") 基于1.35M Instance設(shè)計的GPU加速實例
基于1.35M Instance設(shè)計的GPU加速實例

CPU是計算機的核心部件,由運算器、控制器、寄存器組和內(nèi)部總線等部分組成。常見的x86架構(gòu)CPU核心數(shù)相對較少,一般在8 - 32核左右,主要是為了解決復(fù)雜的邏輯運算和順序執(zhí)行指令的任務(wù)。它在處理單線程任務(wù)時效率很高,能夠快速執(zhí)行復(fù)雜的指令集,例如進(jìn)行數(shù)學(xué)計算、程序的流程控制等操作。
GPU最初是為了圖形渲染而設(shè)計的,其架構(gòu)與CPU有很大不同,采用了大規(guī)模并行架構(gòu)。以英偉達(dá)的CUDA架構(gòu)為例,它擁有成千上萬個CUDA核心,這些核心可以同時處理多個任務(wù)。例如,在深度學(xué)習(xí)中,GPU可以加速神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程,因為神經(jīng)網(wǎng)絡(luò)的訓(xùn)練涉及大量的矩陣運算,這些運算可以并行處理,GPU的并行架構(gòu)能夠大大縮短訓(xùn)練時間。近兩年,GPU也成為EDA(電子設(shè)計自動化)加速的技術(shù)熱點。
在數(shù)字SoC芯片的設(shè)計和實現(xiàn)中,為了達(dá)到功能、性能、功耗和面積目標(biāo),芯片設(shè)計者通常需要進(jìn)行多輪次的迭代和優(yōu)化。數(shù)字后端實現(xiàn)環(huán)節(jié)由于涉及的數(shù)據(jù)規(guī)模龐大且迭代次數(shù)多,基于CPU的計算耗時相當(dāng)長。一般來說,一個后端設(shè)計大概需要半年左右的時間,以一個10M Instance規(guī)模的模塊設(shè)計為例,基于常見的x86_64架構(gòu)、16核×128CPU、2.8G主頻的服務(wù)器運行數(shù)字后端各項任務(wù),每輪時長大約為:布局(Place)75小時、時鐘樹綜合(CTS)45小時、時鐘優(yōu)化(CTSopt)45小時、布線(Route)35小時、布線優(yōu)化(RouteOpt)60小時。如果能夠有效利用GPU的并行計算能力,將對芯片設(shè)計的加速非常有幫助。
芯行紀(jì)自主研發(fā)的新一代數(shù)字實現(xiàn)解決方案,通過適配GPU的環(huán)境,使用GPU為自研布局布線軟件AmazeSys進(jìn)行了加速,并且獲得了可觀的加速效果。以下是一個基于1.35M Instance設(shè)計的GPU加速實例,運行方案如下:
僅使用CPU,啟用31個CPU線程
使用CPU和GPU,啟用31個CPU線程和1個GPU (3584 CUDA cores)

