 嵌入式神經網絡賦予人工智能視覺、聽覺和分析能力
嵌入式神經網絡賦予人工智能視覺、聽覺和分析能力

人工智能(AI)潛在的應用與日俱增。不同的神經網絡(NN)架構能力經過測試、調整和改進,解決了不同的問題,也開發出以AI優化數據分析的各種方法。當今大部份的AI應用,例如Google翻譯(Google Translate)和亞馬遜(Amazon) Alexa語音識別和視覺識別系統,都利用了云端的力量。
藉由依賴常時連網(always-on)的因特網聯機、高帶寬鏈路和網絡服務,物聯網(IoT)產品和智能手機應用也可以整合AI功能。到目前為止,大部份的注意力都集中在基于視覺的人工智能上,部份原因在于它易于出現在新聞報導和視頻中,另外一部份的原因則是它更類似于人類的活動。
在影像識別中,針對一個2D影像進行分析——每次處理一組像素,透過神經網絡的連續層識別更大的特征點。一開始檢測到的邊緣是具有高對比度差異的部份。以人臉為例,最早識別的部位是在眼睛、鼻子和嘴巴等特征外圍。隨著檢測過程深入神經網絡,將會檢測到整個臉部的特征。
而在最后階段,結合這些特征及其位置信息,就能在可用的數據庫中識別到具有最匹配的一張特定人臉。
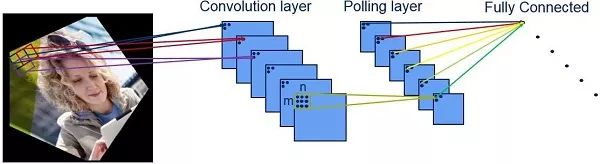
神經網絡的特征提取
為了匹配經由相機拍攝或擷取的物體,希望能透過神經網絡在其數據庫中找到匹配機率最高的人臉。其巧妙之處在于擷取物體時并不需要與數據庫中的照片拍攝角度或場景完全相同,也不必處于相同的光線條件下。
AI這么快就流行起來,在很大程度上是因為開放的軟件工具(也稱為架構),使得建構和訓練神經網絡實現目標應用變得容易起來,即使是使用各種不同的編程語言。兩個常見的通用架構是TensorFlow和Caffe。對于已知的識別目標,可以脫機定義和訓練神經網絡。一旦訓練完成,神經網絡就可以很容易地部署到嵌入式平臺上。這是一種很聰明的劃分方式,能夠藉由開發PC或云端的力量來訓練神經網絡,而功耗敏感的嵌入式處理器只需為了識別目的而使用訓練數據。
這種類似人類的人/物識別能力與流行的應用密切相關,例如工業機器人和自動駕駛車。然而,人工智能在音頻領域同樣具有吸引力和強大的能力。它采用和影像特征分析同樣的方式,可以將音頻分解成特征點而饋入神經網絡。其中一種方法是使用梅爾頻率倒譜系數(MFCC)將音頻分解成有用的特性。一開始,音頻樣本被分解成短時間的訊框,例如20ms,然后再對信號進行傅利葉轉換(Fourier transforms),使用重迭三角窗將音頻頻譜的功率映像到非線性尺度上。
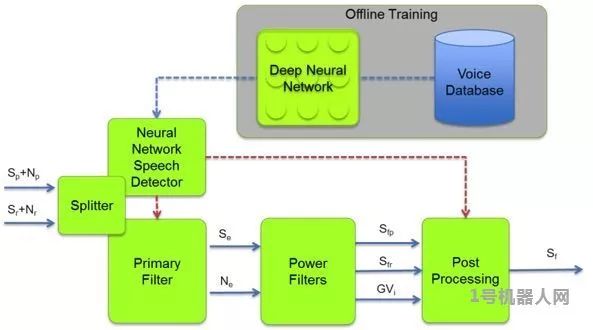
聲音神經網絡分解圖
透過這些提取的特征,神經網絡可以用來確定音頻樣本和音頻樣本數據庫中詞匯或者語音的相似度。就像影像識別一樣,神經網絡為特定詞匯在數據庫中提取了可能的匹配。對于那些想要復制Google和亞馬遜的‘OK Google’或‘Alexa’語音觸發(VT)功能的業者來說,KITT.AI透過Snowboy提供了一個解決方案。觸發關鍵詞可以上傳到他們的平臺進行分析,導出一個檔案后再整合進嵌入式平臺上的Snowboy應用程序,這樣語音觸發(VT)的關鍵詞在脫機情況下也可以被檢測到。音頻識別并不局限于語言識別。TensorFlow提供了一個iOS上的示例,可以區分男性和女性的聲音。
另一個替代應用是檢測我們居住的城市和住宅周圍動物和其他聲音。這已經由安裝在英國倫敦伊麗莎白女王奧林匹克公園(Queen Elizabeth Olympic Park)的深度學習蝙蝠監控系統驗證過了。它提供了將視覺和聽覺識別神經網絡整合于一個平臺的可能性。例如透過音頻識別別特定的聲音,可以用來觸發安全系統進行錄像。
有很多基于云端的AI應用是不實際的,一方面存在數據隱私的問題,另一方面由于數據連接性差或帶寬不夠造成服務不能持續。另外,實時性能也是一個值得關注的問題。例如工業制造系統需要實時響應,以便實時操作生產線,如果連接云端服務的延遲就太長了。
因此,將AI功能移動到“邊緣”(edge)越來越受到關注。也就是說,在使用中的裝置上發揮人工智能的力量。很多IP供貨商都提供了解決方案,如CEVA的CEVA-X2和NeuPro IP核心和配套軟件,都很容易和現有的神經網絡架構進行整合。這為開發具備人工智能的嵌入式系統提供了可能性,同時提供了低功耗處理器的靈活性。以一個語音識別系統為例,可以利用整合在芯片上的功耗優化人工智能,以識別一個語音觸發關鍵詞和語音命令(VC)的最小化組合。更復雜的語音命令和功能,可以在應用從低功耗的語音觸發狀態下喚醒之后,由基于云端的AI完成。
最后,卷積神經網絡(CNN)也可以用來提高文本到語音(TTS)系統的質量。一直以來,TTS用于將同一個配音員的許多高質量錄音片段,整合成連續的聲音。雖然所輸出的結果是人類可以理解的,但由于輸出結果存在奇怪的語調和音調,仍然感覺像是機器人的聲音。如果試圖表現出不同的情緒則需要一組全新的錄音。Google的WaveNet改善了當前的情況,透過CNN以每秒16,000個樣本產生TTS波形。與之前的聲音樣本相比,其輸出結果是無縫連接的,明顯表現出更自然、更高質量的聲音。
-
嵌入式
+關注
關注
5148文章
19645瀏覽量
317021 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103439 -
人工智能
+關注
關注
1806文章
48984瀏覽量
248904
原文標題:嵌入式神經網絡賦予機器視覺、聽覺和分析能力
文章出處:【微信號:robot-1hjqr,微信公眾號:1號機器人網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「芯片通識課:一本書讀懂芯片技術」閱讀體驗】從deepseek看今天芯片發展
BP神經網絡的優缺點分析
人工神經網絡的原理和多種神經網絡架構方法

RT-Thread Smart 嵌入式人工智能師資培訓通知


嵌入式和人工智能究竟是什么關系?
Moku人工神經網絡101

如何利用FPGA技術革新視覺人工智能應用?






 工商網監
工商網監
評論