") 提高IT運(yùn)維效率,深度解讀京東云基于自然語言處理的運(yùn)維日志異常檢測(cè)AIOps落地實(shí)踐
提高IT運(yùn)維效率,深度解讀京東云基于自然語言處理的運(yùn)維日志異常檢測(cè)AIOps落地實(shí)踐
基于NLP技術(shù)對(duì)運(yùn)維日志聚類,從日志角度快速發(fā)現(xiàn)線上業(yè)務(wù)問題
日志在IT行業(yè)中被廣泛使用,日志的異常檢測(cè)對(duì)于識(shí)別系統(tǒng)的運(yùn)行狀態(tài)至關(guān)重要。解決這一問題的傳統(tǒng)方法需要復(fù)雜的基于規(guī)則的有監(jiān)督方法和大量的人工時(shí)間成本。我們提出了一種基于自然語言處理技術(shù)運(yùn)維日志異常檢測(cè)模型。為了提高日志模板向量的質(zhì)量,我們改進(jìn)特征提取,模型中使用了詞性(PoS)和命名實(shí)體識(shí)別(NER)技術(shù),減少了規(guī)則的參與,利用 NER 的權(quán)重向量對(duì)模板矢量進(jìn)行了修改,分析日志模板中每個(gè)詞的 PoS 屬性,從而減少了人工標(biāo)注成本,有助于更好地進(jìn)行權(quán)重分配。為了修改模板向量,引入了對(duì)日志模板標(biāo)記權(quán)重的方法,并利用深度神經(jīng)網(wǎng)絡(luò)(DNN)實(shí)現(xiàn)了基于模板修正向量的最終檢測(cè)。我們的模型在三個(gè)數(shù)據(jù)集上進(jìn)行了有效性測(cè)試,并與兩個(gè)最先進(jìn)的模型進(jìn)行了比較,評(píng)估結(jié)果表明,我們的模型具有更高的準(zhǔn)確度。
日志是記錄操作系統(tǒng)等 IT 領(lǐng)域中的操作狀態(tài)的主要方法之一,是識(shí)別系統(tǒng)是否處于健康狀態(tài)的重要資源。因此,對(duì)日志做出準(zhǔn)確的異常檢測(cè)非常重要。日志異常一般有三種類型,即異常個(gè)體日志、異常日志序列和異常日志定量關(guān)系。我們主要是識(shí)別異常個(gè)體日志,即包含異常信息的日志。
一般來說,日志的異常檢測(cè)包括三個(gè)步驟: 日志解析、特征提取和異常檢測(cè)。解析工具提取的模板是文本數(shù)據(jù),應(yīng)將其轉(zhuǎn)換為數(shù)字?jǐn)?shù)據(jù),以便于輸入到模型中。為此,特征提取對(duì)于獲得模板的數(shù)字表示是必要的。在模板特征提取方面,業(yè)界提出了多種方法來完成這一任務(wù)。獨(dú)熱編碼是最早和最簡(jiǎn)單的方法之一,可以輕松地將文本模板轉(zhuǎn)換為便于處理的數(shù)字表示,但是獨(dú)熱編碼是一種效率較低的編碼方法,它占用了太多的儲(chǔ)存空間來形成一個(gè)零矢量,而且在使用獨(dú)熱編碼時(shí),忽略了日志模板的語義信息。除了這種方便的編碼方法外,越來越多的研究人員應(yīng)用自然語言處理(NLP)技術(shù)來實(shí)現(xiàn)文本的數(shù)字轉(zhuǎn)換,其中包括詞袋,word2vec 等方法。