 大算力芯片的生態突圍與算力革命
大算力芯片的生態突圍與算力革命

電子發燒友網報道(文 / 李彎彎)大算力芯片,即具備強大計算能力的集成電路芯片,主要應用于高性能計算(HPC)、人工智能(AI)、數據中心、自動駕駛等需要海量數據并行計算的場景。隨著 AI 與大數據的爆發式增長,大算力芯片已成為科技競爭的核心領域之一。
大算力芯片的核心應用場景豐富多樣。在人工智能訓練與推理方面,大模型(如 GPT、Llama)的訓練需要超大規模算力(例如千億參數級),通常依賴 GPU(如 NVIDIA H100)或專用 AI 芯片(如 Google TPU)。在邊緣計算領域,自動駕駛、智能攝像頭等場景需要本地化實時處理,這就需要低功耗高算力芯片(如特斯拉 Dojo)。數據中心與云計算領域,通過提供分布式計算資源,支撐搜索引擎、推薦系統等,常用 CPU+GPU/FPGA 異構方案(如 AMD EPYC + NVIDIA A100)。而科學計算與仿真,像氣候模擬、核聚變研究、基因測序等,都需要超算中心的大算力支持(如基于 ARM 的 Fugaku 超算)。
大算力芯片具有幾大典型技術特點。其一為高算力密度,借助多核架構、并行計算以及專用加速單元(如矩陣運算單元),可實現每秒數萬億次甚至千萬億次浮點運算(TFLOPS/PFLOPS)。其二是采用先進制程工藝,運用 3nm/2nm 等先進制程,提升晶體管密度與能效比。其三為芯片間互連技術,如 NVLink、Infinity Fabric 等,能實現多芯片高速互連,構建超大規模計算集群。
主流大算力芯片類型眾多。GPU 方面,有 NVIDIA H100/A100、AMD MI300X 等產品,其優勢在于并行計算能力強,適合矩陣運算(用于 AI 訓練 / 推理)。TPU 是 Google 專為 AI 設計的,采用脈動陣列架構(TPU v4 相比 v3 速度提升 2.1 倍)。FPGA 可編程靈活性強(如 Xilinx Versal 用于 5G 和邊緣 AI)。ASIC 即專用芯片,例如華為昇騰 910(256TOPS@INT8)、寒武紀 MLU370。還有 CPU + 加速器異構方案,如 Intel Sapphire Rapids(集成 AI 加速模塊 AMX)。
從市場競爭格局來看,國際上主要廠商包括英偉達(在 GPU 市場占據主導地位)、AMD(采用 CPU+GPU 融合架構)、英特爾(涉足 FPGA 與 AI 芯片)、谷歌(推出 TPU 定制芯片)。國內廠商則主要有華為昇騰、寒武紀(專注云端 AI 芯片)、壁仞科技(研發通用 GPU)、天數智芯(研發 GPGPU) 。
目前,大算力芯片面臨諸多技術挑戰。算力提升的同時功耗激增(如單顆 H100 功耗達 700W),因此需要液冷等先進散熱技術。算力增長速度快于內存帶寬,這就需要 HBM/Chiplet 技術實現突破。先進制程依賴臺積電 / 三星,地緣政治因素影響著供應鏈安全。此外,CUDA 生態主導市場,其他架構(如 ROCm、OpenCL)還有待追趕。
就當前發展態勢而言,大算力芯片呈現出幾個技術發展趨勢。Chiplet 技術通過小芯片異構集成,降低成本并提升良率。光電融合方面,光計算芯片探索超低功耗方案。從長遠看,量子計算可能顛覆傳統算力范式。同時,中國也將加速國產替代進程。
總的來說,大算力芯片是數字經濟的核心引擎,其技術突破將深刻影響人工智能、自動駕駛、科學計算等領域的未來發展。中國廠商需要在生態建設、制程工藝以及軟件工具鏈等方面持續投入,以縮小與國際巨頭的差距。?
大算力芯片的核心應用場景豐富多樣。在人工智能訓練與推理方面,大模型(如 GPT、Llama)的訓練需要超大規模算力(例如千億參數級),通常依賴 GPU(如 NVIDIA H100)或專用 AI 芯片(如 Google TPU)。在邊緣計算領域,自動駕駛、智能攝像頭等場景需要本地化實時處理,這就需要低功耗高算力芯片(如特斯拉 Dojo)。數據中心與云計算領域,通過提供分布式計算資源,支撐搜索引擎、推薦系統等,常用 CPU+GPU/FPGA 異構方案(如 AMD EPYC + NVIDIA A100)。而科學計算與仿真,像氣候模擬、核聚變研究、基因測序等,都需要超算中心的大算力支持(如基于 ARM 的 Fugaku 超算)。
大算力芯片具有幾大典型技術特點。其一為高算力密度,借助多核架構、并行計算以及專用加速單元(如矩陣運算單元),可實現每秒數萬億次甚至千萬億次浮點運算(TFLOPS/PFLOPS)。其二是采用先進制程工藝,運用 3nm/2nm 等先進制程,提升晶體管密度與能效比。其三為芯片間互連技術,如 NVLink、Infinity Fabric 等,能實現多芯片高速互連,構建超大規模計算集群。
主流大算力芯片類型眾多。GPU 方面,有 NVIDIA H100/A100、AMD MI300X 等產品,其優勢在于并行計算能力強,適合矩陣運算(用于 AI 訓練 / 推理)。TPU 是 Google 專為 AI 設計的,采用脈動陣列架構(TPU v4 相比 v3 速度提升 2.1 倍)。FPGA 可編程靈活性強(如 Xilinx Versal 用于 5G 和邊緣 AI)。ASIC 即專用芯片,例如華為昇騰 910(256TOPS@INT8)、寒武紀 MLU370。還有 CPU + 加速器異構方案,如 Intel Sapphire Rapids(集成 AI 加速模塊 AMX)。
從市場競爭格局來看,國際上主要廠商包括英偉達(在 GPU 市場占據主導地位)、AMD(采用 CPU+GPU 融合架構)、英特爾(涉足 FPGA 與 AI 芯片)、谷歌(推出 TPU 定制芯片)。國內廠商則主要有華為昇騰、寒武紀(專注云端 AI 芯片)、壁仞科技(研發通用 GPU)、天數智芯(研發 GPGPU) 。
目前,大算力芯片面臨諸多技術挑戰。算力提升的同時功耗激增(如單顆 H100 功耗達 700W),因此需要液冷等先進散熱技術。算力增長速度快于內存帶寬,這就需要 HBM/Chiplet 技術實現突破。先進制程依賴臺積電 / 三星,地緣政治因素影響著供應鏈安全。此外,CUDA 生態主導市場,其他架構(如 ROCm、OpenCL)還有待追趕。
就當前發展態勢而言,大算力芯片呈現出幾個技術發展趨勢。Chiplet 技術通過小芯片異構集成,降低成本并提升良率。光電融合方面,光計算芯片探索超低功耗方案。從長遠看,量子計算可能顛覆傳統算力范式。同時,中國也將加速國產替代進程。
總的來說,大算力芯片是數字經濟的核心引擎,其技術突破將深刻影響人工智能、自動駕駛、科學計算等領域的未來發展。中國廠商需要在生態建設、制程工藝以及軟件工具鏈等方面持續投入,以縮小與國際巨頭的差距。?
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
生態
+關注
關注
0文章
25瀏覽量
9040 -
算力芯片
+關注
關注
0文章
54瀏覽量
4809
發布評論請先 登錄
相關推薦
熱點推薦
【一文看懂】什么是端側算力?
隨著物聯網(IoT)、人工智能和5G技術的快速發展,端側算力正逐漸成為智能設備性能提升和智能化應用實現的關鍵技術。什么是端側算力,它的應用價值是什么,與云計算、邊緣計算有哪些區別?本文

