") ARM架構(gòu)的基礎(chǔ)知識(shí)點(diǎn)匯總
ARM架構(gòu)的基礎(chǔ)知識(shí)點(diǎn)匯總
從單片機(jī)轉(zhuǎn)到ARM,主要需要學(xué)習(xí)ARM的架構(gòu),ARM相比單片機(jī)多了一些外設(shè)和總線。在僅僅是裸奔的情況下,如果熟悉了ARM架構(gòu),那么我認(rèn)為使用任何ARM架構(gòu)的芯片和用單片機(jī)將沒(méi)有區(qū)別。ARM架構(gòu)之所以更復(fù)雜,當(dāng)然是為了跑更快以及更好地支持片上系統(tǒng),所以在某種程度上來(lái)說(shuō)對(duì)片上系統(tǒng)不是很了解的話那對(duì)于ARM架構(gòu)的理解也不會(huì)那么深。
本文首先介紹了ARM的架構(gòu)圖及各個(gè)模式,其次介紹了通用寄存器、MMU相關(guān)地址基本概念、ARM920T中有三種類型的地址等,最后闡述了ARM處理器的架構(gòu)及命名規(guī)則。
一、ARM架構(gòu)圖
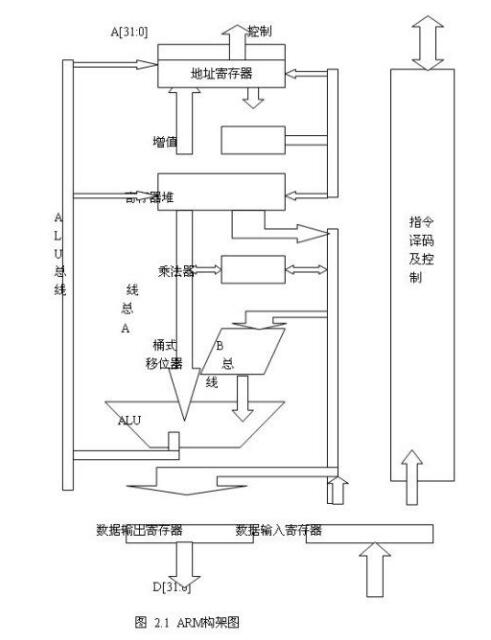
下圖所示的是ARM構(gòu)架圖。它由32位ALU、若干個(gè)32位通用寄存器以及狀態(tài)寄存器、32&TImes;8位乘法器、32&TImes;32位桶形移位寄存器、指令譯碼以及控制邏輯、指令流水線和數(shù)據(jù)/地址寄存器組成。
1.ALU:它有兩個(gè)操作數(shù)鎖存器、加法器、邏輯功能、結(jié)果以及零檢測(cè)邏輯構(gòu)成。
2.桶形移位寄存器:ARM采用了32&TImes;32位的桶形移位寄存器,這樣可以使在左移/右移n位、環(huán)移n位和算術(shù)右移n位等都可以一次完成。
3.高速乘法器:乘法器一般采用“加一移位”的方法來(lái)實(shí)現(xiàn)乘法。ARM為了提高運(yùn)算速度,則采用兩位乘法的方法,根據(jù)乘數(shù)的2位來(lái)實(shí)現(xiàn)“加一移位”運(yùn)算;ARM高速乘法器采用32&TImes;8位的結(jié)構(gòu),這樣,可以降低集成度(其相應(yīng)芯片面積不到并行乘法器的1/3)。
4.浮點(diǎn)部件:浮點(diǎn)部件是作為選件供ARM構(gòu)架使用。FPA10浮點(diǎn)加速器是作為協(xié)處理方式與ARM相連,并通過(guò)協(xié)處理指令的解釋來(lái)執(zhí)行。
5.控制器:ARM的控制器采用的是硬接線的可編程邏輯陣列PLA。
6.寄存器
二、ARM的各個(gè)模式
ARM有以下7種模式:
用戶模式(User,usr) 正常程序執(zhí)行的模式
快速中斷模式(FIQ,fiq) 用于高速數(shù)據(jù)傳輸和通道處理
外部中斷模式(IRQ,irq) 用于通常的中斷處理
特權(quán)模式(Supervisor,svc) 供操作系統(tǒng)使用的一種保護(hù)模式
數(shù)據(jù)訪問(wèn)中止模式(Abort,abt) 用于虛擬存儲(chǔ)及存儲(chǔ)保護(hù)