雖然上述方法可以實(shí)現(xiàn)從文本數(shù)據(jù)到數(shù)字?jǐn)?shù)據(jù)的轉(zhuǎn)換,但在日志異常檢測(cè)方面仍然存在一些缺陷。詞袋和 word2vec 考慮到模板的語義信息,可以有效地獲得單詞向量,但是它們?nèi)狈紤]模板中出現(xiàn)的每個(gè)模版詞的重要性調(diào)節(jié)能力。此外,深度神經(jīng)網(wǎng)絡(luò)(DNN)也被用于模板的特征提取。
我們的模型主要改進(jìn)特征提取,同時(shí)考慮每個(gè)標(biāo)記的模版詞語義信息和權(quán)重分配,因?yàn)闃?biāo)記結(jié)果對(duì)最終檢測(cè)的重要性不同。我們利用兩種自然語言處理技術(shù)即PoS和命名實(shí)體識(shí)別(NER),通過以下步驟實(shí)現(xiàn)了模板特征的提取。具體來說,首先通過 FT-Tree 將原始日志消息解析為日志模板,然后通過 PoS 工具對(duì)模板進(jìn)行處理,獲得模板中每個(gè)詞的 PoS 屬性,用于權(quán)重向量計(jì)算。同時(shí),通過 word2vec 將模板中的標(biāo)記向量化為初始模板向量,并利用權(quán)值向量對(duì)初始模板向量進(jìn)行進(jìn)一步修改,那些重要的模版詞的 PoS屬性將有助于模型更好地理解日志含義。對(duì)于標(biāo)記完 PoS 屬性的模版詞,詞對(duì)異常信息識(shí)別的重要性是不同的,我們使用 NER 在模版的 PoS屬性中找出重要性高的模版詞,并且被 NER 識(shí)別為重要的模版詞將獲得更大的權(quán)重。然后,將初始模板向量乘以這個(gè)權(quán)重向量,生成一個(gè)復(fù)合模板向量,輸入到DNN模型中,得到最終的異常檢測(cè)結(jié)果。為了減少對(duì)日志解析的人力投入,并為權(quán)重計(jì)算做準(zhǔn)備,我們采用了 PoS 分析方法,在不引入模板提取規(guī)則的情況下,對(duì)每個(gè)模版詞都標(biāo)記一個(gè) PoS 屬性。
解析模板的特征提取過程是異常檢測(cè)的一個(gè)重要步驟,特征提取的主要目的是將文本格式的模板轉(zhuǎn)換為數(shù)字向量,業(yè)界提出了各種模板特征提取方法:
One-hot 編碼:在 DeepLog 中,來自一組 k 模板ti,i∈[0,k)的每個(gè)輸入日志模板都被編碼為一個(gè)One-hot編碼。在這種情況下,對(duì)于日志的重要信息ti 構(gòu)造了一個(gè)稀疏的 k 維向量 V = [ v0,v1,... ,vk-1] ,并且滿足j不等于i, j∈[0,k),使得對(duì)于所有vi= 1和 vj = 0。
自然語言處理(NLP):為了提取日志模板的語義信息并將其轉(zhuǎn)換為高維向量,LogRobust 利用現(xiàn)成的 Fast-Text 算法從英語詞匯中提取語義信息,能夠有效地捕捉自然語言中詞之間的內(nèi)在關(guān)系(即語義相似性) ,并將每個(gè)詞映射到一個(gè) k 維向量。使用 NLP 技術(shù)的各種模型也被業(yè)界大部分人使用,如 word2vec 和 bag-of-words 。
