 谷歌大腦與Jürgen Schmidhuber提出「人工智能夢境」
谷歌大腦與Jürgen Schmidhuber提出「人工智能夢境」
人類可以在應對各種情況時在大腦中事先進行充分思考,那么人工智能也可以嗎?近日,由谷歌大腦研究科學家 David Ha 與瑞士 AI 實驗室 IDSIA 負責人 Jürgen Schmidhuber(他也是 LSTM 的提出者)共同提出的「世界模型」可以讓人工智能在「夢境」中對外部環境的未來狀態進行預測,大幅提高完成任務的效率。這篇論文一經提出便吸引了人們的熱烈討論。
人類基于有限的感官感知開發關于世界的心智模型,我們的所有決策和行為都是基于這一內部模型。系統動力學之父 Jay Wright Forrester 將這一心智模型定義為:
「我們周圍的世界在我們的大腦中只是一個模型。沒有人的大腦可以想象整個世界、所有政府或國家。他只選擇概念及其之間的關系,然后使用它們表征真實的系統。」
為了處理我們日常生活中的海量信息,大腦學習對信息進行時空抽象化表征。我們能夠觀察一個場景,并記住其抽象描述 [5, 6]。有證據表明我們在任意時刻的感知都由大腦基于內部模型所做的未來預測而決定 [7, 8]。
圖 2:我們看到的事物基于大腦對未來的預測 (Kitaoka, 2002; Watanabe et al., 2018)。
一種理解大腦中預測模型的方式是:它可能不是預測未來,而是根據給出的當前運動動作預測未來的感官數據 [12, 13]。在面對危險時,我們能夠本能地根據該預測模型來行動,并執行快速的反射行為 [14],無需有意識地規劃一系列動作。
以棒球為例 [15]。棒球擊球手只有幾毫秒時間來決定如何揮動球棒,而眼睛的視覺信號傳到大腦所需時間比這更少。擊球手能夠快速根據大腦對未來的預測來行動,無需有意識地展開多個未來場景再進行規劃 [16]。
在很多強化學習(RL)[17, 18, 19] 問題中,人工智能體還受益于過去和現在狀態的良好表征,以及優秀的未來預測模型 [20, 21],最好是在通用計算機上實現的強大預測模型,如循環神經網絡(RNN)[22, 23, 24]。
大型 RNN 是具備高度表達能力的模型,可以學習數據豐富的時空表征。但是,文獻中很多無模型 RL 方法通常僅使用具備少量參數的小型神經網絡。RL 算法通常受限于信用分配問題(credit assignment problem),該挑戰使傳統的 RL 算法很難學習大型模型的數百萬權重,因此在實踐中常使用小型網絡,因為它們在訓練過程中迭代速度更快,可以形成優秀策略。