未定義指令中止模式(Undefined,und) 用于支持通過(guò)軟件方針硬件的協(xié)處理器
系統(tǒng)模式(System,sys) 用于運(yùn)行特權(quán)級(jí)的操作系統(tǒng)任務(wù)
其中除了用戶模式之外都稱之為特權(quán)模式(privileged modes),而在privileged modes中除了系統(tǒng)模式其它都稱為異常模式,即exception mode。起初關(guān)于異常這個(gè)詞我的理解有些偏差,我認(rèn)為異常模式就是這個(gè)系統(tǒng)出錯(cuò)了,而實(shí)際上不是。exception mode的意思是例外,意思是“這模式什么時(shí)候會(huì)發(fā)生不好說(shuō)……”,比如說(shuō)來(lái)了個(gè)外部中斷也會(huì)進(jìn)入異常模式,但是此時(shí)系統(tǒng)是運(yùn)行完好的。
其中SVC用于在系統(tǒng)剛啟動(dòng)的啟動(dòng)文件BOOT程序中,跳轉(zhuǎn)到kernel之前必須為SVC,SVC具有最高權(quán)限,可以對(duì)任何寄存器進(jìn)行操作。在裸機(jī)程序中我們有時(shí)候會(huì)一直處于SVC模式下。
關(guān)于什么時(shí)候會(huì)進(jìn)入用戶模式或者系統(tǒng)模式,以下是我的猜測(cè),比如進(jìn)入linux kernel之后會(huì)設(shè)置成sys模式,比如任務(wù)調(diào)度等等都會(huì)在sys模式中,而執(zhí)行用戶編寫的應(yīng)用程序時(shí),系統(tǒng)是處于usr模式中。以上猜測(cè)需要在linux中找出證據(jù)驗(yàn)證。
其中FIQ,IRQ為中斷模式,有中斷發(fā)生時(shí)會(huì)進(jìn)入FIQ模式或者IRQ模式,至于到底是進(jìn)入哪個(gè)模式是由開(kāi)發(fā)者設(shè)定的。理論上FIQ模式的響應(yīng)速度比IRQ模式要快。
其中abt模式通常發(fā)生于在訪問(wèn)地址沒(méi)有對(duì)齊時(shí)的情況,此時(shí)會(huì)跳轉(zhuǎn)到abt所屬的中斷向量地址中去。und模式應(yīng)該是取到指令之后發(fā)現(xiàn)指令不能用,,此時(shí)會(huì)跳轉(zhuǎn)到abt所屬的中斷向量地址中去。以上兩種模式應(yīng)該是開(kāi)發(fā)過(guò)程中出現(xiàn)BUG才會(huì)進(jìn)入的,也是一種調(diào)試手段,在版本發(fā)行之前應(yīng)該消除這些錯(cuò)誤。
三、通用寄存器
R13通常被用作棧指針,進(jìn)入異常模式時(shí),可以將需要使用的寄存器保存在R13所指的棧中;當(dāng)退出異常吹程序時(shí),將保存在R13所指的棧中的寄存器值彈出。
R14又被稱為連接寄存器(LinkRegister,LR),即PC的返回值。