深度神經(jīng)網(wǎng)絡(luò)(DNN):與使用 word2vec 或 Fast-Text 等細(xì)粒度單元的自然語言處理(NLP)不同,LogCNN 生成基于29x128codebook的日志嵌入,該codebook是一個(gè)可訓(xùn)練的層,在整個(gè)訓(xùn)練過程中使用梯度下降進(jìn)行優(yōu)化。
Template2Vec:是一種新方法,基于同義詞和反義詞來有效地表示模板中的詞。在 LogClass 中,將經(jīng)典的加權(quán)方法 TF-IDF 改進(jìn)為 TF-ILF,用逆定位頻率代替逆文檔頻率,實(shí)現(xiàn)了模板的特征構(gòu)造。
一段原始日志消息是一個(gè)半結(jié)構(gòu)化的文本,比如一個(gè)從在線支付應(yīng)用程序收集的錯(cuò)誤日志讀取為: HttpUtil-request 連接失敗,Read timeout at jave.net。它通常由兩部分組成,變量和常量(也稱為模板)。對(duì)于識(shí)別個(gè)體日志的異常檢測(cè),目的是從原始日志解析的模板中識(shí)別是否存在異常信息。我們的模型使用 PoS 分析以及 NER 技術(shù)來進(jìn)行更精確和省力的日志異常檢測(cè)。PoS 有助于過濾標(biāo)記有不必要的 PoS 屬性的模版詞,NER的目標(biāo)是將重要性分配給所有標(biāo)記為重要的 PoS 屬性的模版詞。然后通過模板向量和權(quán)向量的乘積得到復(fù)合模板向量。
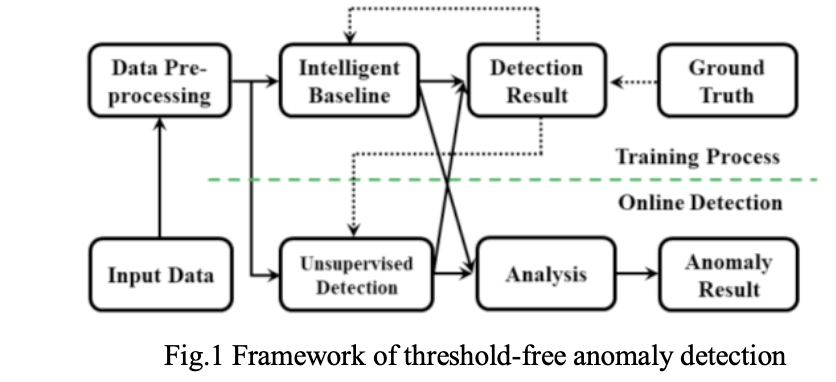
我們的日志異常檢測(cè)模型包括六個(gè)步驟,即模板解析、 PoS分析、初始向量構(gòu)造、基于NER的權(quán)重計(jì)算、復(fù)合向量和最終檢測(cè)。檢測(cè)的整個(gè)過程如圖1所示:
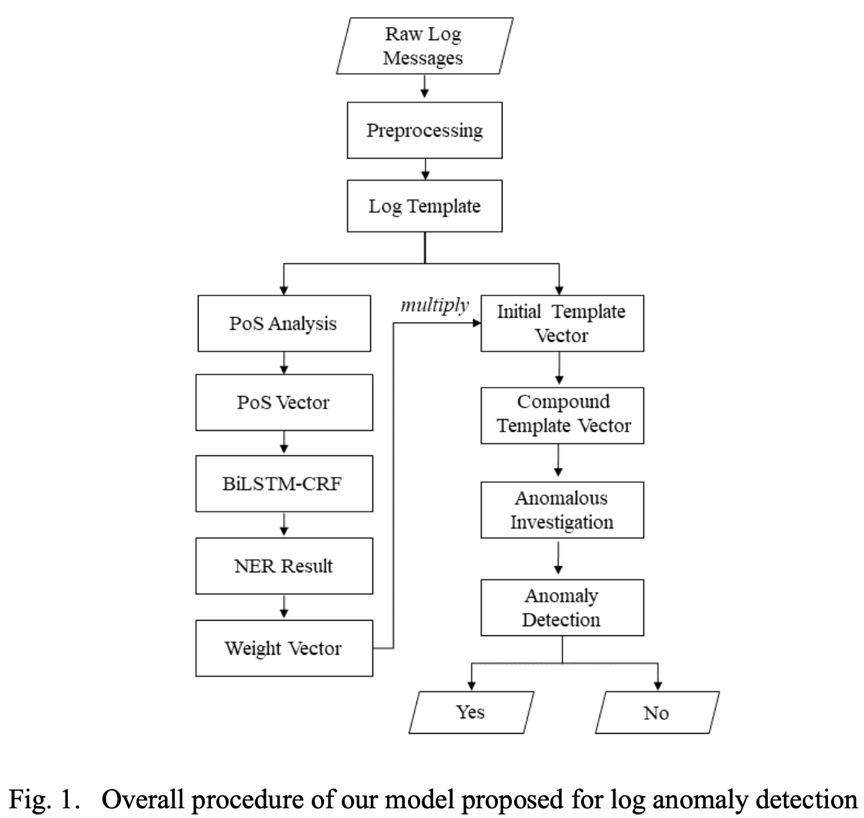
第一步:模板解析
初始日志是半結(jié)構(gòu)化的文本,它們包含一些不必要的信息,可能會(huì)造成混亂或阻礙日志檢測(cè)。因此,需要預(yù)處理來省略變量,比如一些數(shù)字或符號(hào),并提取常量,即模板。以前面提到的日志消息為例,原始日志HttpUtil-request 連接[wx/v1/pay/prepay]的模板失敗,Read timeout at jave.net。可以提取為: HttpUtil 請(qǐng)求連接 * 失敗讀取時(shí)間為 * 。我們使用簡(jiǎn)單而有效的方法 FT-Tree 來實(shí)現(xiàn)日志解析,我們沒有引入復(fù)雜的基于規(guī)則的規(guī)則來去除那些不太重要的標(biāo)記,比如停止詞。
第二步:PoS 分析