理想情況下,我們希望能夠高效訓練基于大型 RNN 網絡的智能體。反向傳播算法 [25, 26, 27] 可用于高效訓練大型神經網絡。本研究中,我們試圖通過將智能體分為大型世界模型和小型控制器模型,來訓練能夠解決 RL 任務的大型神經網絡。我們首先用無監督的方式訓練一個大型神經網絡,來學習智能體世界的模型,然后訓練小型控制器模型來使用該世界模型執行任務。小型控制器使得算法聚焦于小搜索空間的信用分配問題,同時無需犧牲大型世界模型的容量和表達能力。通過世界模型來訓練智能體,我們發現智能體學會一個高度緊湊的策略來執行任務。
盡管存在大量與基于模型的強化學習相關的研究,但本文并不是對該領域當前狀況進行綜述。本文旨在從 1990—2015 年一系列結合 RNN 世界模型和控制器的論文 [22, 23, 24, 30, 31] 中提煉出幾個關鍵概念。我們還討論了其他相關研究,它們也使用了類似的「學習世界模型,再使用該模型訓練智能體」的思路。
本文提出了一種簡化框架,我們使用該框架進行實驗,證明了這些論文中的一些關鍵概念,同時也表明這些思路可以被高效應用到不同的 RL 環境中。在描述方法論和實驗時,我們使用的術語和符號與 [31] 類似。
2. 智能體模型
我們提出一種由人類認知系統啟發而來的簡單模型。在該模型中,我們的智能體有一個視覺感知模塊,可以把所見壓縮進一個小的表征性代碼。它同樣有一個記憶模塊,可以根據歷史信息對未來代碼做預測。最后,智能體還有一個決策模塊,只基于由其視覺和記憶組件創建的表征來制定行動。
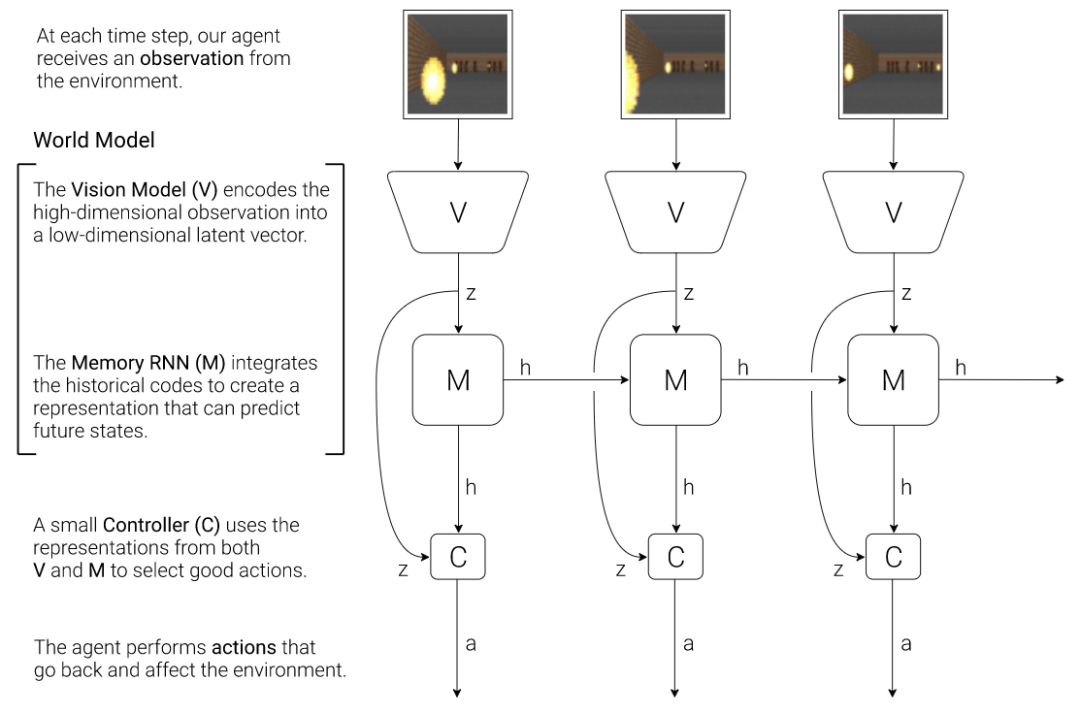
圖 4:我們的智能體包含緊密相連的三個模塊: 視覺 (V)、記憶 (M) 和控制器 (C)。
2.1. VAE (V) 模型
環境在每一時間步上為我們的智能體提供一個高維輸入觀測,這一輸入通常是視頻序列中的一個 2D 圖像幀。VAE 模型的任務是學習每個已觀測輸入幀的抽象壓縮表征。
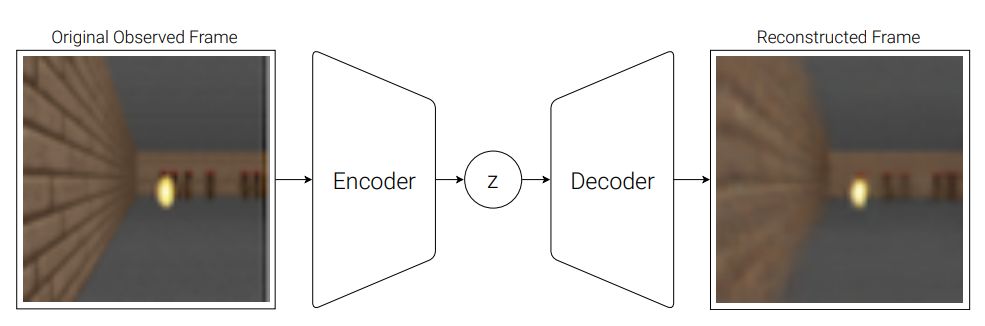
圖 5:VAE 的流程圖。
在我們的試驗中,我們使用一個變分自編碼器 (VAE) (Kingma & Welling, 2013; Jimenez Rezende et al., 2014) 作為 V 模型。
2.2. MDN-RNN (M) 模型
盡管在每一時間幀上壓縮智能體的所見是 V 模型的任務,我們也想壓縮隨著時間發生的一切變化。為達成這一目的,我們讓 M 模型預測未來,它可以充當 V 預期產生的未來 z 向量的預測模型。由于自然中的很多復雜環境是隨機的,我們訓練 RNN 以輸出一個概率密度函數 p(z) 而不是一個確定性預測 z。
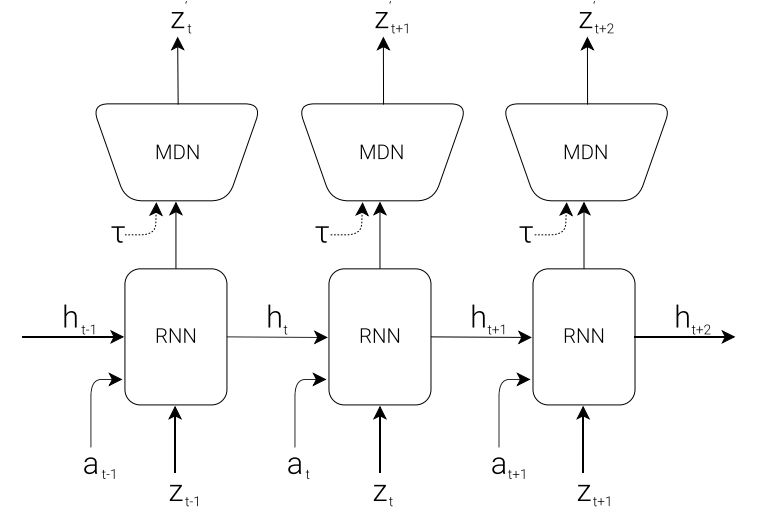