R15又被記作PC。ARM指令是字對(duì)齊的,PC的值的第0位和第1位總為0。也就是說(shuō)是32位對(duì)齊。
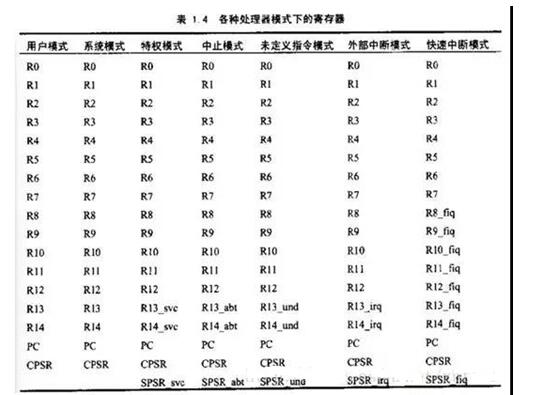
就Cortex-M3來(lái)說(shuō),擁有R0-R15的寄存器組。其中R13作為堆棧指針SP。SP有兩個(gè),分別為R13(MSP)和R13(PSP)即主堆棧指針(MSP)和進(jìn)程堆棧指針(PSP),但在同一時(shí)刻只能有一個(gè)可以看到,這也就是所謂的“banked”寄存器。這些寄存器都是32位的。
四、MMU相關(guān)地址基本概念
關(guān)于MMU,因?yàn)槎喾N存儲(chǔ)設(shè)備的物理地址不同以及不連貫性,將其地址安放在合理的連續(xù)虛擬地址上是很必要的,所以MMU出現(xiàn)了。MMU即將不同的地址放在合適的虛擬地址中,以便調(diào)度。比如要跑LINUX必須要有MMU的支持才行。
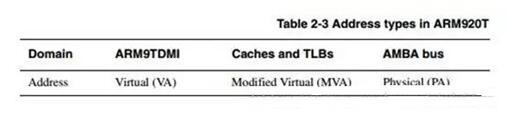
五、ARM920T中有三種類型的地址
虛擬地址(VA),變換后的虛擬地址(MVA),物理地址(PA)。
以下是一個(gè)當(dāng)一個(gè)指令被請(qǐng)求時(shí)地址所做操作的例子:
1、 指令VA(IVA)被ARM920T發(fā)出
2、 它被ProcID(當(dāng)前進(jìn)程所在的進(jìn)程空間塊的編號(hào))轉(zhuǎn)換成指令MVA(IMVA),指令CACHE(ICACHE)和MMU看到的就是IMVA。
3、 如果在IMMU上的保護(hù)模塊確認(rèn)IMVA不會(huì)被中斷,并且IMVA標(biāo)簽也在ICACHE中,指令數(shù)據(jù)會(huì)讀出并返回到ARM920T內(nèi)核中。
4、 如果IMVA tag并不在ICACHE中,那么IMMU會(huì)產(chǎn)生出一個(gè)指令PA(IPA)。地址會(huì)給AMBA總線接口以獲取外部數(shù)據(jù)。
那么VA是如何被PID轉(zhuǎn)換為MVA的呢?
這有關(guān)于CP15中的13,F(xiàn)CSE PID register
R13是fast context switch extension(FCSE 快速上下文切換擴(kuò)展)processidentifier(PID 進(jìn)程標(biāo)識(shí)符)寄存器,此寄存器復(fù)位時(shí)為0。
讀R13會(huì)得到FCSE PID的值,寫R13會(huì)更新FCSE PID的值到[31:25]中,位[24:0]應(yīng)該是零。
如何使用FCSE PID:
920T內(nèi)核發(fā)出的地址都是0-32MB的范圍,4GB的逆序空間被分成了1238個(gè)進(jìn)程空間塊,每個(gè)進(jìn)程空間塊大小為32MB。每個(gè)進(jìn)程空間塊中可以包含一個(gè)進(jìn)程。系統(tǒng)128個(gè)進(jìn)程空間塊的編號(hào)0-127,編號(hào)為I的進(jìn)程空間塊中的進(jìn)程實(shí)際使用的虛擬地址空間為(I*0x02000000)到(I*0x02000000+0x01FFFFFF)。