上一步的模版解析結(jié)果只有英語單詞、短語和一些非母語單詞保留在解析好的模板中,這些模版詞具有各種 PoS 屬性,例如 VB 和 NN。根據(jù)我們對(duì)大量日志模板的觀察,一些 PoS 屬性對(duì)于模型理解模板所傳達(dá)的意義很重要,而其他屬性可以忽略。如圖3所示,解析模板中的單詞“ at”在理論上是不必要的,相應(yīng)的 PoS 屬性“ IN”也是不必要的,即使去掉 IN 的標(biāo)記,我們?nèi)匀豢梢耘袛嗄0迨欠裾!R虼耍谖覀兊玫搅?PoS 向量之后,我們可以通過去掉那些具有特定 PoS 屬性的模版詞來簡(jiǎn)化模板。剩余的模版詞對(duì)于模型更好地理解模板內(nèi)容非常重要。
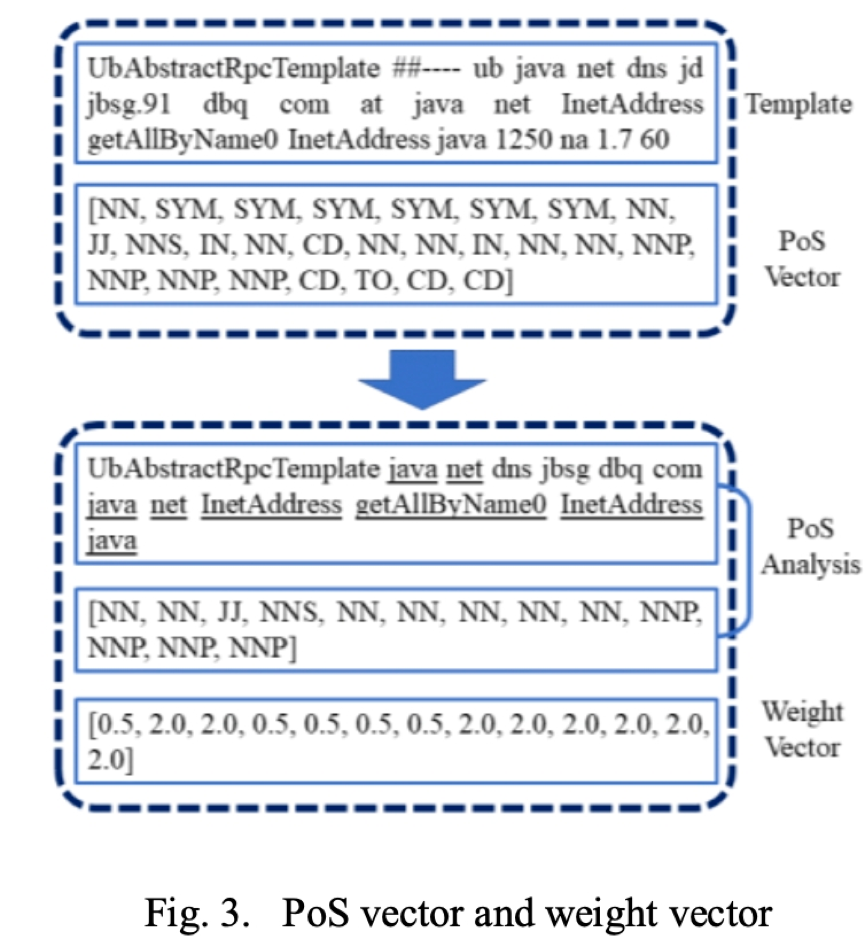
第三步:初始模板向量構(gòu)造
在獲得 PoS 矢量的同時(shí),模板也被編碼成數(shù)字向量。為了考慮模板的語義信息,在模型中使用 word2vec 來構(gòu)造模板的初始向量。該初始向量將與下一步得到的權(quán)重向量相乘,得到模板的復(fù)合優(yōu)化表示。
第四步: 權(quán)重分析
首先對(duì)模板中的模版詞進(jìn)行 PoS 分析處理,剔除無意義的模版詞。至于其余的模版詞,有些是關(guān)鍵的,用于傳達(dá)基本信息,如服務(wù)器操作、健康狀態(tài)等。其他的可能是不太重要的信息,比如動(dòng)作的對(duì)象、警告級(jí)別等等。為了加大模型對(duì)這些重要模版詞的學(xué)習(xí)力度,我們構(gòu)造了一個(gè)權(quán)重向量來突出這些重要的模版詞。為此,我們采用了 NER 技術(shù),通過輸入已定義的重要實(shí)體,學(xué)習(xí)挑選標(biāo)記為重要實(shí)體的所有模版詞。該過程如圖所示:
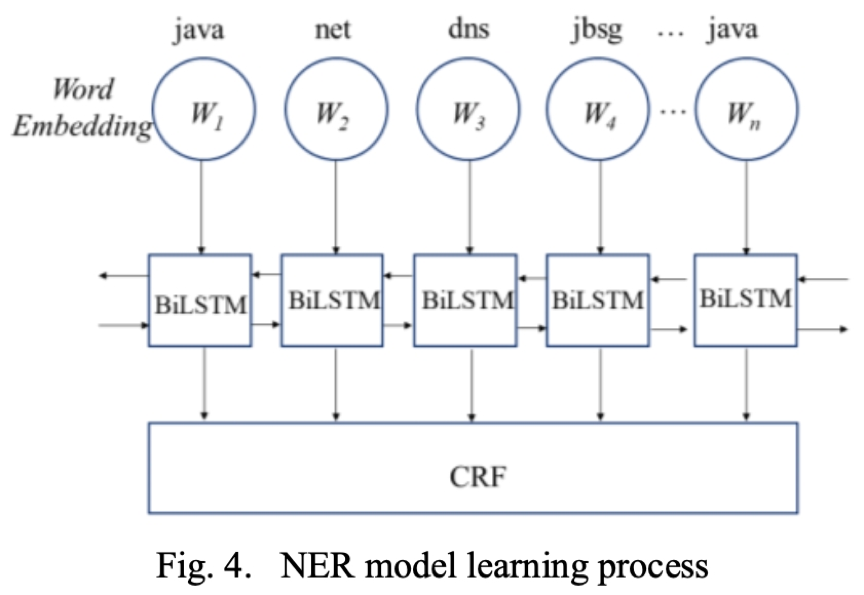
CRF 是 NER 通常使用的工具,它也被用于我們的模型識(shí)別模版詞的重要性。也就是說,通過向模型提供標(biāo)記為重要的模版詞,模型可以學(xué)習(xí)識(shí)別那些未標(biāo)注的日志的重要的模版詞。一旦模板中的模版詞被 CRF 識(shí)別出來,相應(yīng)的位置就會(huì)賦予一個(gè)權(quán)重值(2.0)。因此,我們得到一個(gè)權(quán)向量 W。
第五步:復(fù)合向量
在獲得權(quán)重向量 W 之后,通過將初始向量 V’乘以權(quán)重向量 W,可以得到一個(gè)表示模板的復(fù)合優(yōu)化向量 V。重要的模版詞分配更大權(quán)重,而其他的模版詞分配更小的。
第六步:異常檢測(cè)
將第五步得到的復(fù)合矢量 v 輸入到最終全連接層中,以便進(jìn)行異常檢測(cè)。完全連通層的輸出分別為0或1,表示正常或異常。
?模型評(píng)估
我們通過實(shí)驗(yàn)驗(yàn)證了該模型對(duì)日志異常檢測(cè)的改進(jìn)效果。采用了兩個(gè)公共數(shù)據(jù)集,以及一套我們內(nèi)部數(shù)據(jù)集,來驗(yàn)證我們模型的實(shí)用性。我們將自己的結(jié)果與業(yè)界針對(duì)日志異常檢測(cè)提出的兩個(gè)Deeplog 和 LogClass模型進(jìn)行了比較。
CANet 的框架是用 PyTorch 構(gòu)建的,我們?cè)?5個(gè)訓(xùn)練周期中選擇新加坡隨機(jī)梯度下降(SGD)作為優(yōu)化器。學(xué)習(xí)速度設(shè)定為2e4。所有的超參數(shù)都是從頭開始訓(xùn)練的。
