") 一個基于Tensorflow框架的開源Tacotron實現(xiàn)
一個基于Tensorflow框架的開源Tacotron實現(xiàn)
幸運的是近年來基于神經(jīng)網(wǎng)絡(luò)架構(gòu)的深度學(xué)習(xí)方法崛起,使得原本在傳統(tǒng)專業(yè)領(lǐng)域門檻極高的TTS應(yīng)用上更接地氣。現(xiàn)在,我們有了新方法Tacotron一種端到端的TTS生成模型。所謂“端到端”就是直接從字符文本合成語音,打破了各個傳統(tǒng)組件之間的壁壘,使得我們可以從<文本,聲譜>配對的數(shù)據(jù)集上,完全隨機從頭開始訓(xùn)練。從Tacotron的論文中我們可以看到,Tacotron模型的合成效果是優(yōu)于要傳統(tǒng)方法的。
本文下面主要內(nèi)容是github上一個基于Tensorflow框架的開源Tacotron實現(xiàn),介紹如何快速上手漢語普通話的語音合成。至于模型的技術(shù)原理,限于篇幅就不再詳細(xì)介紹了,有興趣可以直接閱讀論文,本文的宗旨是,對于剛?cè)腴T的同學(xué)能夠在自己動手實踐中獲取及時的結(jié)果反饋。
在正文開始之前,筆者假設(shè)讀者手頭已經(jīng)準(zhǔn)備好項目運行的軟硬件環(huán)境,包括NVIDIA GTX系列顯卡及其驅(qū)動,能夠在控制臺上使用Python3引入Tensorflow模塊。
關(guān)于Tacotron的源代碼,我們選擇了Keith Ito的個人項目,筆者的漢語語音合成正是基于此源碼上修改而成,代碼在:https://github.com/begeekmyfriend/tacotron
訓(xùn)練語料庫可以在:
http://www.openslr.org/18上下載6.4G大小的THCHS-30,這是由清華大學(xué)開放的漢語普通話語料,許可證為Apache License v2.0。
我們可以開始安裝運行了。先clone源代碼到本地~/tacotron,然后解壓THCHS-30數(shù)據(jù)集到根目錄下,如下所示:
~/tacotron
|- data_thchs30
|- data
|- dev
|- lm_phone
|- lm_word
|- README.TXT
|- test
|- train
注意,~/tacotron是默認(rèn)的路徑,之后運行Python程序會直接把~/tacotron作為根目錄,如果你的項目根目錄不一樣,那么你必須修改程序的默認(rèn)路徑參數(shù),否則會出現(xiàn)運行錯誤。
我們可以深入到:~/tacotron/data_thchs30/data里面去觀摩一下,后其中綴為“wav”是語音文件,采樣率16KHz,樣本寬度16-bit,單聲道,內(nèi)容是時長為10s左右的一段漢語。后綴為“trn”文件為文本標(biāo)注(transcript),不同語言有著不同的標(biāo)注方法,比如英語就可以直接用26個字母加上標(biāo)點符號作為標(biāo)注,也就是直接使用英文內(nèi)容本身;韓語由它自己一套字母表,每個字母可以使用Unicode代碼作為標(biāo)注字符;而漢字本身有2~3萬個,窮舉的話太多,還有很多同音字,所以我們使用漢語拼音作為字符標(biāo)注是一種可行方案(在此向漢語拼音之父周有光表示敬意)。比如有這么一句:
綠 是 陽春 煙 景 大塊 文章 的 底色 四月 的 林 巒 更是 綠 得 鮮活 秀媚 詩意 盎然
用漢語拼音標(biāo)注為:
lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de5 di3 se4 si4 yue4 de5 lin2 luan2 geng4 shi4 lv4 de5 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
注意到除了拉丁字母的拼音,還有1~5個阿拉伯?dāng)?shù)字,表示聲調(diào)(四種聲調(diào)加上輕聲)。
也可以使用音素(聲母+韻母)為單元標(biāo)注:
l v4 sh ix4 ii iang2 ch un1 ii ian1 j ing3 d a4 k uai4 uu un2 zh ang1 d e5 d i3 s e4 s iy4 vv ve4 d e5 l in2 l uan2 g eng4 sh ix4 l v4 d e5 x ian1 h uo2 x iu4 m ei4 sh ix1 ii i4 aa ang4 r an2
根據(jù)經(jīng)驗筆者要指出,如果以字符為單位[a-z1-5],其實上述兩種標(biāo)注方法沒有本質(zhì)區(qū)別,故我們只要使用漢語拼音標(biāo)注方案即可。
聰明的讀者應(yīng)該明白了,所謂的<文本,聲譜>配對,就是要讓機器學(xué)會將每一個包括空格和標(biāo)點在內(nèi)的字符[a-z1-5 ,.;:],對應(yīng)到(mel或線性)聲譜的某幾幀。

接下來進入實際操作階段。在根目錄下運行如下命令:
> python3 preprocess.py --dataset thchs30
這條命令會在根目錄下生成training目錄,里面存放了每個音頻文件的mel頻譜和線性頻譜(通過短時傅里葉變換STFT而得),后綴為"npy"的文件,用numpy庫加載即可得到多個narray數(shù)組(可以視為多個特征向量組成的多維矩陣),用作語音的聲學(xué)特征提取。除此之外還有個train.txt文件,里面基本上就是csv的格式將拼音標(biāo)注同每個文件的聲譜對應(yīng)起來。
再提醒一遍,我們的tacotron根目錄默認(rèn)是~/tacotron,更改需要改變命令行參數(shù)。有了<文本,聲譜>配對數(shù)據(jù)集形式后,我們可以訓(xùn)練了,輸入以下命令行:
> nohup python3 train.py --name thchs30 > output.out &
我們使用了nohup命令來屏蔽一切中斷信號,同時將Python進程置于后臺,這是由于訓(xùn)練過程十分漫長(一般收斂需要10個小時,得到好的效果需要2天),免得網(wǎng)絡(luò)中斷或者終端斷開導(dǎo)致Python進程被殺死。訓(xùn)練過程中的輸出將會保存在logs-thchs30目錄下,可能是這樣的:
~/tacotron
|- logs-thchs30
|- model.ckpt-92000.data-00000-of-00001
|- model.ckpt-92000.index
|- model.ckpt-92000.meta
|- step-92000-align.png
|- step-92000-align.wav
|- ...