所以VA通常高7位都為0時(shí) MVA = VA | (PID 《《 25)
當(dāng)VA高7位不為0時(shí) MVA = VA,這種VA是本進(jìn)程用于訪問(wèn)別的進(jìn)程中的數(shù)據(jù)和指令的虛擬地址,注意這時(shí)被訪問(wèn)的進(jìn)程標(biāo)識(shí)符不能為0。
注意:當(dāng)FCSE_PID為0時(shí),即當(dāng)前復(fù)位,則當(dāng)前920T和CACHES及MMU之間是平面映射的關(guān)系(很巧妙:))。
六、TLB是什么
TLB即translate look-aside buffer,快表就是存儲(chǔ)幾個(gè)常用的頁(yè)表,以提高系統(tǒng)運(yùn)行的速度。在更新頁(yè)表之前要使其無(wú)效,其操作的寄存器為R8,R8為只寫寄存器,如果讀它則會(huì)造成不可估計(jì)的后果。
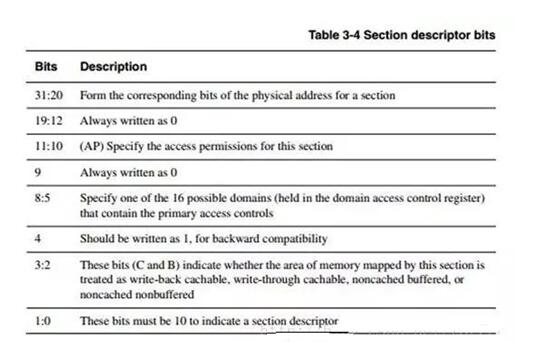
七、AP賦值表
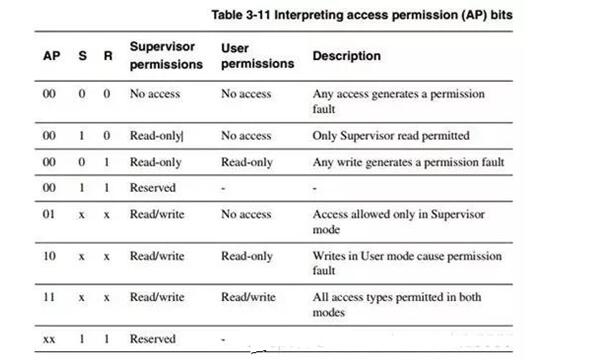
而DOMAIN的賦值則是在C3中的,32bit共有16個(gè)域,每個(gè)域分兩個(gè)bit,這兩個(gè)bit控制當(dāng)前域的權(quán)限。而以上四個(gè)bit是為了選擇0-15個(gè)域的其中一個(gè)。
八、關(guān)于C、B賦值
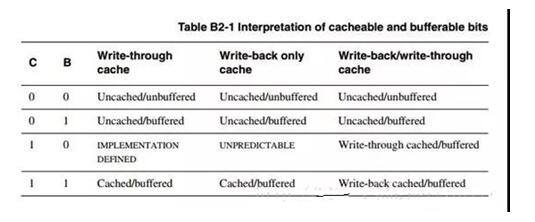
以上有關(guān)于兩種寫緩存,寫通以及寫回。寫回法是指CPU在執(zhí)行寫操作時(shí),被寫的數(shù)據(jù)只寫入cache,不寫入主存,僅當(dāng)需要替換時(shí),才把已經(jīng)修改的cache塊寫回到主存中。寫通法是指CPU在執(zhí)行寫操作時(shí),必須把數(shù)據(jù)同時(shí)寫入cache和主存。
九、時(shí)鐘以及總線概念
FCLK, HCLK, andPCLK
FCLK is used byARM920T.
HCLK is used forAHB bus, which is used by the ARM920T, the memory controller, the interruptcontroller, the LCD controller, the DMA and USB host block.
PCLK is used forAPB bus, which is used by the peripherals such as WDT, IIS, I2C, PWM timer, MMCinterface,ADC, UART, GPIO, RTC and SPI.
What is AHB/APB?