2.3. 控制器 (C) 模型
在環境的展開過程中,控制器 (C) 負責決定動作進程以最大化智能體期望的累加獎勵。在我們的試驗中,我們盡可能使 C 模型簡單而小,并把 V 和 M 分開訓練,從而智能體的絕大多數復雜度位于世界模型(V 和 M)之中。
2.4. 合并 V、M 和 C
下面的流程圖展示了 V、M 和 C 如何與環境進行交互:
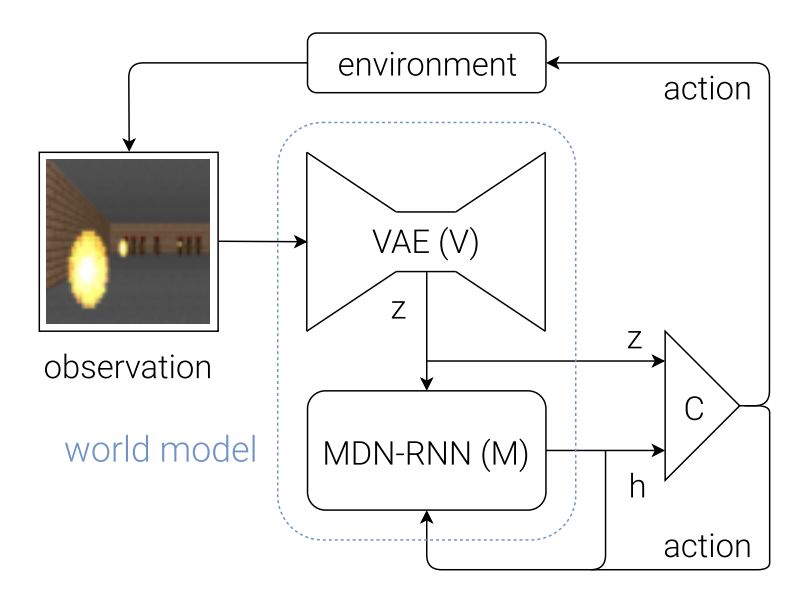
圖 8:智能體模型的流程圖。原始的觀察每個時間步 t 到 zt 首先在 V 上進行處理。C 的輸入是隱向量 zt 在每個時間步上與 M 隱藏態的串接。隨后 C 會輸出動作矢量以控制 motor,這會影響整個環境。隨后 M 會以 zt 作為輸入,生成時間 t+1 的狀態 ht+1。
3.Car Racing 實驗
在這一章節中,我們描述了如何訓練前面所述的智能體模型,并用來解決 Car Racing 任務。就我們所知,我們的智能體是解決該任務并獲得預期分數的第一個解決方案。
總結而言,Car Racing 實驗可以分為以下過程:
1. 從隨機策略中收集 10000 個 rollouts。
2. 訓練 VAE(V)將視頻幀編碼為 32 維的隱向量 z。
3. 訓練 MDN-RNN(M)建模概率分布 P(z_{t+1} | a_t, z_t, h_t)。
4. 定義控制器(C)為 a_t = W_c [z_t, h_t] + b_c。
5. 使用 CMA-ES 求解 W_c 和 b_c 而最大化預期累積獎勵。

表 1:多種方法實現的 CarRacing-v0 分數。
因為我們的世界模型能夠對未來建模,因此我們能自行假設或預想賽車場景。給定當前狀態,我們可以要求模型產生 z_{t+1} 的概率分布,然后從 z_{t+1} 中采樣并作為真實世界的觀察值。我們可以將已訓練的 C 放回由 M 生成的預想環境中。下圖展示了模型所生成的預想環境,而該論文的在線版本展示了世界模型在預想環境中的運行。
圖 13:我們的智能體在自己的預想環境或「夢」中學習駕駛。在這里,我們將已訓練策略部署到從 MDN-RNN 生成的偽造環境中,bintonggu 并通過 VAE 的解碼器展示。在演示中,我們可以覆蓋智能體的行動并調整τ以控制由 M 生成環境的不確定性。
4. VizDoom 實驗
如果我們的世界模型足夠準確,足以處理手邊的問題,那么我們應該能夠用實際環境來替換世界模型。畢竟,我們的智能體不直接觀察現實,而只是觀察世界模型呈現給它的事物。在該實驗中,我們在模仿 VizDoom 環境的世界模型所生成的幻覺中訓練智能體。
