 解決不重復序列全排列問題的兩個方法
解決不重復序列全排列問題的兩個方法
簡介
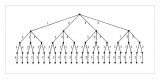
給定 {1, 2, 3, , , n},其全排列為 n! 個,這是最基礎的高中組合數學知識。我們以 n=4 為例,其全部排列如下圖(以字典序樹形式來呈現):

我們很容易想到用遞歸來求出它的所有全排列。
仔細觀察上圖,
以 1 開頭,下面跟著 {2, 3, 4} 的全排列;
以 2 開頭,下面跟著 {1, 3, 4} 的全排列;
以 3 開頭,下面跟著 {1, 2, 4} 的全排列;
以 4 開頭,下面跟著 {1, 2, 3} 的全排列。
代碼如下:
/**
*
* author : 劉毅(Limer)
* date : 2017-05-31
* mode : C++
*/
#include
#include
usingnamespacestd;
voidFullPermutation(intarray[],intleft,intright)
{
if(left==right)
{
for(inti=0;i4;i++)
cout<array[i]<" ";
cout<endl;
}
else
{
for(inti=left;i<=?right;i++)
{
swap(array[i],array[left]);
FullPermutation(array,left+1,right);
swap(array[i],array[left]);
}
}
}
intmain()
{
intarray[4]={1,2,3,4};
FullPermutation(array,0,3);
return0;
}
運行如下:

咦~ 遞歸寫出的全排列有點不完美,它并不嚴格遵循字典序。但是熟悉 C++ 的朋友肯定知道另一種更簡單,更完美的全排列方法。
定義于文件
1、next_permutation,對于當前的排列,如果在字典序中還存在下一個排列,返回真,并且把當前排列調整為下一個排列;如果不存在,就把當前排列調整為字典序中的第一個排列(即遞增排列),返回假。
2、prev_permutation,對于當前的排列,如果在字典序中還存在上一個排列,返回真,并且把當前排列調整為上一個排列;如果不存在,就把當前排列調整為字典序中的最后一個排列(即遞減排列),返回假。
/**
*
* author : 劉毅(Limer)
* date : 2017-05-31
* mode : C++
*/
#include
#include
usingnamespacestd;
voidFullPermutation(intarray[])
{
do
{
for(inti=0;i4;i++)
cout<array[i]<" ";
cout<endl;
}while(next_permutation(array,array+4));
}
intmain()
{
intarray[4]={1,2,3,4};
FullPermutation(array);
return0;
}
運行截圖省略。輸出結果正好符合字典序。
那這個 “輪子” 是怎么做的呢?(摘自侯捷的《STL 源碼剖析》)
1、next_permutation,首先,從最尾端開始往前尋找兩個相鄰元素,令第一元素為*i,第二元素為*ii,且滿足*i < *ii,找到這樣一組相鄰元素后,再從最尾端開始往前檢驗,找出第一個大于*i的元素,令為*j,將 i,j 元素對調,再將 ii 之后的所有元素顛倒排列,此即所求之 “下一個” 排列組合。
2、prev_permutation,首先,從最尾端開始往前尋找兩個相鄰元素,令第一元素為*i,第二元素為*ii,且滿足*i > *ii,找到這樣一組相鄰元素后,再從最尾端開始往前檢驗,找出第一個小于*i的元素,令為*j,將 i,j 元素對調,再將 ii 之后的所有元素顛倒排列,此即所求之 “上一個” 排列組合。
代碼如下:
boolnext_permutation(int*first,int*last)
{
if(first==last)returnfalse;// 空區間
int*i=first;
++i;
if(i==last)returnfalse;// 只有一個元素
i=last;
--i;
for(;;)
{
int*ii=i;
--i;
if(*i< *ii)
{
int*j=last;
while(!(*i< *--j))// 由尾端往前找,直到遇上比 *i 大的元素
;
swap(*i,*j);
reverse(ii,last);
returntrue;
}
}
if(i==first)// 當前排列為字典序的最后一個排列
{
reverse(first,last);// 全部逆向排列,即為升序
returnfalse;
}
}
boolprev_premutation(int*first,int*last)
{
if(first==last)returnfalse;// 空區間
int*i=first;
++i;
if(i==last)returnfalse;// 只有一個元素
i=last;
--i;
for(;;)
{
int*ii=i;
--i;
if(*i> *ii)
{
int*j=last;
while(!(*i> *--j))// 由尾端往前找,直到遇上比 *i 大的元素
;
swap(*i,*j);
reverse(ii,last);
returntrue;
}
}
if(i==first)// 當前排列為字典序的第一個排列
{
reverse(first,last);// 全部逆向排列,即為降序
returnfalse;
}
}
結后語
這篇文章主要介紹了解決不重復序列的全排列問題的兩個方法:遞歸和字典序法。
-
嵌入式
+關注
關注
5141文章
19537瀏覽量
315138
原文標題:詳解全排列算法
文章出處:【微信號:mcuworld,微信公眾號:嵌入式資訊精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
生成不重復的隨機數
用于配置兩個QSPI將序列數據比特傳輸到其它設備
DNA片段拼接中的預歸并重復序列屏蔽方法

DS18B20 穩定搜索20個ROM,不重復,不掉線







 工商網監
工商網監
評論