(1)數(shù)據(jù)集:我們選取了兩套公共集和一套公司內(nèi)部數(shù)據(jù)集進(jìn)行模型評(píng)估,BGL 和 HDFS 都是用于日志分析的兩個(gè)常用公共數(shù)據(jù)集:HDFS:是從運(yùn)行基于 Hadoop 的作業(yè)的200多個(gè) Amazon EC2節(jié)點(diǎn)收集的。它由11,175,629條原始日志消息組成,16,838條被標(biāo)記為“異常”。BGL:收集自 BlueGene/L 超級(jí)計(jì)算機(jī)系統(tǒng) ,包含4,747,963條原始日志消息,其中348,469條是異常日志。每條日志消息都被手動(dòng)標(biāo)記為異常或者正常。數(shù)據(jù)集 A:是從我們公司內(nèi)部收集來進(jìn)行實(shí)際驗(yàn)證的數(shù)據(jù)集。它包含915,577條原始日志消息和210,172條手動(dòng)標(biāo)記的異常日志。
(2)base模型:我們將自己的模型在三個(gè)數(shù)據(jù)集上,與兩個(gè)業(yè)界最先進(jìn)的模型(DeepLog和LogClass)進(jìn)行比較:DeepLog:是一個(gè)基于深度神經(jīng)網(wǎng)絡(luò)的模型,利用長短期記憶(LSTM)來實(shí)現(xiàn)檢測(cè)。DeepLog 采用一次性編碼作為模板向量化方法。LogClass:LogClass 提出了一種新的方法——逆定位頻率(ILF) ,在特征構(gòu)造中對(duì)日志文字進(jìn)行加權(quán)。這種新的加權(quán)方法不同于現(xiàn)有的反文檔頻率(IDF)加權(quán)方法。
(3)模型評(píng)估結(jié)果:我們從Precision、Recall和F1-score三個(gè)方面評(píng)估兩個(gè)base模型和我們的模型的異常檢測(cè)效果,在 HDFS 數(shù)據(jù)集上,我們的模型獲得了最高的 F1得分0.981,此外,我們的模型在召回方面也表現(xiàn)最好。LogClass 在Precision上取得了最好的成績,比我們的稍微高一點(diǎn)。在第二套數(shù)據(jù)集BGL上,我們的模型在召回率Recall(0.991)和 F1-score (0.986)方面表現(xiàn)最好,但在Precision上略低于 LogClass。在第三套數(shù)據(jù)集 A 上三個(gè)模型的性能,我們的模型實(shí)現(xiàn)了最佳性能,其次是 LogClass。
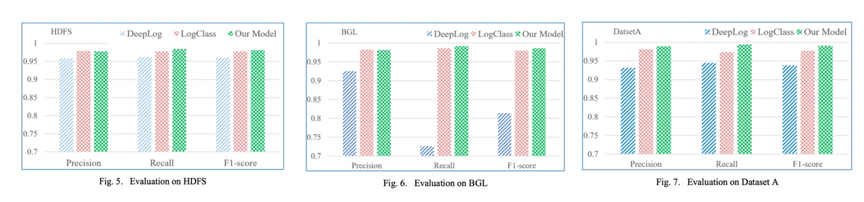
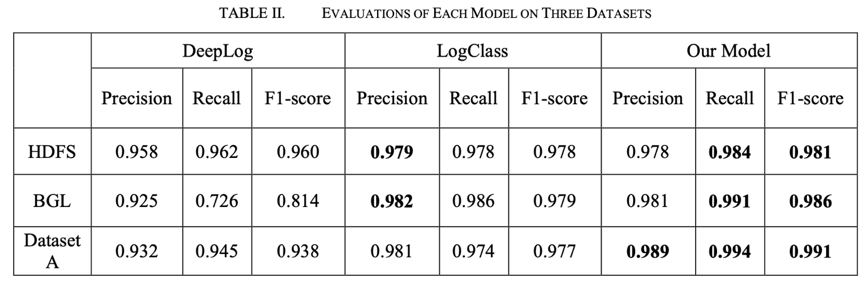
在所有的數(shù)據(jù)集中,我們的模型具有最好的 F1得分和最高的召回率,這意味著我們的模型造成的不確定性更小。
?Natural Language Processing-based Model for Log Anomaly Detection. SEAI.