DeepSeek對芯片算力的影響
DeepSeek模型,尤其是其基于MOE(混合專家)架構的DeepSeek-V3,對芯片算力的要求產生了深遠影響。為了更好地理解這一影響,我們可以從幾個方面進行分析。一.MOE架構對算


算智算中心的算力如何衡量?
作為當下科技發展的重要基礎設施,其算力的衡量關乎其能否高效支撐人工智能、大數據分析等智能應用的運行。以下是對智算中心算力衡量的詳細闡述:一、算
杰和課堂|帶你認識算力
杰和課堂|帶你認識算力人工智能浪潮洶涌的今天,算力一詞頻繁出現在各類科技新聞、產業發展報告中。了解過杰和科技產品的讀者們,也會在杰和各產品參數中發現算

算力調度的基礎知識
編者按 “算力調度”的概念,這幾年越來越多的被提及。剛聽到這個概念的時候,我腦海里一直拐不過彎。作為底層芯片出身的我,一直認為:算力是硬件的

算力基礎篇:從零開始了解算力
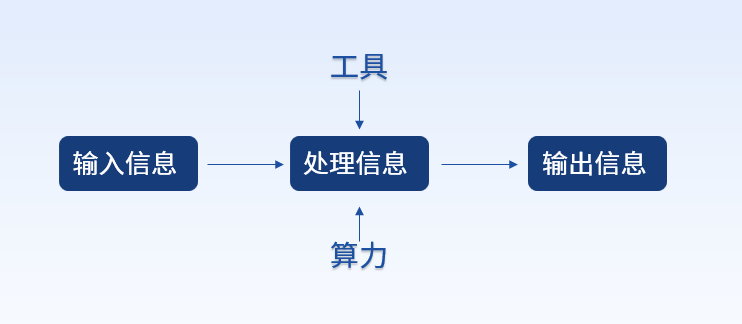
算力即計算能力(Computing Power),狹義上指對數字問題的運算能力,而廣義上指對輸入信息處理后實現結果輸出的一種能力。雖然處理的內容不同,但處理過程的能力都可抽象為算力。比
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
本帖最后由 1653149838.791300 于 2024-10-16 22:19 編輯
感謝平臺提供的書籍,厚厚的一本,很有分量,感謝作者的傾力付出成書。
本書主要講算力芯片CPU
發表于 10-15 22:08
燧弘華創助力慶陽構建算力產業生態
構建AI全產業鏈生態方面的顯著成就,榮獲“全國一體化算力網絡國家樞紐節點(甘肅·慶陽)首批萬P算力建設成果突出貢獻企業”的殊榮。在啟動儀式上
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
試用評測資格!
前言
不知不覺中,我們來到一個計算機科學飛速發展的時代,手機和計算機中各類便捷的軟件已經融入日常生活,在此背景下,硬件特別是算力強勁的芯片,對于軟件服務起到不可替代的支撐作用。
發表于 09-02 10:09
大模型時代的算力需求
現在AI已進入大模型時代,各企業都爭相部署大模型,但如何保證大模型的算力,以及相關的穩定性和性能,是一個極為重要的問題,帶著這個極為重要的問題,我需要在此書中找到答案。
發表于 08-20 09:04
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
近日,中國信通院公布首個《算力服務產業圖譜(2024年)》及《算力服務產品名錄(2024年)》。曙光智算構建的全國一體化





 工商網監
工商網監
評論