InternalAdvanced Microcontroller Bus Architecture(AMBA)是一種總線標(biāo)準(zhǔn),以下兩項(xiàng)都符合此標(biāo)準(zhǔn)。
AHB(AdvancedHigh performance Bus),主要用于系統(tǒng)高性能、高時(shí)速速率模塊間通信。
APB(AdvancedPeripheral Bus),主要用于慢速片上外設(shè)與ARM核的通訊。
AHB私有外設(shè)總線,只用于CM3內(nèi)部的AHB外設(shè),它們是:NVIC,F(xiàn)PB, DWT和ITM。
APB私有外設(shè)總線,既用于CM3內(nèi)部的APB設(shè)備,也用于外部設(shè)備(這里的“外部”是對(duì)內(nèi)核而言)。CM3允許器件制造商再添加一些片上APB外設(shè)到APB私有總線上,它們通過(guò)APB接口來(lái)訪問(wèn)。
十、四種耗電模式
NORMAL,SLOW,IDLE,SLEEP
先配置主PLL MPLL給CPU用。在上電復(fù)位的時(shí)候PLL是不穩(wěn)定的,所以在PLLCON在被軟件配置之前Fin直接是跳過(guò)MPll給FCLK,所以不配置PLLCON也是可以正常工作。即使工作在正常狀態(tài)下,也可以對(duì)MPLLCON進(jìn)行配置,配置之后等待PLL Lock-time過(guò)后內(nèi)部各模塊的CLK才可以被正常供應(yīng)。
十一、arm處理器架構(gòu)詳解
那架構(gòu)呢?再來(lái)看一張圖。

其中左側(cè)的就是架構(gòu),右側(cè)的是處理器,也可以叫核。arm首個(gè)最成功的cpu是ARM7TDMI,是基于ARMv4的。ARM架構(gòu)包含了下述RISC特性:
讀取/儲(chǔ)存 架構(gòu)
不支援地址不對(duì)齊內(nèi)存存取(ARMv6內(nèi)核現(xiàn)已支援)
正交指令集(任意存取指令可以任意的尋址方式存取數(shù)據(jù)Orthogonal instrucTIon set)
大量的16 &TImes; 32-bit 寄存器陣列(register file)
固定的32 bits 操作碼(opcode)長(zhǎng)度,降低編碼數(shù)量所產(chǎn)生的耗費(fèi),減輕解碼和流水線化的負(fù)擔(dān)。
大多均為一個(gè)CPU周期執(zhí)行。
不同版本的架構(gòu)會(huì)有所調(diào)整。
和三星相同的其他和arm合作的各大廠商通常會(huì)把它的CPU和各類外圍IP都放到一起,然后自己拿著圖紙去流片,生產(chǎn)出來(lái)的也是一個(gè)正方形,下面有很多引腳,這個(gè)東西不僅包含了CPU,還包含了其他的控制器,這個(gè)東西就叫做SOC(system on chip)。從英文來(lái)看,所謂的四核SOC什么的,本意就不是單指CPU,而是四核系統(tǒng)。
所以目前各大廠商所做的事情,就是買來(lái)ARM的授權(quán),得到ARM處理器的源代碼,而后自己搞一些外圍IP(或者買或者自己設(shè)計(jì)),組成一個(gè)SOC后,去流片。不同的SOC,架構(gòu)不同(就是CPU如何和IP聯(lián)系起來(lái),有的以總線為核心,有的以DDR為核心),所以,海思是擁有自主產(chǎn)權(quán)的SOC架構(gòu)。可是,無(wú)論任何廠商,再怎么折騰,都沒(méi)有怎么動(dòng)過(guò)CPU,ARM核心就好好的呆在那里,那就是中央處理器。
目前ARM的產(chǎn)品天梯:
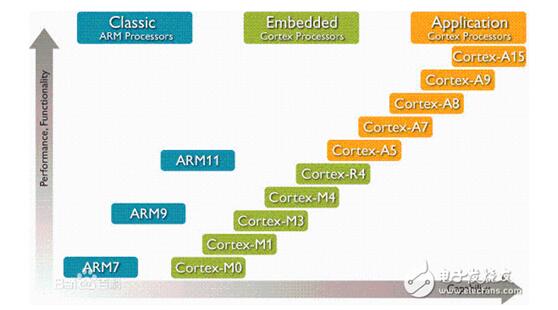
ARM命名規(guī)則:
第一個(gè)數(shù)字:系列名稱:eg.ARM7、ARM9
第二個(gè)數(shù)字:Memory system
2:帶有MMU
4:帶有MPU
6:無(wú)MMU與MPU
第三個(gè)數(shù)字:Memory size
0:標(biāo)準(zhǔn)Cache(4-128k)
2:減小的Cache
6:可變的Cache
第四個(gè)字符:T:表示支持Thumb指令集
D:表示支持片上調(diào)試(Debug)
M:表示內(nèi)嵌硬件乘法器(MulTIplier)
I :支持片上斷點(diǎn)和調(diào)試點(diǎn)
E:表示支持增強(qiáng)型DSP功能
J :表示支持Jazelle技術(shù),即Java加速器
S:表示全合成式
-
ARM處理器
+關(guān)注
關(guān)注
6文章
361瀏覽量
42488 -
ARM架構(gòu)
+關(guān)注
關(guān)注
15文章
182瀏覽量
37050
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論