?ieeexplore檢索:https://ieeexplore.ieee.org/abstract/document/9680175

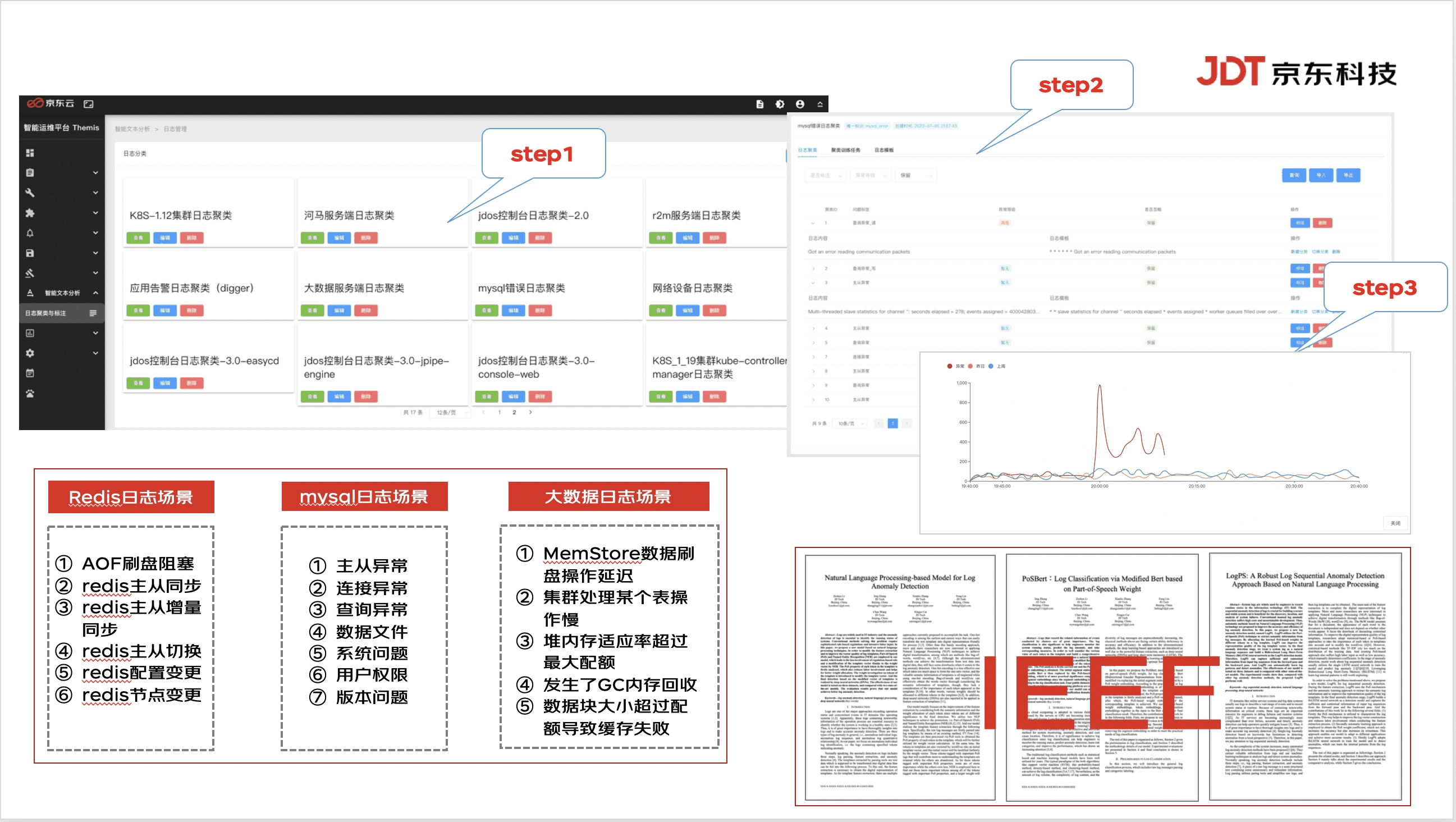
?Themis智能運(yùn)維平臺(tái)智能文本分析功能視圖:(http://jdtops.jd.com/)
?團(tuán)隊(duì)介紹:
京東科技從2018年開始建設(shè)智能運(yùn)維,基于京東多年一線運(yùn)維經(jīng)驗(yàn),以大數(shù)據(jù)和人工智能技術(shù)為抓手,形成以應(yīng)用為中心的一體化智能運(yùn)維解決方案。利用京東內(nèi)部歷年大促場(chǎng)景的數(shù)據(jù)積累,對(duì)算法進(jìn)行不斷的優(yōu)化訓(xùn)練,在監(jiān)控、數(shù)據(jù)庫、網(wǎng)絡(luò)、資源調(diào)度等多個(gè)縱向場(chǎng)景取得突破,可移植性強(qiáng),自研通用化智能基線算法學(xué)件10+,自研通用化異常檢測(cè)算法學(xué)件10+,場(chǎng)景化異常檢測(cè)算法方案5+,具備多種自研通用化根因定位算法學(xué)件,可以自動(dòng)觸發(fā)多維實(shí)時(shí)根因定位 ,從上萬維度屬性值中定位到根因維度,自研5種以上增量式學(xué)習(xí)模板提取與相關(guān)分析算法學(xué)件,運(yùn)維知識(shí)圖譜內(nèi)涵蓋節(jié)點(diǎn)30W+,以應(yīng)用為中心向外延伸出的圖譜關(guān)系達(dá)90W+,賦能根因分析快速精準(zhǔn)查詢調(diào)用。發(fā)表IEEE國際會(huì)議論文(AIOps方向)8篇,申請(qǐng)40余項(xiàng)智能運(yùn)維專利。
審核編輯 黃宇
-
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14056 -
IT運(yùn)維
+關(guān)注
關(guān)注
0文章
5瀏覽量
3171 -
AIOps
+關(guān)注
關(guān)注
0文章
9瀏覽量
1247 -
京東云
+關(guān)注
關(guān)注
0文章
172瀏覽量
122
發(fā)布評(píng)論請(qǐng)先 登錄
AI集成運(yùn)維管理平臺(tái)的架構(gòu)與核心構(gòu)成解析
提高IT運(yùn)維效率,深度解讀京東云AIOps落地實(shí)踐(異常檢測(cè)篇)
儲(chǔ)能運(yùn)維平臺(tái)在換電站的應(yīng)用 有效提高運(yùn)維效率