經過一段時間訓練后,我們的控制器學會在夢境中尋路,逃離 M 模型生成怪獸的致命火球攻擊(fireballs shot)。
圖 15:我們的智能體發現一個策略可以逃避幻境中的火球。
我們把在虛擬幻境中訓練的智能體放在原始 VizDoom 場景中進行測試。
圖 16:將智能體在幻覺 RNN 環境中學到的策略部署到真實的 VizDoom 環境中。
由于我們的世界模型只是該環境的近似概率模型,它偶爾會生成不遵循真實環境法則的軌跡。如前所述,世界模型甚至無法確切再現真實環境中房間另一端的怪獸數量。就像知道空中物體總會落地的孩子也會想象存在飛越蒼穹的超級英雄。為此,我們的世界模型將被控制器利用,即使在真實環境中此類利用并不存在。
圖 18:智能體在多次運行中被火球擊中后,發現了自動熄滅火球的對抗策略。
5. 迭代訓練過程
在我們的實驗中,任務相對簡單,因此使用隨機策略收集的數據集可以訓練出較好的世界模型。但是如果環境復雜度增加了呢?在難度較大的環境中,在智能體學習如何有策略地穿越其世界后,它也僅能獲取世界的一部分知識。
更復雜的任務則需要迭代訓練。我們需要智能體探索自己的世界,不斷收集新的觀測結果,這樣其世界模型可以不斷改善和細化。迭代訓練過程(Schmidhuber, 2015a)如下:
1. 使用隨機模型參數初始化 M、C。
2. 在真實環境中試運行 N 次。智能體可能在運行過程中學習。將運行中的所有動作 a_t 和觀測結果 x_t 保存在存儲設備上。
3. 訓練 M 對 P(x_t+1, r_t+1, a_t+1, d_t+1|x_t, a_t, h_t) 進行建模。
4. 如果任務未完成,則返回步驟 2。
論文:World Models

摘要:我們探索構建流行的強化學習環境之下的生成神經網絡。我們的「世界模型」可以無監督方式進行快速訓練,以學習環境的有限時空表征。通過使用提取自世界模型的特征作為智能體的輸入,我們可以訓練一個非常緊密且簡單的策略,解決目標任務。我們甚至可以完全通過由世界模型本身生成的虛幻夢境訓練我們的智能體,并把從中學會的策略遷移進真實環境之中。
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103053 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247461
原文標題:模擬世界的模型:谷歌大腦與Jürgen Schmidhuber提出「人工智能夢境」
文章出處:【微信號:fbigdata,微信公眾號:AI報道】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論