圖1:機器配置
從圖2可以看到,通過啟用1個GPU,placement各個主要階段得到了5到20倍不等的加速比。
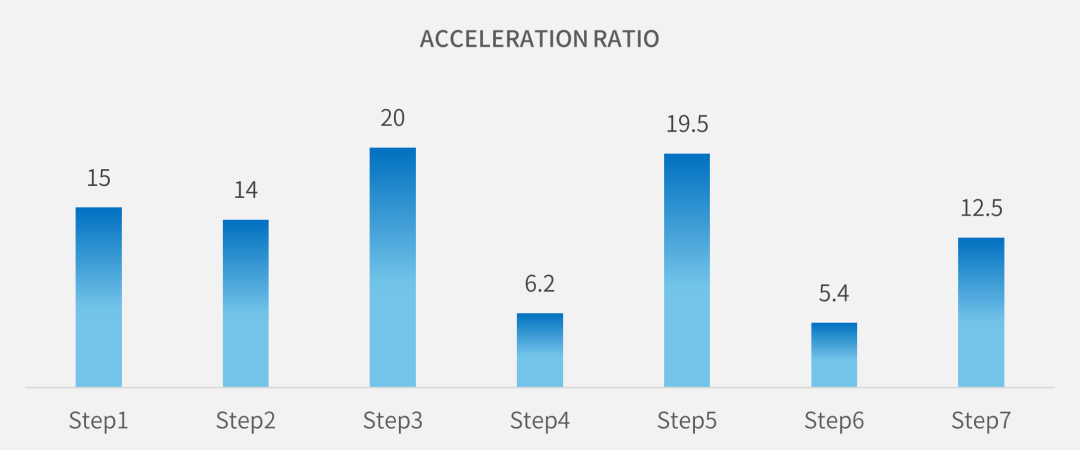
圖2:Placement過程中的加速比
從圖3可以看到,使用兩種方案的wire length基本持平, GPU加速時雖然overflow略有增加,但總體獲得了9.1倍加速的效果。并且,當(dāng)GPU數(shù)量增加、性能增強,加速比也將會繼續(xù)增大。
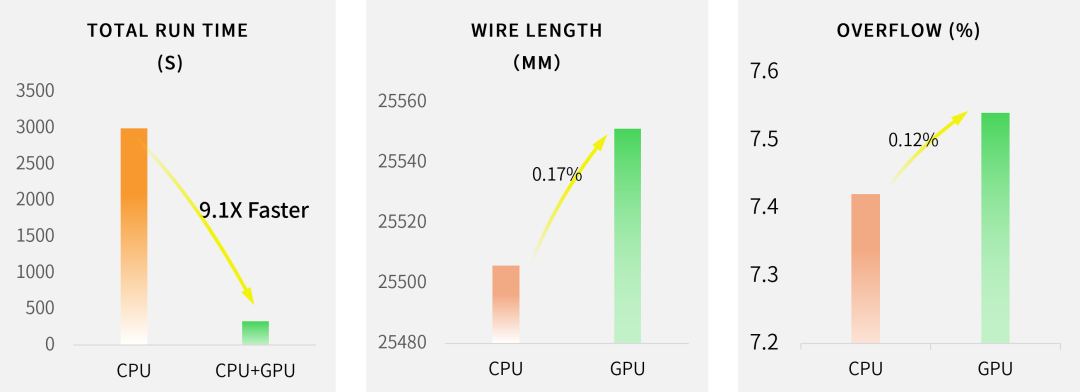
圖3:使用GPU加速的結(jié)果
數(shù)字布局布線涉及的串行計算相對較多,但每一個環(huán)節(jié)只要能夠有并行的可能的情況下,提前考慮算法以及GPU環(huán)境的匹配,是能夠?qū)崿F(xiàn)加速可能性的。GPU加速對數(shù)字電路的后端設(shè)計而言,屬于EDA工具研發(fā)中的新挑戰(zhàn)。芯行紀(jì)AmazeSys數(shù)字布局布線軟件適配GPU硬件加速技術(shù),為設(shè)計者縮短設(shè)計周期、加速設(shè)計創(chuàng)新提供了新的途徑。
關(guān)于芯行紀(jì)
芯行紀(jì)科技有限公司匯聚EDA研發(fā)和技術(shù)支持精英,主營研發(fā)符合3S理念(Smart、Speedy、Simple)、包含新一代布局布線技術(shù)的數(shù)字實現(xiàn)EDA平臺,并提供高端數(shù)字芯片設(shè)計解決方案,助力提升芯片設(shè)計效率,以科技創(chuàng)新推動發(fā)展新質(zhì)生產(chǎn)力。
-
控制器
+關(guān)注
關(guān)注
114文章
17113瀏覽量
184358 -
gpu
+關(guān)注
關(guān)注
28文章
4948瀏覽量
131259 -
計算機
+關(guān)注
關(guān)注
19文章
7663瀏覽量
90825 -
eda
+關(guān)注
關(guān)注
71文章
2930瀏覽量
178013
原文標(biāo)題:GPU硬件加速在數(shù)字實現(xiàn)EDA中的應(yīng)用
文章出處:【微信號:gh_2894c3fc5359,微信公眾號:芯行紀(jì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
《CST Studio Suite 2024 GPU加速計算指南》
GPU加速XenApp/Windows 2016/Office/IE性能會提高嗎
可與NvFBC一起使用的GPU
GPU加速matlab程序
tengine是如何使用arm的GPU進(jìn)行加速的
Javascript如何實現(xiàn)GPU加速?
算法 | 超Mask RCNN速度4倍,僅在單個GPU訓(xùn)練的實時實例分割算法
首個采用NVIDIA M2050 GPU的實例 開啟GPU云計算下個十年
使用GPU加速RELION進(jìn)行生物結(jié)構(gòu)解析
OrCAD Capture CIS instance和occurrences概念解析
Oracle 云基礎(chǔ)設(shè)施提供新的 NVIDIA GPU 加速計算實例

GPU虛擬化技術(shù)MIG簡介和安裝使用教程
instance是何時翻轉(zhuǎn)的?每次有多少instance在翻轉(zhuǎn)?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論