以上是92K次迭代后保存下來的模型和alignment圖,順便說一下我們不需要關(guān)注step-92000-align.wav這個音頻文件,這并不是通過模型預(yù)測的實際效果,只是在訓(xùn)練中使用了teacher forcing方法,不代表evaluation效果,可以不去管它。
如何判斷訓(xùn)練是否達到預(yù)期呢?個人經(jīng)驗有兩個:一看學(xué)習(xí)是否收斂;二看損失(loss)低于某個值。由于Tacotron模型本質(zhì)上是基于編碼器解碼器模式的seqtoseq模型,所以學(xué)習(xí)是否收斂可以從編碼器序列和解碼器序列是否對齊(alignment)判斷。
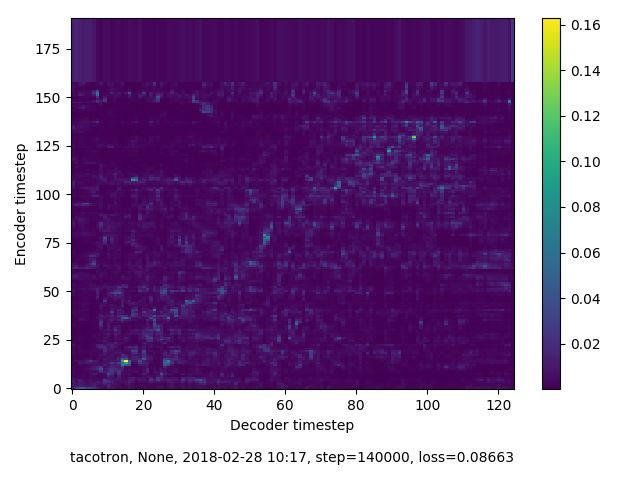
我們放了兩張alignment圖對比,上圖訓(xùn)練了140K次迭代,可以看到?jīng)]有出現(xiàn)對齊,說明沒有收斂。可能的原因很多,比如數(shù)據(jù)集質(zhì)量不好,標(biāo)注不正確等等。下圖是92K次迭代,可以看到對齊情況良好,表明基本上可以通過文本來合成出有效的語音。這里要指出,所謂對齊并不是一定要筆直的斜線,它只是代表編碼器序列(文本)和解碼器序列(聲譜)是否對應(yīng)起來,而且像素點越亮,效果越好。
第二個判斷點是loss值,越小表明越接近地真值(ground truth),當(dāng)然必須在收斂的前提下,loss會趨于穩(wěn)定。在實際訓(xùn)練中有可能出現(xiàn)loss值很低,但是仍然沒出現(xiàn)alignment的情況,這是是無法合成語音的。
當(dāng)我們從訓(xùn)練日志上看到,loss值低于0.07的時候,基本表示學(xué)習(xí)收斂并且效果穩(wěn)定了。可以殺掉后臺Python進程,別擔(dān)心,logs-thchs30目錄下已經(jīng)保存了之前訓(xùn)練過程中產(chǎn)生的模型,你可以從任意時刻生成模型隨時恢復(fù)繼續(xù)訓(xùn)練,比如我們需要從92K次迭代生成的模型基礎(chǔ)上繼續(xù)訓(xùn)練,命令行如下:
> nohup python3 train.py --name thchs30 --restore_step 92000 >> output.out &
好了,現(xiàn)在終于到了檢驗我們錄音效果的時刻了!不過我們無法直接輸入漢字文本,而是拼音標(biāo)注,好在有開源項目python-pinyin幫我們搞定:https://github.com/mozillazg/python-pinyin
比如我們想合成一句“每個內(nèi)容生產(chǎn)者都可以很方便地實現(xiàn)自我價值,更多的人有了微創(chuàng)業(yè)的機會。”我們使用python-pinyin輸出的拼音標(biāo)注拷貝到eval.py里,輸入命令行:
> python3 eval.py --checkpoint logs-thchs30/model.ckpt-133000
一段時間后,就會在logs-thchs30目錄下生成了eval-133000-0.wav,這就是我們想要的結(jié)果,一起來聽聽看吧~
-
語音合成
+關(guān)注
關(guān)注
2文章
92瀏覽量
16437 -
GitHub
+關(guān)注
關(guān)注
3文章
482瀏覽量
17527
原文標(biāo)題:基于Tacotron漢語語音合成的開源實踐
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
SSM框架的源碼解析與理解
用于SLAM中點云地圖綜合評估的開源框架






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論