolerance
- Virtual memory support with precise exceptions
- Up to 48-bit addressing
- Multi-core, multi-cluster processor configuration, up to 8 cores
三、應(yīng)用場(chǎng)景與典型案例
- 數(shù)據(jù)中心AI加速
谷歌采用X280作為TPU的配套管理節(jié)點(diǎn),通過(guò)VCIX接口連接自研MXU(脈動(dòng)矩陣乘法器),實(shí)現(xiàn)AI負(fù)載的靈活分配。X280負(fù)責(zé)運(yùn)行Linux系統(tǒng)和管理代碼,MXU加速核心計(jì)算,兩者協(xié)同提升大語(yǔ)言模型(如Llama)的推理效率。 - 邊緣計(jì)算與消費(fèi)電子
? 智能攝像頭/AR設(shè)備 :X280的矢量單元可實(shí)時(shí)處理圖像識(shí)別與語(yǔ)音交互,例如在MobileNet任務(wù)中實(shí)現(xiàn)24倍于標(biāo)量架構(gòu)的加速。
? 汽車電子 :車規(guī)級(jí)X280-A版本支持ADAS系統(tǒng)的實(shí)時(shí)目標(biāo)檢測(cè),符合ISO 26262 ASIL-D標(biāo)準(zhǔn),已被多家Tier 1供應(yīng)商采用。 - 異構(gòu)計(jì)算平臺(tái)
X280與SiFive P系列CPU(如P870)組成混合架構(gòu),對(duì)標(biāo)Arm big.LITTLE設(shè)計(jì),適用于數(shù)據(jù)中心的高效任務(wù)調(diào)度與能效優(yōu)化。
四、行業(yè)影響與未來(lái)趨勢(shì)
- 挑戰(zhàn)傳統(tǒng)架構(gòu)壟斷
X280的開(kāi)放生態(tài)吸引谷歌、特斯拉等企業(yè)替代NVIDIA GPU或Arm方案。例如,谷歌放棄自研TPU管理核心,轉(zhuǎn)而采用X280+VCIX架構(gòu),節(jié)省開(kāi)發(fā)周期并提升靈活性。 - 推動(dòng)RISC-V進(jìn)入高性能市場(chǎng)
此前RISC-V多用于MCU場(chǎng)景,而X280通過(guò)矢量擴(kuò)展與多核集群設(shè)計(jì),將應(yīng)用擴(kuò)展至數(shù)據(jù)中心和自動(dòng)駕駛,縮小與x86/Arm在高性能計(jì)算領(lǐng)域的差距。 - 生態(tài)合作與標(biāo)準(zhǔn)化
SiFive與谷歌合作推進(jìn)RISC-V對(duì)Android的兼容性,同時(shí)參與制定RISC-V UEFI、SBI等規(guī)范,加速生態(tài)成熟。
總結(jié)
SiFive Intelligence X280憑借開(kāi)放架構(gòu)、多引擎協(xié)同、高能效比三大核心優(yōu)勢(shì),成為RISC-V生態(tài)沖擊AI芯片市場(chǎng)的里程碑產(chǎn)品。其與谷歌TPU的深度整合、車規(guī)級(jí)安全特性及靈活擴(kuò)展能力,不僅驗(yàn)證了RISC-V在高性能場(chǎng)景的可行性,更推動(dòng)了從邊緣到云端全棧AI計(jì)算的范式革新。隨著生成式AI與自動(dòng)駕駛需求激增,X280或?qū)⒊蔀橄乱淮悩?gòu)計(jì)算平臺(tái)的關(guān)鍵組件。
-
數(shù)據(jù)手冊(cè)
+關(guān)注
關(guān)注
95文章
6205瀏覽量
43715 -
RISC-V
+關(guān)注
關(guān)注
46文章
2574瀏覽量
48855
發(fā)布評(píng)論請(qǐng)先 登錄
芯海mcu有更詳細(xì)的數(shù)據(jù)手冊(cè)嗎?
RK3588參數(shù)與主要特性 RK3588數(shù)據(jù)手冊(cè)解讀

面向AI與機(jī)器學(xué)習(xí)應(yīng)用的開(kāi)發(fā)平臺(tái) AMD/Xilinx Versal? AI Edge VEK280
開(kāi)源的AI MPU
EE-280:基于ADSP-2106x SHARC處理器的在線閃存編程

TMS320x280x、2801x、2804x DSP引導(dǎo)ROM參考指南
TMS320x280x 2801x、2804x 模數(shù)轉(zhuǎn)換器(ADC)模塊參考指南
TMS320x280x、2801x、2804x DSP系統(tǒng)控制和中斷參考指南
TMS320x280x、2801x、2804x內(nèi)部集成電路(I2C)參考指南
將TMS320x280x中的eQEP模塊用作專用捕獲
將PWM輸出用作TMS320F280x上的數(shù)模轉(zhuǎn)換器
從TMS320x281x遷移到TMS320x280x/2801x/2804x
SiFive發(fā)布MX系列高性能AI加速器IP
TMS320F280x、TMS320C280x、TMS320F2801x數(shù)字信號(hào)處理器數(shù)據(jù)表
TMS320F280x、TMS320C280x、TMS320F2801x數(shù)字信號(hào)處理器數(shù)據(jù)表





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論