數(shù)據(jù)驅(qū)動(dòng)的光伏運(yùn)維:平臺(tái)如何提升發(fā)電效率?
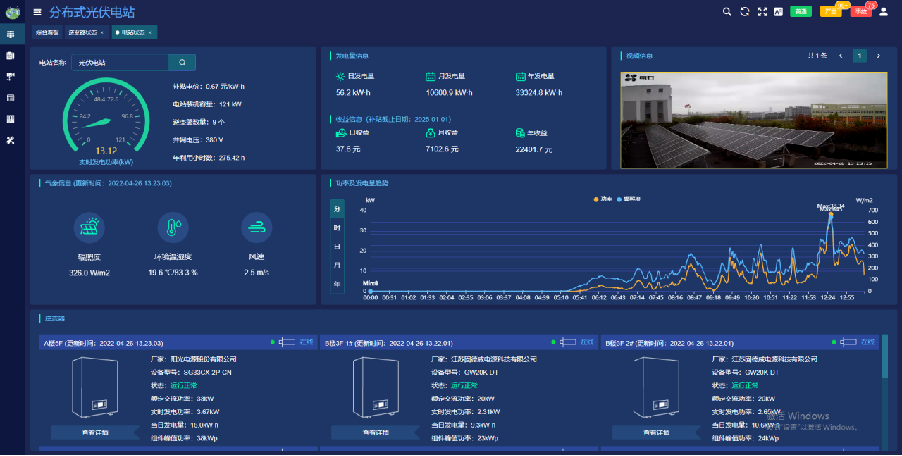
智慧光伏運(yùn)維管理系統(tǒng)助力光伏運(yùn)維降本增效
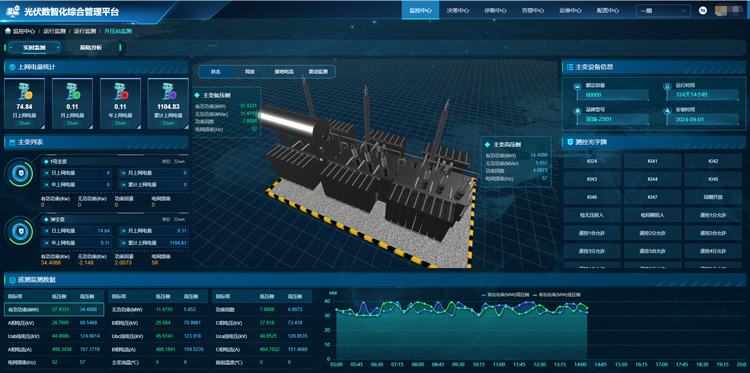
分布式光伏運(yùn)維云平臺(tái)助力光伏電站運(yùn)營
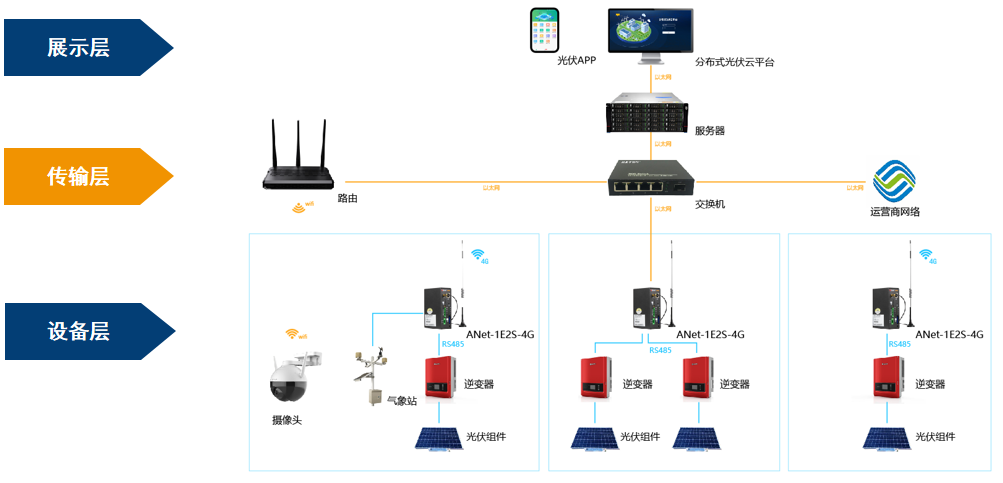
自然語言處理與機(jī)器學(xué)習(xí)的關(guān)系 自然語言處理的基本概念及步驟
自然語言處理與機(jī)器學(xué)習(xí)的區(qū)別
光伏電站運(yùn)維管理系統(tǒng)與傳統(tǒng)運(yùn)維模式對(duì)比分析
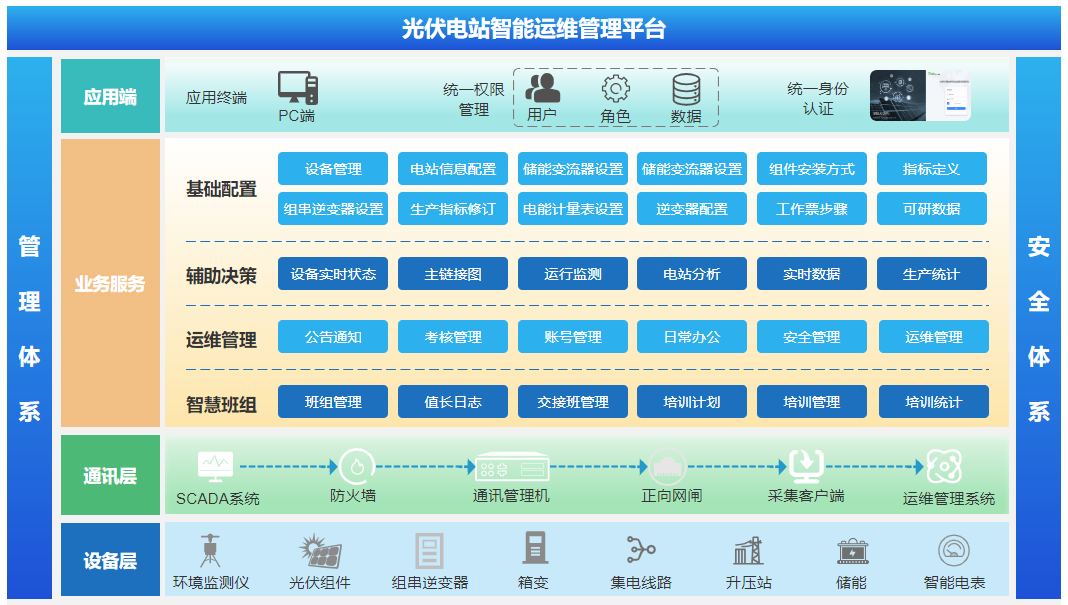
設(shè)備數(shù)據(jù)接入運(yùn)維管理云平臺(tái)實(shí)現(xiàn)什么功能
儲(chǔ)能運(yùn)維平臺(tái)如何優(yōu)化充放電策略
光伏電站運(yùn)維管理系統(tǒng)實(shí)現(xiàn)電站智能運(yùn)維與管理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論